
9.2.1 Boosting是什么
Boosting是一类算法的统称,翻译成中文为“自适应”算法,它们的主要
特点是使用一组弱分类器通过“迭代更新”的方式构造一个强分类器。在每轮
迭代中会在训练集上产生一个新的弱分类器,然后使用该弱分类器对所有样本
进行分类,从而评估每个样本的重要性。从中文名可以看出来,Boosting算法
的每轮学习都会根据数据调整参数,不断提升模型的准确率。
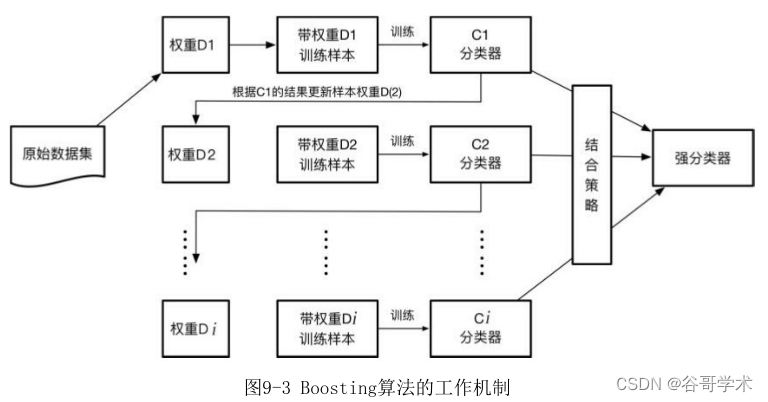
Boosting算法的工作机制如图9-3所示。它首先基于训练样本生成一个弱
学习器,然后基于弱学习器的表现调整样本分布,即增加错误样本的权重,使
其在后续受到更多关注。调整好权重的训练集后,继续生成?一个弱学习器,
不断循环这个过程,直到生成一定数量的弱学习器,最后基于某种结合策略来
综合这多个弱学习器的输出。
这种模式类似于一个放大版的神经网络。还记得在神经网络中,我们需要
预设参数,再根据样本数据训练模型,不断调整参数,最后才能输出结果。在
Boosting 算法中,一个个弱分类器就像不同的神经元,每一次传输就像经过
一层隐藏层,然后层层输出,不断调整参数,最后基于某种策略综合后得到输
出结果。
Boosting算法并没有规定具体的实现方法,但大多数实现算法会有以?特
点:
(1)通过迭代的方式生成多个弱分类器。
(2)将这些弱分类器组合成一个强分类器,通常会根据各个弱分类器的
准确性设置不同的权重。
(3)每生成一个弱分类器,会重新设置训练样本的权重,被错误分类的
样本会增加其权重,正确分类的样本会减少其权重,所以后续生成的分类器将
更多地关注前面分错的样本。
弱分类器训练的目的在于,通过改变样本分布,使得分类器聚集在那些很
难区分的样本上,对容易错分的样本加强学习,增加错分样本的权重。这样做
使得错分的样本在?一轮的迭代中有更大的作用,这也是一种对错分样本的惩
罚机制。这种设计有两个好处,一方面可以根据权重的分布情况,提供数据抽
样的依据;另一方面可以利用权重提升弱分类器的决策能力,使弱分类器也能
达到强分类器的效果。
Boosting算法通过权重投票的方式将N个弱分类器组合成一个强分类器。
只有弱分类器的分类精度高于 50%,才可以将它组合到强分类器里,这种方式
会逐渐降低强分类器的分类误差。但是这个机制也并非最完美的,由于
Boosting 算法将注意力集中在难分的样本上,这使得它对训练集的噪声点非
常敏感,把主要的精力都集中在噪声样本上,从而影响最终的分类性能,也容
易造成过拟合现象。
因此关于 Boosting 算法,有两个值得深入探讨的地方:一是在每一轮迭
代中如何改变训练数据的分布情况;二是如何将多个弱分类器组合成一个强分
类器。使用的学习策略不同,算法的效果也不相同。
。
9.2.2 AdaBoost如何增强
在1995年,弗洛因德(Yoav Freund)教授与夏皮尔教授根据在线分配算
