
MySQL 优化
参考:
- 步步深入:MySQL 架构总览 -> 查询执行流程 -> SQL 解析顺序
- 颜群老师的课程:SQL 优化(MySQL 版)
基础
给 mysql 的超级管理员 root 增加密码:
/usr/bin/mysqladmin -u root password root
MySQL 核心目录:
- 安装目录:
/var/lib/mysql - 配置文件目录:
/usr/share/mysql - 命令目录:
/usr/bin- mysqladmin 是一个执行管理操作的客户端程序,可以用来检查服务器的配置、状态、修改密码、创建删除数据库等- mysqldump 是用于迁移和备份数据库的工具- …
MySQL 分层、存储引擎
- 连接层:提供与客户端连接的服务
- 服务层:提供各种用户使用的接口,提供 SQL 优化器 (MySQL Query Optimizer)
- 引擎层:提供各种存储数据的方式 (InnoDB、MyISAM)
- 存储层:存储数据
InnoDB 对比 MyISAM:
- InnoDB:事务优先(适合并发操作,行锁)
- MyISAM:性能优先(表锁)
# 查询 MySQL 中支持的引擎
show engines;# 常规表格显示
show engines \G # 清晰显示# 查询当前使用的引擎
show variables like '%storage_engine%';
+---------------------------------+-----------+
| Variable_name | Value |
+---------------------------------+-----------+
| default_storage_engine | InnoDB || default_tmp_storage_engine | InnoDB || disabled_storage_engines ||| internal_tmp_mem_storage_engine | TempTable |
+---------------------------------+-----------+
# 查询当前使用的字符集
show variables like '%character%';
示例:指定 MyISAM 引擎建表
CREATETABLE tb (
id INT(4)AUTO_INCREMENT,
name VARCHAR(5),
dept VARCHAR(5),PRIMARYKEY(id))ENGINE=MyISAM AUTO_INCREMENT=1DEFAULTCHARSET=utf8;
SQL 解析过程、索引、B 树
SQL 优化的原因:
- 性能低
- 执行时间长
- 等待时间长
- SQL 语句欠佳(连接查询)
- 索引失效
- 服务器参数设置不佳(缓冲、线程数)
SQL 编写过程和解析过程的差异:
- 编写过程-
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit - 解析过程-
from ... on ... join ... where ... group by ... having ... select distinct... order by ... limit - 参考文章:步步深入:MySQL架构总览 -> 查询执行流程 -> SQL解析顺序
-- 解析顺序SELECTDISTINCT<select_list>FROM<left_table><join_type>JOIN<right_table>ON<join_condition>WHERE<where_condition>GROUPBY<group_by_list>HAVING<having_condition>ORDERBY<order_by_condition>LIMIT<limit_number>-- 执行顺序FROM<left_table>ON<join_condition><join_type>JOIN<right_table>WHERE<where_condition>GROUPBY<group_by_list>HAVING<having_condition>SELECTDISTINCT<select_list>ORDERBY<order_by_condition>LIMIT<limit_number>
索引
索引是帮助 MySQL 高效获取数据的数据结构,一般采用树结构(B+ 树、Hash )
索引的优势与弊端
索引的弊端:
- 索引本身需要占用空间(一般是硬盘)
- 索引不适用于以下场景:少量数据、频繁更新的字段、很少使用的字段
- 索引提高查询效率,但是降低了增删改查效率
索引的优势:
- 降低 IO 使用率
- 降低 CPU 使用率(对于查询时的排序操作,B 树本身就是排好序的,可以直接使用)
B 树与索引
B 树与索引:
- 三层 B 树可以存放百万级别的数据
- B 树一般指 B+ 树,数据都保存在叶节点(查找数据的次数为 n 次,即 B+ 树的高度)
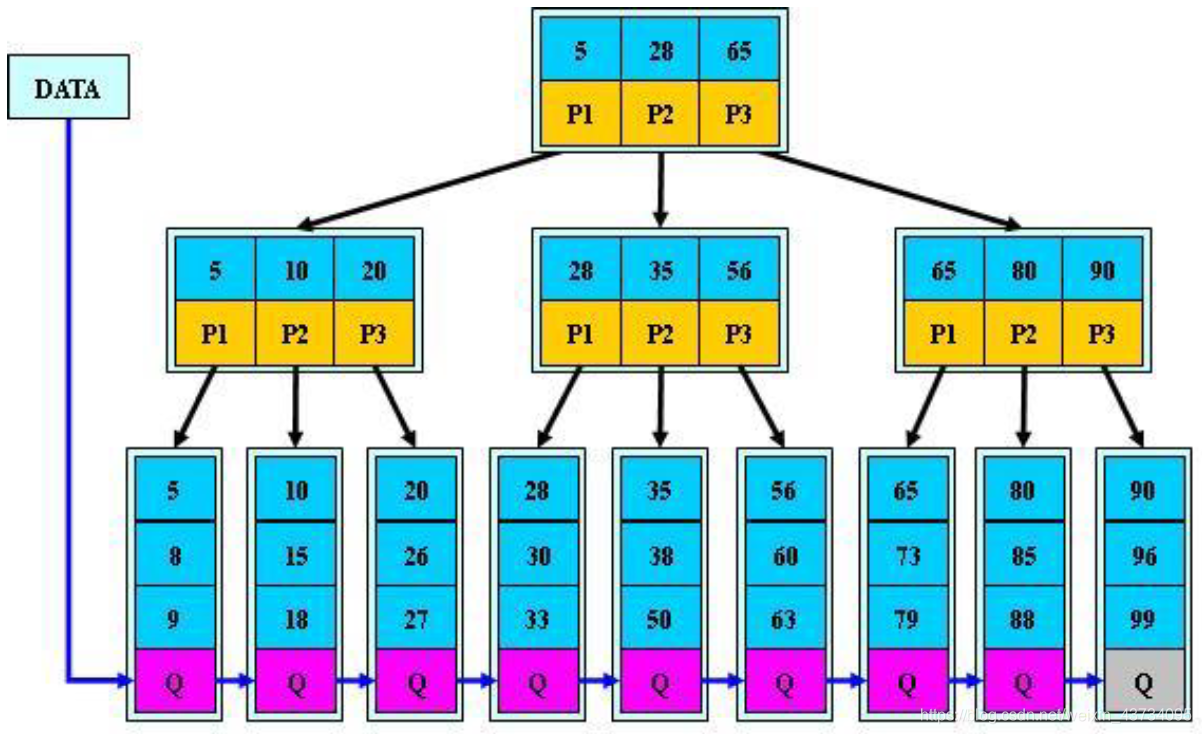
索引的分类:
- 单值索引:单列,一个表可以有多个单值索引
- 主键索引:不能重复,不能为 null
- 唯一索引:不能重复,可以为 null
- 复合索引:多个列构成的索引,相当于二级目录
注意: 如果一个字段是 primary key,则该字段默认就是 主键索引
索引相关操作
创建索引方式一:
create 索引类型 索引名 on 表(字段)
-- 单值索引CREATEINDEX dept_index ON tb(dept);-- 唯一索引CREATEUNIQUEINDEX name_index ON tb(name);-- 复合索引CREATEINDEX dept_name_index ON tb(dept, name);
创建索引方式二:
ALTER TABLE 表名 ADD 索引类型 索引名(字段)
-- 单值索引ALTERTABLE tb ADDINDEX dept_index(dept)-- 唯一索引ALTERTABLE tb ADDUNIQUEINDEX name_index(name)-- 复合索引ALTERTABLE tb ADDINDEX dept_name_index(dept, name)
DDL 语句不需要
commit;,会自动提交
删除索引:
DROP INDEX 索引名 on 表
DROPINDEX name_index ON tb;
查询索引:
SHOW INDEX FROM 表名
SHOWINDEXFROM tb;
执行计划 - EXPLAIN
SQL 性能问题:
- 分析 SQL 执行计划:
explain可以模拟 SQL 优化器执行 SQL 语句 - MySQL 的查询优化会干扰我们自己的优化
