

任务描述
- 创建使用Dockerfile安装Python3和Keras或NumPy的容器映像
- 当我们启动镜像时,它应该会自动开始在容器中训练模型。
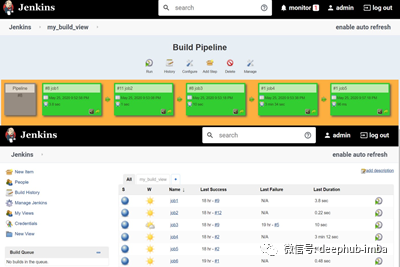
- 使用Jenkins中的build pipeline插件创建job1、job2、job3、job4和job5的作业链
- Job1:当一些开发人员将repo推送到Github时,自动拉Github repo。
- Job2:通过查看代码或程序文件,Jenkins应该自动启动安装了相应的机器学习工具或软件的映像容器,以部署代码并开始培训(例如,如果代码使用CNN,那么Jenkins应该启动已经安装了CNN处理所需的所有软件的容器)。
- Job3:训练你的模型和预测准确性或指标。
- Job4:如果度量精度低于95%,那么调整机器学习模型架构。
- Job5:重新训练模型或通知正在创建最佳模型
- 为monitor创建一个额外的job6:如果应用程序正在运行的容器。由于任何原因失败,则此作业应自动重新启动容器,并且可以从上次训练的模型中断的位置开始。
首先创建docker镜像:
# docker build -t deephub/optml:1.0 .
创建完后可以开始编写任务
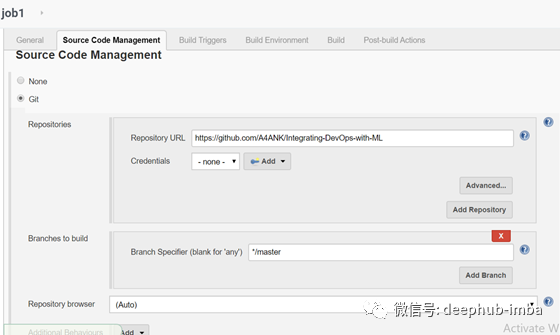
Job 1
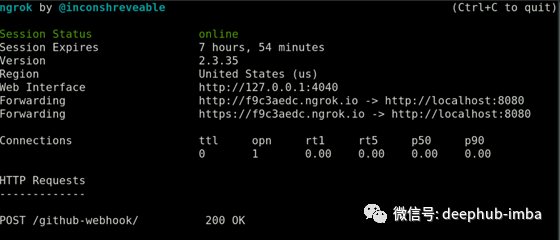
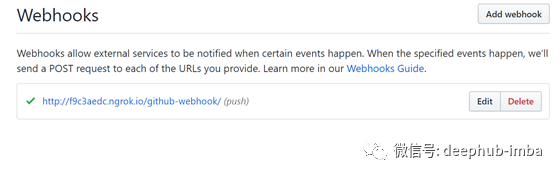
这里使用ngrok作为样例来为github webhooks payload url建一个隧道,这样我们的内网github就可以发布到公网上。除了ngrok以外可以选择其他服务。
# ./ngrok http 8080
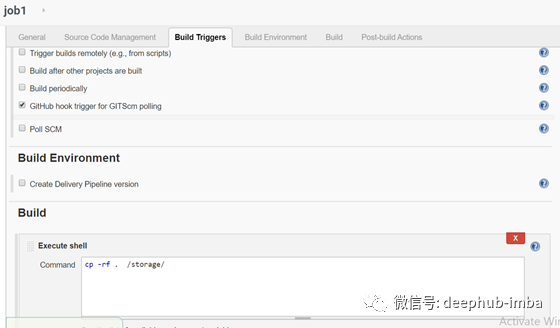
Job 2
此作业将在容器未启动时触发启动,或者在job1成功生成时触发。
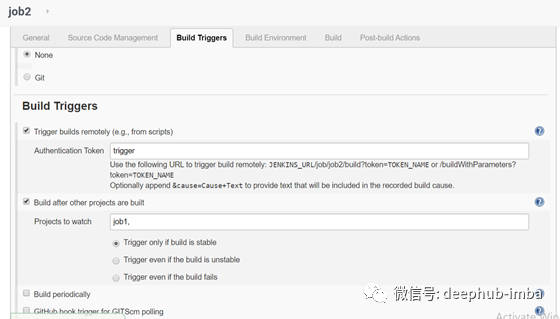
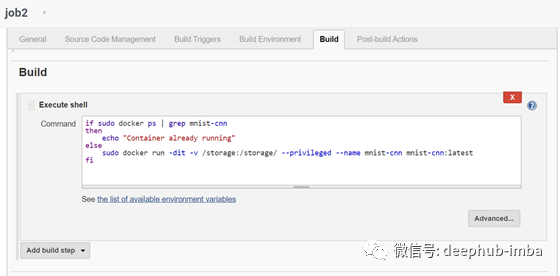
Job 3
当job2生成成功时,将触发此作业。这项工作是第一次训练模型,并检查模型的准确性是否大于95%。如果大于95%,则将模型保存到相应位置。
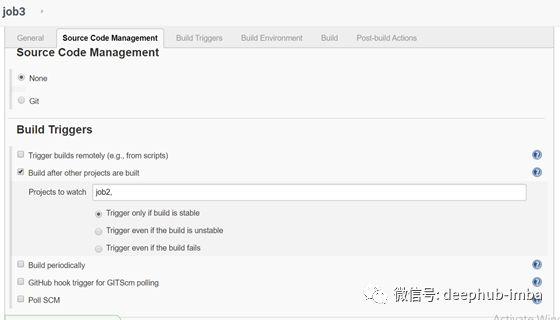