法理论提出了随后风靡一时的AdaBoost算法,这是一种改进版的Boosting分类
算法。由于AdaBoost算法的优异性能,弗洛因德和夏皮尔教授获得了2003年度
的哥德尔奖,该奖是理论计算机科学领域中最负盛名的奖项之一。
AdaBoost是Adaptive Boosting的缩写,中文意思为“自适应增强”。这
个算法的“增强”体现在它设置了两种权重:一种是数据的权重;另一种是弱
分类器的权重。数据的权重主要用于弱分类器寻找其分类误差最小的决策点,
找到之后用这个最小误差计算出该弱分类器的权重,表示该分类器的“发言
权”,分类器权重越大说明该弱分类器在最终决策时拥有越大的发言权。在前
一个弱分类器中被错误分类的样本的权重会增大,而正确分类的样本的权重会
减小,并再次用来训练?一个基本分类器。同时,在每一轮迭代中,加入一个
新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭
代次数,从而确定最终的强分类器。
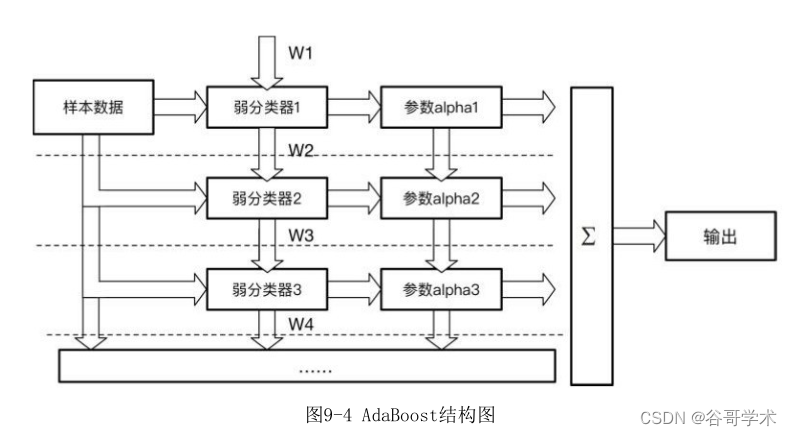
AdaBoost 分类器的整体结构如图 9-4 所示,图中的虚线表示不同轮次的
迭代效果。第1次迭代时,只有第1行结构;第2次迭代时,包括第1行与第2行
的结构。每次迭代都增加一行结构,不断迭代这个过程直至所有弱分类器训练
完?。
在这个迭代过程中,每一轮迭代都需要经过以?几个步骤:
(1)新增一个弱分类器(i)并且赋予弱分类器一个权重值alpha(i)。
(2)通过样本数据集与数据权重W(i)训练弱分类器(i),并得出其分类错
误率,以此计算出这个弱分类器的权重alpha(i)。
(3)通过加权投票表决的方式,让所有弱分类器进行加权投票表决得到
最终预测输出,计算最终分类错误率。如果最终错误率低于设定阈值(比如
5%),迭代结束;如果最终错误率高于设定阈值,则更新数据权重得到
W(i+1)。上述步骤如图9-4所示。
?面举一个直观的例子让大家感受一?AdaBoost算法的分类过程。如图9-
5所示,图中两种符号代表正负两类数据,目前的样本分布为D1,我们开始训
练模型。

第一步采用弱分类器W1对样本数据分类。根据这次分类的正确性,得到一
个新的样本分布D2,如图9-6所示。其中画圈的样本是被分错的,在右边的图
中,比较大的“+”表示对该样本做了加权,?一轮分类时会“重点照顾”这
些样本,同时赋予弱分类器W1一个权值。图中的 ε1=0.3,表示错误率;
α1=0.42,表示该分类器的权重,α1=1/2*ln((1- ε1)/ ε1)。

第二步采用弱分类器W2对样本数据进行分类,根据这次分类的正确性,再
得到一个新的样本分布D3,同时更新W2的权值,如图9-7所示。

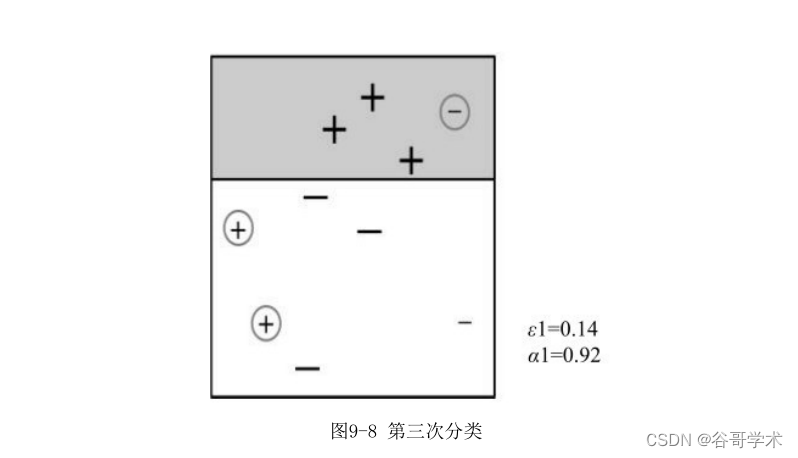
第三步采用弱分类器W3对样本数据进行分类,根据这次分类的正确性,再
得到一个新的样本分布D4,同时更新W3的权值,如图9-8所示。
