
https://www.aqistudy.cn/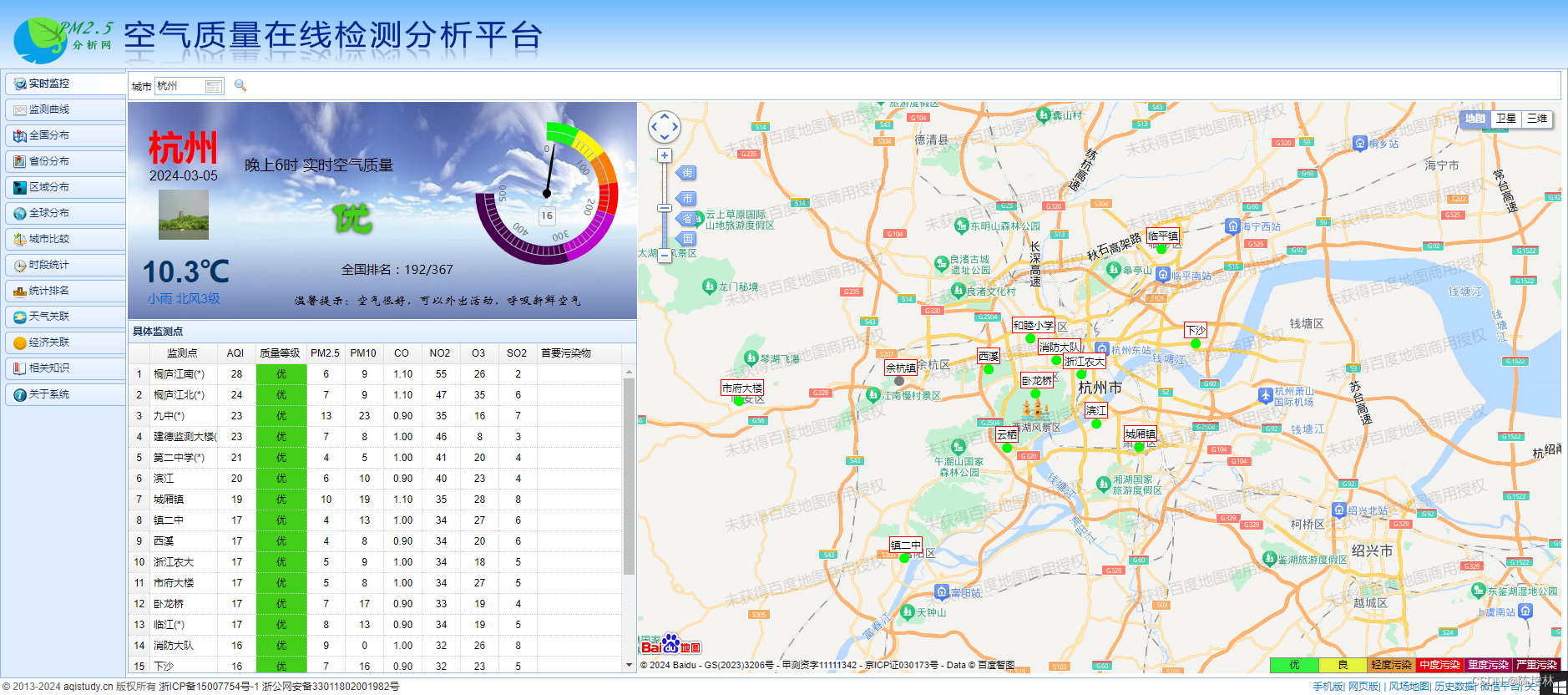
爬取指定城市在指定时间范围内的空气质量数据,并将数据保存为CSV文件。它首先从两个文本文件中读取城市信息和代理IP信息,然后提示用户输入爬取的起始年份、结束年份、起始月份和结束月份。接下来,它启动了Chrome浏览器的调试服务,并创建了一个Chrome驱动,用于自动化地访问指定的网页。之后,它定义了一个函数crawl_aqi_data(),用于爬取指定城市、指定年份和月份的空气质量数据,并将数据保存到本地文件。最后,它循环遍历所有城市和时间段,调用crawl_aqi_data()函数来完成数据爬取任务,完成后关闭浏览器,并输出"数据爬取完成。"
import os
import time
import subprocess
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from fake_useragent import UserAgent
import random
# 读取城市信息withopen("city.txt","r", encoding="utf-8")asfile:
cities =[line.strip()for line infileif line.strip()]
ips =[]withopen('ip.txt','r')as f:for line in f:
ip = line.strip()
ips.append(ip.strip())# 输入爬取的起始年份、结束年份、起始月份和结束月份
start_year =int(input("请输入起始年份: "))
end_year =int(input("请输入结束年份: "))
start_month =int(input("请输入起始月份: "))
end_month =int(input("请输入结束月份: "))# 启动Chrome浏览器调试服务
subprocess.Popen('cmd', shell=True)
subprocess.Popen('"chrome-win64\chrome.exe" --remote-debugging-port=9222', shell=True)# 创建Chrome驱动
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress","localhost:9222")
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable‐gpu')
chrome_options.add_argument('--proxy-server=http://'+ random.choice(ips))
chrome_options.add_argument(f"user-agent={UserAgent().random}")
driver = webdriver.Chrome(options=chrome_options)defcrawl_aqi_data(city, year, month):# 构建URL
url =f"https://www.aqistudy.cn/historydata/daydata.php?city={city}&month={year}{month:02}"# 打开URL
driver.get(url)
time.sleep(2)# 等待页面加载完成# 创建目录
folder_path = os.getcwd()+f"\data\空气质量/{city}/{year}年"ifnot os.path.exists(folder_path):
os.makedirs(folder_path)# 读取数据并保存到DataFrame
rows = driver.find_elements(By.CSS_SELECTOR,".row tr")
data =[]for row in rows:
row_data =[cell.text for cell in row.find_elements(By.TAG_NAME,"td")if cell.text]if row_data:
