

团队名称
卡我一个
团队成员
张 菠(重庆邮电大学)
陈星霖(重庆邮电大学)
王 飞(重庆邮电大学)
团队名次
全国第四名
赛题描述说明介绍
报名 | 2024中国高校计算机大赛——大数据挑战赛报名启动!
关注微****信公众号“数据派THU”,后台回复“20240615”,即可获取“赛题描述”
参赛分享与收获
我们队伍非常有幸参加本次时序预测相关的大数据挑战赛,通过本次比赛,我们队伍收获颇丰,在大量查阅论文,复现代码,提升成绩的过程中,不仅提升了对时序数据的分析能力,也深化了对深度学习模型在时序预测的应用理解。
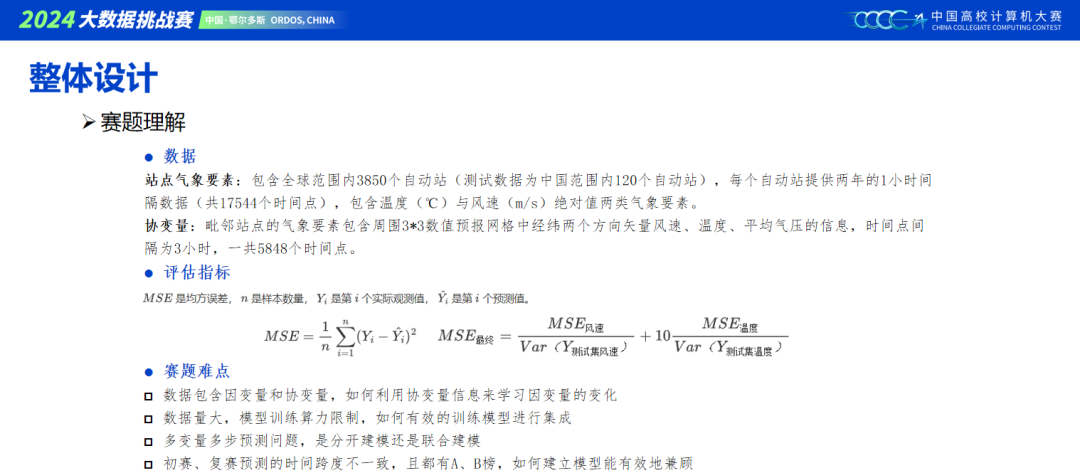
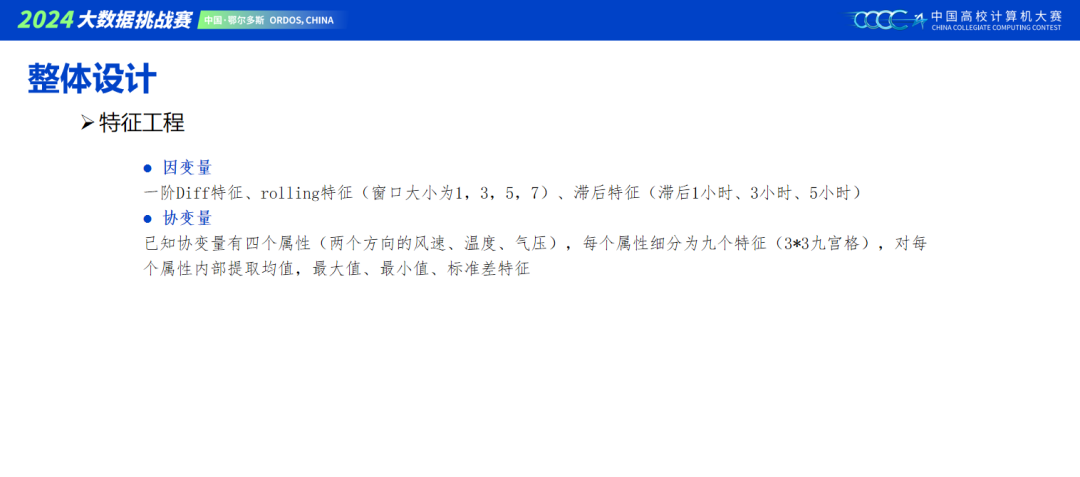
