
cxhttps://dblab.xmu.edu.cn/blog/3525/ 参考地址
一,下载数据集
数据集
数据集的介绍

数据集大小

二,数据预处理
使用python对数据进行预处理,由于数据量比较大,选取前一百万条数据
import csv
import time
print("执行")
start_time = time.mktime(time.strptime('2017-11-25', '%Y-%m-%d'))
end_time = time.mktime(time.strptime('2017-12-03', '%Y-%m-%d'))
i = 0
with open("D:\\UserBehavior.csv\\UserBehavior.csv", 'r') as fr:
reader = csv.reader(fr)
for row in reader:
if row[3] != "pv":
if start_time < int(row[4]) < end_time:
str_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(row[4])))
info = [row[0], row[1], row[3], str_time]
i += 1
if i > 10000:
break
with open("D:\\UserBehavior.csv\\processed2.csv", "a+", newline='') as fw:
writer = csv.writer(fw)
writer.writerow(info)
fr.close()
fw.close()
t2=time.time()
三,数据分析
使用spark对数据进行处理
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import java.io.{File, PrintWriter}
object Main {
def main(args: Array[String]): Unit = {
println("Hello world!")
val sparkConf=new SparkConf().setMaster("local").setAppName("a")
val sc =new SparkContext(sparkConf)
val spark=SparkSession.builder().getOrCreate()
val inputfile="D:\\UserBehavior.csv\\processed.csv"
import spark.implicits._
//用户行为信息统计
val UserBehaviorDF=sc.textFile(inputfile).map(_.split(",")).map(attributes=>Info(attributes(0).trim.toInt,attributes(1).trim.toInt,attributes(2),attributes(3))).toDF()
val UserBehaviorCount=UserBehaviorDF.groupBy("action").count()
val result1=UserBehaviorCount.toJSON.collectAsList().toString
val writer1=new PrintWriter(new File("D:\\Json\\result1.json"))
writer1.write(result1)
writer1.close()
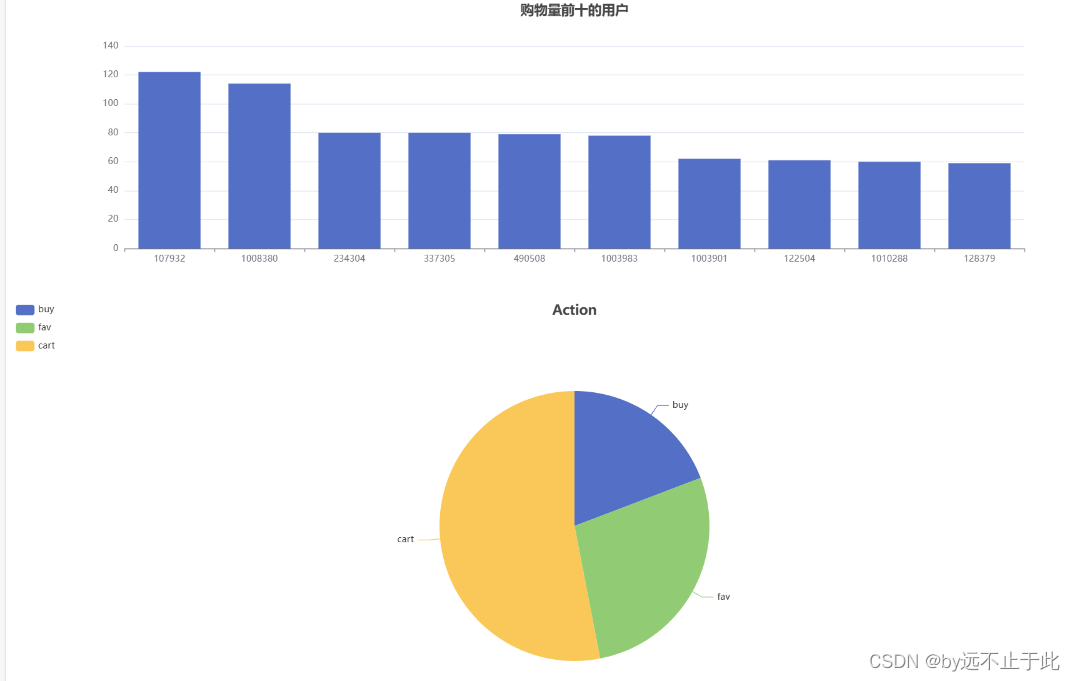
//购物数量前十的用户
val userBehavior_top10=UserBehaviorDF.filter(UserBehaviorDF("action")==="buy").select(UserBehaviorDF("userId")).rdd.map(v=>(v(0).toString,1)).reduceByKey(_+_).sortBy(_._2,false).take(10)
val result2=sc.parallelize(userBehavior_top10).toDF().toJSON.collectAsList().toString
val writer2=new PrintWriter(new File("D:\\Json\\result2.json"))
writer2.write(result2)
writer2.close()
//销量前十的商品
val item_top10=UserBehaviorDF.filter(UserBehaviorDF("action")==="buy").select(UserBehaviorDF("itemId")).rdd.map(v=>(v(0).toString,1)).reduceByKey(_+_).sortBy(_._2,false).take(10)
val result3=sc.parallelize(item_top10).toDF().toJSON.collectAsList().toString
val writer3=new PrintWriter(new File("D:\\Json\\result3.json"))
writer3.write(result3)
writer3.close()
//时间段平台销量统计
val buy_order_by_date=UserBehaviorDF.filter(UserBehaviorDF("action")==="buy").select(UserBehaviorDF("time")).rdd.map(v=>(v.toString().replace("[","").replace("]","").split(" ")(0),1)).reduceByKey(_+_).sortBy(_._1).collect()
val result4=sc.parallelize(buy_order_by_date).toDF().toJSON.collectAsList().toString
val writer4=new PrintWriter(new File("D:\\Json\\result4.json"))
writer4.write(result4)
writer4.close()
sc.stop()
}
}
四,数据可视化
使用flask和echarts进行数据可视化
from flask import Flask, render_template
import json
import jinja2
app = Flask(__name__)
with open("D:\\Json\\result1.json",'r') as file1:
data = json.load(file1)
with open("D:\\Json\\result2.json") as file2:
data2 = json.load(file2)
with open("D:\\Json\\result3.json") as file3:
data3 = json.load(file3)
with open("D:\\Json\\result4.json") as file4:
data4 = json.load(file4)
@app.route('/')
def index():
# 将数据转换为ECharts饼图所需格式
series_data1 = [{'name': item['action'], 'value': item['count']} for item in data]
series_data2 = [{'name': item['_1'], 'value': item['_2']} for item in data2]
categries_data2=[ item["_1"] for item in data2]
series_data3 = [{'name':item['_1'],"value":item['_2'] }for item in data3]
categries_data3 = [item["_1"] for item in data3]
series_data4 = [{'name': item['_1'], 'value': item['_2']} for item in data4]
categries_data4=[item["_1"] for item in data4]
# 将数据传递给模板
return render_template('demo.html',series_data1=series_data1, series_data2=series_data2, categries_data2=categries_data2,series_data3=series_data3, categries_data3=categries_data3,categries_data4=categries_data4,series_data4=series_data4)
if __name__ == '__main__':
app.run(debug=True)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>淘宝数据可视化</title>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/echarts.min.js"></script>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
</head>
<body>
<h1 align="center">Spark淘宝数据分析可视化图表</h1>
<div class="empty"></div>
<div class="contain">
<div id="box1" style="width: 1500px;height:400px"></div>
<div id="box2" style="width: 1500px;height:600px"></div>
<div id="box3" style="width: 1500px;height:400px"></div>
<div id="box4" style="width: 1500px;height:600px"></div>
</div>
<script type="text/javascript">
var myChart1 = echarts.init(document.getElementById('box1'))
var option = {
title: {
text: "购物量前十的用户",
left: 'center'
},
tooltip: {},
xAxis: {
type: 'category',
data:{{ categries_data2|tojson }}
},
yAxis: { type:"value"},
series: [
{
data: {{ series_data2|tojson }},
type: 'bar'
}
]
};
myChart1.setOption(option)
</script>
<script type="text/javascript">
var myChart2 = echarts.init(document.getElementById('box2'))
option2 = {
title: {
text: "Action",
left: 'center'
},
tooltip: {
trigger: 'item'
},
legend: {
orient: 'vertical',
left:""
},
series: [
{
name: 'Access From',
type: 'pie',
radius: '60%',
data: {{ series_data1|tojson}},
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
myChart2.setOption(option2)
</script>
<script type="text/javascript">
var myChart3 = echarts.init(document.getElementById('box3'))
var option3 = {
title: {
text: "商品销量前十",
left: 'center'
},
tooltip: {},
xAxis: {
type: 'category',
data:{{ categries_data3|tojson }}
},
yAxis: { type:"value"},
series: [
{
data: {{ series_data3|tojson }},
type: 'bar'
}
]
};
myChart3.setOption(option3)
</script>
<script type="text/javascript">
var myChart4 = echarts.init(document.getElementById('box4'))
option4 = {
title: {
text: "11月25日到12月3日平台销量统计",
left: 'center'
},
tooltip: {
trigger: 'item'
},
xAxis: {
type: 'category',
data: {{ categries_data4|tojson }}
},
yAxis: {
type: 'value'
},
series: [
{
data: {{ series_data4|tojson }},
type: 'line'
}
]
};
myChart4.setOption(option4)
</script>
</body>
</html>

本文转载自: https://blog.csdn.net/L666223/article/details/137358766
版权归原作者 by远不止于此 所有, 如有侵权,请联系我们删除。
版权归原作者 by远不止于此 所有, 如有侵权,请联系我们删除。