data.append(row_data)# 将数据转换为DataFrame
df = pd.DataFrame(data)# 保存DataFrame为CSV文件
file_path =f"{folder_path}/{year}年{month:02}月.csv"
df.to_csv(file_path, index=False, encoding="utf-8")# 循环爬取指定城市、指定时间段的数据for city in cities:for year inrange(start_year, end_year +1):for month inrange(start_month, end_month +1):
crawl_aqi_data(city, year, month)# 关闭浏览器
driver.quit()print("数据爬取完成。")
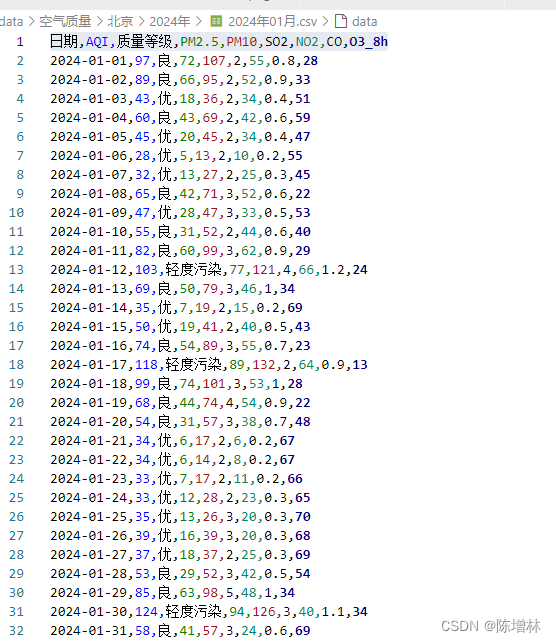
数据可视化
import os
import pandas as pd
import matplotlib.pyplot as plt
# 指定数据文件夹路径
data_folder = os.path.join(os.getcwd(),'data','空气质量')# 设置中文显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False# 读取CSV文件并加载数据defload_data(file_path):if os.path.exists(file_path):if os.stat(file_path).st_size ==0:print(f"File '{file_path}' is empty.")returnNone
df = pd.read_csv(file_path)return df
else:print(f"File '{file_path}' does not exist.")returnNone
all_df=[]# 遍历天气目录下的城市数据for city_name in os.listdir(data_folder):
city_dir = os.path.join(data_folder, city_name)if os.path.isdir(city_dir):# 遍历城市文件夹下的所有 CSV 文件for year in os.listdir(city_dir):
year_dir = os.path.join(city_dir, year)for csv_file in os.listdir(year_dir):if csv_file.endswith(".csv"):# 构建文件路径
file_path = os.path.join(year_dir, csv_file)# 加载数据
df = load_data(file_path)# 添加城市列
df['城市']= city_name
all_df.append(df)
df = pd.concat(all_df, ignore_index=True)# 可视化显示
plt.figure(figsize=(10,6))
plt.plot(df['城市'], df['AQI'], marker='o', color='red', linestyle='-')
plt.xlabel('城市')
plt.ylabel('AQI')
plt.title('各城市空气质量对比')
plt.xticks(rotation=90)# 旋转x轴标签,以便更好地显示城市名
plt.grid(True)# 显示网格线
plt.tight_layout()# 调整布局,防止标签重叠
plt.show()
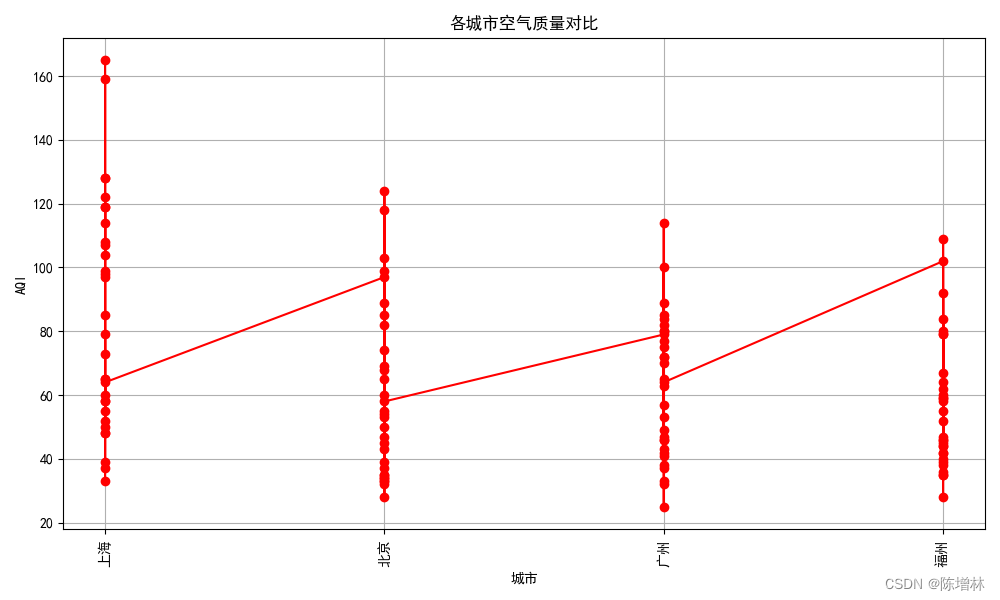
应该改成日期横坐标,算了
本文转载自: https://blog.csdn.net/qq_37655607/article/details/136486379
版权归原作者 陈增林 所有, 如有侵权,请联系我们删除。
版权归原作者 陈增林 所有, 如有侵权,请联系我们删除。