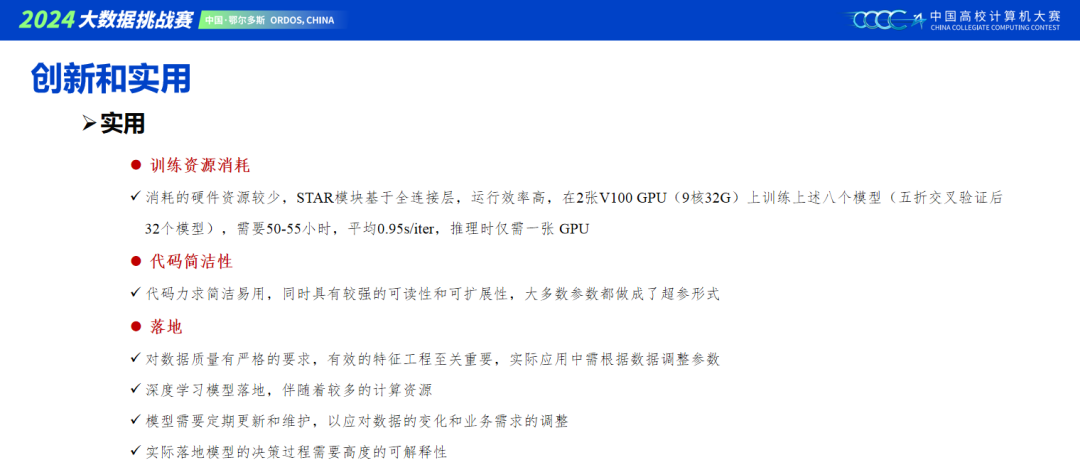
大赛初期开源了非常有效的baseline,基本上是给我们指明了建模方向,本次大赛只有一个目标,那就是如何增加手里模型的泛化性,重中之重。通过尝试,我们可以知道提取特征可以有效上分,修改模型结构也能达到上分的效果,但是都很容易过拟合。由于提交次数限制,我们队伍最终选择了模型之路,去搭建更多差异性大的模型,来进行集成,相对的特征方面做的工作就少了。一方面考虑,目前的时序sota都没有做更多的数据预处理以及特征工程,都在尝试建立不同的模型,去提取时序数据的趋势与季节性。另一方面考虑,本次切换测试数据次数比较多,不能把握数据分布的情况下,我们也希望模型对数据的泛化能力能强一些。同时,也了解到有做很多EDA工作的队伍,效果反而不佳,我们队伍便减少了数据方面的工作。