
一.Flink简介
Apache Flink是一款开源流处理框架,由Apache软件基金会进行维护和开发,专为实时数据处理、批处理以及流批一体的大规模数据处理场景而设计。Flink的核心理念是提供了一种统一的数据处理模型,使得无论是实时流处理还是批量处理,都可以在同一个系统中以一致的方式高效执行。
Flink的设计基于数据流编程模型,其核心特性包括事件时间处理(Event Time Processing)、精确一次状态一致性(Exactly-once State Consistency)和故障恢复机制,这些都确保了在高并发、大数据量下对数据进行低延迟、高吞吐且准确无误的处理。
首先,Flink支持事件时间处理,这意味着它能够根据数据本身携带的时间戳进行计算,而非系统的处理时间,从而更好地处理乱序事件和窗口计算问题,尤其适合于实时业务监控、预警等场景。
其次,Flink提供了精确一次的状态一致性保证,即使在发生故障或重启的情况下,也能确保每条记录只被处理一次,并且中间结果的状态保持正确。这对于需要维护用户会话、统计累积指标等有状态计算任务至关重要。
再者,Flink具备高度的可扩展性和容错性,其分布式运行环境能很好地适应大规模集群部署,通过checkpoint机制实现快速故障恢复,保障服务的高可用性。
此外,Flink支持丰富的连接器接口,可以无缝对接各种数据源和数据接收系统,如Kafka、HDFS、MySQL、Elasticsearch等,方便企业构建端到端的数据处理管道。
Flink还具有动态资源调整、SQL & Table API等多种易用性功能,使开发者无需深入了解底层细节,即可快速构建复杂的数据处理应用。
总的来说,Apache Flink凭借其强大的实时处理能力、灵活的编程模型、严格的精确一次语义以及广泛的数据源适配性,在大数据处理领域占据了重要地位,已在全球范围内被诸多互联网公司、金融机构以及其他行业的企业广泛应用,有效推动了实时数据分析与决策的发展。
Flink发展历程
Flink起源于Stratosphere项目,这是2010年至2014年间由三所柏林大学和其他欧洲大学共同开展的一项研究项目。2014年4月,Stratosphere代码的一个分支被捐赠给了Apache软件基金会作为一个孵化项目,其初始提交者由系统的核心开发人员组成。此后不久,许多创始人离开大学,创办了一家名叫Data Artisans的公司,用于将Flink商业化。在孵化期间,为了防止与其他不相关的项目混淆,对项目名称做了更改,选择Flink作为该项目的新名称。
注1:Data Artisans公司于2019年1月被阿里以9000万欧元收购。
注2:在德语中,“Flink”一词的意思是快速或敏捷,它代表该项目所具有的流和批处理程序的风格。因为松鼠速度快、敏捷,所以Flink选择柏林郊外的一种红棕色松鼠作为Logo。在下图中,左图为柏林郊外的红松鼠,右图为Flink的Logo。

项目快速完成孵化,2014年12月,Flink毕业成为Apache软件基金会的顶级项目。
Flink是Apache软件基金会最大的5个大数据项目之一,在全球拥有超过200名开发人员的社区和多个生产安装。作为公认的新一代大数据计算引擎,Flink 已成为阿里、腾讯、滴滴、美团、字节跳动、Netflix、Lyft 等国内外知名公司建设流计算平台的首选!

Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。
Flink1.10.0 完美整合了阿里的BLink、支持了YARN模式下的跨Task资源共享,并强化了对Hive的支持。随着 Flink 1.10 版本的发布,Blink 合并的正式完成,Flink 作业的整体性能及稳定性有了显著优化,越来越多的企业开始采用 Flink 用于生产环境。相信 Flink 的整体性能将随着社区发展、生态的完善不断取得新突破。
Flink特性
Flink支持流和批处理、复杂的状态管理、事件时间处理语义,以及对状态的一次一致性保证。此外,Flink可以部署在各种资源提供者(如YARN、Apache Mesos和Kubernetes)上,也可以作为独立集群部署在裸机硬件上。可以将Flink集群配置为高可用的以避免单点故障。
Flink设计用于在任何规模上运行有状态流应用程序。应用程序可能被并行化为数千个任务,这些任务分布在集群中并并行执行。因此,一个应用程序可以利用几乎无限数量的CPU、主内存、磁盘和网络IO。此外,Flink很容易维护非常大的应用程序状态。它的异步和增量检查点算法在保证精确一次性的状态一致性的同时,确保对处理延迟的影响最小。
Apache Flink 为用户提供了更强大的计算能力和更易用的编程接口:
- 批流统一。Flink在Runtime和SQL层批流统一,提供高吞吐低延时计算能力和更强大的SQL支持。
- 生态兼容。Flink能与Hadoop Yarn / Apache Mesos / Kubernetes集成,并且支持单机模式运行。
- 性能卓越。Flink提供了性能卓越的批处理与流处理支持。
- 规模计算。Flink的作业可被分解成上千个任务,分布在集群中并发执行。
Flink已经被证明可以扩展到数千个内核和TB级的应用程序状态,提供高吞吐量和低延迟,并支持世界上一些要求最高的流处理应用程序。Apache Flink 在 2019 年阿里巴巴双 11 场景中突破实时计算消息处理峰值达到 25 亿条/秒。
Flink程序运行规模:
- 每天处理数万亿个事件的应用程序
- 维护多个TB级状态的应用程序
- 运行在数千个内核上的应用程序
二、Flink 部署及启动
Apache Flink 提供了多种部署模式以满足不同环境下对实时数据处理的需求。以下是Flink最常见的部署模式及其特点概述:
1. 本地执行 (Local Execution)
适用场景: 开发阶段的本地调试与测试。
本地模式下,Flink会在单个Java虚拟机(JVM)中运行,所有的组件(如JobManager、TaskManager)都运行在同一进程中。这种模式无需额外的集群资源,非常适合编写和初步测试Flink应用程序。
2. Standalone 集群部署
适用场景: 小型至中型生产环境。
在Standalone模式下,Flink可以独立部署在一个或多个物理节点组成的集群上,不依赖于其他的资源管理系统。用户需要手动配置并启动JobManager和TaskManager实例,可通过配置文件设定高可用性(HA)选项,例如结合ZooKeeper进行故障恢复。
2.1 会话模式(Session Mode)
在会话模式中,用户首先启动一个持久化的Flink集群,然后在该集群上提交多个作业。集群资源在整个会话期间保持活跃,作业之间共享资源,可能导致资源争抢。
2.2 单作业模式(Per-Job Mode)和应用模式(Application Mode)
这两种模式在资源隔离和生命周期管理上更为精细。虽然早期版本的Flink Standalone集群可能不直接支持单作业模式部署,但在更现代的部署方案中,特别是结合Kubernetes或者YARN时,这两种模式变得越来越常见。
- 单作业模式(Per-Job Mode):为每个作业启动一个独立的集群,作业完成后集群资源会被释放,这样能确保每个作业都有固定的资源使用,避免资源竞争。
- 应用模式(Application Mode):类似于单作业模式,但概念上更加广义,指的是每个应用(可能是包含多个相关作业的逻辑单元)拥有独立的资源容器,作业之间仍然保持资源隔离。
3. 资源管理器集成部署
适用场景: 大型生产环境,资源池化管理。
Flink可以很好地整合到现有的资源管理框架中,如Hadoop YARN、Kubernetes和Mesos等。
- YARN模式:- Session-Cluster:在YARN中启动一个持久化的Flink会话集群,允许连续提交多个作业。- Per-Job-Cluster:每次提交作业时,YARN都会为该作业动态创建一个Flink集群,作业执行完毕后自动清理资源。
- Kubernetes模式:- 类似地,Flink也可以在Kubernetes平台上运行,支持会话模式和应用模式,利用Kubernetes原生的资源管理和弹性伸缩能力。
