
🏖️作者:@malloc不出对象
⛺专栏:《初识C语言》
👦个人简介:一名双非本科院校大二在读的科班编程菜鸟,努力编程只为赶上各位大佬的步伐🙈🙈

目录
前言
今天我们要来探究的内容是一个或者多个源文件(.c)是如何变成一个可执行程序(.exe)的,博主将在Linux环境gcc编译器中进行分步演示,让你深入理解程序环境。
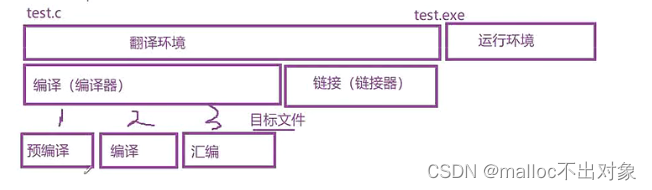
程序的翻译环境和执行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。
第2种是执行环境,它用于实际执行代码
我们来简单的看下示意图: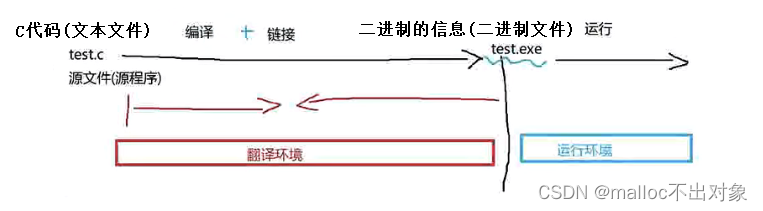
一. 程序的翻译环境
我们通常把
一个或多个源文件(.c)
形成
一个(.exe)可执行程序
叫做翻译环境,在这个环境中它其实就是将
源代码
转换为
可执行的机器指令
。