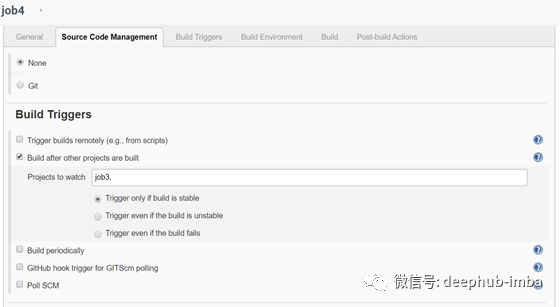
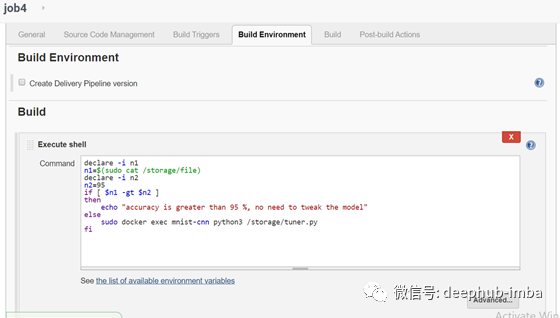
Job 4
当job3构建成功时,将触发此job。这项工作检查模型的准确性是否大于95%。如果它大于95%,那么它将不做任何事情,否则它将运行模型的另一个训练,以调整和调整模型的超参数,使模型的精度>95。
Job 5
当job4生成成功时,将触发此作业。在调整模型之后,此作业检查模型的准确性是否大于95%。如果它大于95%,那么它将发出通知并发送邮件,否则它将什么也不做。


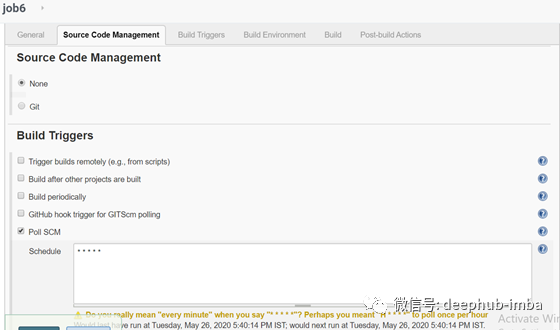
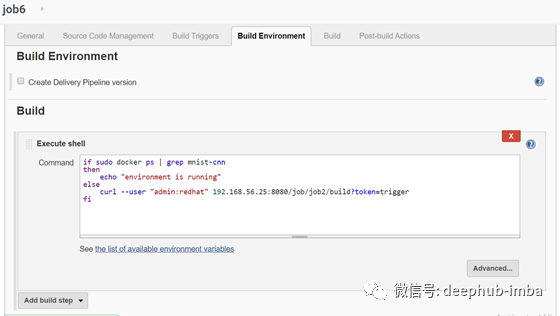
Job 6
此作业将使用Poll SCM触发,它将在容器停止时进行检查,然后通过触发job2重新启动容器,否则不执行任何操作。
至此,所有的任务创建完成可以开始使用了
作者:ANKUR DHAKAR
代码地址:https://github.com/A4ANK/Integrating-DevOps-with-ML
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********