在资源管理器集成部署模式下,Flink作业的生命周期和资源分配由对应的资源管理器控制,这大大简化了运维工作,并实现了资源的有效利用和弹性伸缩。
三.Flink架构和执行原理
在大数据领域,有许多流计算框架,但是通常很难兼顾延迟性和吞吐量。Apache Storm提供低延迟,但目前不提供高吞吐量,也不支持在发生故障时正确处理状态。Apache Spark Streaming的微批处理方法实现了高吞吐量的容错性,但是难以实现真正的低延时和实时处理,并且表达能力方面也不是特别丰富。而Apache Flink兼顾了低延迟和高吞吐量,是企业部署流计算时的首选。 表1.1 三种流计算框架比较
流处理框架高吞吐量低延迟易于使用和表达正确的时间/窗口语义压力下保持正确性Storm×√×××Spark Streaming√×××√Flink√√√√√
Flink架构
Flink 是可以运行在多种不同的环境中的,例如,它可以通过单进程多线程的方式直接运行,从而提供调试的能力。它也可以运行在 Yarn 或者 K8S 这种资源管理系统上面,也可以在各种云环境中执行。
Flink的整体架构如下图所示。
针对不同的执行环境,Flink 提供了一套统一的分布式作业执行引擎,也就是 Flink Runtime(Flink运行时)这一层。Flink 在 Runtime 层之上提供了 DataStream 和 DataSet 两套 API,分别用来编写流作业与批作业,以及一组更高级的 API 来简化特定作业的编写。
Flink runtime是Flink的核心计算结构,这是一个分布式系统,它接受流数据流程序,并在一台或多台机器上以容错的方式执行这些数据流程序。这个运行时可以作为YARN的应用程序在集群中运行,也可以很快在Mesos集群中运行,或者在一台机器中运行(通常用于调试Flink应用程序)。
Flink Runtime 层的主要架构如下图所示,它展示了一个 Flink 集群的基本结构。Flink Runtime 层的整个架构采用了标准 Master-Slave 的结构,即总是由一个Flink Master和一个或多个Flink TaskManager组成。在下面的架构图中,其中左侧的AM(Application Manager)部分即是Master,它负责管理整个集群中的资源并处理作业提交、作业监督;而右侧的两个 TaskExecutor 则是 Slave,这是工作(worker)进程,负责提供具体的资源并实际执行作业。

一个Flink集群总是由一个Flink Master和一个或多个Flink TaskManager组成。Flink Master负责处理作业提交、作业监督以及资源管理。Flink TaskManager是工作(worker)进程,负责执行组成Flink作业的实际任务。
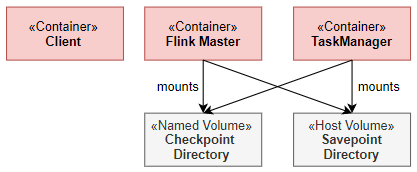
Flink Master是Flink集群的主进程。它包含三个不同的组件:Resource Manager、Dispatcher以及每个运行时Flink作业的JobManager。这三个组件都包含在 AppMaster 进程中。
- Dispatcher 负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的 JobManager 组件。
- ResourceManager 负责资源的管理,在整个 Flink 集群中只有一个 ResourceManager。
- JobManager 负责管理作业的执行,在一个 Flink 集群中可能有多个作业同时执行,每个作业都有自己的 JobManager 组件。
TaskManager是一个Flink集群的工作(worker)进程。任务(Tasks)被调度给TaskManager执行。它们彼此通信以在后续任务之间交换数据。
总体来说,Flink运行时由两种类型的进程组成:
- JobManager:协调分布式执行。他们安排任务、协调检查点、协调故障恢复,等等。至少有一个JobManager。一个高可用性的设置将有多个JobManager,其中一个总是leader,其他的都是standby。
- TaskManager:执行数据流的任务(或者更具体地说,子任务),并缓冲和交换数据流。必须始终至少有一个TaskManager。
JobManager和TaskManager可以多种方式启动:直接在机器上作为独立集群(standalone)启动,或者在容器中启动,或者由诸如YARN或Mesos之类的资源框架管理。
客户端不是运行时和程序执行的一部分,而是用于准备和向JobManager发送数据流。之后,客户端可以断开连接,或保持连接以接收作业进度报告。客户端可以作为触发执行的Java/Scala程序的一部分运行,也可以在命令行进程(./bin/flink run)中运行。
任务槽和资源
每个worker (TaskManager)都是一个JVM进程,可以在单独的线程中执行一个或多个子任务。为了控制一个worker接受多少任务,一个worker具有所谓的"任务插槽"(task slots,至少一个)。
每个task slot表示TaskManager资源的一个固定子集。例如,一个有三个插槽的TaskManager会将其1/3的托管内存分配给每个插槽。对资源进行插槽化意味着子任务不会与来自其他作业的子任务争夺托管内存,而是拥有一定数量的预留托管内存。注意,这里没有发生CPU隔离;当前插槽只分隔任务的托管内存。
通过调整任务槽的数量,用户可以定义子任务如何彼此隔离。每个TaskManager有一个插槽(slot)意味着每个任务组运行在各自的JVM中(例如,可以在单独的容器中启动JVM)。拥有多个插槽意味着更多的子任务共享同一个JVM。相同JVM中的任务共享TCP连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销。
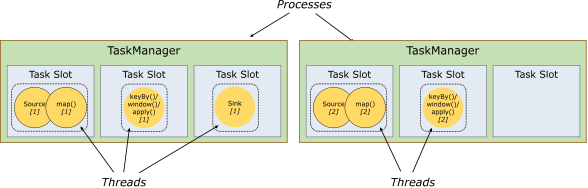
默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自相同的作业。结果是一个槽可以容纳作业的整个管道。允许这个插槽共享(slot sharing)有两个主要好处:
- Flink集群需要的任务插槽与作业中使用的最高并行度一样多。不需要计算一个程序总共包含多少任务(具有不同的并行度)。
- 更容易得到更好的资源利用。如果没有插槽共享,非密集型source/map()子任务将阻塞与资源密集型窗口子任务一样多的资源。使用插槽共享,将我们示例中的基本并行度从2提高到6,可以充分利用插槽资源,同时确保繁重的子任务在TaskManager中得到公平分配。

API还包括一个资源组(resource group)机制,可用于防止不需要的插槽共享。
根据经验,一个好的默认任务槽数应该是CPU内核的数量。使用超线程,每个槽将接受2个或更多的硬件线程上下文。
Flink资源管理
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。实际上,Flink作业调度可以看做是对资源和任务进行匹配的过程。Flink集成了所有常见的集群资源管理器,如Hadoop YARN、Apache Mesos和Kubernetes,但也可以设置为作为独立集群运行。
补充:在部署Flink应用程序时,Flink根据应用程序配置的并行性自动标识所需的资源,并从资源管理器中请求这些资源。如果发生故障,Flink通过请求新的资源来替换失败的容器。所有提交或控制应用程序的通信都是通过REST调用进行的。这简化了Flink在许多环境中的集成。
在 Flink 中,资源是由 TaskExecutor 上的 Slot 来表示的,每个 Slot 可以用来执行不同的任务(Task)。而 Job 中实际的 Task,包含了待执行的用户逻辑。作业调度的主要目的就是为了给 Task 找到匹配的 Slot。
补充:逻辑上来说,每个 Slot 都应该有一个向量来描述它所能提供的各种资源的量,每个 Task 也需要相应的说明它所需要的各种资源的量。但是实际上在 1.9 之前,Flink 是不支持细粒度的资源描述的,而是统一的认为每个 Slot 提供的资源和 Task 需要的资源都是相同的。从 1.9 开始,Flink 开始增加对细粒度的资源匹配的支持的实现,但这部分功能目前仍在完善中。