我们来简单看下形成过程,首先我们创建了一个源文件,并没有编译运行这个程序。
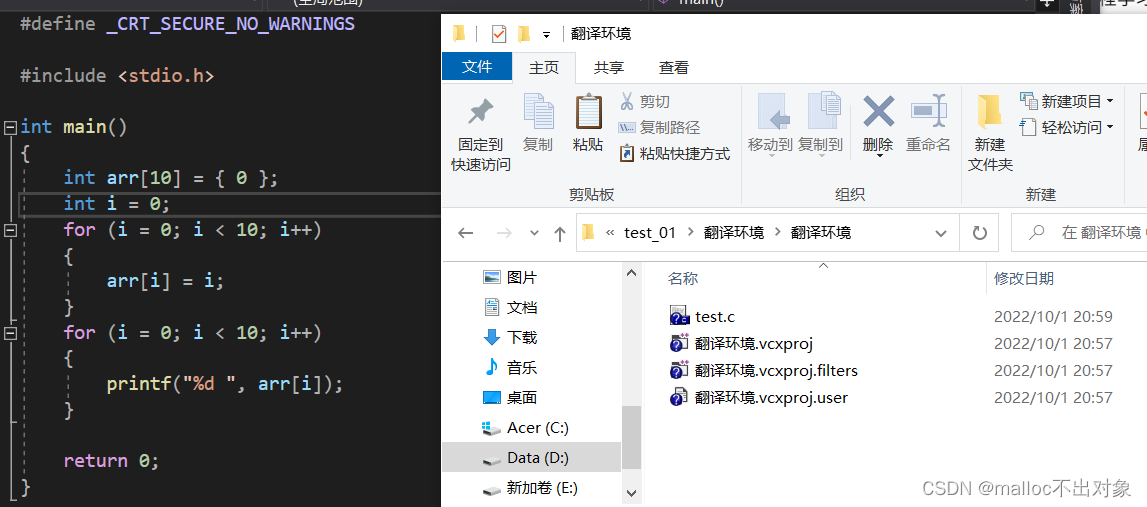
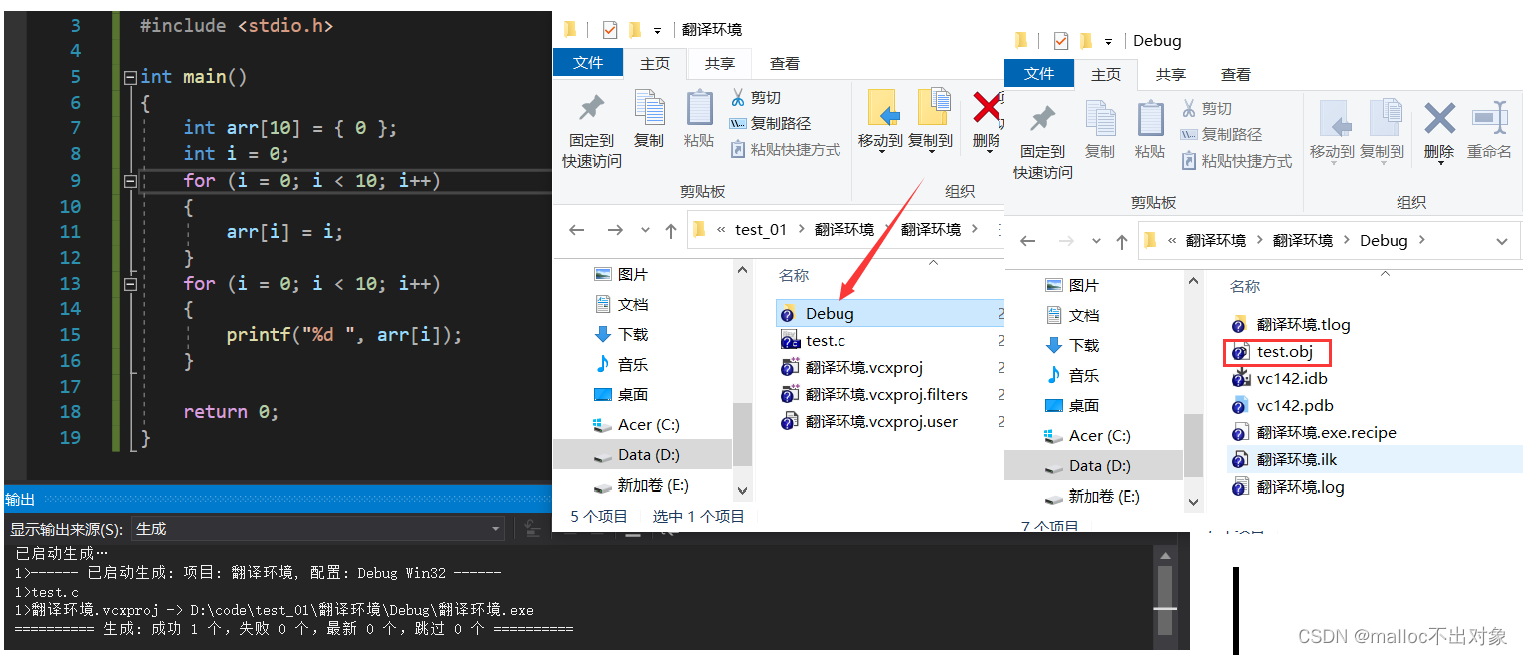
接下来我们运行一下这段程序,我们在源文件目录下发现了
Debug
文件,点击进入我们看到了
.obj
目标文件等一些其他文件:
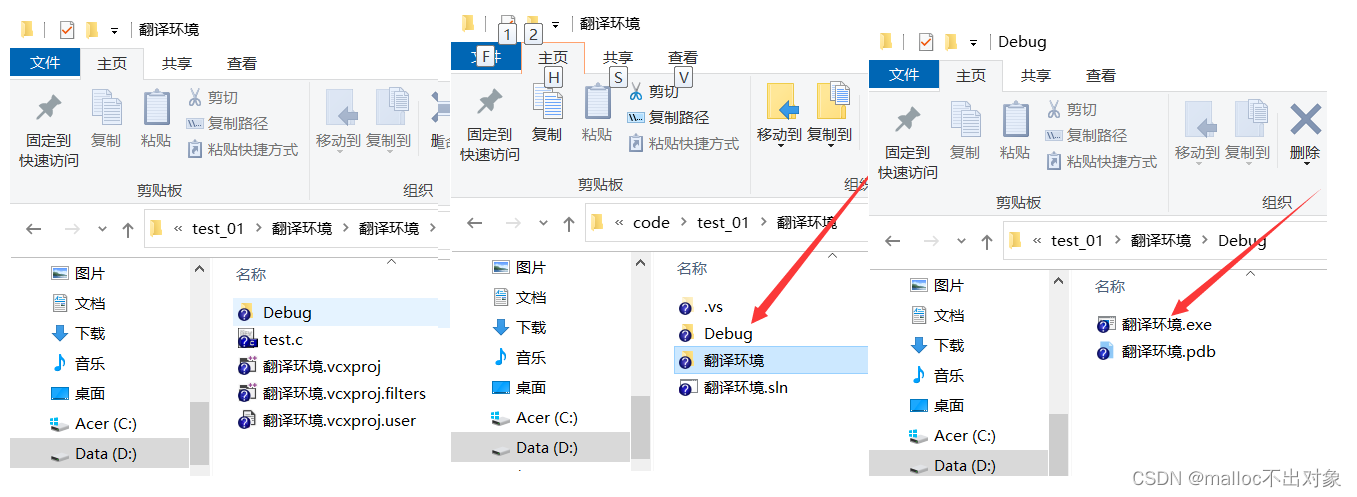
我们返回上一目录,点击进入
Debug
文件在里面我们发现了
.exe
可执行程序。
那如果是多个源文件组合在一起,程序运行之后它又会产生几个
.obj目标文件
和
.exe可执行程序
呢?请看下图例子:
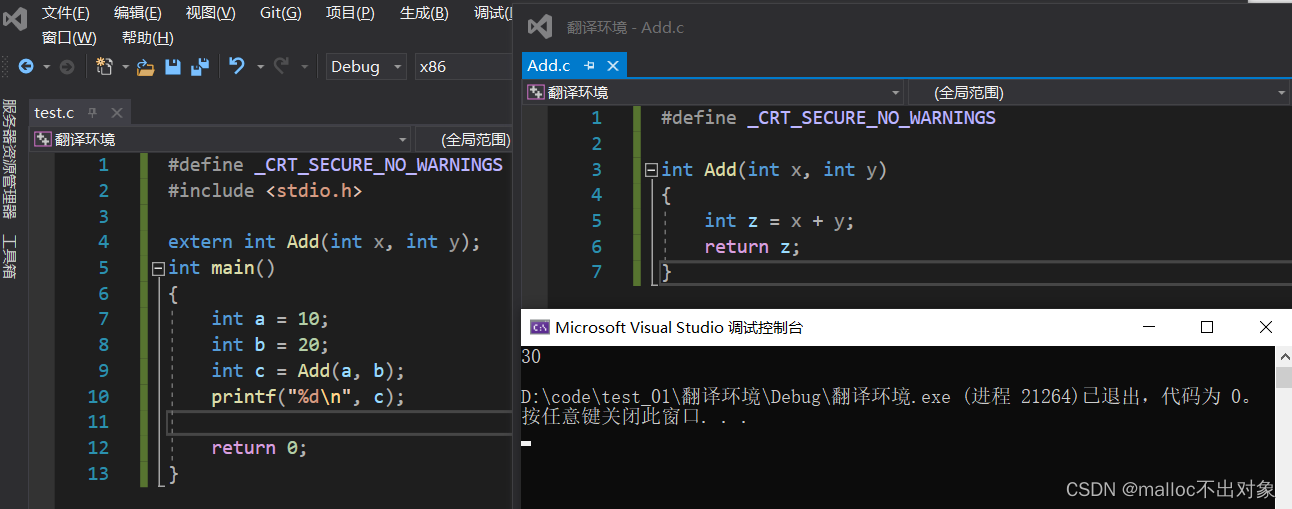
相信大家都知道这两个源文件组合运行起来能得出正确答案,那么它到底生成了几个
.obj目标文件
和
.exe可执行程序
呢?下面我们一起来观察一下目录。