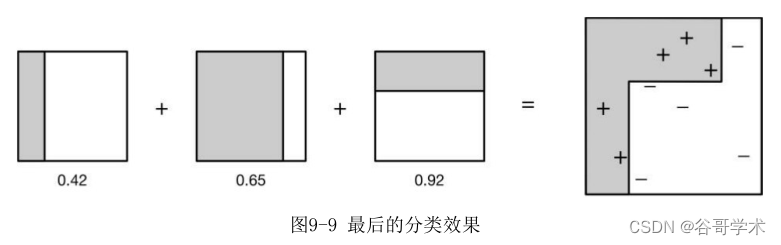
最后我们整合三个分类情况。同时根据三个分类器的权值采用加权的方式
计算结果,最后的分类效果如图9-9所示,从结果看,即使简单的分类器,将
它们组合起来也能获得很好的分类效果。
相比普通的 Boosting 算法,AdaBoost 能够自适应地调整弱学习算法的
错误率,经过若干次迭代后使得错误率达到预期的大小 。同时它也不需要知
道精确的样本空间分布,在每次学习后调整样本空间分布;更新所有训练样本
的权重——将样本空间中正确分类的样本权重降低,提高错误分类的样本权
重;?次学习时分类器才会关注这些错误分类的样本,提升?轮分对的概率。
如果还没有分对,那么继续增加错分点的权重,一直重复这个过程,直到模型
运行结束。
AdaBoost 算法最大的优点在于,它不需要预先知道弱分类器的错误率上
限,最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,所以具
有深挖分类器的能力。同时它可以根据弱分类器的反馈,自适应地调整假定的
错误率,执行效率高。并且AdaBoost提供一种框架,在框架内可以使用各种方
法构建子分类器,不用对特征进行筛选,也不存在过拟合的现象。在理论上任
何学习器都可以用于AdaBoost算法。但在实际项目中,使用最广泛的AdaBoost
弱学习器是决策树和神经网络,因为它们可以很容易地应用到实际问题中,目
前已成为最流行的Boosting算法。
AdaBoost算法并非没有缺点,在AdaBoost训练过程中,它会使得难于分类
的样本的权值呈指数增长,训练会过于偏向这类样本,导致算法易受“噪
声”干扰。这一点是我们在使用过程中值得注意的地方。
9.2.3 梯度下降与决策树集成
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法是近
年来受到大家广泛关注的一个算法,这主要得益于该算法的优异性能,以及该
算法在各类数据挖掘与机器学习比赛中的卓越表现。
GBDT算法也是Boosting家族的重要成员,它是Gradient Boosting的其中
一个方法。GBDT实际上结合了梯度?降、决策树两种方法的优点,再采用集成
的方式训练模型,从而得到更优的结果。以往单独使用决策树算法时,很容易
产生过拟合现象。而通过梯度提升的方法集成多个决策树,能够有效解决过拟
合的问题。由此可见,梯度提升方法和决策树学习算法可以互相取长补短,发
挥1+1>2的价值。
GBDT算法的结构如图9-10所示。GBDT通过多轮迭代,每轮迭代产生一个弱
分类器,每个分类器在上一轮分类器的?差基础上进行训练。一般选择分类回
归树作为弱分类器,且这棵树必须满足低方差和高偏差的特点。因为 GBDT 的
训练过程是通过降低偏差使得分类器的精度升高的。同时也因为高偏差和简单
的要求,每个分类回归树的深度不会很深。最终的总分类器是将每轮训练得到