在 ResourceManager 中,有一个子组件叫做 SlotManager,它维护了当前集群中所有 TaskExecutor 上的 Slot 的信息与状态,如该 Slot 在哪个 TaskExecutor 中,该 Slot 当前是否空闲等。如下图所示:
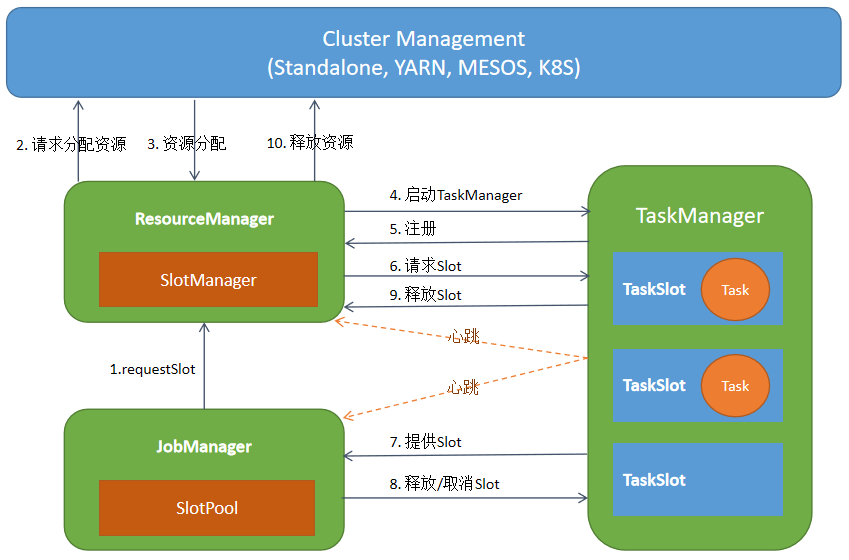
当 JobManger 为特定 Task 申请资源的时候,根据当前是 Per-job 还是 Session 模式,ResourceManager 可能会去申请资源来启动新的 TaskExecutor。当 TaskExecutor 启动之后,它会通过服务发现找到当前活跃的 ResourceManager 并进行注册。在注册信息中,会包含该 TaskExecutor中所有 Slot 的信息。 ResourceManager 收到注册信息后,其中的 SlotManager 就会记录下相应的 Slot 信息。当 JobManager 为某个 Task 来申请资源时, SlotManager 就会从当前空闲的 Slot 中按一定规则选择一个空闲的 Slot 进行分配。当分配完成后,RM 会首先向 TaskManager 发送 RPC 要求将选定的 Slot 分配给特定的 JobManager。TaskManager 如果还没有执行过该 JobManager 的 Task 的话,它需要首先向相应的 JobManager 建立连接,然后发送提供 Slot 的 RPC 请求。在 JobManager 中,所有 Task 的请求会缓存到 SlotPool 中。当有 Slot 被提供之后,SlotPool 会从缓存的请求中选择相应的请求并结束相应的请求过程。
当 Task 结束之后,无论是正常结束还是异常结束,都会通知 JobManager 相应的结束状态,然后在 TaskManager 端将 Slot 标记为已占用但未执行任务的状态。JobManager 会首先将相应的 Slot 缓存到 SlotPool 中,但不会立即释放。这种方式避免了如果将 Slot 直接还给 ResourceManager,在任务异常结束之后需要重启时,需要立刻重新申请 Slot 的问题。通过延时释放,Failover 的 Task 可以尽快调度回原来的 TaskManager,从而加快 Failover 的速度。当 SlotPool 中缓存的 Slot 超过指定的时间仍未使用时,SlotPool 就会发起释放该 Slot 的过程。与申请 Slot 的过程对应,SlotPool 会首先通知 TaskManager 来释放该 Slot,然后 TaskExecutor 通知 ResourceManager 该 Slot 已经被释放,从而最终完成释放的逻辑。
除了正常的通信逻辑外,在 ResourceManager 和 TaskExecutor 之间还存在定时的心跳消息来同步 Slot 的状态。在分布式系统中,消息的丢失、错乱不可避免,这些问题会在分布式系统的组件中引入不一致状态,如果没有定时消息,那么组件无法从这些不一致状态中恢复。此外,当组件之间长时间未收到对方的心跳时,就会认为对应的组件已经失效,并进入到容错的流程。
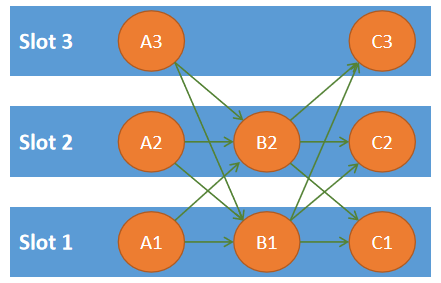
在 Slot 管理基础上,Flink 可以将 Task 调度到相应的 Slot 当中。如上文所述,Flink 尚未完全引入细粒度的资源匹配,默认情况下,每个 Slot 可以分配给一个 Task。但是,这种方式在某些情况下会导致资源利用率不高。如下图所示,假如 A、B、C 依次执行计算逻辑,那么给 A、B、C 分配单独的 Slot 就会导致资源利用率不高。为了解决这一问题,Flink 提供了 Share Slot 的机制。如图中所示,基于 Share Slot,每个 Slot 中可以部署来自不同 JobVertex(作业向量)的多个任务,但是不能部署来自同一个 JobVertex 的 Task。如图中所示,每个 Slot 中最多可以部署同一个 A、B 或 C 的 Task,但是可以同时部署 A、B 和 C 的各一个 Task。当单个 Task 占用资源较少时,Share Slot 可以提高资源利用率。 此外,Share Slot 也提供了一种简单的保持负载均衡的方式。
图 共享Slot
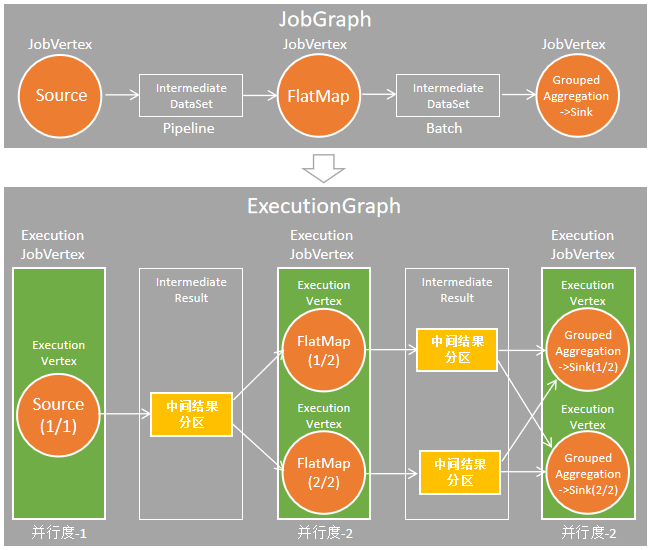
基于上述 Slot 管理和分配的逻辑,JobManager 负责维护作业中 Task执行的状态。如上文所述,客户端会向 JobManager 提交一个 JobGraph,它代表了作业的逻辑结构。JobManager 会根据 JobGraph 按并发展开,从而得到 JobManager 中关键的 ExecutionGraph。ExecutionGraph 的结构如下图所示,与 JobGraph 相比,ExecutionGraph 中对于每个 Task 与中间结果等均创建了对应的对象,从而可以维护这些实体的信息与状态。
图 ExecutionGraph 是 JobGraph 按并发展开所形成的,它是 JobMaster中的核心数据结构
在一个 Flink Job 中是包含多个 Task 的,因此另一个关键的问题是在 Flink 中按什么顺序来调度 Task。如下图所示,目前 Flink 提供了两种基本的调度逻辑,即延迟调度(Lazy From Source)和即时调度(Eager调度) 。即时调度会在作业启动时申请资源将所有的Task 调度起来。这种调度算法主要用来调度可能没有终止的流作业。与之对应,延迟调度则是从Source开始,按拓扑顺序来进行调度。简单来说,延迟调度会先调度没有上游任务的Source任务,当这些任务执行完成时,它会将输出数据缓存到内存或者写入到磁盘中。然后,对于后续的任务,当它的前驱任务全部执行完成后,Flink 就会将这些任务调度起来。这些任务会从读取上游缓存的输出数据进行自己的计算。这一过程继续进行直到所有的任务完成计算。
图 Flink中两种基本的调度策略

四.Flink本地集群安装
Flink运行在Linux、Mac OS x和Windows上。本教程中我们将Flink集群搭建在Linux系统上。
使用Flink需要满足以下先决条件:
- 需要安装Java 8/Java11来运行Flink作业/应用程序;
- Scala API(可选地)依赖于Scala 2.11;
- 如果配置为高可用(没有单点故障),需要Apache ZooKeeper;
- 如果配置为高可用(可以从故障中恢复)的流处理,Flink需要某种形式的检查点分布式存储 (HDFS / S3 / NFS / SAN / GFS / Kosmos / Ceph / …)
Flink集群可以运行在单节点上,这称为“Local Cluster”模式。本地集群安装步骤如下所示:
1、要运行Flink,要求必须安装好Java 8.x
使用如下命令检查Java是否已经正确安装:
java -version
如果已经正确地安装了Java 8,那么会输出类似如下的内容:

2、下载和安装Flink
下载地址:Downloads | Apache Flink。可以选择任何喜欢的Hadoop/Scala组合。

将下载的安装包放在"/software/"目录下,然后将其解压缩到指定的位置(例如,/bigdata/目录下)。在终端执行如下的命令。
cd ~/bigdata
tar xzf ~/software/flink-1.10.0-bin-scala_2.11.tgz
cd flink-1.10.0
3、启动一个本地Flink集群
对于单节点设置,Flink是开箱即用的,即不需要更改默认配置,直接启动即可。
./bin/start-cluster.sh
使用jps命令查看,可以看到启动了以下两个进程:
2672 StandaloneSessionClusterEntrypoint
3096 TaskManagerRunner