EXPLAINSELECT*FROM tb;

id编号select_type查询类型table表名type类型possible_keys预测用到的索引key实际用到的索引key_len实际使用索引的长度ref表之间的引用rows通过索引查询到的数据量Extra额外信息
数据准备
createtable course (
cid int(3),
cname varchar(20),
tid int(3));createtable teacher (
tid int(3),
tname varchar(20),
tcid int(3));createtable teacherCard (
tcid int(3),
tcdesc varchar(200));insertinto course values(1,'java',1);insertinto course values(2,'html',1);insertinto course values(3,'sql',2);insertinto course values(4,'web',3);insertinto teacher values(1,'tz',1);insertinto teacher values(2,'tw',2);insertinto teacher values(3,'tl',3);insertinto teacher values(4,'ta',4);insertinto teacher values(5,'tb',5);insertinto teacher values(6,'tc',6);insertinto teacherCard values(1,'tzdesc');insertinto teacherCard values(2,'twdesc');insertinto teacherCard values(3,'tldesc');
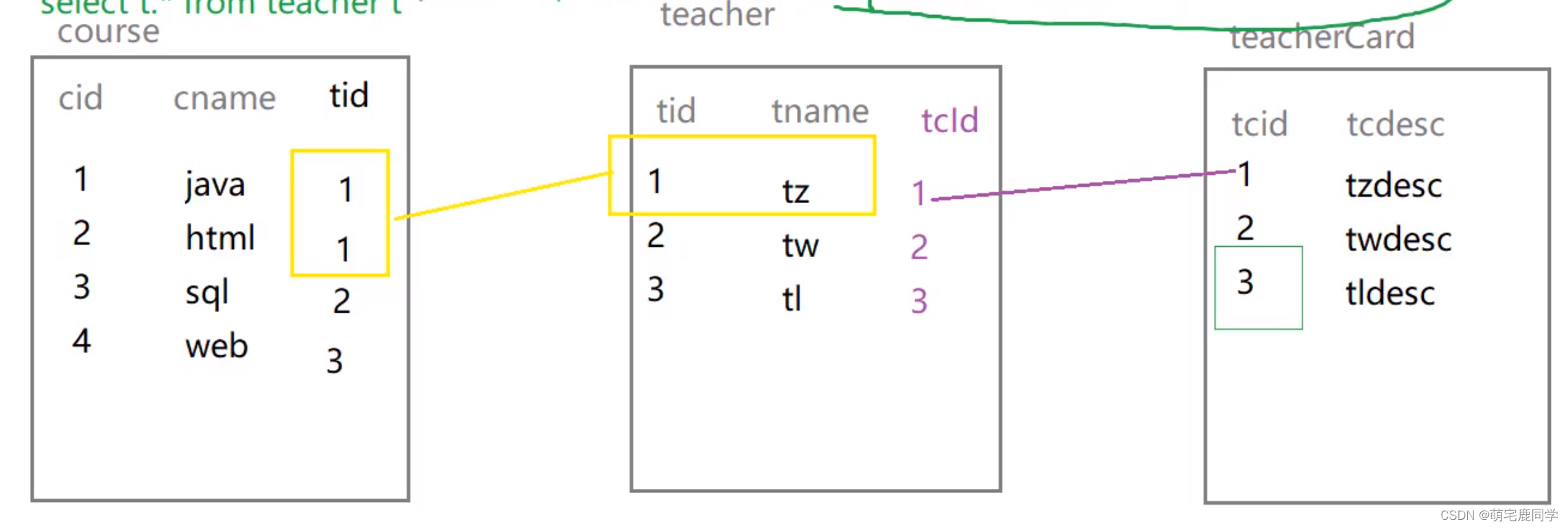
id - 编号
题目:查询课程编号为 2 或教师证编号为 3 的老师信息
EXPLAINSELECT teacher.*FROM course, teacher, teacherCard
WHERE course.tid = teacher.tid
AND teacher.tcid = teacherCard.tcid
AND(course.cid =2or teacherCard.tcid =3);
结论:
- id 值相同,从上往下,顺序执行;数据量小的表优先查询
题目:查询教授 SQL 课程的老师描述信息
-- 多表连接形式 - id 值相同EXPLAINSELECT teacherCard.tcdesc FROM teacherCard, course, teacher
WHERE course.tid = teacher.tid
AND teacher.tcid = teacherCard.tcid
AND course.cname='sql';-- 子查询形式 - id 值不同EXPLAINSELECT tcdesc FROM teacherCard WHERE teacherCard.tcid =(SELECT teacher.tcid FROM teacher WHERE teacher.tid =(SELECT course.tid FROM course));-- 多表 + 子查询 - id 值相同 + 不同EXPLAINSELECT teacher.tname,teacherCard.tcdesc FROM teacher, teacherCard
WHERE teacher.tcid = teacherCard.tcid
AND teacher.tid =(SELECT course.tid FROM course WHERE cname ='sql');
结论:
- id 值相同,从上往下,顺序执行;数据量小的表优先查询
- id 值不同,id 值大的优先查询。(本质:在嵌套子查询时,先查内层,再查外层)
- id 值相同 + 不相同,id 值大的优先执行,id 值相同的的从上往下顺序执行
select_type - 查询类型
- PRIMARY 包含子查询 SQL 中的注查询(最外层)
- SUBQUERY 包含子查询 SQL 中的子查询(非最外层)
- SIMPLE 简单查询,不包含子查询和 union
- DERIVED 衍生查询,使用到了临时表 - FROM 子查询中只有一张表
explainselect cr.cname from(select*from course where tid in(1,2)) cr;- from 子查询中,如果有table1 union table2,table1 就是 derivedexplainselect cr.cname from(select*from course where tid=1unionselect*from course where tid =2) cr; - union result - 告知关联关系的表是哪两张
type - 索引类型
索引类型排序:
system
const
eq_ref
ref
range
index
all
- system 和 const 是理想情况,一般无法达到
- 没有索引必然是 all
system:只有一条数据的系统表,或者衍生表只有一条数据的主查询
createtable test01
(
tid int(3),
tname varchar(20));altertable test01 addconstraint tid_pk primarykey(tid);insertinto test01 values(1,'a');explainselect*from(select*from test01) t where tid =1;
const:只能查到一条数据的 SQL(只能用于 primary key 或 unique 索引,一般索引不会出现 const)
-- 此时是 const 索引explainselect tid from test01 where tid =1;/* 删除 primary 索引 */altertable test01 dropprimarykey;/* 修改索引为一般索引 */createindex test01_index on test01(tid);-- 此时查不是 const 索引explainselect tid from test01 where tid =1;
eq_ref:对于每个索引键的查询,返回匹配有且只有一行数据(常见于唯一索引和主键索引)