还有一方面,输入倒置之后,一个通道就是一个特征,我们希望模型内部的交互,能去自动捕获通道的依赖性。虽然目前sota论文,大部分建立在CI的基础上,但是在本次比赛的数据基础上,对特征维度加强交互,依旧会带来收益,因此我们对模型内部都采用了双维度的结构(特征和时间维度)。
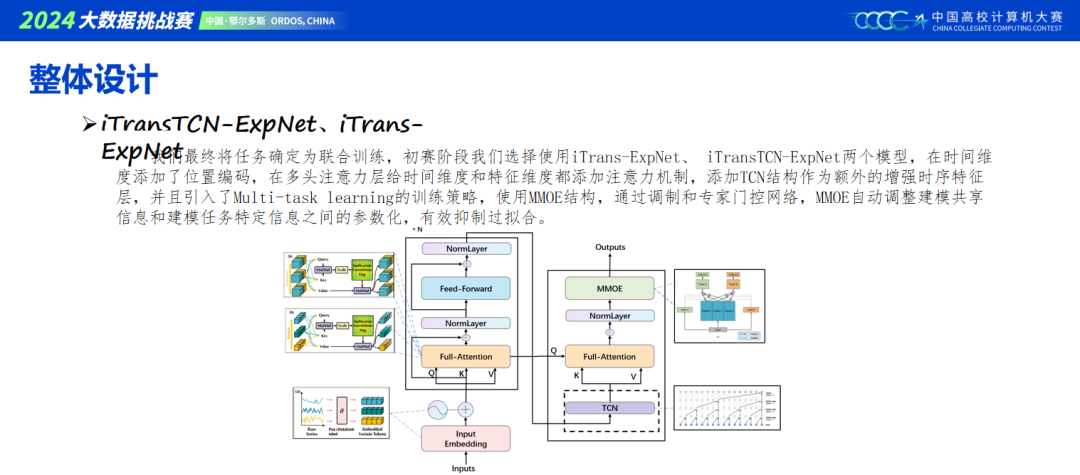
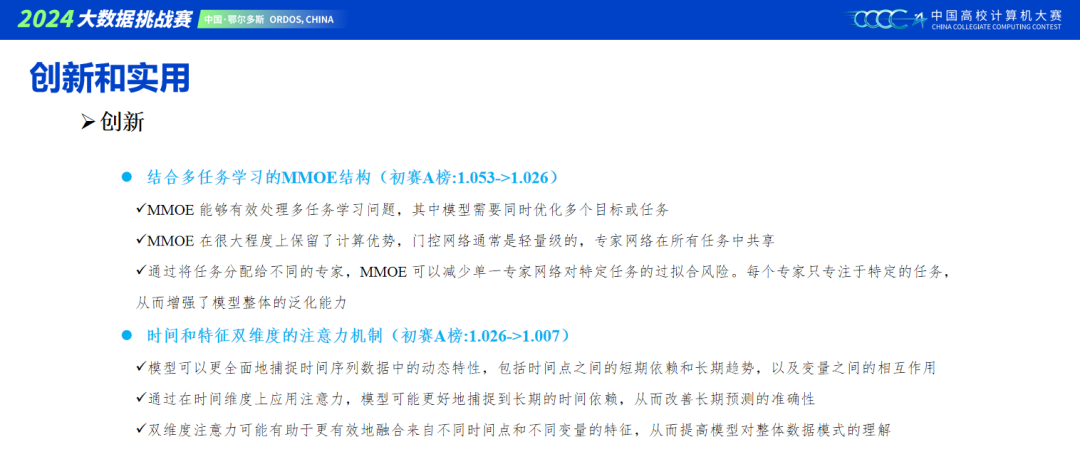
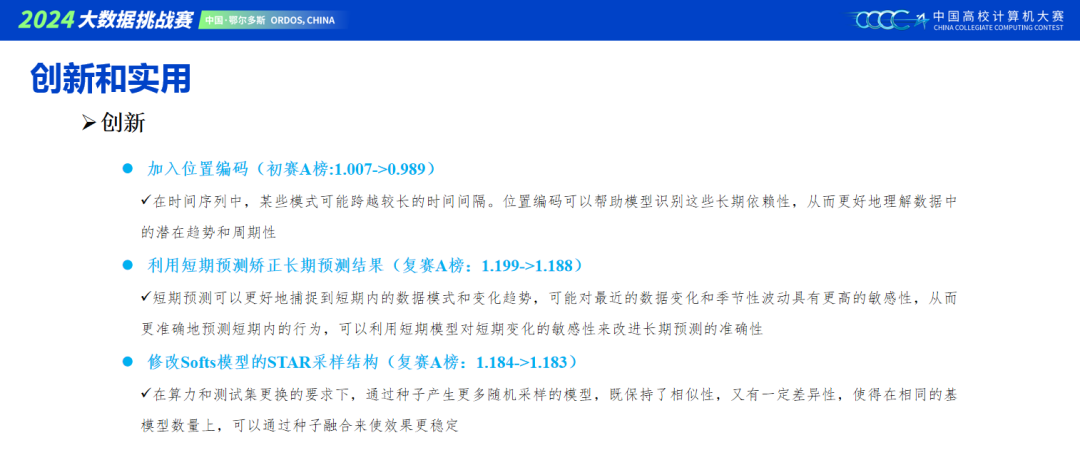
本次比赛初赛需要预测24小时,复赛需要预测72小时,很明显就能想到一个结果矫正的操作,即将初赛的结果按照一定的比例融合进复赛结果的前24天,也可以是一种长期预测任务未来的思路。同时预测目标只有两个,很适合用MMOE结构来进行输出,对本次容易过拟合的情况也有一定缓解。
