
HTTP
概述
HTTP协议,相当于是对前面的网络协议做进一步的补充。
- HTTP 协议大概率是我们日后开发中用的最多的协议。
- HTTP 处于 TCP / IP 五层协议栈中的 应用层 。
- HTTP 在传输层是基于 TCP的。最新的 HTTP3 是基于 UDP 实现的。
- HTTP 是设计好的协议,但是自身的可扩展性很强,可以根据自身需要,去传输各种自定义的数据信息。
协议
HTTP 是一个 文本格式的协议。通过 抓包工具 来看到报文格式
抓包工具
抓包工具,其实就是一个第三方程序。在这个网络通信的过程中,类似于“代理”,举个例子:
假设我女朋友想喝奶茶,她有两种方法喝到奶茶:1、自己去买。2、我帮他去买。第二种方法就是一种代理。
就像着这个例子: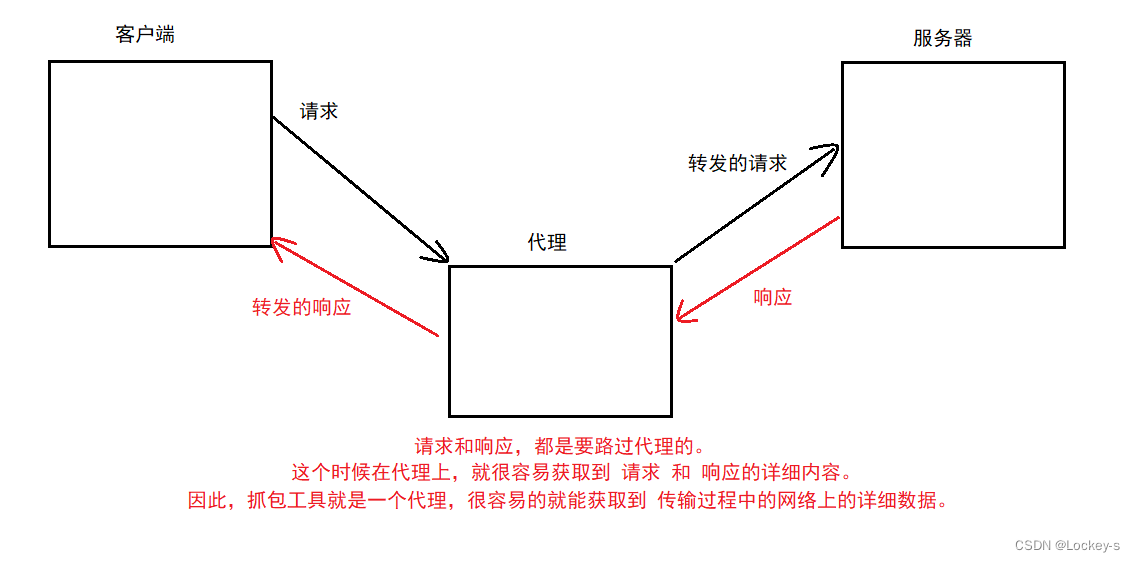
我们这里使用 fiddler 来抓包。fiddler 是一个专门抓 HTTP 包的软件。
在安装完之后,需要设置一下,就可以抓 HTTPS 的包了: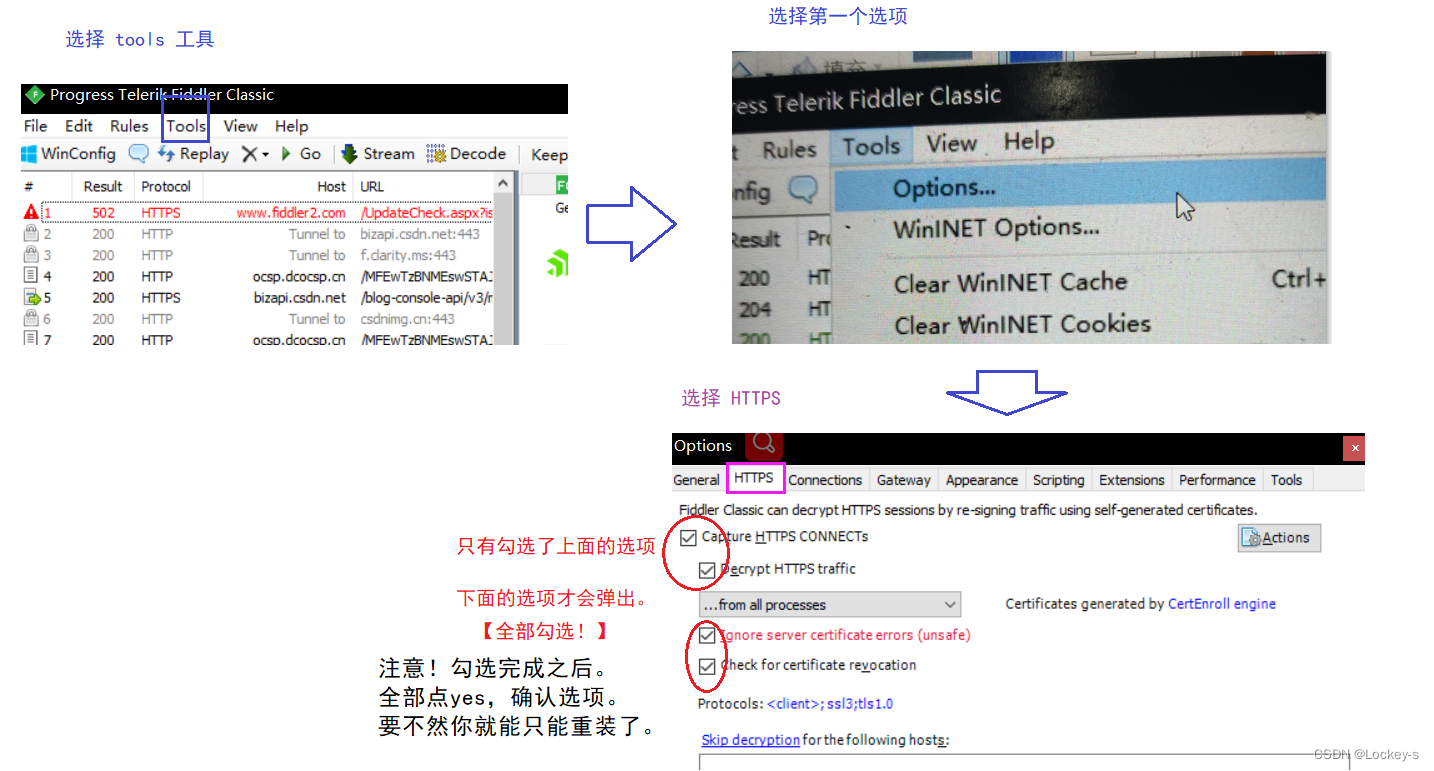
关于抓包工具:
打开抓包工具之后,随便刷新一下页面就可以看到好多信息了: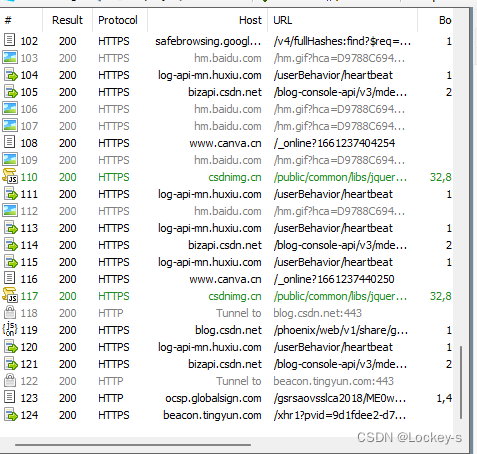
然后选中之后,双击就可以发现被分为两部分: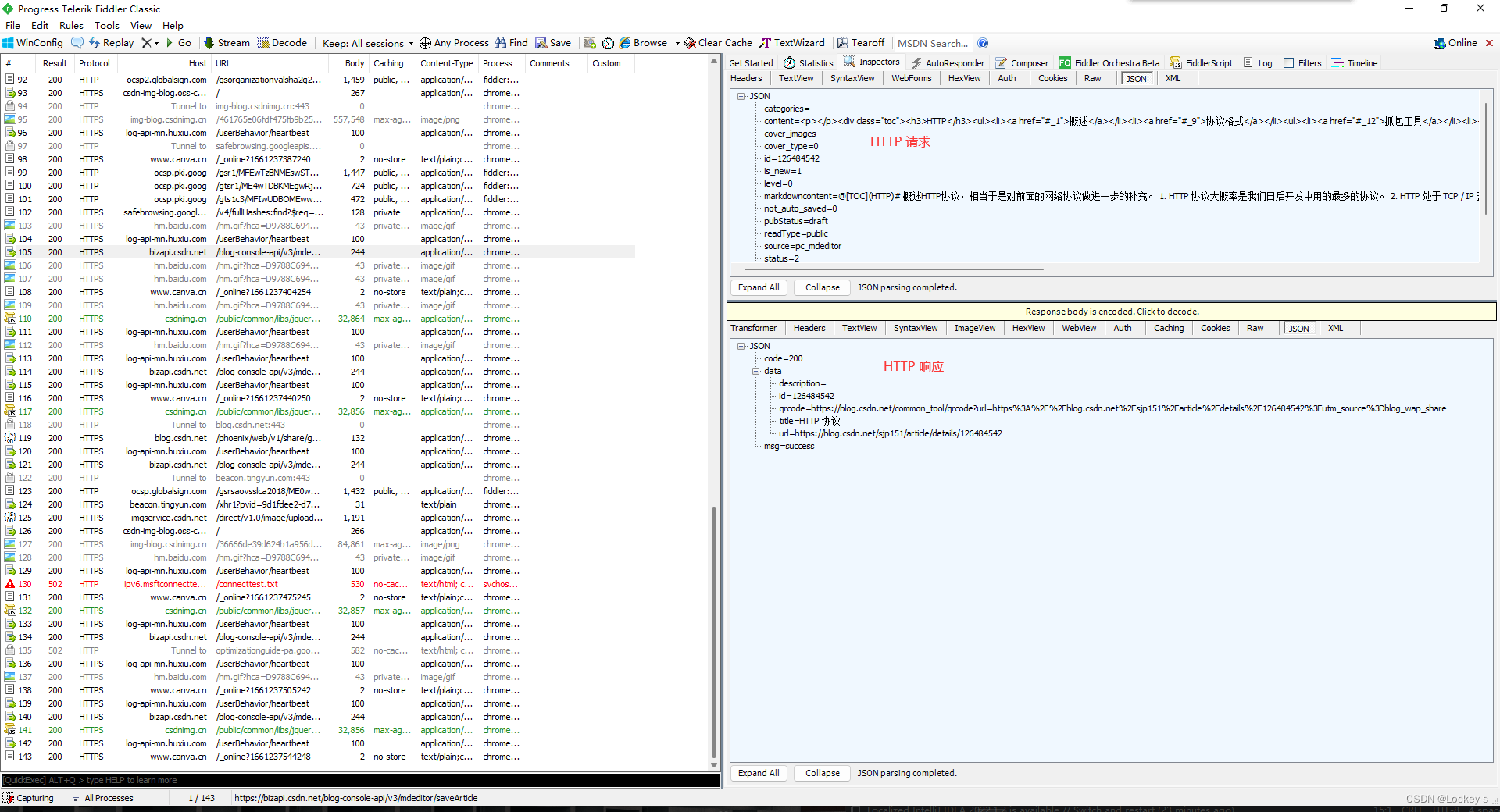
上面的部分就是 HTTP 请求,下面的部分就是 HTTP 响应。
上面这里就表示了以什么样的格式显示 HTTP 请求,用的最多的就是 Raw ,来查看原始请求。其它的选项,就相当于 fiddler 对数据进行了加工