altertable teacherCard addconstraint pk_tcid primarykey(tcid);altertable teacher addconstraint uk_tcid uniqueindex(tcid);deletefrom teacher where tcid>3;explainselect t.tcid from teacher t, teacherCard tc where t.tcid = tc.tcid;
上述语句用到的索引是 teacher 表的 tcid 字段
如果 teacher 表的数据个数和连接查询的数据个数一致,才有可能满足 eq_ref 级别
ref:非唯一索引,对于每个索引键的查询,返回匹配的所有行
insertinto teacher values(4,'tz',4);insertinto teacherCard values(4,'tzc');altertable teacher addindex index_name(tname);explainselect*from teacher where tname='tz';
range:检索指定范围的行,where 后面是一个范围查询
between、in、<、>、>=、<=in查询,有时会失效,从 range 级别转为 all 无索引级别
altertable teacher addindex tid_index(tid);explainselect t.*from teacher t where t.tid <3;
index:查询全部索引数据
all:查询全部数据
总结:
system/const:结果只有一条eq_ref:结果有多条,每条数据唯一ref:结果有多条,每调数据可能是多条
possible_keys、key
- possible_keys 是对可能用到的索引的预测
- key 是实际用到的索引
NULL 表示无索引
key_len - 索引的长度
key_len 代表索引的长度,用于判断复合索引是否被完全使用
- utf8 编码下,对于
char(20)有key_len = 60(1 个字符占 3 个字节) - 如果索引字段可以为 null,MySQL 底层会用 1 个字节用于标识
- 索引字段为 Varchar,MySQL 用 2 个字节代表可变长度
- utf8mb4 中,一个字符占 4 个字节
- utf8 中,1 个字符占 3 个字节
- gbk 中,1 个字符 2 个字节
- latin 中,一个字符 1 个字节
createtable test_kl
(
name char(20)notnulldefault'');altertable test_kl addindex index_name(name);explainselect*from test_kl where name='';altertable test_kl addcolumn name1 char(20);altertable test_kl addindex index_name1(name1);explainselect*from test_kl where name1='';dropindex index_name on test_kl;dropindex index_name1 on test_kl;altertable test_kl addindex name_name1_index (name, name1);explainselect*from test_kl where name1='';altertable test_kl addcolumn name2 varchar(20);altertable test_kl addindex name2_index(name2);/* key_len = 83 = 80 + 1(null) + 2(varchar) */explainselect*from test_kl where name2='';
ref - 当前表参照的字段
与 type 中的 ref 进行区分
ref 指明当前表所参照的字段
select ... where a.c=b.x,其中b.x可以是常量
altertable course addindex tid_index(tid);explainselect*from course c, teacher t where c.tid = t.tid and t.tname='tw';
rows - 通过索引查询到的数据量
rows:扫描的行数
explainselect*from course c, teacher t where c.tid = t.tid and t.tname='tz';
Extra - 额外信息
Using filesort
- 性能消耗大,需要额外一次排序或查询
- 如果排序和查找不是同一个字段,则会出现 Using filesort
- 如果符合索引跨列,会出现 Using filesort - where 和 order by 按照符合索引的顺序使用,不要跨列或无序
- 常见于 order by
createtable test02
(
a1 char(3),
a2 char(3),
a3 char(3),index idx_a1(a1),index idx_a2(a2),index idx_a3(a3));/* 排序和查找不是同一个字段 Using filesort */explainselect*from test02 where a1 =''orderby a2;dropindex idx_a1 on test02;dropindex idx_a2 on test02;dropindex idx_a3 on test02;altertable test02 addindex idx_a1_a2_a3(a1, a2, a3);/* 复合索引跨列 */explainselect*from test02 where a1=''orderby a3;explainselect*from test02 where a2=''orderby a3;explainselect*from test02 where a1=''orderby a2;
Using temporary
- 用到了临时表
- 常用于 groub by
- 避免方法:查询哪列就使用哪列 group by
explainselect a1 from test02 where a1 in('1','2','3')groupby a2;
Using index
- 使用到的列都在索引中,称为索引覆盖
- 性能提升
- 不读取原文件,只从索引文件中获取数据
- 不需要回表查询
- 索引覆盖对 possible_keys 和 key 的影响 - 如果没有 where,则索引只出现在 key 中- 如果有 where,则索引出现在 key 和 posiible_keys 中