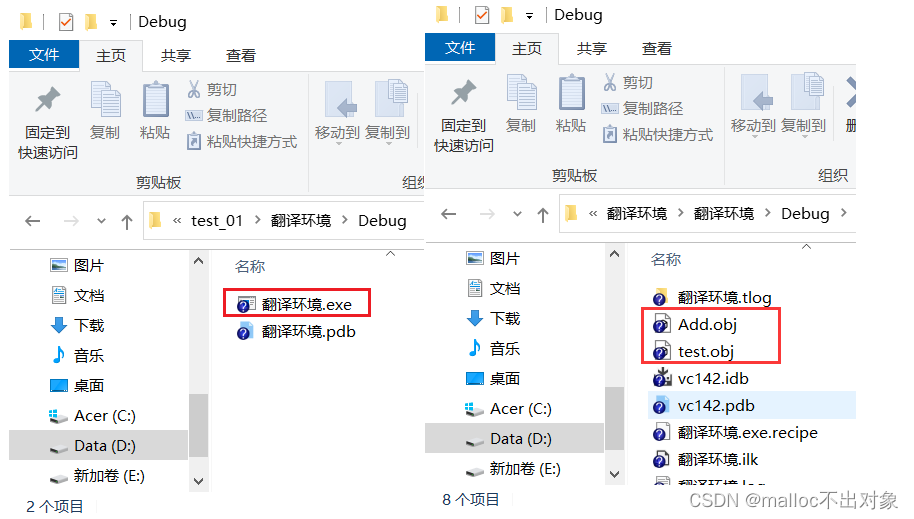
我们发现目录下出现了两个
.obj目标文件
,而只生成了
一个可执行程序
。由此,我们是不是能初步的得出一个小结论:每个源文件经过编译过程都会形成各自的.obj目标文件,但.exe可执行程序只有一个。
下面这幅图就是整个翻译环境中的各个过程了: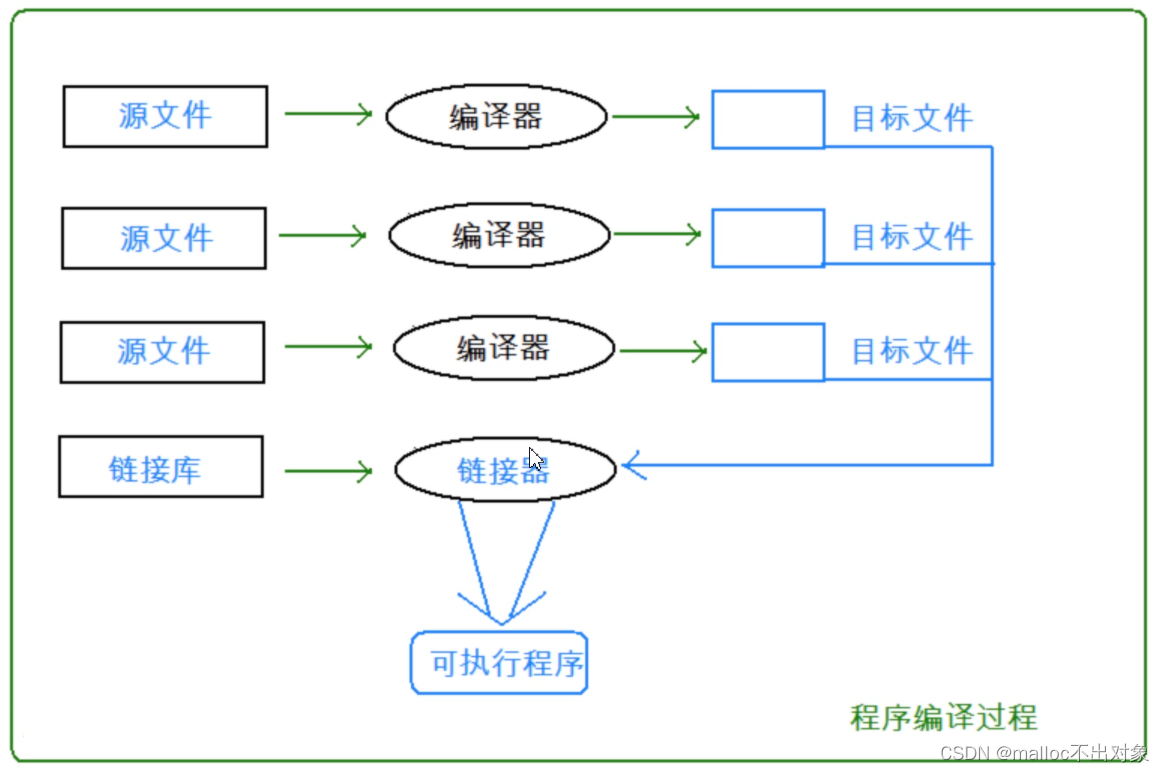
翻译环境可分为两个过程:
翻译+链接。这里我们的
编译器执行
编译操作,
链接器执行
链接操作。
- 组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)。
- 每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。
- 链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中。
1. 编译