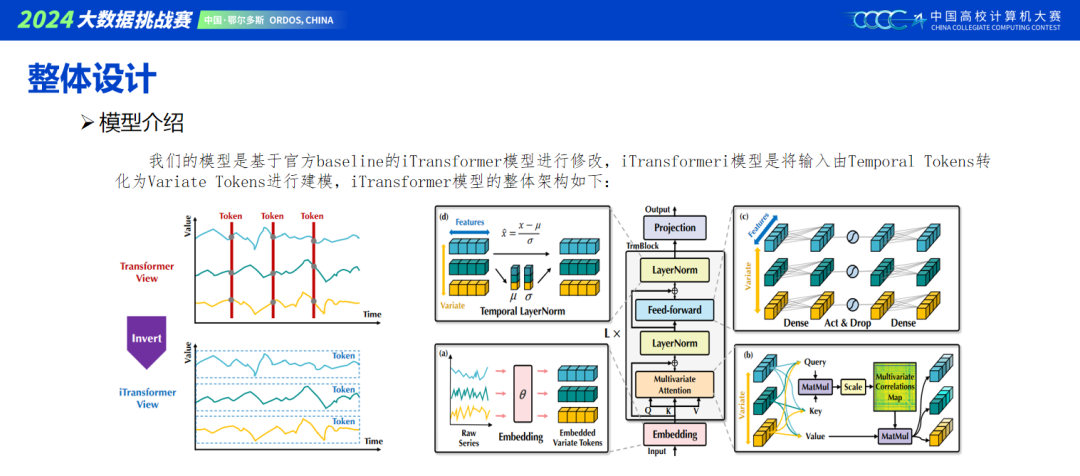
iTransformer论文提到将数据倒置之后,数据会自动包含时序信息,因此不用添加位置编码。但是,我们队伍发现,在时间维度添加位置编码是稳稳有效果的,具体原因还需要思考。
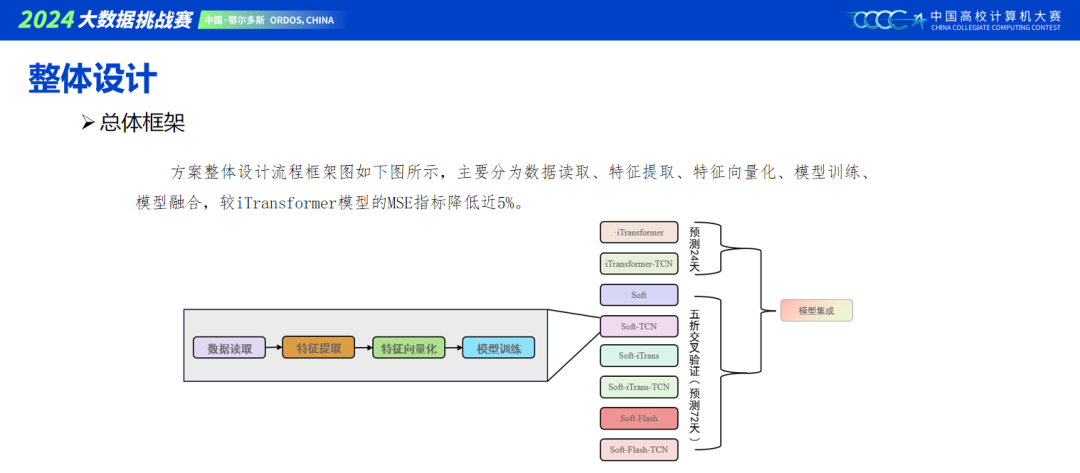
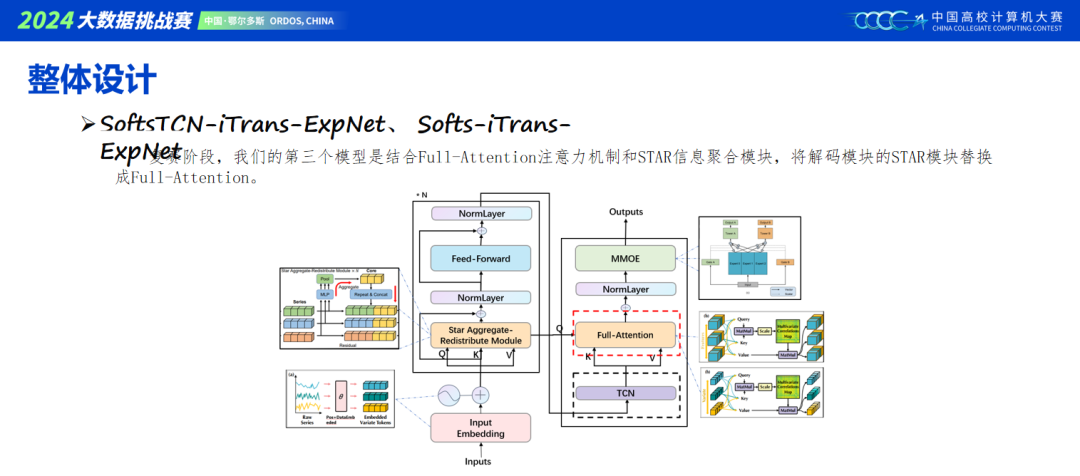
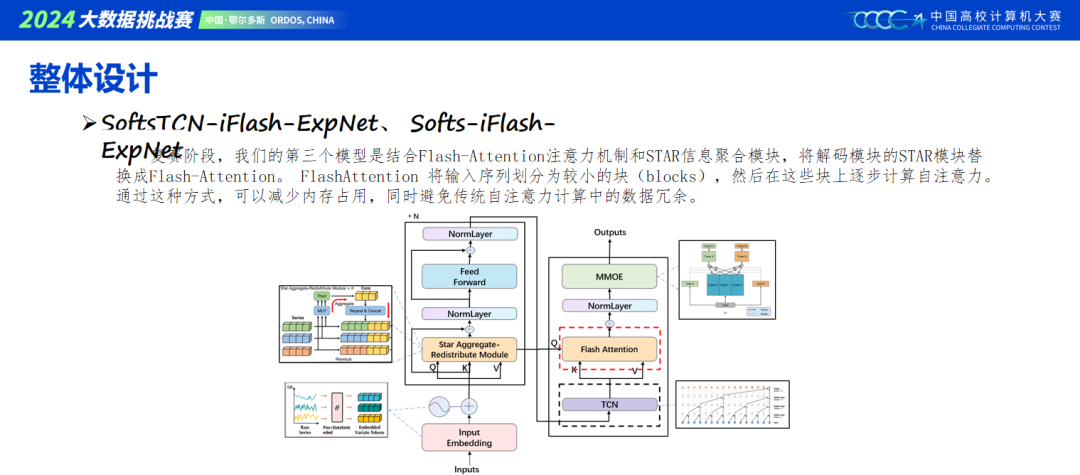
当前主流的建模包含Transformer和MLP结构,我们模型基本是将两者进行结合,具体可以看ppt里的模型搭建。TCN作为时序特征增强层,单独效果不佳,但用做模型集成效果很好。