explainselect a1, a2 from test02 where a1=''or a2='';dropindex idx_a1_a2_a3 on test02;altertable test02 addindex id_a2_a2(a1, a2);explainselect a1, a3 from test02 where a1=''or a3='';/* 对 possible_keys 和 key 的影响 */explainselect a1, a2 from test02 where a1=''or a2='';explainselect a1, a2 from test02;
Using where
- 回表查询
explainselect a1, a3 from test02 where a3 ='';
Impossible WHERE
- where 子句永远为 false
explainselect*from test02 where a1='x'and a1='y';
Using join buffer
- MySQL 引擎使用了连接缓存
SQL 优化
优化示例
createtable test03
(
a1 int(4)notnull,
a2 int(4)notnull,
a3 int(4)notnull,
a4 int(4)notnull);altertable test03 addindex idx_a1_a2_a3_4(a1, a2, a3, a4);/* Using index *//* 推荐按照复合索引的顺序查询 */explainselect a1, a2, a3, a4 from test03 where a1=1and a2=2and a3=3and a4=4;/* Using index *//* 经过 SQL 优化器后,效果与上一个查询语句一致 */explainselect a1, a2, a3, a4 from test03 where a4=1and a3=2and a2=3and a1=4;/* Using where; Using index *//* a4 跨列,索引失效,造成回表查询 *//* where a1=1 and a2=2 ... order by a3 仍然遵循复合索引的顺序,因此有 Using index */explainselect a1, a2, a3, a4 from test03 where a1=1and a2=2and a4=4orderby a3;/* Using where; Using index; Using filesort *//* where a1=1 ... order by a3 跨列,多了一次查找/排序,出现 Using filesort */explainselect a1, a2, a3, a4 from test03 where a1=1and a4=4orderby a3;
总结:
- 如果复合索引使用顺序完全一致,索引全部使用;部分一致,索引部分使用
- where 和 order 的拼接不要跨列
单表优化及总结
数据准备:
createtable book
(
bid int(4)primarykey,
name varchar(20)notnull,
authorid int(4)notnull,
publicid int(4)notnull,
typeid int(4)notnull);insertinto book values(1,'java',1,1,2);insertinto book values(2,'html',2,1,2);insertinto book values(3,'sql',3,2,1);insertinto book values(4,'C',4,4,3);
SQL 优化过程:
-- 默认不进行优化,进行查询/* type:All*//* Using where; Using filesort */explainselect bid from book where typeid in(2,3)and authorid=1orderby typeid desc;-- 优化:给每个字段设置索引,再进行查询/* type:index *//* Using where; Using index; Using filesort */altertable book addindex idx_bta(bid, typeid, authorid);/* 为避免干扰,优化之前删除老的索引 */dropindex idx_bta on book;/* 根据 sql 实际解析的顺序,调整索引顺序 *//* type:index *//* Using where; Using index */altertable book addindex idx_tab(typeid, authorid, bid);/* 删除索引,创建新索引测试 */dropindex idx_tab on book;/* 将出现范围查询的字段 typeid 放到后面 */altertable book addindex idx_atb(authorid, typeid, bid);/* 将范围查询 typeid in (2, 3) 放到 authorid=1 后面 *//* type:ref *//* Using where; Using index *//* key_len: 4 */explainselect bid from book where authorid=1and typeid in(2,3)orderby typeid desc;/* Using index *//* key_len: 8 *//* typeid in(2, 3) 改为 typeid=3,不使用范围查询,typeid 索引有效 *//* 通过 key_len 也可以佐证,此处有 2 个索引,typeid 索引有效 */explainselect bid from book where authorid=1and typeid=3orderby typeid desc;
总结:
- 索引不能跨列使用,保持索引定义和使用顺序一致性
- 索引需要逐步优化
- 将含 in 的范围查询放到条件最后,防止整个索引失效
同时出现了 Using index 和 Using where:
Using index,由于where authorid = 1 ...,authorid 在索引中,不需要回原表
Using where,由于... and typeid in (2, 3),typeid 在索引中,但是使用了 in 范围查询,索引失效,需要回原表
多表优化及总结
数据准备:
createtable teacher2
(
tid int(4)primarykey,
cid int(4)notnull);insertinto teacher2 values(1,2);insertinto teacher2 values(2,1);insertinto teacher2 values(3,3);createtable course2