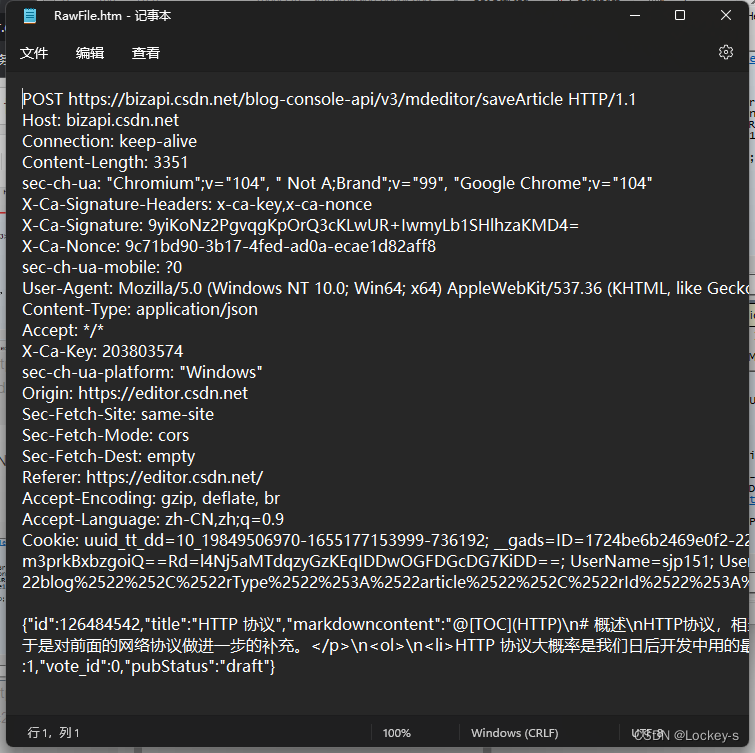
然后就可以通过 View in Notepad 来使用电脑的记事本来打开了:
响应部分,也是看 Raw 就可以了,但是如果是乱码的话: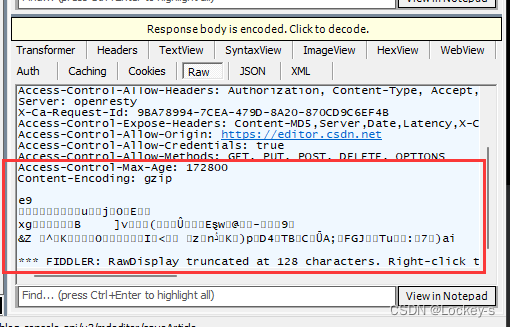
这就是把响应压缩了,点击上面的 黄色背景的部分就可以解压缩了。
协议格式
我们对照请求响应图来更好的了解: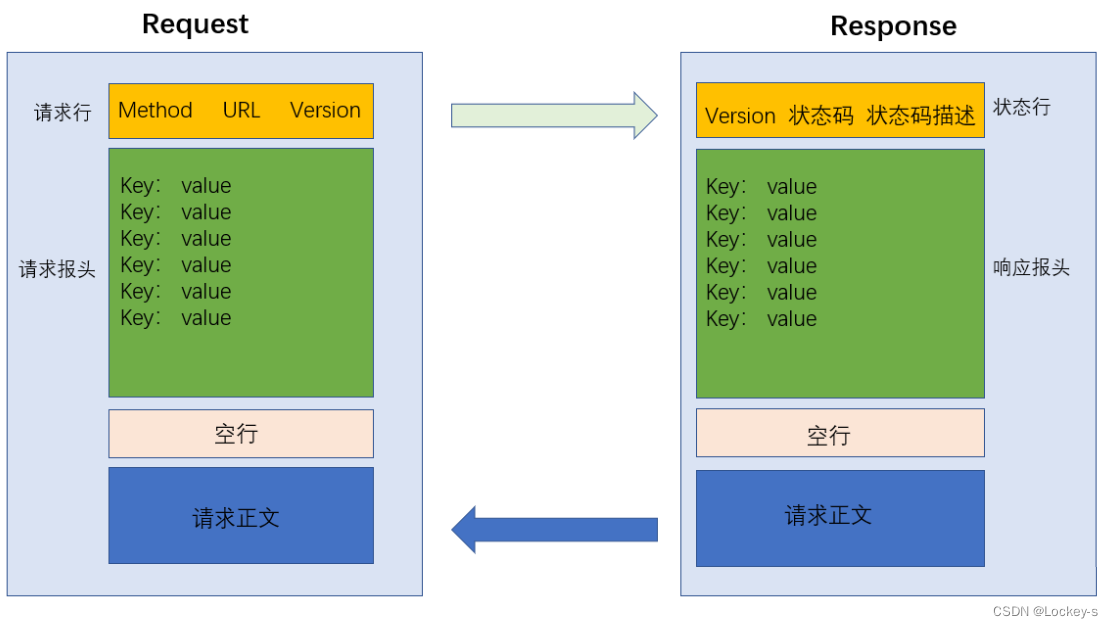
请求部分
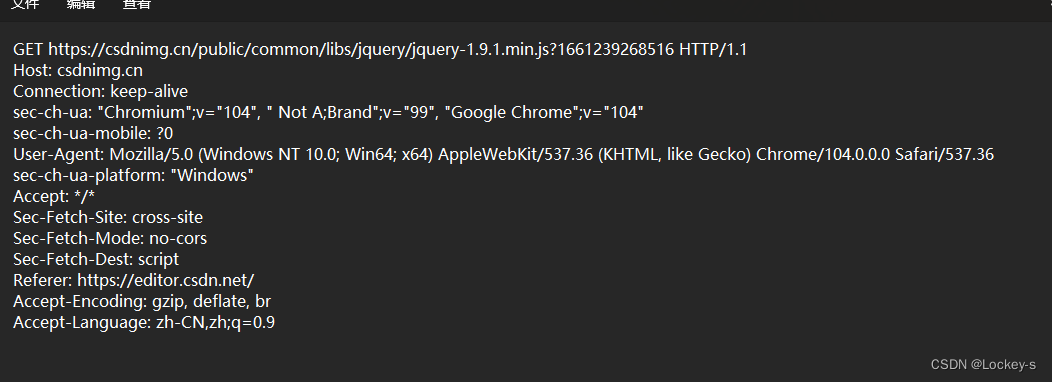
请求分为四个部分:
- 请求行: a)HTTP 的方法,描述请求想干啥。GET 就是想从服务器获取到某个东西。 b)URL,描述了要访问得到网络上的资源具体在哪儿。 c)版本号,HTTP/1.1 表示当前使用的 HTTP 版本号是 1.1。1.1 是当下最主流的版本。
- 请求头,包含了很多行: a)每一行都是一个键值对,键和值之间使用 :空格 来分割。 b)键值对的个数是不确定的,不同的键值对,表示的含义是不一样的。
- 空行:相当于请求的结束标志。
- 请求正文(body):可选的,有的有,有的没有。空行后面的就是正文。
响应部分
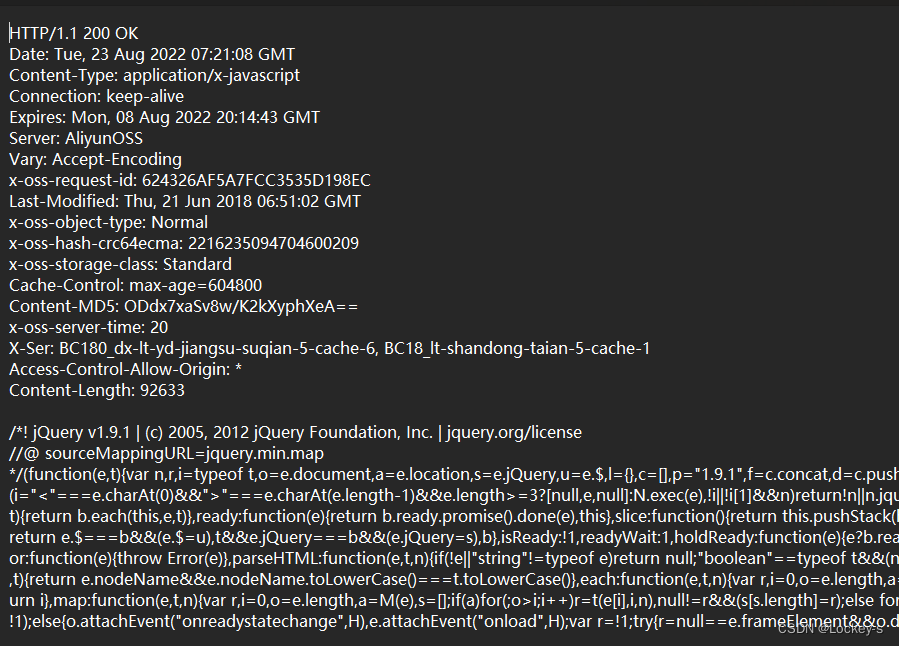
响应也是分为四个部分:
- 首行:包含了 3 个部分: a)版本号:HTTP/1.1 b)200:状态码,描述了这个响应,是一个表示 ”成功“ 还是 ”失败“ ,以及其他不同的状态码,描述了失败的原因。 c)200:状态码描述,通过 一个/一组 简单的单词,来描述当前的状态码的含义。
