
环境说明:
flink 1.15.2
mysql 版本5.7 注意:需要开启binlog,因为增量同步是基于binlog捕获数据
windows11 IDEA 本地运行
先上官网使用说明和案例:MySQL CDC Connector — Flink CDC documentation
- mysql开启binlog (注意,引擎是 InnoDB,如果是ndbcluster,本人测试是捕获不到binlog日志的,增量相当于没用,不知道是不是ndbcluster 下的binlog 配置是否有问题,但是同一集群下,InnoDB的表就可以捕获到binlog日志。听朋友说,ndbcluster 是内存型引擎,有可能不会实时写日志到磁盘,所以捕获不到.....)
判断MySQL是否已经开启binlog on 为打开状态
SHOW VARIABLES LIKE 'log_bin';
查看MySQL的binlog模式
show global variables like "binlog%";
查看日志开启状态
show variables like 'log_%';
刷新log日志,立刻产生一个新编号的binlog日志文件,跟重启一个效果
flush logs;
清空所有binlog日志
reset master;
- 创建一个用户,赋权
CREATE USER 'flink_cdc_user'@'%' IDENTIFIED BY 'flink@cdc';
GRANT ALL PRIVILEGES ON . TO 'flink_cdc_user'@'%';
- maven依赖:
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.15.2</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
<!-- 此标签会移除jar包,当需要打包到集群运行时加上此标签-->
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.ververica/flink-sql-connector-mysql-cdc -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<version>2.3.0</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>1.15.2</version>
<!--<scope>provided</scope>-->
<!--此标签会移除jar包,当需要打包到集群运行时加上此标签-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
</dependencies>
- 若是打包到集群运行,相关依赖要放开 provided,这样就不会把依赖打入到jar包里面,就不会和flink lib里面的jar包冲突。
lib 里面需要加入的包:从官网下载,放入即可
flink-connector-jdbc-1.15.4.jar
flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
flink-sql-connector-mysql-cdc-2.3.0.jar
mysql-connector-java-8.0.29.jar
commons-cli-1.5.0.jar
5.mysql建表如下:
#mysql建表:
CREATE TABLE
user(
idint(11) NOT NULL,
usernamevarchar(255) DEFAULT NULL,
passwordvarchar(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE
user_sink(
idint(11) NOT NULL,
usernamevarchar(255) DEFAULT NULL,
passwordvarchar(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
6.测试demo如下:
package com.xgg.flink.stream.sql;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class MysqlToMysqlHavePrimaryKey {
public static void main(String[] args) {
//1.获取stream的执行环境
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
String sourceTable = "CREATE TABLE mysql_cdc_source (" +
" id INT,\n" +
" username STRING,\n" +
" password STRING,\n" +
"PRIMARY KEY(id) NOT ENFORCED\n" +
") WITH (\n" +
"'connector' = 'mysql-cdc',\n" +
"'hostname' = 'localhost',\n" +
"'port' = '3306',\n" +
"'username' = 'root',\n" +
"'password' = 'root',\n" +
"'database-name' = 'test_cdc',\n" +
"'debezium.snapshot.mode' = 'initial',\n" +
"'table-name' = 'user'\n" +
")";
tEnv.executeSql(sourceTable);
String sinkTable = "CREATE TABLE mysql_cdc_sink (" +
" id INT,\n" +
" username STRING,\n" +
" password STRING,\n" +
"PRIMARY KEY(id) NOT ENFORCED\n" +
") WITH (\n" +
"'connector' = 'jdbc',\n" +
"'driver' = 'com.mysql.cj.jdbc.Driver',\n" +
"'url' = 'jdbc:mysql://localhost:3306/test_cdc?rewriteBatchedStatements=true',\n" +
"'username' = 'root',\n" +
"'password' = 'root',\n" +
"'table-name' = 'user_sink'\n" +
")";
tEnv.executeSql(sinkTable);
tEnv.executeSql("insert into mysql_cdc_sink select id,username,password from mysql_cdc_source");
tEnv.executeSql("select * from mysql_cdc_source").print();
}
}
源表进行操作,flink cdc 捕获操作记录进行打印,然后插入到表中。(mysql的cdc可以一边打印,一边写表,无问题。oracle的cdc,如果有多个执行操作,就会只执行一个,比如,先打印再写表,oracle只能打印,写表操作就不会触发。如果不打印,只写表,那就没问题。好像和senv.setParallelism(1);没关系,应该还是底层实现的问题。)
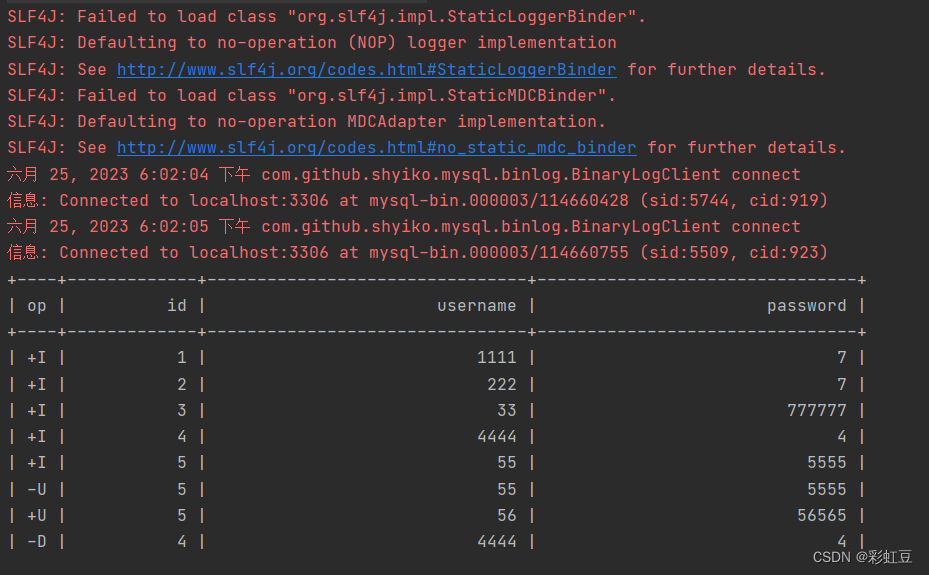
user 源表和目标表 user_sink,数据都如下。
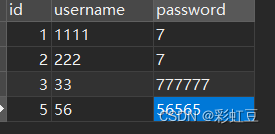
源表和目标表都是在Mysql有主键的,所以找个参数虽然是初始化操作,后面插入也是 insert into ,但是不管执行多少遍,都不会有重复的数据。
"'debezium.snapshot.mode' = 'initial',\n" +
?rewriteBatchedStatements=true 这个参数是开启批量写,能加大写速度。
版权归原作者 彩虹豆 所有, 如有侵权,请联系我们删除。