(
cid int(4),
cname varchar(20));insertinto course2 values(1,'java');insertinto course2 values(2,'python');insertinto course2 values(3,'kotlin');/* 左连接,将数据量少的表放到左边 *//* type:All *//* Extra: *//* type:All *//* Extra: Using where; Using join buffer */explainselect*from teacher2 t leftouterjoin course2 c
on t.cid=c.cid where c.cname='java';/* 增加索引 *//* type: index *//* Extra: Using index *//* type: All *//* Extra: Using where; Using join buffer*/altertable teacher2 addindex index_teacher2_cid(cid);/* type: ref *//* Extra: Using where *//* type: ref *//* Extra: Using index*/altertable course2 addindex index_course2_cname(cname);
索引添加原则:
- 小表驱动大表
- 索引建立在经常使用的字段上
- 左外连接,给左表加索引;右外连接,给右表加索引
三表或更多表使用相同的原则
避免索引失效的原则
/* 2 个索引都有效 *//* type:ref *//* Extra: *//* key_len: 8 */explainselect*from book where authorid=1and typeid=2;/* 只有 1 个索引有效 *//* type:ref *//* Extra: using where *//* key_len: 4 */explainselect*from book where authorid=1and typeid*2=2;/* 2 个索引都失效 *//* type:All *//* Extra: using where *//* key_len: NULL */explainselect*from book where authorid*2=1and typeid*2=2;/* 2 个索引都失效,复合索引左边失效,整个索引失效 *//* type:All *//* Extra: using where *//* key_len: NULL */explainselect*from book where authorid*2=1and typeid=2;/* 删除复合索引 */dropindex idx_atb on book;altertable book addindex idx_authorid(authorid);altertable book addindex idx_typeid(typeid);/* 1 个索引都失效,独立索引,第 1 个索引失效,不影响后面的索引 *//* type:ref *//* Extra: using where *//* key_len: 4 */explainselect*from book where authorid*2=1and typeid=2;/* 索引有效 */explainselect*from book where authorid =1and typeid =2;/* 使用了不等于,索引失效 */explainselect*from book where authorid !=1and typeid =2;
避免索引失效的原则:
- 复合索引,不要跨列或无序使用
- 尽量使用全索引匹配
- 不要在索引上进行任何操作(计算、函数、类型转换、如
... where a.x * 3) - 复合索引,左边索引失效,所有索引失效
- 复合索引使用不等于 (
!=、<>) 或者is null,自身索引会失效,右侧索引可能会失效 - MySQL 本身有 sql 优化器,实际优化效果并非百分之百达到预期
索引优化与预期不符合的情况
dropindex idx_typeid on book;dropindex idx_authorid on book;altertable book addindex idx_book_at(authorid, typeid);/* 复合索引全部使用 *//* key_len:8 *//* type: ref */explainselect*from book where authorid =1and typeid =2;/* where 中最左侧的索引字段有 > 号,复合索引中自身及右侧全部失效 *//* type:All *//* Extra: Using where *//* key_len: NULL */explainselect*from book where authorid >1and typeid =2;/* 最右侧索引使用了 > 号,复合索引没有失效 *//* type: range *//* Extra: Using where *//* key_len: 8 */explainselect*from book where authorid =1and typeid>2;/* 复合索引只有 1 个生效 *//* type: range *//* key_len: 4 *//* Extra: Using where */explainselect*from book where authorid <1and typeid=2;/* 相比上一条 SQL,只将 authorid<1 改为 authorid<4,右侧索引也失效 *//* type: ALL *//* key_len: NULL *//* Extra: Using where */explainselect*from book where authorid <4and typeid=2;/* 使用百分号开头,索引失效 *//* type: ALL *//* key_len: NULL *//* Extra: Using where */explainselect*from teacher where tname like'%x%';/* 不使用百分号开头,索引仍然有效 *//* type: range *//* key_len: NULL *//* Extra: Using where */explainselect*from teacher where tname like'x%';/* 使用百分号开头,但是实现索引覆盖,仍然起到了一定的优化作用 *//* type: index *//* key_len: 63 *//* Extra: Using where; Using index */explainselect tname from teacher where tname like'%x%';/* tname 和 'abc' 都是字符形式,索引有效 *//* type: ref *//* key_len: 63 *//* Extra: Using where */explainselect*from teacher where tname ='abc';/* tname 是字符类型,123 是整数,查找时有类型转换操作,导致索引失效 *//* type: ALL *//* key_len: NULL *//* Extra: Using where */explainselect*from teacher where tname =123;/* 使用 and,索引仍然有效 *//* type: ref *//* key_len: 63 *//* Extra: Using where */explainselect*from teacher where tname =''and tcid>1;/* 使用了 or,导致 or 左侧的索引也失效 *//* type: ALL *//* key_len: NULL *//* Extra: Using where */explainselect*from teacher where tname =''or tcid>1;
- 一般情况,范围查询之后的索引失效
- 使用索引覆盖,索引优化会完全符合预期
- like 尽量以常量开头,不以
'%'开头,否则索引失效 - 使用类型转换(显式或隐式),会导致索引失效
- 使用 or 会导致索引失效,甚至会影响左侧的索引
常见的优化方法及慢 SQL 排查
exists 和 in
/* 有数据 */select tname from teacher whereexists(select*from teacher);/* 无数据 */select tname from teacher whereexists(select*from teacher where tid=9999);
- 如果主查询数据集大,使用 in
- 如果子查询数据集大,使用 exist
exists 的作用:将主查询的结构放到子查询结果中进行条件校验
- 如果子查询有数据,则校验成功
- 如果符合校验,则保留数据
order by 优化
双路排序: MySQL 4.1 之前的默认策略,扫描 2 次磁盘
- 第 1 次:从磁盘读取排序字段,对排序字段进行排序,在 buffer 中进行排序
- 第 2 次:扫描其他字段
单路排序:一次读取全部磁盘,在 buffer 中进行排序
- 不一定是真正的单路,仍然有可能是多次 IO(数据量过大时,分片读取)
单路排序比双路排序占用更多 buffer
调整 buffer 大小:
set max_length_for_sort_data=1024
单路自动切换到双路的条件:需要排序的列总大小超过
set max_length_for_sort_data=1024
定义的字节数
提高 order by 效率的策略:
- 选择使用单路,双路
- 调整 buffer 容量大小
- 避免使用
select * - 复合索引避免跨列
- 保证全部排序字段顺序的一致性
慢查询日志
慢查询日志:MySQL 用于记录响应时间超过阈值的 SQL 语句
long_query_time- 阈值(默认 10 秒)- 慢查询日志模式是关闭的,需要手动开启(建议调优时打开,部署上线时关闭)
开启慢查询日志:
- 检查是否开启了慢查询日志:
show variables like '%slow_query_log%'; - 临时开启:
set global slow_query_log =1;,mysql 服务重启后失效 - 永久开启:
vi /etc/my.cnf
# 配置文件中添加以下内容[mysqld]slow_query_log=1slow_query_log_file=/var/lib/mysql/localhost-slow.log
慢查询阈值修改:
- 查询慢查询阈值:
show variables like '%long_query_time%'; - 临时修改:
set global long_query_time=5;,重新登录后生效 - 永久修改:
vi /etc/my.cnf
[mysqld]long_query_time=3
相关基础语句:
- 休眠模拟慢查询:
select sleep(4); - 查询超过阈值的 SQL 数量:
show global status like '%slow_queries%'; - 在 Linux 命令行,通过日志查看慢查询 SQL 的详情:
cat /var/lib/mysql/localhost-slow.log
使用 mysqldumpslow 工具分析慢查询:
mysqldumpslow 各种参数 慢查询日志文件路径
- s 排序方式
- r 逆序
- l 锁定时间
- g 正则匹配模式
/* 模拟慢查询 */select sleep(5);select sleep(4);select sleep(3);/* 获取返回记录最多的 3 个 SQL */
mysqldumpslow -s r -t 3/var/lib/mysql/bigdata01-slow.log
/* 获取访问次数最多的 3 个 SQL */
mysqldumpslow -s c -t 3/var/lib/mysql/bigdata01-slow.log
/* 按照时间排序,前 10 条包含 left join 查询语句的 SQL */
mysqldumpslow -s t -t 10-g "left join"/var/lib/mysql/bigdata01-slow.log
模糊并通过 profiles 分析海量数据
1、建表:
createdatabase testdata;use testdata;createtable dept
(
dno int(5)primarykeydefault0,
dname varchar(20)notnulldefault'',
loc varchar(30)default'')engine=innodbdefaultcharset=utf8;createtable emp
(
eid int(5)primarykey,
ename varchar(20)notnulldefault'',
job varchar(20)notnulldefault'',
deptno int(5)notnulldefault0)engine=innodbdefaultcharset=utf8;