- 响应头:也是键值对结构,每个键值对占一行,每个键值对之间使用 : 和 空格 来分割。响应头当中的键值对个数,也是不确定的,不同的键值对表示不同的含义。
- 空行:表示响应头的结束
- 响应正文:就是服务器返回给客户端的具体数据。内容可能有各种格式,最常见的就是 HTML。
请求详解
URL
URL - Uniform Resource Locator:全球资源定位器。也就是网络唯一资源的地址符。像下面这里就是 URL: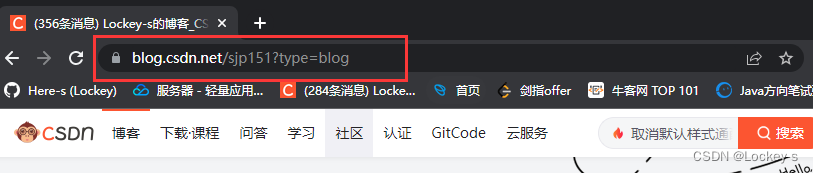
URL 都要遵守一个基本模板:
- 协议方案名,就是描述了这个 URL 是给哪个协议来使用的。
- 登录信息,现在不用了,以前会用。
- 服务器地址。就是当前要访问的主机是啥,可以是 IP 地址,也可以是 域名。
- 端口号,就是表示当前要访问的主机上的哪个应用程序。大部分情况下,端口号都是会省略的。省略的时候,浏览器会自动加一个端口号。
- 文件路径,描述了当前要访问的服务器资源是啥。
通过这些 IP 地址,端口,带层次的文件路径,就描述了一个网络上具体的资源。
- 查询字符串,本质上是 浏览器/客户端 给服务器传送的自定义信息,相当于对获取到的资源提出了进一步的要求。
- 片段标识符,描述了要访问当前 HTML 页面中哪个具体的子部分,能够克制浏览器滚动到相关的位置。
URL 的 encode/decode