打开浏览器,输入地址:http://localhost:8081 ,可查看检查调度程序的web前端。web前端应该报告有单个可用的TaskManager实例。
还可以通过检查logs目录中的日志文件来验证系统是否正在运行:
tail log/flink-*-standalonesession-*.log
4、运行单词计数程序
1)首先,启动netcat服务器,运行在9000端口:
nc -l 9000
2)打开另一个终端,执行以下命令,启动Flink示例程序,监听netcat服务器:
它将从套接字中读取文本,并每5秒打印前5秒内每个不同单词出现的次数,即处理时间的滚动窗口。
./bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9000
3)在netcat控制台,键入一些内容,Flink将会处理它。
good good study
day day up
4)启动第三个终端窗口,并在该窗口中执行以下命令,查看日志中的输出:
cd ~/bigdata/flink-1.10.0
tail -f log/flink-*-taskexecutor-*.out
可以看到如下输出结果:
good : 2
study : 1
day : 2
up : 1
5)还可以检查Flink Web UI来查看job是怎样执行的。
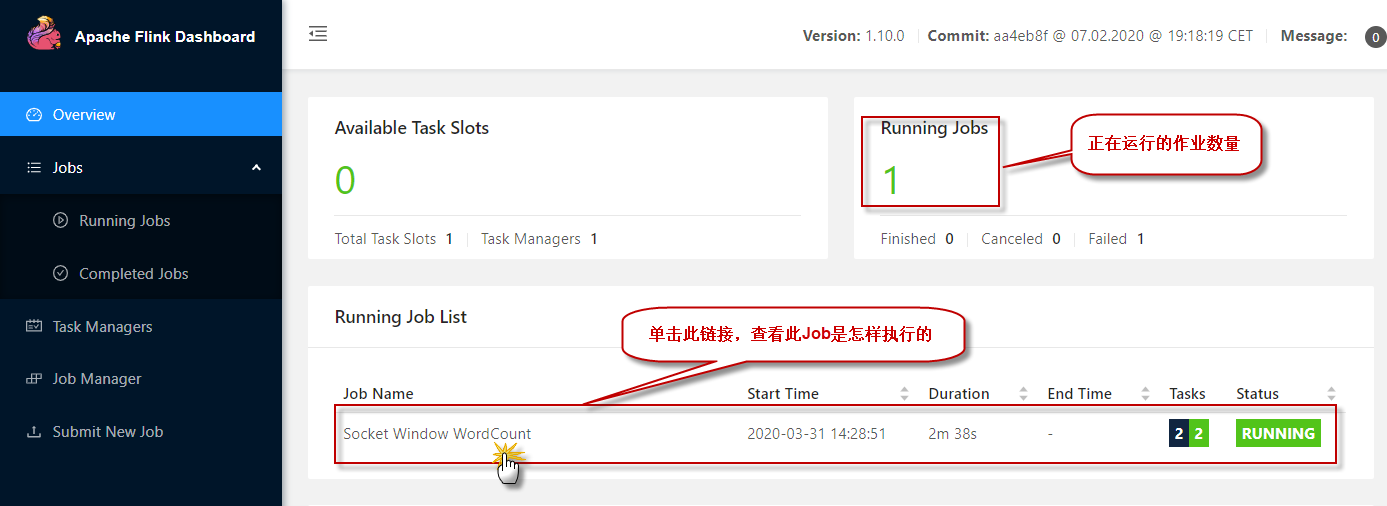
单击图中的【Running Job List】下正在运行的作业列表,查看某一个正在运行的作业执行情况:
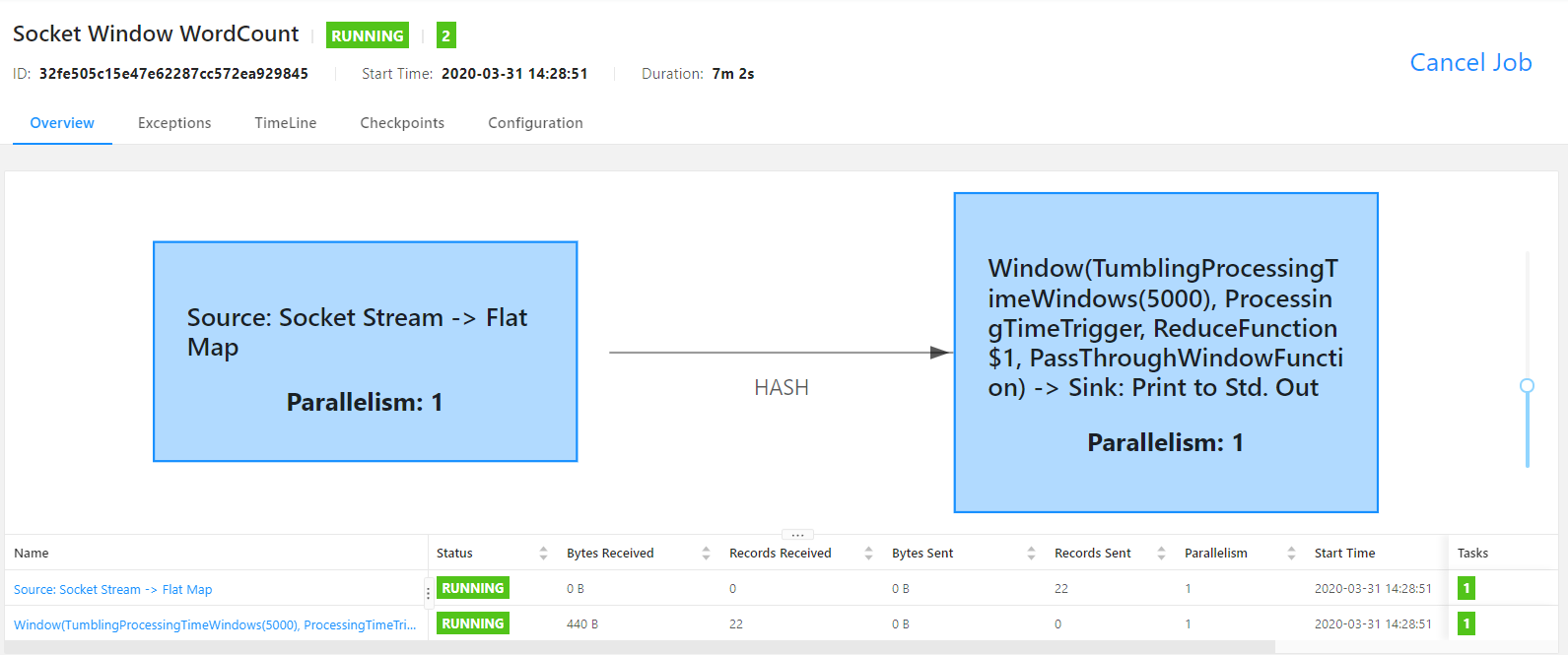
5、运行Flink自带的单词计数程序:
Flink安装包自带了一个以文本文件作为数据源的单词计数程序,位于Flink下的"example/batch/"目录下的WordCount.jar包中。可以执行下面的命令来在Flink集群上执行该程序,读取HDFS上的输入数据文件进行处理,并输出计算结果到HDFS上。
注:从flink 1.8开始,Hadoop不再包含在Flink的安装包中,所以需要单独下载并拷贝到Flink的lib目录下。请从Flink官网下载flink-shaded-hadoop2-uber-2.7.5-1.10.0.jar并拷贝到Flink的lib目录下。
start-dfs.sh
./bin/flink run ./examples/batch/WordCount.jar
--input hdfs://hadoop:8020/wc.txt
--output hdfs://hadoop:8020/result
上面的命令是在运行WordCount时读写HDFS中的文件,其中--input参数指定要处理的输入文件,--output指定计算结果输出到的结果文件。(注:如果不加hdfs://前缀,默认使用本地文件系统)
执行以下命令查询输出结果:
hdfs dfs -cat hdfs://hadoop:8020/result
可以看到以下计算结果:
day 2
good 2
study 1
up 1
6、要停止Flink,在终端窗口输入以下命令:
./bin/stop-cluster.sh
五.Flink完全分布式集群安装
Flink支持完全分布式模式,这时它由一个master节点和多个worker节点构成。在本节,我们将搭建一个如下的三个节点的Flink集群。

Flink完全分布式集群搭建步骤如下:
1、配置从master到worker节点的SSH无密登录,并保持保节点上相同的目录结构。
(1) 在每台机器上,执行如下命令:
$ ssh localhost
$ ssh exit # 记得最后通过这个命令退出ssh连接
(2)在master上,使用如下命令生成公私钥:
$ cd .ssh
$ ssh-keygen -t rsa
然后一路回车,在.ssh下生成公私钥。
(3)将master上的公钥分别加入master、worker1和worker2机器的授权文件中。
在master机器上,执行如下命令:
$ ssh-copy-id hduser@master
$ ssh-copy-id hduser@worker1
$ ssh-copy-id hduser@worker2
(4)测试。在master机器上,使用ssh分别连接master、worker1和worker2:
$ ssh master
$ ssh worker1
$ ssh worker2
这时会发现不需要输入密码,直接就ssh连接上了这两台机器。
2、Flink要求在主节点和所有工作节点上设置JAVA_HOME环境变量,并指向Java安装的目录。
使用如下命令检查Java的安装和版本信息:
$ java -version
3、下载Flink安装包。下载地址:下载Flink安装包 。可以选择任何喜欢的Hadoop/Scala组合。
4、将下载的最新版本的Flink压缩包拷贝到master节点的"/software/"目录下,并解压缩到"/bigdata/"目录下。
步骤如下:
$ cd ~/bigdata/
$ tar xzf ~/software/flink-1.10.0-bin-scala_2.11.tgz
$ cd flink-1.10.0
5、在master节点上配置Flink
所有的配置都在"conf/flink-conf.yaml"文件中。在实际应用中,以下几个配置项是非常重要的:
- jobmanager.heap.mb:每个JobManager的可用内存量,以MB为单位。
- taskmanager.heap.mb:每个TaskManager的可用内存量,以MB为单位。
- taskmanager.numberOfTaskSlots:每台机器上可用的cpu数量,默认为1。
- parallelism.default:集群中cpu的总数。
- io.tmp.dirs:临时目录。
首先用编辑器nano打开该配置文件(你也可以用任何你喜欢的编辑器,如vim,都可以)。
$ vim conf/flink-conf.yaml
编辑如下内容(注意,冒号后面一定要有一个空格):
jobmanager.rpc.address: master // 指向master节点
jobmanager.rpc.port: 6123
jobmanager.heap.size: 1024m // 定义允许JVM在每个节点上分配的最大主内存量
taskmanager.memory.process.size: 1024m
taskmanager.numberOfTaskSlots: 2
parallelism.default: 1
6、每个节点下的Flink必须保持相同的目录内容。因此将配置好的Flink拷贝到集群中的另外两个节点work01和work02,使用如下的命令:
$ scp -r ~/bigdata/flink-1.10.0 hduser@worker01:~/bigdata/
$ scp -r ~/bigdata/flink-1.10.0 hduser@worker02:~/bigdata/
7、最后,必须提供集群中所有用作worker节点的列表。在"conf/slaves"文件中添加每个slave节点信息(IP或hostname均可),每个节点一行,如下所示。每个工作节点稍后将运行一个TaskManager:
master
worker1
worker2
8、启动集群:
$ ./bin/start-cluster.sh
这个脚本会在本地节点启动一个JobManager并通过SSH连接到所有的worker节点(在slaves文件中列出的) 以启动每个节点上的TaskManager。注意观察启动过程中的输出信息,如下:
Starting cluster.
Starting standalonesession daemon on host master.
Starting taskexecutor daemon on host master.
Starting taskexecutor daemon on host worker1.
Starting taskexecutor daemon on host worker2.