2、创建存储函数:
use testdata;delimiter $
createfunction randstring(n int)returnsvarchar(255)begindeclare all_str varchar(100)default'abcdefghijklmnopqrestuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';declare return_str varchar(255)default'';declare i intdefault0;while i<n
doset return_str=concat(return_str, substring(all_str, FLOOR(1+rand()*52),1));set i=i+1;endwhile;return return_str;end $
慢查询日志 与 存储过程/存储函数 冲突错误:
/* 开启慢查询日志,再创建存储过程/存储函数,报如下错误 *//* ERROR 1418 (HY000):
This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA
in its declaration and binary logging is enabled
(you *might* want to use the less safe log_bin_trust_function_creators variable) *//* 临时解决 */setglobal log_bin_trust_function_creators=1;
# 永久解决vi /etc/my.cnf
[mysqld]log_bin_trust_function_creators=1
3、通过存储函数插入随机整数:
use testdata;createfunction ran_num()returnsint(5)begindeclare i intdefault0;set i=floor(rand()*100);return i;end$
4、通过存储过程插入海量数据:
emp 表:
createprocedure insert_emp(in eid_start int(10),in data_times int(10))begindeclare i intdefault0;set autocommit =0;repeatinsertinto emp values(eid_start+i, randstring(5),'other', ran_num());set i=i+1;
until i=data_times
endrepeat;commit;end $
dept 表:
createprocedure insert_dept(in dno_start int(10),in data_times int(10))begindeclare i intdefault0;set autocommit =0;repeatinsertinto dept values(dno_start+i, randstring(6), randstring(8));set i=i+1;
until i=data_times
endrepeat;commit;end $
调用存储函数,插入数据:
delimiter;call insert_emp(1000,800000);call insert_dept(10,30);/* 验证插入数据量 */selectcount(1)from emp;
5、分析海量数据
show variables like'%profiling%';/* profiling 影响性能,在部署实施前,应关闭此项 */set profiling=on;/* 记录 profiling 打开之后的所有 SQL 语句消耗的时间 */show profiles;/* 精确查询更多详情,Query_Id 参考上个语句的查询结果 */show profile allfor query 2;show profile cpu, block io for query 2;
全局查询日志
show variables like'%general_log%';/* 开启全局日志,记录开启之后的所有 SQL 语句 */setglobal general_log=1;/* 将日志记入表中 */setglobal log_output='table';/* 设置后执行一条查询 */selectcount(1)from dept;/* 显示日志信息 */select*from mysql.general_log;/* 将日志记入文件 */setglobal log_output='file';/* 通过默认保存地址查看日志文件 */
cat /var/lib/mysql/bigdata01.log;
开启 general_log 后,所有 SQL 会被记录到系统自带的 mysql.general_log 表中
锁机制详解
锁机制:解决因资源共享造成的并发问题
按 操作类型 进行分类:
- 读锁(共享锁):对同一条数据,多个读操作可以同时进行,互不干扰
- 写锁(互斥锁):如果当前写操作没有完毕,则无法进行其他读操作
按 操作范围 进行分类:
- 表锁: - 对整张表加锁- 开销小,加锁快- 无死锁- 容易发生锁冲突(同时操作一条数据的概率增高)- 并发度低- MyISAM 采用表锁
- 行锁: - 对一条数据加锁- 开销大,加锁慢- 容易出现死锁- 锁的范围较小,不易发生锁冲突- 高并发概率低- InnoDB 采用行锁行锁
- 页锁
表锁
/* MYSQL/SQLSERVER 支持自增,Oracle 需要借助于序列来实现自增 */createtable tablelock
(
id intprimarykeyauto_increment,
name varchar(20))engine myisam;insertinto tablelock(name)values('a1');insertinto tablelock(name)values('a2');insertinto tablelock(name)values('a3');insertinto tablelock(name)values('a4');insertinto tablelock(name)values('a5');/* 查看加锁情况 */showopentables;/* 加锁 */locktable tablelock read;/* 加锁后可以读 */select*from tablelock;/* 加锁后不能写 *//* ERROR 1099 (HY000): Table 'tablelock' was locked with a READ lock and can't be updated */deletefrom tablelock where id=1;/* 加锁后,当前会话不能对其他表进行读操作 *//* ERROR 1100 (HY000): Table 'dept' was not locked with LOCK TABLES */selectcount(1)from dept;/* 加锁后,当前会话不能对其他表进行写操作 *//* ERROR 1100 (HY000): Table 'dept' was not locked with LOCK TABLES */insertinto dept values(39,'xxxxxx','yyyyyyyy');/* 释放锁 */unlocktables;