当 query string 中如果包含了特殊字符,就需要对特殊字符进行转义。转义的过程就叫做 URLencode,反之,把转义后的内容还原回来,就叫做URLdecode。
因为一个 URL 里面是有很多特殊的含义的符号的:/ : ? & = …这些符号都是在 URL中具有特定含义的。万一,queryString 里面也包含这类特殊符号,就可能导致 URL 被解析失败!所以要进行 encode。
方法
GET POST 都是方法。HTTP 方法很多,常用的就是 GET / POST 方法: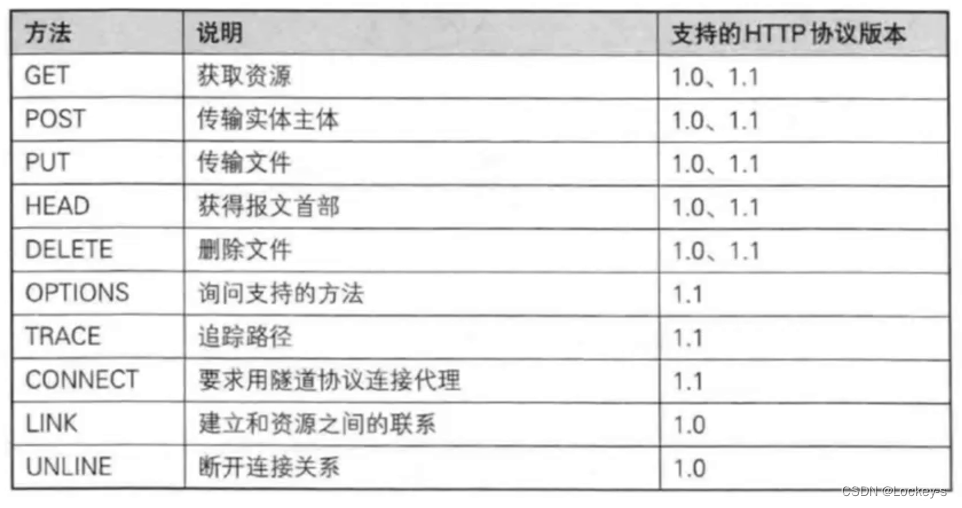
GET 和 POST 的区别:
GET 和 POST 没有本质区别。具体来说,相当于是 GET 使用的场景,也能换成 POST。POST 使用的场景,也能换成 GET。但是细节上还是有区别的:
a)GET 通常用来取数据。POST 通常用来上传数据。
b)通常情况下,GET 没有 body,GET 是通过 query string 向服务器传递数据的。通常情况下,POST 是有 body 的,通过 body 向服务器传递数据。
c)GET 请求一般是幂等(每次相同的输入,得到的输出结果是确定的)的,POST 请求一般是不幂等(每次相同的输入,得到的结果是不确定的)的。
d)GET 可以被缓存,POST 不能被缓存。
请求的报头
Host
就是服务器主机的地址和端口,就像 GitHub 这样的 Host 就是这样:
https://github.com/
Content-Length && ContentType
这两个属性都是在描述 body
- Content-Length:表示 body 中的数据长度.