可以看出,Flink先在master上启动standalonesession进程,然后依次在master、worker1和worker2上启动taskexecutor进程。
启动以后,分别在master、worker1和worker2节点上执行jps命令,查看各节点上的进程是否正常启动了。
9、关闭集群
$ ./bin/stop-cluster.sh
也可以分别停止JobManager和TaskManager。
执行以下命令,停止单个的Job Manager:
$ ./bin/jobmanager.sh stop cluster
执行以下命令,停止单个的Task Manager:
$ ./bin/taskmanager.sh stop cluster
执行Flink自带的流处理程序-单词计数
1、首先,启动netcat服务器,运行在9000端口:
$ nc -l 9000
2、在另一个终端,启动Flink示例程序,监听netcat服务器。它将从套接字中读取文本,并每5秒打印前5秒内每个不同单词出现的次数,即处理时间的滚动窗口。
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname master --port 9000
3、回到第一个终端窗口,在正在运行的netcat终端窗口,随意输入一些内容,单词之间用空格分隔,Flink将会处理它。
good good study
day day up
4、分别使用ssh登录master、worker01和worker02节点,并执行以下命令,查看日志中的输出:
$ cd ~/bigdata/flink-1.10.0
$ tail -f log/flink-*-taskexecutor-*.out
可以看到如下输出结果:
good : 2
study : 1
day : 2
up : 1
5、还可以检查Flink Web UI来查看Job是怎样执行的。
打开浏览器,输入地址:http://master:8081 ,可查看检查调度程序的web前端。web前端应该报告有三个可用的TaskManager实例,以及正在执行的作业。Flink WebUI包含许多关于Flink集群及其作业(JobGraph、指标、检查点统计、TaskManager状态等)的有用而有趣的信息。
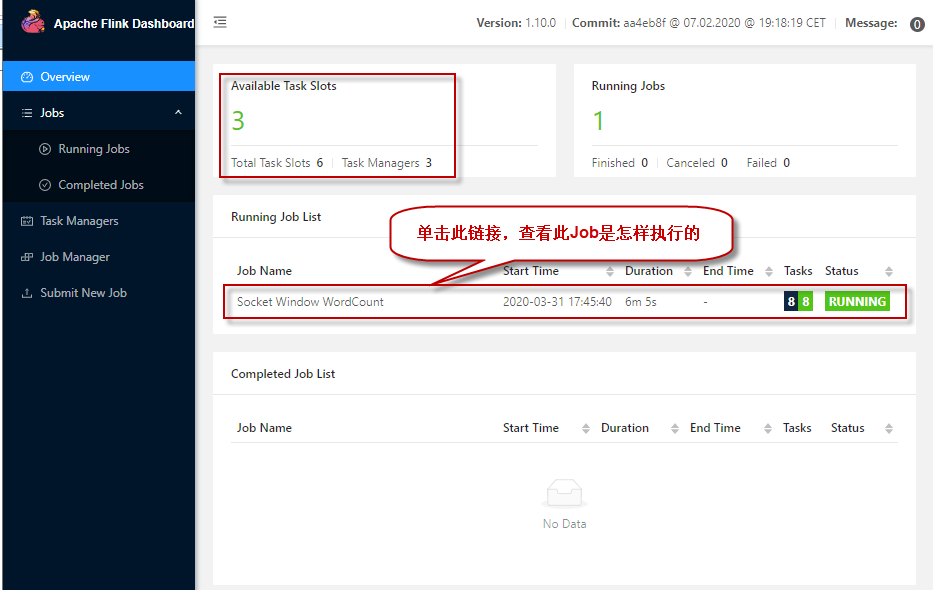
点击正在运行的作业,查看作业运行的详细信息,如下图所示:
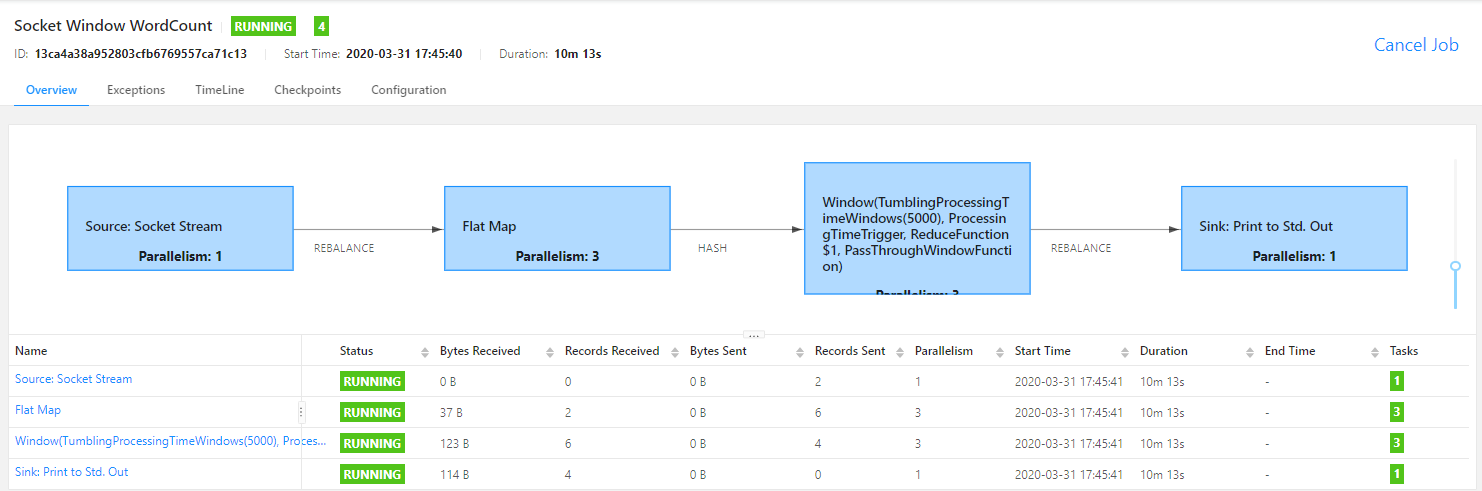
运行Flink自带的批处理程序-单词计数程序
Flink安装包自带了一个以文本文件作为数据源的单词计数程序,位于Flink下的"example/batch/"目录下的WordCount.jar包中。可以执行下面的命令来在Flink集群上执行该程序,读取HDFS上的输入数据文件进行处理,并输出计算结果到HDFS上。
注:从flink 1.8开始,Hadoop不再包含在Flink的安装包中,所以需要单独下载并拷贝到Flink的lib目录下。请从Flink官网下载 flink-shaded-hadoop2-uber-2.7.5-1.10.0.jar并拷贝到Flink的lib目录下。
$ start-dfs.sh
$ ./bin/flink run ./examples/batch/WordCount.jar \
--input hdfs://master:8020/flink_data/wc.txt \
--output hdfs://master:8020/flink_data/result
上面的命令是在HDFS中运行WordCount,其中--input参数指定要处理的输入文件,--output指定计算结果输出到的结果目录(事先要不存在)。(注:如果不加hdfs://前缀,默认使用本地文件系统)
执行以下命令查询输出结果:
$ hdfs dfs -cat hdfs://master:8020/flink_data/result/*
可以看到以下计算结果:
day 2
good 2
study 1
up 1
六、Flink 数据流
Flink数据流
在Flink中,应用程序由数据流组成,这些数据流可以由用户定义的运算符(注:有时我们称这些运算符为“算子”)进行转换。这些数据流形成有向图,从一个或多个源开始,以一个或多个输出结束。

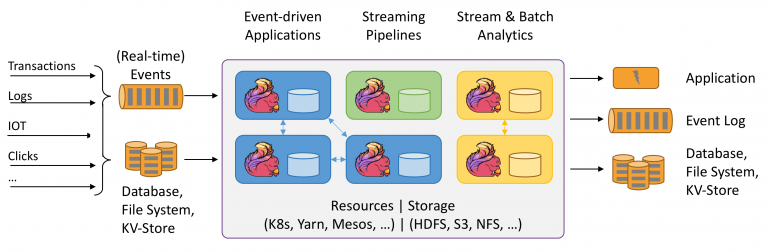
Flink支持流处理和批处理,它是一个分布式的流批结合的大数据处理引擎。在Flink中,认为所有的数据本质上都是随时间产生的流数据,把批数据看作是流数据的特例,只不过流数据是一个无界的数据流,而批数据是一个有界的数据流(例如固定大小的数据集)。如下图所示:

因此,Flink是一个用于在无界和有界数据流上进行有状态计算的通用的处理框架,它既具有处理无界流的复杂功能,也具有专门的运算符来高效地处理有界流。通常我们称无界数据为实时数据,来自消息队列或分布式日志等流源(如Apache Kafka或Kinesis)。而有界数据,通常指的是历史数据,来自各种数据源(如文件、关系型数据库等)。由Flink应用程序产生的结果流可以发送到各种各样的系统,并且可以通过REST API访问Flink中包含的状态。