的弱分类器加权求和得到的。由于模型中的弱学习器采用分类回归树,因此这
个模型可以解决回归问题或分类问题。

GBDT的主要思想是:每一次建立单个学习器时,基于以往已建立模型的损
失函数的梯度?降方向优化。我们都知道损失函数越大,模型越容易出错。如
果我们的模型能够让损失函数持续?降,则说明我们的模型在不停地往好的方
向改进。而最好的?降方式就是让损失函数在其梯度的方向?降。
我们用一个形象的例子说明。假设小李忘记了每个月自己手机流量有多
少,他想通过自己的使用情况测试总量。于是第一轮他?载了一部360MB的电
影,发现还有流量;第二轮?载了一部120MB的短片,发现还有流量;第三轮
他又?载了一本20MB的小说,发现流量终于用完了。如果此时还没有得出结
果,则可以继续迭代。每一轮迭代,都会往结果?近一步,最终加权所有的结
果就能够得出流量总共有 500MB,这就是GBDT的工作方式。
再用一个例子说明GBDT和传统决策树之间的区别。以选房为例,假设A、
B、C、D是在市区内的四套房子,面积分别是70、80、120、130平方米。其中
A、B房子距离地铁站都在500米以内,C、D房子则距离地铁站比较远。A、C房
子都在13楼以上,B、D 房子都在 13 楼以?。如果用一棵传统的回归决策树
帮助我们选房,结果如图9-11所示。

现在我们使用 GBDT 算法来选房。由于数据太少,我们限定叶子节点最多
有两个,即每棵树都只有一个分支,并且限定只生成两棵树,这样能够得到如
图 9-12 所示结果。

第一棵树分支如上图所示,首先还是将A、B分为一类,C、D分为一类。然
后用平均面积作为预测值,分别计算每个结果的?差,A 的?差为:70-
75=-5。此处需要注意,A的预测值是指前面所有树累加的和,在这个例子中只
有一棵树,所以结果直接为75。如果前面还有树,则需要都累加起来作为A的
预测值。
同理可得A、B、C、D的?差分别为-5、5、-5、5。在第二轮迭代时,我们
拿上一轮得到的?差替代 A、B、C、D 原有的值。如果预测值和它们的?差相
等,只需把第二棵树的结果累加到第一棵树上就能得到真实的房屋面积了。第
二棵树有两个值5和-5,直接分成两个节点。此时所有房子面积的?差都是0,
即每间房子面积的真实值都被预测出来了。
从上述例子可以看出 GBDT 算法与决策树的区别,虽然两者最后得到的结
果相同,但是决策树算法使用了三个特征,GBDT算法只使用了两个特征。在实
际项目中, GBDT可能只使用10个特征就能够拟合出决策树使用30个特征的效
果。在面对新数据时,显然使用特征更少的算法产生过拟合现象的概率更低。
并且 GBDT 算法不是简单的一刀切,而是通过不断减小误差的方法逐渐?近真
实值,能够获得更精确的预测结果。因其优异的性能,GBDT目前被广泛用于欺
诈检测、交易风险评估、搜索结果排序、文本信息处理、信息流排序等领域。
版权归原作者 谷哥-Mr.Gu 所有, 如有侵权,请联系我们删除。