- Content-Type:表示请求的 body 中的数据格式
我们从 fiddler 里面打开一个 csdn 的包,就能找到这两个: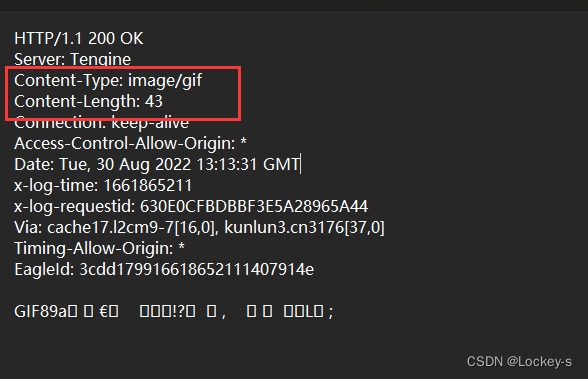
在登录的时候,大多数是使用 POST 进行的,因为使用 POST 登录的时候,用户名和密码是不能直接看到的。
关于 Content-length,HTTP 也是基于 TCP 协议的,TCP 是面向字节流,有粘包问题,所以这里也有,就可以通过下面这两种方法来解决:
- 使用分隔符
- 使用长度
User-Agent
这里表示的是,当前用户是拿一个什么样的东西来上网。我们找一个 fiddle 里面的包来看: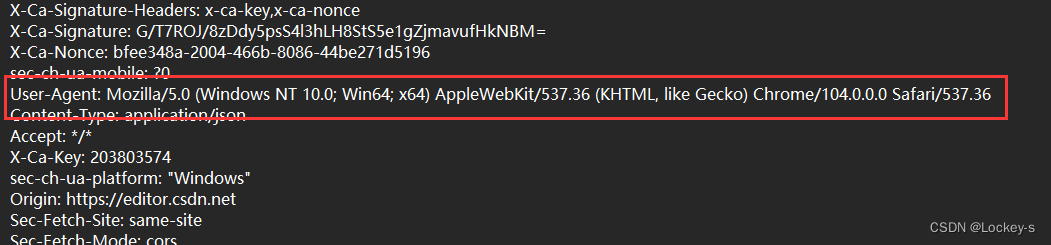
就是表示,在 win10,64位,chrome 浏览器来上网。现在 User-Agent 的作用,更多的是用来区别电脑和手机。
Referer
表示当前的页面,是从哪里跳过来的。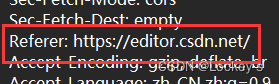
表示当前页面是从 csdn 编辑器转过来的。Referer 的了一个作用就是,可以看到广告的点击跳转从哪里来的。
Cookie
就是浏览器给页面提供的一种纽扣持久化存储数据的机制,就是把数据写在文件里面。最典型的应用场景就是存储当前用户的身份信息,就像我们登录 CSDN 之后,刷新页面,或者重新打开 CSDN 网站,仍然是已登录状态。
具体的组织形式:
- 先按照域名来组织。针对每个域名,分配一个小房间。
- 然后在小房间里面,又会根据 键值对 来组织数据。
在网页链接的前面,有个小锁,点击小锁就会弹出: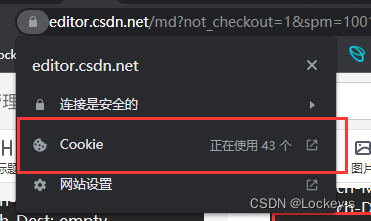
点击之后,就能看到键值对: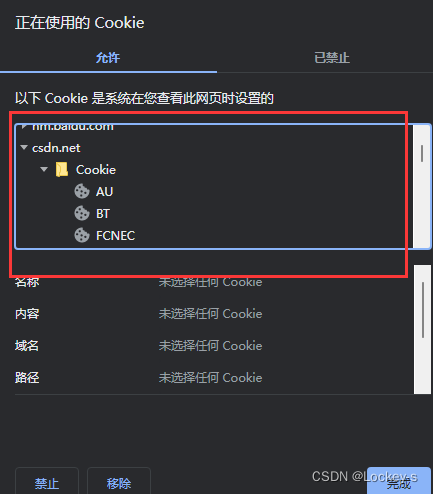
Cookie 的数据是服务器返回给客户端的。Cookie 里面保存的身份信息,就类似于去游乐场,拿着自己办的年卡进去的时候,刷卡的时候,自己的姓名,身份信息就知道了。其他信息,如入园次数,办卡日期都是在服务器上面放着。服务器上面的这些东西,就是 “session”。
Session
就是会话,就像微信消息列表,就相当于是会话列表。聊天记录,就相当于是用户的详细信息。
响应部分
响应的大部分,都和请求是一样的。不同的部分如下
状态码
HTTP 提供的状态码有很多,我们讲最常用到的:
- 200 OK,就是表示浏览器很顺利的就获取到了想要的内容了,没有出现意外。
- 404 Not Found,就是表示访问的资源不存在。
- 403 Forbidden,就是资源存在,但是没有权限访问。
