
Flink中的状态
一、Flink中的状态
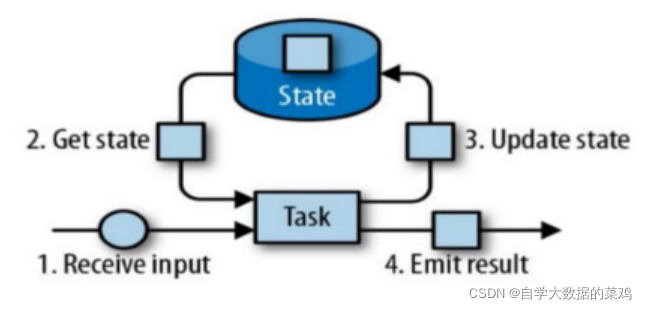
1)由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态。
2)可以认为状态就是一个本地变量(一般放在本地内存,本地内存读取修改什么的都比较快),可以被任务的业务逻辑访问。
3)Flink会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑。
像map、filter、flatMap这些算子,来一个输出一个,不依赖于其它的数据,也不依赖于之前的结果,所以它们是无状态的算子。
像window、reduce、聚合等一些操作,需要依赖于之前计算的结果,所以这些算子都属于有状态的算子。
在Flink中,状态始终与特定算子相关联(其实,在map、filter里面可以定义状态),跟特定的任务绑定在一起的,后面发生的任务不能访问到前面任务的状态,因为后面任务可能跟前面任务不在一个taskManager或者slot,如果要访问状态,需要做网络传输,而状态是在内存中的,不可能做网络传输。
为了使运行时的Flink了解算子的状态,算子需要预先注册其状态
总的来说,有两种类型的状态:
算子状态(Operator State):算子状态的作用范围限定为算子任务
键控状态(Keyed State):根据输入数据流中定义的键(key)来维护和访问
1、算子状态
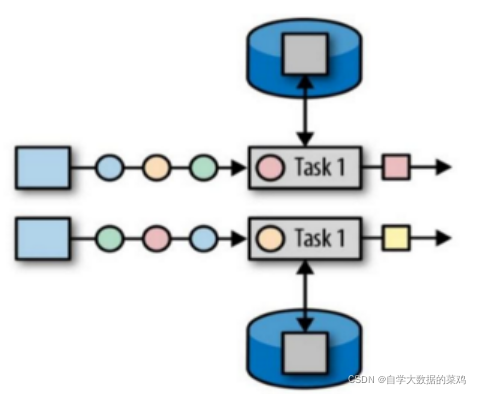
上图中两个Task1属于一个算子的两个并行子任务,它们不在一个slot上,甚至不在一个TaskManager上,所以不能访问别人的状态。
1)算子状态的作用范围限定为算子任务,由同一并行任务(上图上面的一个Task1属于一个并行子任务,下面那个也是一个并行子任务,所以有两个并行子任务)所处理的所有数据都可以访问到相同的状态。
2)状态对于同一子任务而言是共享的(一个Task1里所有数据都共享这个状态)。
3)算子状态不能由相同或不同算子的另一个子任务访问(即使上图中的两个Task1是一个算子的两个子任务,也不能互相访问)。
4)只要在同一个分区,不管key相不相同,访问的都是一个状态。
1.1 算子状态数据结构
1)列表状态(List state)
将列表表示为一组数据的列表(在故障恢复之后,可能会发生并行度的调整,如果要进行聚合还好说,如果要拆分就不容易去拆分)
2)联合列表状态(Union list state)
也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
例如有两个并行子任务,每个并行子任务有三个状态,经过故障恢复后要并行度变为3,如果是列表状态,会把第一个子任务的前两个状态分给分区后的1,会把第二个子任务的前两个状态分给分区后的2,会把剩下的状态分给分区后的3;如果是联合列表状态,会把这六个状态给下游全部分发一份,让它们自己挑选状态。
3)广播状态(Broadcast state)
如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
1.2 算子状态案例
需求:定义一个有状态的map操作,统计当前分区数据个数
代码如下:
下面代码可以实现一个有状态的map操作,可以统计当前分区内数据个数,但是如果不做特殊说明,容错的时候不会进行相应的处理,本地变量在内存中,没办法进行恢复,只能重新从0开始count。
//定义一个有状态的map操作,统计当前分区的数据个数
mapResult.map(newMapFunction<SensorReading, Integer>(){//定义一个本地变量作为算子状态private Integer count=0;@Overridepublic Integer map(SensorReading sensorReading)throws Exception {
count++;return count;}})
进行了容错配置的代码(还需要额外实现ListCheckpointed接口):
mapResult.map(newMyCountMapper());publicstaticclassMyCountMapperimplementsMapFunction<SensorReading,Integer>, ListCheckpointed<Integer>{//定义一个本地变量作为算子状态private Integer count=0;@Overridepublic Integer map(SensorReading sensorReading)throws Exception {