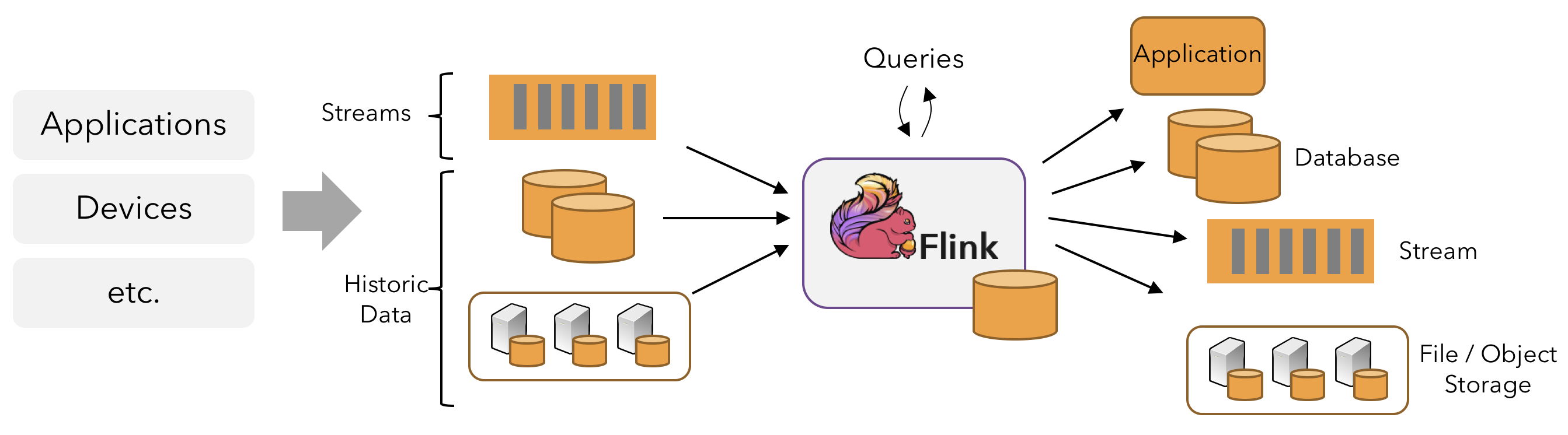
当Flink处理一个有界的数据流时,就是采用的批处理工作模式。在这种操作模式中,我们可以选择先读取整个数据集,然后对数据进行排序、计算全局统计数据或生成总结所有输入的最终报告。 当Flink处理一个无界的数据流时,就是采用的流处理工作模式。对于流数据处理,输入可能永远不会结束,因此我们必须在数据到达时持续不断地对这些数据进行处理。
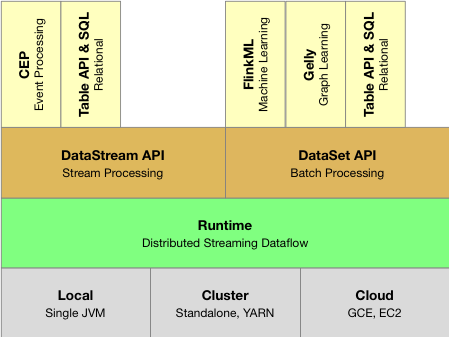
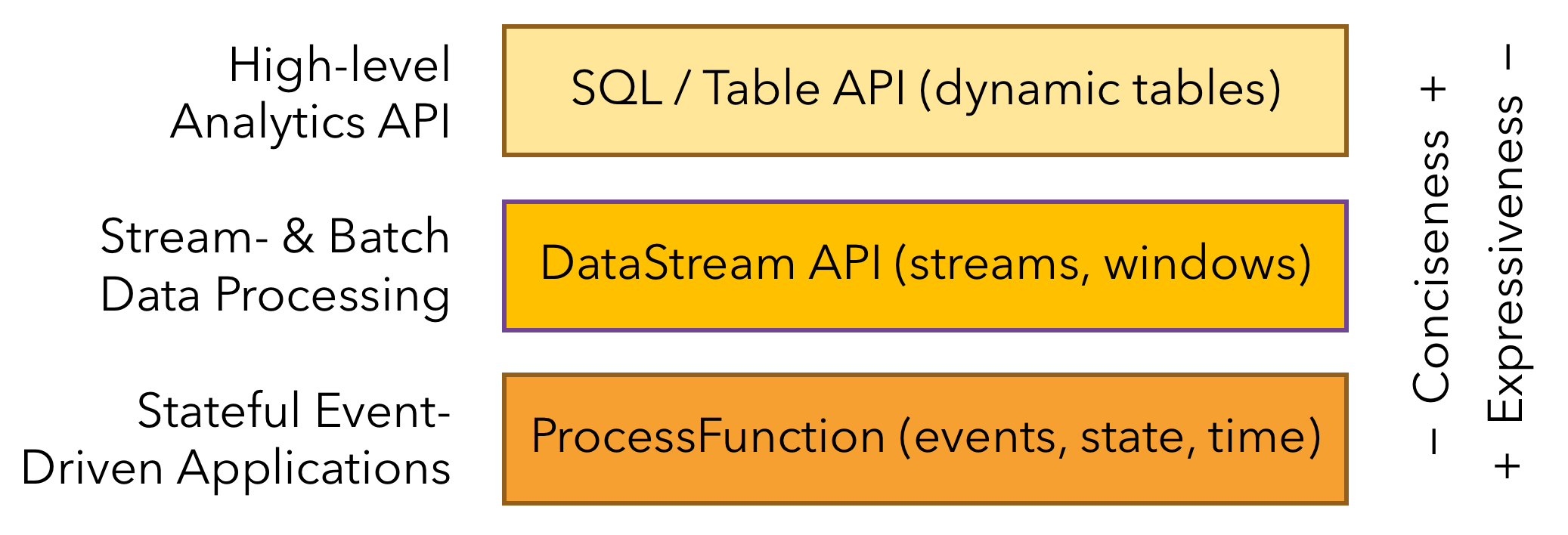
Flink分层API
Flink提供了开发流/批处理应用程序的不同抽象层次。如下图所示:

Flink提供了三个分层的API。每个API在简洁性和表达性之间提供了不同的权衡,并针对不同的应用场景。
七.Flink 算子
Flink既可以进行批处理(DataSet),也可以进行实时处理(DataStream)。
将Flink的算子分为两大类:一类是DataSet,一类是DataStream。
Apache Flink 的 DataSet API 提供了一系列的转换操作(Transformations)和动作操作(Operations),这些操作可以用来处理批数据集(DataSets)。以下是一些常用的 DataSet 批处理算子及其在 Scala 中的使用示例。
map - 对数据集中的每个元素应用一个函数,并返回一个新的数据集。
val input: DataSet[String] = ...
val output: DataSet[Int] = input.map(_.length)
** flatMap** - 类似于 map,但是可以返回多个元素。
val input: DataSet[String] = ...
val output: DataSet[String] = input.flatMap(_.split(" "))
filter - 根据条件过滤数据集中的元素。
val input: DataSet[Int] = ...
val output: DataSet[Int] = input.filter(_ % 2 == 0)
reduce - 对数据集中的元素进行累加操作。
val input: DataSet[Int] = ...
val result: Int = input.reduce(_ + _)
fold - 类似于 reduce,但是提供了一个初始值。
val input: DataSet[Int] = ...
val initial: Int = 0
val result: Int = input.fold(initial)(_ + _)
groupBy - 根据给定的键将数据集分组。
val input: DataSet[(String, Int)] = ...
val keyed: GroupedDataSet[(String, Int)] = input.groupBy(_._1)
coGroup - 将两个数据集按照指定的键进行分组并联合。
val input1: DataSet[(String, Int)] = ...
val input2: DataSet[(String, Int)] = ...
val coGrouped: CoGroupedDataSet[(String, Int), (String, Int)] = input1.coGroup(input2)
join - 根据给定的键将两个数据集进行连接。
val input1: DataSet[(String, Int)] = ...
val input2: DataSet[(String, Int)] = ...
val joined: DataSet[(String, (Int, Int))] = input1.join(input2).where(_._1).equalTo(_._1).map(_._1 -> _._2._1)
window - 对数据集进行窗口操作。
val input: DataSet[(String, Int)] = ...
val windowed: WindowedDataStream[(String, Int), TimeWindow] = input.window(TumblingEventTimeWindows.of(Time.of(5, TimeUnit.SECONDS)))
aggregate - 对数据集进行聚合操作。
val input: DataSet[(String, Int)] = ...
val aggregated: DataSet[(String, Int)] = input.aggregate(new MyAggregateFunction)
iterate - 对数据集进行迭代操作。
val input: DataSet[Int] = ...
val iterated: DataSet[Int] = input.iterate(10, i => i < 100)
broadcast - 将数据集广播到其他数据集的每个元素。
val broadcastSet: DataSet[String] = ...
val input: DataSet[Int] = ...