- 405 Method Not Allowed,就是访问方式不允许,比如用 GET 访问只支持 POST 的服务器。
- 500 Internal Server Error,就是指服务器出现了 bug,自己写后台的时候,很容易出现这样的 bug。
- 504 Gateway Timeout,就是服务器太繁忙的意思。
- 302 Move Temporarily,就是重定向。就像是打电话的时候的呼叫转移。
报头
响应报头的格式和请求报头的格式基本一致。像 Content-Type , Content-Length 等属性的含义也和请求中的含义一致。不过响应的 Content-Type 常见取值有这几种:
- text/html : body 数据格式是 HTML
- text/css : body 数据格式是 CSS
- application/javascript : body 数据格式是 JavaScript
- application/json : body 数据格式是 JSON
构造 HTTP 请求
构造 HTTP 请求的时候,有如下两种:
- 基于 HTML/JS 1)基于 form 表单 2)基于 Ajax
- 基于 Java 基于socket
基于 form 表单,构造 HTTP 请求
核心 HTML 标签,就是 form 标签。form 标签里面的 action,就是提交请求的地址是什么。还有就是 method 就是由 GET 请求来提交,还是 POST 请求来提交:
<body><formaction="https://www.csdn.com/"method="get"></form></body>
光有 form 标签,还不能提交,也没有东西提交。还需要搭配 from 里面的一些其他标签,比如 input 之类的。
<body><formaction="https://www.csdn.com/"method="get"><inputtype="text"name="username"><inputtype="password"name="password"><inputtype="submit"value="提交"></form></body>
这里的 username 和 password 就是 form 表单的 键值对。输入信息之后点击就可以跳转了: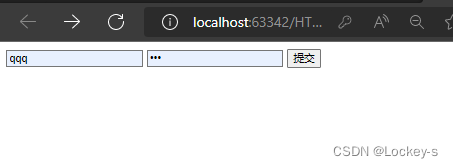
点击提交之后: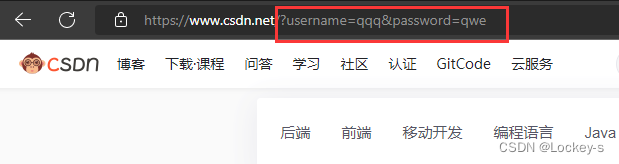
form 是最原始的构造方式,使用 form 一定会跳转页面,会加载全新页面,就会有很大的资源消耗。如果只加载一部分变化的内容,就需要用到 Ajax 了。
基于 Ajax 构造 HTTP 请求