count++;return count;}//Checkpoint触发时会调用这个方法,我们要实现具体的snapshot逻辑,比如将哪些本地状态持久化//对状态做快照,返回一个Integer的List@Overridepublic List<Integer>snapshotState(long l,long l1)throws Exception {return Collections.singletonList(count);}//从上次Checkpoint中恢复数据到本地内存//发生故障时,从做的快照里面进行恢复count//如果发生并行度减少,可能list里面不止一个值,所以需要合并@OverridepublicvoidrestoreState(List<Integer> list)throws Exception {for(Integer num:list){
count+=num;}}}
2、键控状态(Keyed State)—更常用
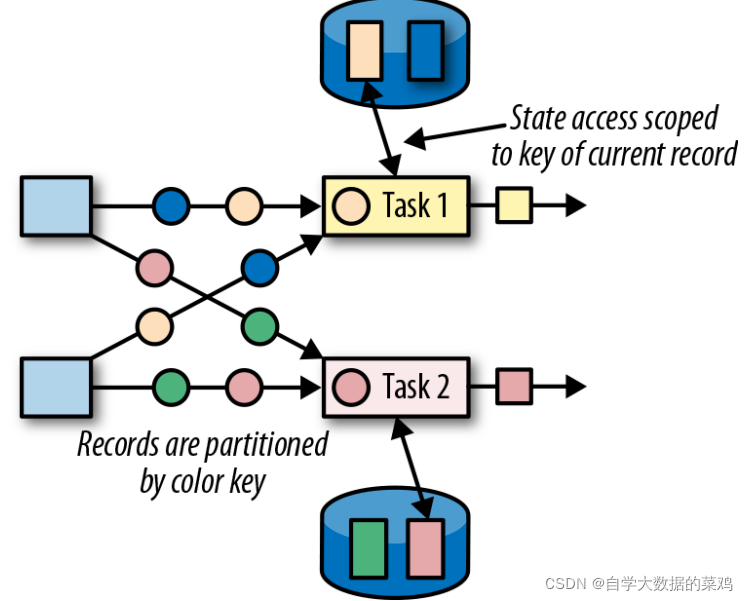
上图中的Task1和Task2也是一个算子的两个并行子任务。这里经过keyBy等重分区操作,黄色和蓝色进入了Task1,绿色和粉色进入了Task2。以Task1为例,这个分区里有多个Key,但是跟算子状态不一样的是,一个分区里不是一个状态,一个分区里每个key都有一个状态,黄色的想访问蓝色的状态是不行的,但是它们都可以访问Task1里的类的实例。
1)键控状态是根据输入数据流中定义的键(key)来维护和访问的。
2)Flink 为每个键值Key维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个 key 对应的状态。
3)当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。
因此,具有相同 key 的所有数据都会访问相同的状态。
2.1 键控状态数据结构
1)值状态(Value state)
将状态表示为单个的值。
2)列表状态(List state)
将状态表示为一组数据的列表。
3)映射状态(Map state)
将状态表示为一组Key-Value对
4)聚合状态(Reducing & Aggregating State)
将状态表示为一个用于聚合操作的列表
2.2 键控状态的使用
键控状态需要用到运行时上下文,因为一个分区中可能有多个Key,而键控状态是针对每一个Key的,所以我们要通过运行时上下文来获取Key的值,使用运行时上下文要用到富含数。
要使用键控状态,主要分为以下几步:
1)声明一个键控状态:
myValueState =getRuntimeContext().getState(newValueStateDescriptcr<Integer>("my-value1",Integer.class));
2)读取当前状态的值:
Integer myValue = myValueState.value();
3)修改当前状态:
myValueState.update( value:10);
整体使用代码如下:
mapResult.keyBy("id").map(newMyKeyCountMapper());//自定义实现RichFunctionpublicstaticclassMyKeyCountMapperextendsRichMapFunction<SensorReading,Integer>{private ValueState<Integer> keyCountState;//其他类型状态的声明private ListState<String> myListState;private MapState<String,Double> myMapState;private ReducingState<SensorReading> myReducingState;@Overridepublicvoidopen(Configuration parameters)throws Exception {
keyCountState=getRuntimeContext().getState(newValueStateDescriptor<Integer>("key-count",Integer.class));
myListState =getRuntimeContext().getListState(newListStateDescriptor<String>("my-list",String.class));