val result: DataSet[(String, Int)] = input.broadcast(broadcastSet).flatMap((i, b) => b.split(" ").map((_, i)))
请注意,上述代码示例仅用于展示算子的基本用法,实际使用时可能需要根据具体业务逻辑进行调整。此外,Flink 还提供了其他的算子和功能,如自定义函数、状态管理等,以支持更复杂的数据处理需求。在使用这些算子时,需要确保正确导入相关的 Flink 库和类。
八.读取各种数据源
在 Apache Flink 中,使用 DataStream API 可以从各种数据源获取数据。以下是一些常见的数据源以及如何在 Scala 中使用它们来创建 DataStream 的示例和描述。
1. 文件数据源
文件数据源是最常见的数据源之一,可以从文件中读取数据。Flink 支持读取文本文件、CSV 文件等。
- readTextFile(String path):逐行读取路径指定的文本文件,即符合TextInputFormat规范的文本文件,并以字符串形式返回。
- readFile(FileInputFormat inputFormat, String path):根据指定的文件输入格式读取(一次)文件。
- readFile(fileInputFormat, path, watchType, interval, pathFilter):这是前两个方法在内部调用的方法。它根据给定的fileInputFormat读取路径中的文件。
// 创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment()
// 从文件读取数据,例如 /path/to/file.txt
val fileStream: DataStream[String] = env.readTextFile("/path/to/file.txt")
// 打印数据流
fileStream.print()
// 启动 Flink 作业
env.execute("Flink DataStream File Source Example")
2. Socket 数据源
Socket 数据源允许 Flink 从 TCP 套接字读取数据。
- socketTextStream(hostName, port)
- socketTextStream(hostName, port, delimiter):可指定分隔符。
- socketTextStream(hostName, port, delimiter, maxRetry):还可以指定API应该尝试获取数据的最大次数。
// 创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment()
// 从 Socket 读取数据,例如监听 localhost 的 9999 端口
val socketStream: DataStream[String] = env.socketTextStream("localhost", 9999)
// 打印数据流
socketStream.print()
// 启动 Flink 作业
env.execute("Flink DataStream Socket Source Example")
3. 集合数据源
集合数据源允许你直接从 Scala 集合创建一个 DataStream。
- fromCollection(Seq):从Java Java.util. collection创建一个数据流。集合中的所有元素必须具有相同的类型。
- fromCollection(Iterator):从迭代器创建数据流。该类指定迭代器返回的元素的数据类型。
- fromElements(elements: _*):根据给定的对象序列创建数据流。所有对象必须具有相同的类型。
- fromParallelCollection(SplittableIterator):并行地从迭代器创建数据流。该类指定迭代器返回的元素的数据类型。
- generateSequence(from, to):并行地生成给定区间内的数字序列。
// 创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment()
// 从 Scala 集合创建 DataStream
val collectionStream: DataStream[String] = env.fromCollection(Seq("Flink", "DataStream", "Example"))
// 打印数据流
collectionStream.print()
// 启动 Flink 作业
env.execute("Flink DataStream Collection Source Example")
4. Kafka 数据源
Flink 可以连接到 Kafka 并从 Kafka 主题读取数据。
import org.apache.flink.streaming.connectors.kafka.{KafkaSource, KafkaDeserializationSchema}
import org.apache.flink.api.common.serialization.SimpleStringSchema
// 创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment()
// 定义 Kafka 连接配置
val kafkaProps = new Properties()
kafkaProps.setProperty("bootstrap.servers", "localhost:9092")
kafkaProps.setProperty("group.id", "flink-kafka-example")
// 创建 Kafka 数据源
val kafkaStream: DataStream[String] = env
.addSource(new KafkaSource[String](kafkaProps, "your-topic", new SimpleStringSchema()))
// 打印数据流
kafkaStream.print()
// 启动 Flink 作业
env.execute("Flink DataStream Kafka Source Example")
5. 自定义数据源
Flink 允许你通过实现
SourceFunction
接口来创建自定义数据源。
import org.apache.flink.streaming.api.functions.source.SourceFunction
// 定义一个自定义数据源
class CustomSource extends SourceFunction[String] {
private var running = true
override def run(sourceContext: SourceContext[String]): Unit = {
for (i <- 1 to 10) {
sourceContext.collect("Element: " + i)
Thread.sleep(1000) // 模拟数据生成延迟
}
running = false
}
override def cancel(): Unit = running = false
}
// 创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment()
// 添加自定义数据源
val customStream: DataStream[String] = env.addSource(new CustomSource)
// 打印数据流
customStream.print()
// 启动 Flink 作业
env.execute("Flink DataStream Custom Source Example")
以上示例展示了如何在 Scala 中使用 Flink DataStream API 来从不同的数据源获取数据。每个示例都包含了创建数据流的代码和对数据流进行操作的注释。这些示例可以作为构建更复杂 Flink 流处理作业的起点。
九.流处理中的Time与Window
时间是流应用程序的另一个重要组成部分。大多数事件流都具有固有的时间语义,因为每个事件都在特定的时间点生成。此外,许多常见的流计算都是基于时间的,比如窗口聚合、会话、模式检测和基于时间的连接。
Flink提供了一组丰富的与时间相关的特性:
- 事件时间模式:流应用程序(使用事件时间语义处理流)基于事件的时间戳计算结果。因此,事件时间处理允许精确和一致的结果。
- 处理时间模式:除了事件时间模式,Flink还支持处理时间语义,它执行由处理机器的挂钟时间触发的计算。处理时间模式可以适用于某些具有严格低延迟要求的应用程序,这些应用程序可以容忍近似结果。
- 水印支持:Flink在事件时间应用程序中使用水印来推断时间。水印是一种灵活的机制,用来平衡结果的延迟和完整性。
- 迟到数据处理:当以事件时间模式处理带有水印的流时,可能会在所有相关事件到达之前完成计算。这样的事件称为迟到事件。Flink提供了多个处理迟到事件的选项,比如通过侧输出重新路由它们,并更新以前完成的结果。
在 Flink 的流处理中,时间(Time)和窗口(Window)是两个核心概念,它们共同为处理无界数据流提供了强大的机制。
时间概念
Flink Streaming API借鉴了谷歌数据流模型,它的流API明确支持三个不同的时间概念:
- 事件时间:事件发生的时间,由产生(或存储)事件的设备记录。
- 接入时间:Flink在接入事件时记录的时间戳。
- 处理时间:管道中特定操作符处理事件的时间。
设置时间特性
时间特性定义了系统如何为依赖时间的顺序和依赖时间的操作(如时间窗口)确定时间。默认情况下,Flink DataStream程序将使用EventTime(事件时间)。如果要改用处理时间,那么需要在一开始就设置时间特性。
// 获得流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置流的时间特性(这里设置为采用处理时间)
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
注:在Flink 1.12之前,Flink DataStream默认使用的是处理时间。从Flink 1.12开始,默认的流时间特性已被更改为EventTime,因此不再需要调用此方法来启用事件时间支持。
当然也可以选择设置其他类型时间特性。
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
事件时间和水印
支持事件时间的流处理器需要一种方法来度量事件时间的进度。例如,针对事件时间对数据进行窗口或排序的操作符必须缓冲数据,直到它们能够确保已接收到某个时间间隔的所有时间戳为止。这是由所谓的“时间水印”来处理的。
在Flink中测量事件时间进展的机制是水印(watermarks),水印是一种特殊类型的事件,是告诉系统事件时间进度的一种方式。水印流是数据流的一部分,并带有时间戳t。水印(t)声明事件时间已经到达该流中的时间t,这意味着时间戳t ' <= t(即时间戳更早或等于水印的事件)的流中不应该有更多的元素。
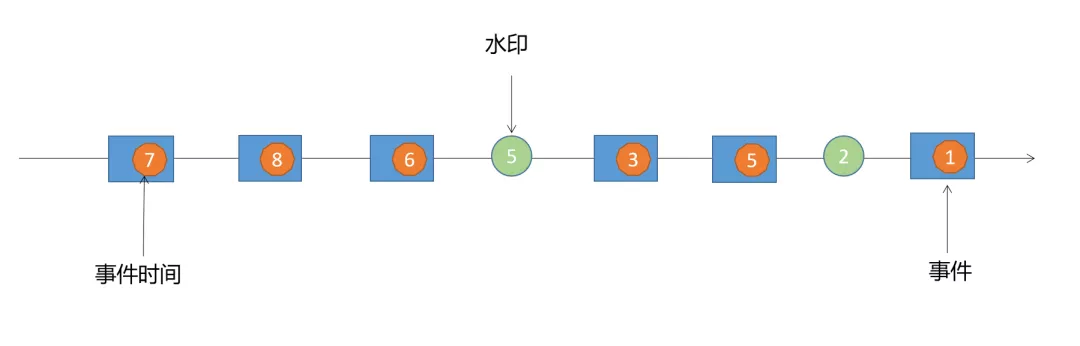
时间t的水印标记了数据流中的一个位置,并断言此时的流在时间t之前已经完成。为了执行基于事件时间的事件处理,Flink需要知道与每个事件相关联的时间,它还需要包含水印的流。水印就是系统事件时间的时钟。水印触发基于事件时间的计时器的触发。
下图显示了带有(逻辑的)时间戳的事件流,以及内联流动的水印。在这个例子中,事件是按顺序排列的(相对于它们的时间戳),这意味着水印只是流中的周期标记。
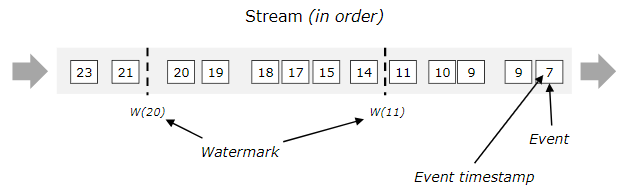
对于无序流,水印是至关重要的,如下图所示,其中事件不是按照它们的时间戳排序的。
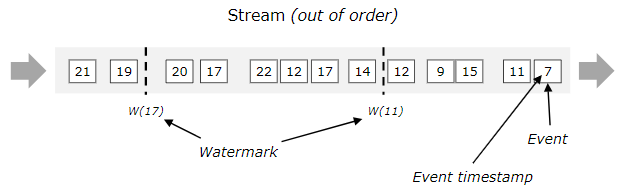
例如,当操作符接收到w(11)这条水印时,可以认为时间戳小于或等于11的数据已经到达,此时可以触发计算。同样,当接收到w(17)这条水印时,可以认为时间戳小于等于17的数据已经到达,此时可以触发计算。
可以看出,水印的时间戳是单调递增的,时间戳为t的水印意味着所有后续记录的时间戳将大于t。一般来说,水印是一种声明,在流中的那个点之前,在某个时间戳之前的所有事件都应该已经到达。当水印到达运算符(算子)时,运算符可以将其内部事件时间时钟推进到水印的值。
时间(Time)
Flink 支持三种时间类型,它们分别是:
- 事件时间(Event Time):这是数据事件发生的实际时间,通常由数据源中的时间戳表示。事件时间是处理乱序事件和确保一致性的关键。为了使用事件时间,需要定义水印(Watermarks)来表示事件时间的进度。
- 摄取时间(Ingestion Time):这是数据进入 Flink 系统的时间。摄取时间不依赖于事件的实际发生时间,而是依赖于数据到达 Flink 系统的时间。摄取时间通常用于快速处理数据,但不适合处理乱序数据。
- 处理时间(Processing Time):这是 Flink 任务执行操作的时间。处理时间与系统时钟相关,适用于不需要事件时间一致性的实时处理场景。
窗口(Window)
窗口是流处理中的一种机制,用于将无界数据流划分为有界的片段,以便于进行聚合和其他计算。Flink 提供了多种窗口类型:
- 时间窗口(Time Window):根据时间将数据分组到窗口中。时间窗口可以是翻滚的(Tumbling)或滑动的(Sliding)。- 翻滚时间窗口(Tumbling Time Window):将时间轴分割成固定大小的不重叠窗口。每个数据元素只能属于一个窗口。- 滑动时间窗口(Sliding Time Window):与翻滚窗口类似,但窗口有重叠。一个数据元素可以属于多个窗口。
- 计数窗口(Count Window):根据数据元素的数量将数据分组到窗口中。当窗口中的元素数量达到预设的阈值时,窗口会被触发处理。
- 会话窗口(Session Window):根据数据中的活动间隙来分组。会话窗口可以动态地根据数据的活跃度来打开和关闭,适用于用户交互等场景。
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{SlidingEventTimeWindows, TumblingEventTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
// 创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 定义带有事件时间戳的数据流
val stream: DataStream[(String, Int, Long)] = ???