Ajax 就是通过 JS 代码,来构造 HTTP 请求,再通过 JS 代码来处理这里的响应,并且把得到的一些数据更新到页面上面。全名是:
Asynchronous Javascript And XML
,就是:异步 JavaScript 和 XML。
异步等待就相当于是去修电脑,让电脑师傅修好之后给你打电话。就是调用者发起一个调用请求之后,就不管了。得到调用者结果出来之后,再来通知调用着。
Ajax 就是先构造出一个 HTTP 请求发给服务器,然后就执行其他代码,等到服务器的响应回来了,再去执行。
通过 JQuery 来实现 Ajax 请求:
- 先找到 JQuery 代码,百度搜索 JQuery CDN,然后找到能用的就可以了
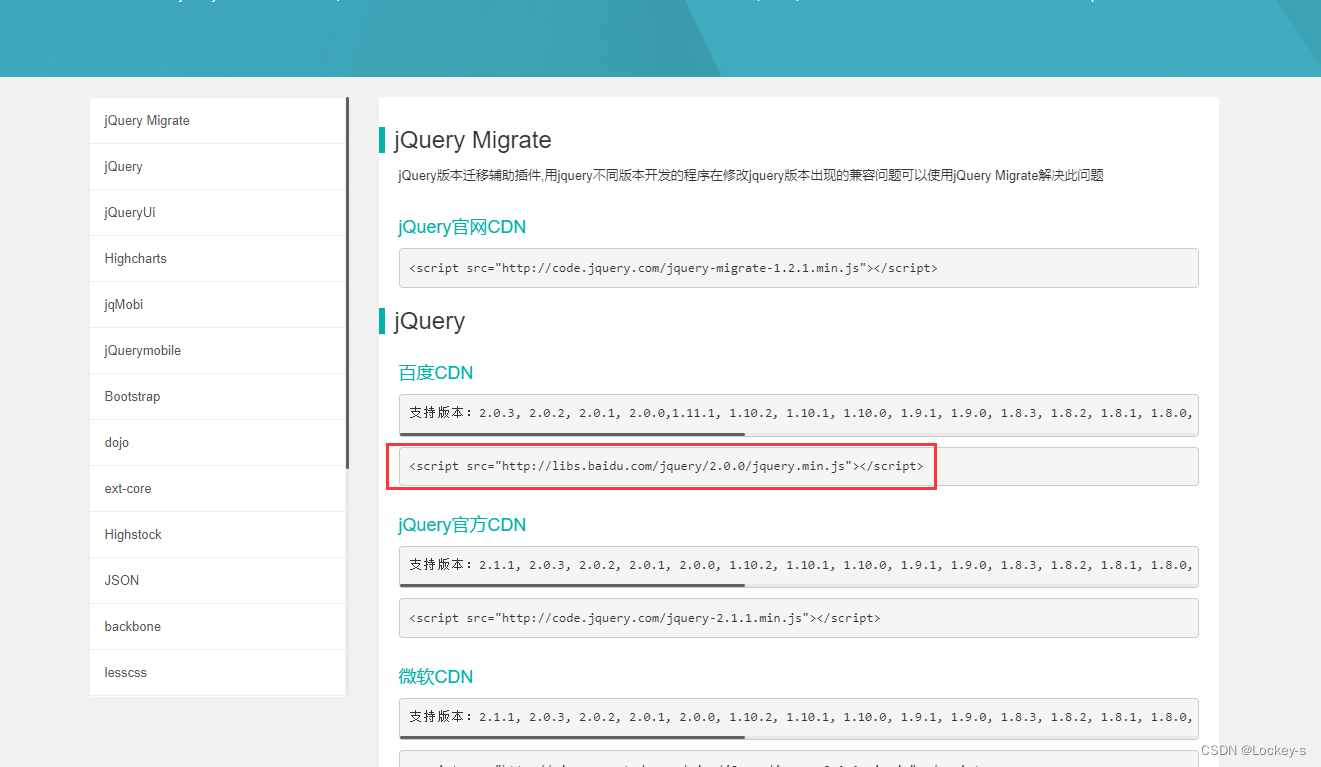
- 然后把链接复制,能打开就行了
- 然后把内容全部复制,项目中新建 JS 文件,然后复制进去就好了。使用 Ajax 的时候,通过 $ 来使用:
<body><scriptsrc="jquery.js"></script><script> $.ajax({});</script></body> - Ajax 的参数只有一个,是一个对象,里面有 type,就是访问类型。url 就是访问地址。success 就是回调函数,服务器返回信息之后,就执行。error 就是获取相应失败执行:
<body><scriptsrc="jquery.js"></script><script> $.ajax({type:'get',url:'https://www.csdn.com/',success:function(body){//响应的回调函数 console.log("获取到响应数据!"+body);},error:function(){//会在请求失败之后调用这个函数 console.log("获取响应失败")}});</script></body>但是浏览器打开之后,却是空白页面,打开控制台发现回调函数执行为 error :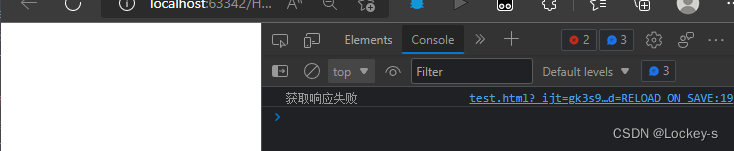 这个原因就是因为跨域访问,浏览器是禁止 Ajax 进行跨域访问的。就是禁止跨越多个域名/服务器。
这个原因就是因为跨域访问,浏览器是禁止 Ajax 进行跨域访问的。就是禁止跨越多个域名/服务器。
HTTPS
HTTPS 相当于 HTTP 的孪生兄弟。就是在 HTTP 的基础上,引入了一个加密层。就是对数据加密,防止 运营商劫持。就像在很多时候,我们在网页上下载软件,下载之后却发现下载下的软件和我们想要的软件不一样。
HTTPS 的工作过程
主要就是读密码进行加密,但是加密之后,也可以破解,但是破解的成本很高。HTTPS 当中引入的加密层,称为 SSL/TLS,主要的加密方式有两种:
- 对称加密:使用同一个密钥,既可以进行加密,也可以进行解密。
- 非对称加密。
对称加密
就像图片这样: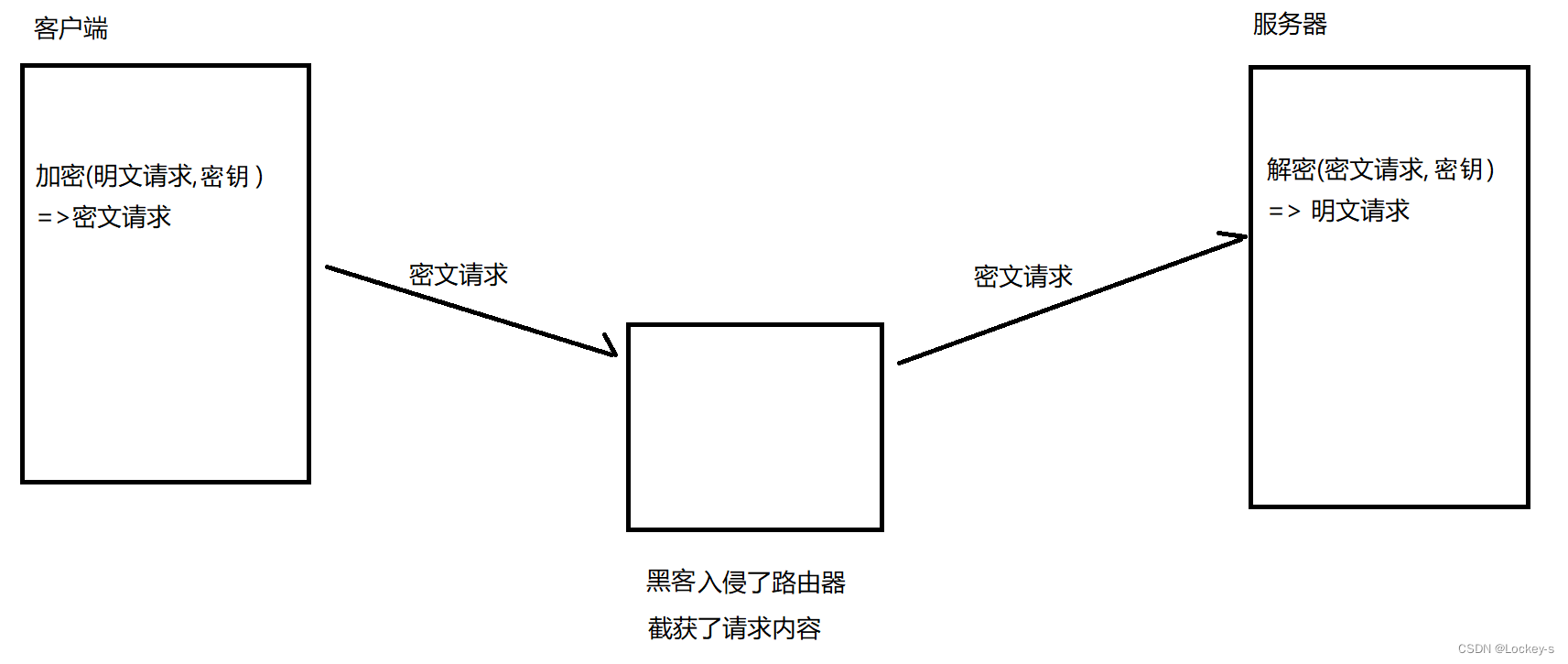
客户端和服务器持有同一个密钥,客户端传输的数据(HTTP 请求的 header 和 body)都通过这个密钥进行加密。然后再网络上传输的就是密文了。服务器在收到密文之后,接下来就可以根据密钥进行解密,拿到明文了。
但是!一个服务器有很多客户端,如果都用同一个密钥的话,那黑客也接入客户端,就把其他客户端都破解了。所以一个客户端对应一个密钥。所以就要么是客户端生成密钥,要么就是服务器生成密钥,然后通过网络传送。我们假设是客户端生成密钥: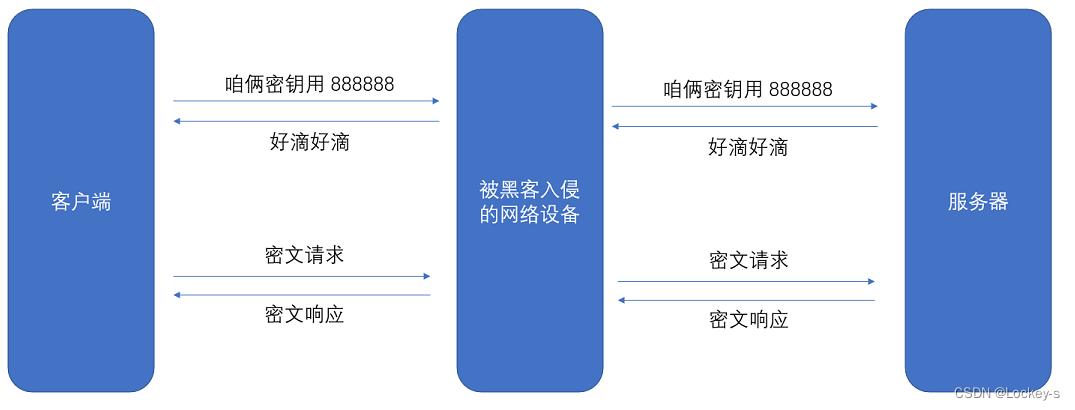
客户端生成密钥,然后再通过网络告诉服务器,但是密钥如果用明文传输,也会让黑客拿到,加密也就没有意义了。所以使用对称加密,最大的问题就是:密钥能传输到服务器,明文传输是不行的,所以必须继续对密钥加密,就成了套娃操作了。所以还得使用 :非对称加密。
非对称加密
非对称加密,有两个密钥:公钥和私钥。公钥:人人都知道。私钥:只有自己才知道。使用公钥加密,私钥解密。或者私钥加密,公钥解密。两者的关系就相当于是支付宝余额,别人都可以给你转钱,但是只有你自己可以取钱。
基于非对称加密,服务器就可以自己生成一对公钥和私钥,公钥人人都能拿到。客户端使用公钥,对数据加密,然后把数据传给服务器,服务器再用私钥解密。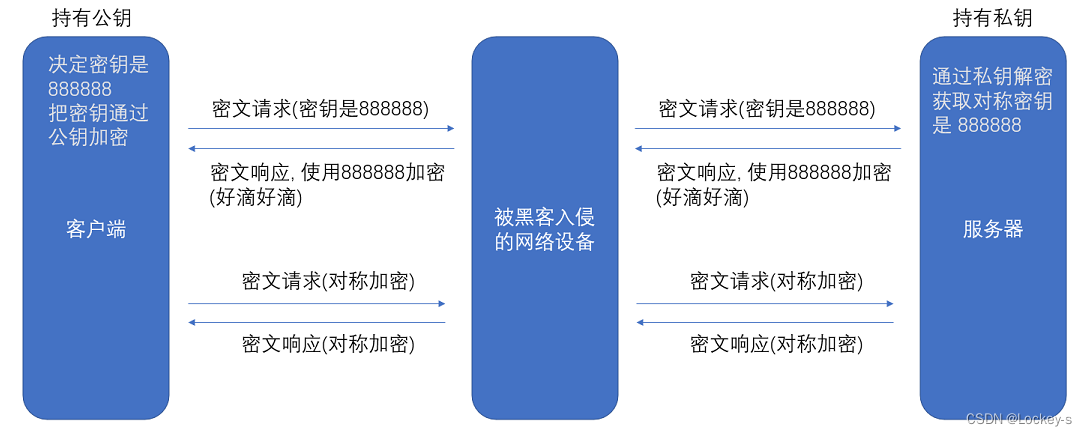
就是服务器持有私钥,然后客户端拿到公钥之后,对生成的对称密钥进行加密,然后再传给服务器,服务器进行解密。但是如果直接用非对称加密进行传输的话,对资源消耗是很高的。非对称加密的资源消耗比对称加密高很多很多。
上面的非对称加密,其实也会受到 “中间人攻击” : 正常情况是这样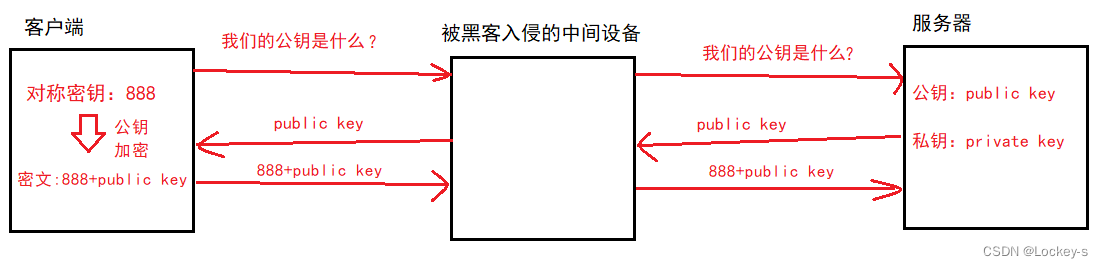
在访问的时候,找服务器要到公钥,黑客没有干预。异常情况如下:
就是客户端刚开始会问服务器要公钥,然后服务器返回公钥和私钥的时候,黑客拦截到服务器的公钥,然后黑客自己也生成一副公钥,私钥。然后把生成的公钥发给客户端。然后客户端加密之后,把密文发出去的时候,黑客在进行解密拦截解密。黑客为了隐藏自己,再用自己拿到的服务器的公钥加密,之后发给服务器。如下图所示: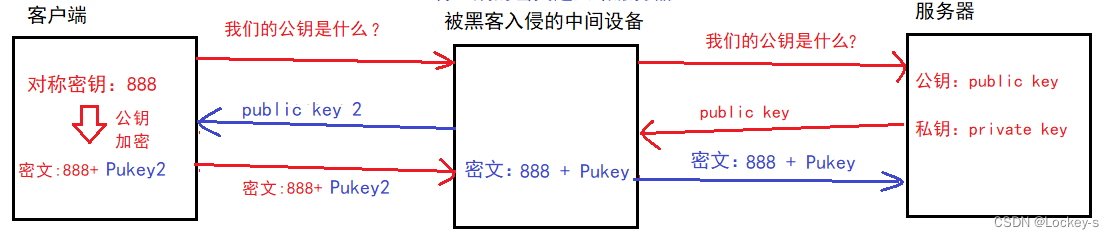
解决中间人攻击: 关键就是仍客户端确认,当前的公钥是来自于服务器还是黑客。验证的时候,就通过第三方公信机构来验证。就像是住酒店的时候,刷身份证,这也是通过公安局来验证的。
版权归原作者 Lockey-s 所有, 如有侵权,请联系我们删除。