myMapState=getRuntimeContext().getMapState(newMapStateDescriptor<String, Double>("my-map",String.class,Double.class));//myReducingState=getRuntimeContext().getReducingState(new ReducingStateDescriptor<SensorReading>(""))}@Overridepublicvoidclose()throws Exception {super.close();}@Overridepublic Integer map(SensorReading sensorReading)throws Exception {
Integer count = keyCountState.value();
count++;
keyCountState.update(count);//其他状态API调用
Iterable<String> strings = myListState.get();for(String str:strings){
System.out.print(str);}
myListState.add("hello");//Map State
myMapState.get("1");
myMapState.put("2",12.3);//Reduce state
myReducingState.add(sensorReading);return count;}}
2.3 键控状态的API
1)值状态(ValueState)
获取值:valueState.value()
修改值:valueState.update(value: T)
2)列表状态(ListState)
单个添加值:listState.add(value: T)
添加所有值:listState.addAll(values: java.util.List[T])
获得所有值:ListState.get()(注意:返回的是Iterable[T])
修改所有值:ListState.update(values: java.util.List[T])
3)映射状态(MapState)
根据Key获取值:mapState.get(key: K)
添加一对值:mapState.put(key: K, value: V)
判断Key是否存在:mapState.contains(key: K)
移除某个Key:mapState.remove(key: K)
4)聚合状态(ReducingState & AggregatingState)
add方法:ReducingState.add(value: T)
在使用聚合状态时,ReducingState需要传递三个参数:
5)通用API:
State.clear()是清空操作。
myReducingState=getRuntimeContext().getReducingState(newReducingStateDescriptor<SensorReading>("my-reduce",newMyReduceFunction(),SensorReading.class));//Reduce state
myReducingState.add(sensorReading);
方法里的输入输出类型不能改变的,当调用add方法时传递一个sensorReading对象,实际上是把这个对象传递给了自定义的MyReduceFunction()类,然后进行聚合操作。
至于AggregatingState,与ReducingState不同的是最后获取的结果类型可以跟输入的结果类型不一样。
3、键控状态的案例
需求:检测传感器的温度值,如果连续的两个温度差值超过10度,就输出报警。
需求分析:要实现这个功能,在我们获取到当前一条数据的时候,要跟上一条数据进行对比,所以要把上一条数据的状态进行保存,可以保存为valuestate,如果温差超过10,那么就要输出报警,但是如果温差不超过10,就没有必要输出。而map算子如果规定了输出类型是必须要输出的,flatMap算子则是采用collect方法进行输出,所以也可以不输出,所以flatMap算子更加适合。
代码实现:
SingleOutputStreamOperator<Tuple3<String, Double, Double>> result = mapResult.keyBy("id").flatMap(newMyTemperatureWarning(10.0));publicstaticclassMyTemperatureWarningextendsRichFlatMapFunction<SensorReading, Tuple3<String,Double,Double>>{private Double range;private ValueState<Double> valueState;publicMyTemperatureWarning(Double range){this.range = range;}@Overridepublicvoidopen(Configuration parameters)throws Exception {