会话:每一个访问数据库的 dos 命令行、数据库客户端工具,都是一个会话
当前会话,对 A 表加了 read 锁:
- 该会话对 A 表:可以读,不能写
- 该会话对其他表:不能读,不能写
此时其他会话:
- 对 A 表:可以读,需要等待锁释放后可以写
- 对其他表:可以读,可以写
写锁
/* 加写锁 */locktable tablelock write;/* 不能对其他表进行任何操作 *//* ERROR 1100 (HY000): Table 'dept' was not locked with LOCK TABLES */selectcount(1)from dept;
当前会话,对 A 表加 write 锁:
- 当前会话对 A 表:可以进行任何操作
- 当前会话对其他表:不能进行任何操作
- 其他会话:对 A 表进行操作的前提是等待写锁释放
MyISAM 模式特征
- MyISAM 在执行查询语句前,会自动给涉及的所有表加读锁
- MyISAM 在执行更新操作 (DML) 前,会自动给涉及的表加写锁
对 MyISAM 表进行读操作:
- 其他进程对同一表的操作 - 读:不阻塞- 写:阻塞
- 只有读锁释放后,才会执行其他进程的写操作
对 MyISAM 表进行写操作:
- 其他进程对同一表操作 - 读:阻塞- 写:阻塞
- 只有写锁释放后,才会执行其他进程的写操作
表锁情况分析
查看哪些表加了锁:
show open tables;
分析表锁定的严重程度:
show status like '%table%'
Table_locks_immediate- 能够获取到的锁Table_locks_waited- 需要等待的锁
Table_locks_immediate/
Table_locks_waited5000
- 满足上面的情况建议使用 InnoDB 引擎,否则建议使用 MyISAM 引擎
- 获取到的资源充分时,使用行锁,因此采用 InnoDB
行锁
createtable linelock
(
id int(5)primarykeyauto_increment,
name varchar(20))engine=innodb;insertinto linelock(name)values('1');insertinto linelock(name)values('2');insertinto linelock(name)values('3');insertinto linelock(name)values('4');insertinto linelock(name)values('5');set autocommit=0;/* 当前会话操作第 6 行 */insertinto linelock values(6,'a6');/* 其他会话操作第 6 行 *//* 无法操作,需要等待锁释放 */update linelock set name='ax'where id=6;/* 其他会话操作第 8 行,没有锁,可以操作 */insertinto linelock values(8,'a8');
某个会话对一行数据进行 DML 操时,其他会话需要等待锁释放
释放锁的方法:
- 表锁:
unlock tables;或commit / rollback事务提交 - 行锁:
commit / rollback事务提交
行锁的注意事项
行锁转为表锁
如果没有索引,行锁会转为表锁
showindexfrom linelock;/* 为 name 列增加索引 */altertable linelock addindex idx_linelock_name(name);/* 当前会话操作 name='3' 的行 */update linelock set name='a3x'where name='3';/* 其他会话操作 name='4' 的行 *//* name 列索引有效,不同的行操作互不影响 */update linelock set name='a4x'where name='4';/* 当前会话操作 name=3 的行 *//* name 列是 varchar 类型,而 3 是整数类型,类型转换时索引失效,行锁转为表锁 */update linelock set name='a3x'where name=3;/* 其他会话操作 name='4' 的行 *//* name 列索引失效,表被锁定,无法操作 name='4' 行,需要等待锁释放 */update linelock set name='a4x'where name='4';
间隙锁
间隙锁是行锁的一种特殊情况,MySQL 会自动给间隙加锁
/* 不存在 id=7 的数据,此时 MySQL 会自动加上间隙锁 */update linelock set name='x'where id>1and id<9;/* 其他会话操作 id=7 需要等待锁释放 */insertinto linelock value(7,'a7');
行锁分析
- 如果加锁时有 where 语句,where 范围内的数据都会被加锁
- 并发能力强,效率高
showstatuslike'%innodb_row_lock%';
类型说明Innodb_row_lock_current_waits当前正在等待锁的进程数量Innodb_row_lock_time从系统启动到现在,等待总时长Innodb_row_lock_time_avg从系统启动到现在,平均等待时长Innodb_row_lock_time_max从系统启动到现在,最大等待时长Innodb_row_lock_waits从系统启动到现在,等待次数
查询行锁
/* for update 为查询语句加锁 */select*from linelock where id=2forupdate;/* 其他会话操作该行要等待锁释放 */update linelock set name='x'where id=2;
关闭事务自动提交的三种方式
set autocommit =0;start transaction;begin;
版权归原作者 萌宅鹿同学 所有, 如有侵权,请联系我们删除。