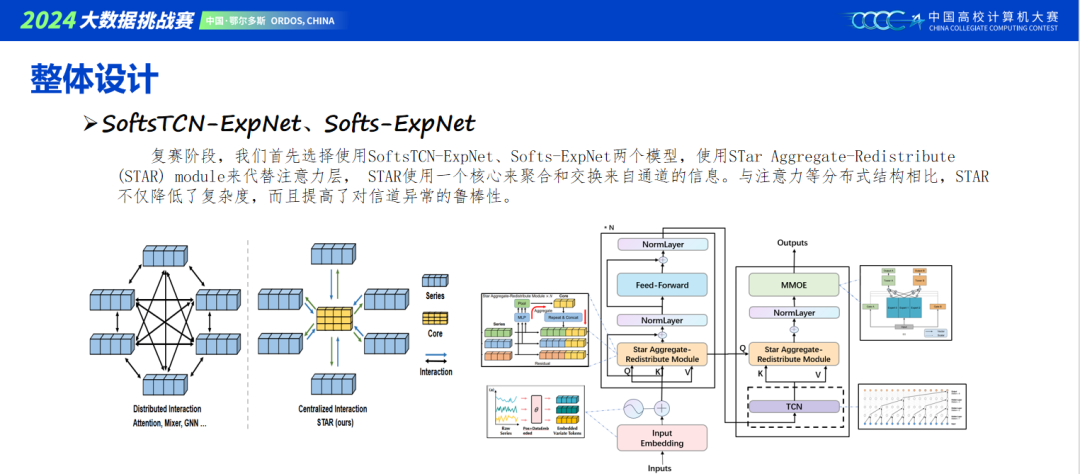
Soft模型中的信息集中模块,采用了随机采样,根据以往,模型越多越稳定的经验,很容易想到用种子来产生不同的随机采样的推理结果,最终我们在模型融合采用了五个种子融合。
最后,感谢为大赛付出的主办方,承办方,以及其他相关单位。感谢老师和为大赛做出相关工作的清华的同学们。希望未来的我们能在数据挖掘领域能有更多的创新与收获。
决赛答辩ppt分享







编辑:文婧
校对:丁玺茗
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU****
今日头条:数据派THU
版权归原作者 数据派THU 所有, 如有侵权,请联系我们删除。