valueState=getRuntimeContext().getState(newValueStateDescriptor<Double>("my-temperature",Double.class));}@Overridepublicvoidclose()throws Exception {super.close();}@OverridepublicvoidflatMap(SensorReading sensorReading, Collector<Tuple3<String, Double, Double>> collector)throws Exception {//获取上个状态的温度,如果不是第一次if(valueState.value()!=null){if(Math.abs(valueState.value()-sensorReading.getTemperature())>=range)
collector.collect(Tuple3.of(sensorReading.getId(),valueState.value(), sensorReading.getTemperature()));}
valueState.update(sensorReading.getTemperature());}}
4、状态后端(State Backends)
4.1 状态后端了解
1)每传入一条数据,有状态的算子任务都会读取和更新状态。
2)由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速的状态访问。
3)状态的存储、访问以及维护由一个可插入的组件决定,这个组件就叫做状态后端。
4)状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储。
4.2 状态后端的类型
1)MemoryStateBackend
内存级状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager的JVM堆上(因为TaskManager负责执行任务,而再执行任务的过程中需要访问状态,所以放在TaskManager中可以快速的访问,避免网络请求和传输),而将checkpoint存储在JobManager的内存中。
特点:快速、低延迟,但不稳定
2)FsStateBackend
将checkpoint存到远程的持久化文件系统(FileSystem)上,而对于本地状态,跟MemoryStateBackend一样,也会存在TaskManager的JVM堆上。
特点:同时拥有内存及的本地访问速度,和更好的容错保证;
缺点:如果状态越来越多,数据量越来越大,内存放不下,出现OOM的错误,只能去扩容或者更换状态后端
3)RocksDBStateBackend
将所有状态序列化后,存入本地的RocksDB中。
特点:速度稍微慢一点,但是不会出现OOM的情况,适用于数据量比较大且会不断增长的情况
4.3 状态后端的设置
配置文件里的配置: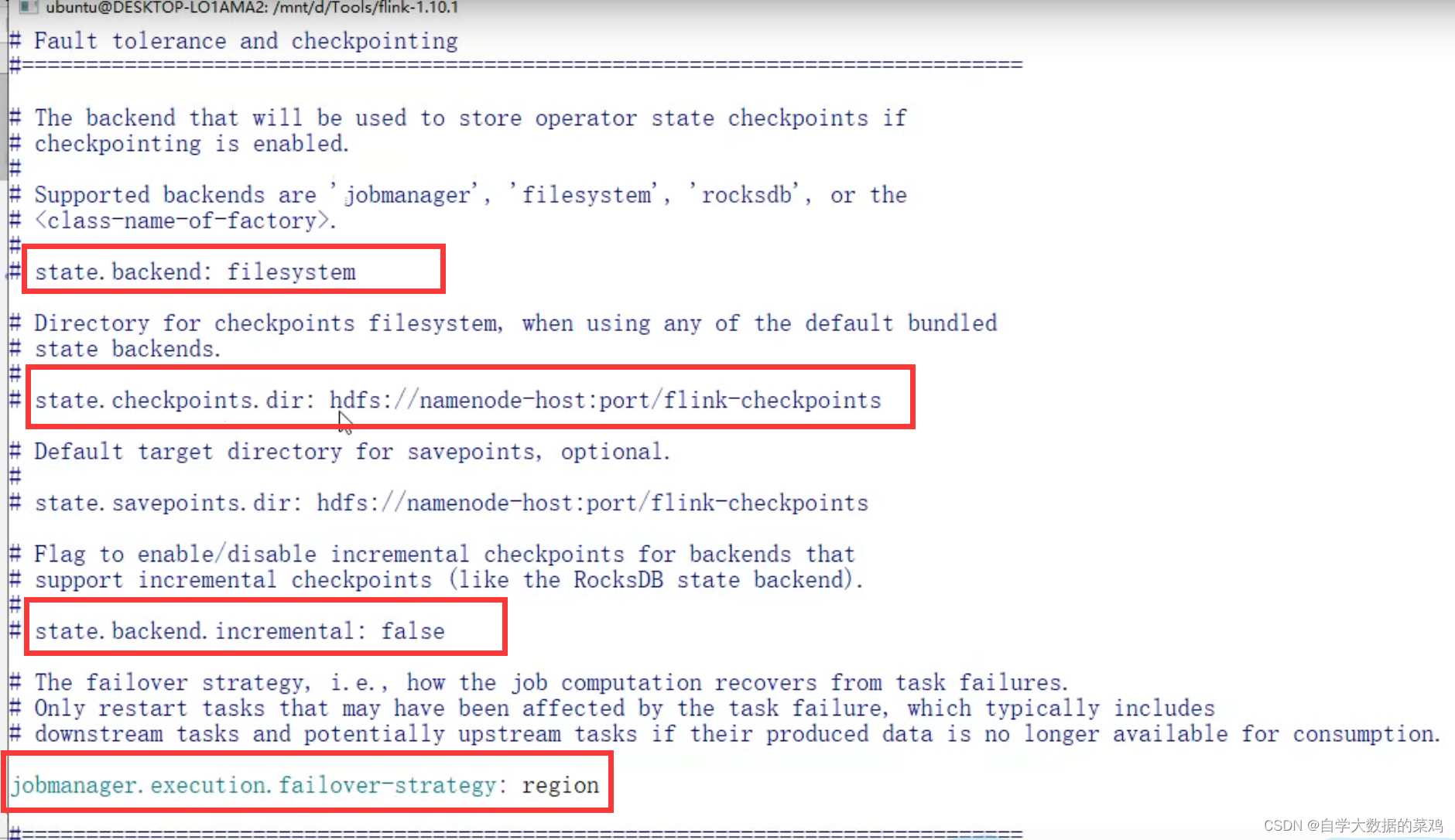
上图第一个红框的参数,可以设置checkpoint的存储方式,jobmanager是存储到内存,filsystem是存储到HDFS等文件系统,rocksdb是存储到这个数据库中。
第二个参数是如果存储到文件系统,指定存储的路径。
第三个参数是进行增量化保存checkpoint,文件系统就不支持,rocksdb支持。
第四个参数是进行区域化划分,当发生故障时,如果不设置区域化划分,需要重启所有的并行任务,重新加载自己的状态;使用了区域化划分,只需要启动划分的区域的部分。
代码中进行配置:
//true代表是允许异步做快照,可以提高性能
env.setStateBackend(newMemoryStateBackend(true));
env.setStateBackend(newFsStateBackend("hdfs://hadoop102:"));//第二个参数为true代表允许增量话保存checkpoint
env.setStateBackend(newRocksDBStateBackend("hdfs://hadoop102:",true));
上述代码分别创建了三种状态后端方式。
版权归原作者 自学大数据的菜鸡 所有, 如有侵权,请联系我们删除。