// 使用事件时间戳和水印定义时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
stream.assignTimestampsAndWatermarks(WatermarkStrategy.noWatermarks())
// 应用翻滚时间窗口进行处理
val tumblingWindowedStream: DataStream[(String, Int)] = stream
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.sum(2) // 假设我们对每个窗口中的整数进行求和
// 应用滑动时间窗口进行处理
val slidingWindowedStream: DataStream[(String, Int)] = stream
.keyBy(_._1)
.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(1)))
.sum(2) // 假设我们对每个窗口中的整数进行求和
// 打印结果并执行作业
tumblingWindowedStream.print()
slidingWindowedStream.print()
env.execute("Flink Time and Window Example")
十.处理函数
在 Flink 中,
ProcessFunction
是一个强大的处理函数,它允许用户对流中的每个元素进行复杂的处理,包括状态管理和定时器设置。
ProcessFunction
提供了更细粒度的控制,适用于需要维护状态或实现事件时间处理的复杂逻辑。
以下是
ProcessFunction
的一些主要特点和作用:
- 状态管理 -
ProcessFunction允许用户创建和操作状态,这使得可以跟踪元素的历史信息或执行基于状态的决策。 - 定时器 - 用户可以在
ProcessFunction中设置事件时间或处理时间的定时器,以便在将来的某个时间点接收通知。 - 延迟处理 -
ProcessFunction可以处理延迟数据,即在事件发生后一段时间内到达的数据。 - 复杂的业务逻辑 - 由于其灵活性,
ProcessFunction可以用来实现复杂的业务逻辑,如窗口聚合、事件模式匹配等。
MapFunction
- 作用:对每个数据流中的元素应用一个一对一的转换逻辑。
import org.apache.flink.api.common.functions.MapFunction
class MultiplyByTwoMap extends MapFunction[Int, Int] {
override def map(value: Int): Int = {
// 将传入的整数值翻倍
value * 2
}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val inputDataStream = env.fromElements(1, 2, 3, 4)
val mappedStream = inputDataStream.map(new MultiplyByTwoMap())
// 这里创建了一个新的DataStream,其中每个元素都是原DataStream中对应元素的两倍
FlatMapFunction
- 作用:对每个数据流元素应用一个转换逻辑,可以生成零个、一个或多个输出元素。
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.api.java.tuple.Tuple2
class TokenizeWords extends FlatMapFunction[String, Tuple2[String, Integer]] {
override def flatMap(value: String, out: Collector[Tuple2[String, Integer]]): Unit = {
for (word <- value.split("\\s+")) {
out.collect(Tuple2(word, 1))
}
}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val textStream = env.socketTextStream("localhost", 9999)
val wordCountStream = textStream.flatMap(new TokenizeWords()).keyBy(_._1).sum(1)
// 此处将文本行分割成单词,并生成包含单词与计数值(初始化为1)的元组流
FilterFunction
- 作用:根据给定条件过滤数据流中的元素。
import org.apache.flink.api.common.functions.FilterFunction
class EvenNumberFilter extends FilterFunction[Int] {
override def filter(value: Int): Boolean = {
// 保留偶数
value % 2 == 0
}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val numbersStream = env.fromElements(1, 2, 3, 4, 5)
val evenNumbersStream = numbersStream.filter(new EvenNumberFilter())
// 此处仅保留了数据流中的偶数元素
ReduceFunction
- 作用:对数据流中的元素进行聚合,按照指定逻辑合并元素。
import org.apache.flink.api.common.functions.ReduceFunction
class SumReducer extends ReduceFunction[Int] {
override def reduce(value1: Int, value2: Int): Int = {
// 对整数进行求和
value1 + value2
}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val numbersStream = env.fromElements(1, 2, 3, 4, 5)
val sumResult = numbersStream.reduce(new SumReducer())
// 此处计算数据流中所有整数的总和
此外,还有许多其他高级函数,例如:
- KeyedProcessFunction:用于对键控流上的每个键进行状态管理和时间驱动的操作。它可以访问和更新键控状态,并响应定时器事件。这对于实现复杂的事件时间或处理时间相关的业务逻辑非常有用,比如会话窗口处理、状态过期清理等。
以下是一个使用 Scala 实现的
KeyedProcessFunction
示例,该示例展示了如何跟踪每组用户的最后活跃时间,并在用户超过5分钟未活动后发送通知:
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.api.common.time.Time
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala.OutputTag
import org.apache.flink.util.Collector
// 定义侧输出流标签
val inactiveUsersOutputTag = new OutputTag[String]("inactive-users") {
override def toString: String = "inactive-users"
}
class UserActivityTracker(
timeout: Time
) extends KeyedProcessFunction[String, UserEvent, (String, Boolean)] {
// 定义状态存储用户上次活跃时间
val lastActiveTimeState: ValueState[java.lang.Long] =
getRuntimeContext.getState(new ValueStateDescriptor("last-active-time", classOf[java.lang.Long]))
override def processElement(event: UserEvent, ctx: KeyedProcessFunction[String, UserEvent, (String, Boolean)]#Context, out: Collector[(String, Boolean)]): Unit = {
// 更新用户活跃时间
lastActiveTimeState.update(event.timestamp)
// 注册定时器,在超时后触发
ctx.timerService().registerEventTimeTimer(event.timestamp + timeout.toMilliseconds)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, UserEvent, (String, Boolean)]#OnTimerContext, out: Collector[(String, Boolean)], out2: Collector[(String, Boolean)] @UnusedParam): Unit = {
// 如果定时器触发,检查是否已超时
if (timestamp > lastActiveTimeState.value()) {
// 用户已超时未活跃
val userId = ctx.getCurrentKey
// 输出到侧输出流
out2.collect(userId)
// 可选地,也可以清除或更新状态
lastActiveTimeState.clear()
}
}
}
case class UserEvent(userId: String, timestamp: Long)
// 创建环境和数据源...
val env = StreamExecutionEnvironment.getExecutionEnvironment
val eventsStream = ...
// 应用 KeyedProcessFunction
val userActivities = eventsStream
.keyBy(_.userId)
.process(new UserActivityTracker(Time.minutes(5)))
// 获取侧输出流
val inactiveUsers = userActivities.getSideOutput(inactiveUsersOutputTag)
// 分别处理主输出流(活跃用户相关处理)和侧输出流(不活跃用户的通知)
inactiveUsers.print() // 假设打印不活跃用户ID
- WindowFunction:一种专门用来处理窗口数据的函数,它可以在窗口触发时对窗口内的所有元素进行一次性的处理。窗口可以基于时间(如每5分钟一个窗口)或数量(如每100个元素一个窗口)进行划分。
以下是一个使用 Scala 实现的
WindowFunction
示例,我们将计算每5分钟一组用户的点击次数:
import org.apache.flink.api.common.functions.WindowFunction
import org.apache.flink.api.java.tuple.Tuple2
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
case class ClickEvent(userId: String, timestamp: Long)
class ClickCounter extends WindowFunction[ClickEvent, Tuple2[String, Int], String, TimeWindow] {
override def apply(key: String, window: TimeWindow, inputs: Iterable[ClickEvent], out: Collector[Tuple2[String, Int]]): Unit = {
// 计算特定用户在给定时间窗口内的点击次数
val clickCount = inputs.size
// 输出用户ID和点击次数
out.collect(Tuple2(key, clickCount))
}
}
// 创建环境和数据源...
val env = StreamExecutionEnvironment.getExecutionEnvironment
val clickEventsStream = ...
// 定义时间窗口
val timeWindow = Time.minutes(5)
// 对事件进行分组并应用窗口函数
val userClickCounts = clickEventsStream
.keyBy(_.userId) // 根据用户ID进行分组
.timeWindow(timeWindow) // 应用时间窗口
.apply(new ClickCounter()) // 使用WindowFunction计算点击次数
// 打印结果或进一步处理
userClickCounts.print()
// 启动执行环境
env.execute("Click Count by User and Time Window")
版权归原作者 Oz_Mood 所有, 如有侵权,请联系我们删除。