关于上述的翻译环境我们只是讲了一个大概,并没有进行深入的分析。编译分为:预处理、翻译、汇编三个阶段。
下面我将带大家在Linux环境
gcc
编译器中进行深入的分析每一步的过程,有些读者可能没有学习过Linux环境中的一些命令操作,这没有关系你只要保证自己能听懂就OK。
1.1 预处理
首先我们创建一个
test.c
的源文件,它的代码显示如下:
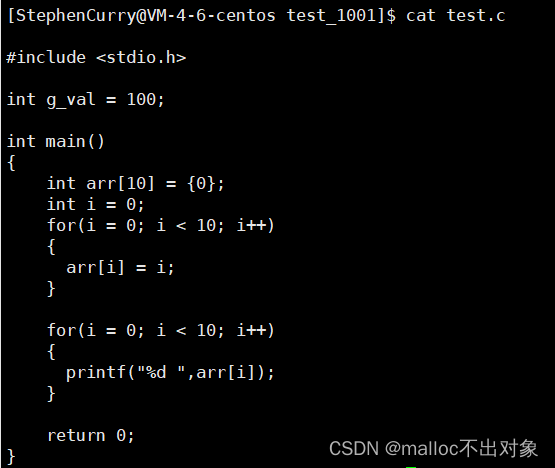
而且当前目录下只有一个
test.c
源文件,
ls
可以显示到当前目录下有什么文件

接下来输入
gcc -E test.c -o test.i
这个指令,它代表的意思是预处理完成之后就停下来,预处理之后产生的结果都放在
test.i
文件中。这个文件我们可以随便取名,但是为了编码规范我们写成一般的这种形式,比如什么阶段生成什么后缀的文件名,这里就不做过多的赘述了。
执行完上述指令我们查看到当前目录下出现了
test.i
文件。

1.1.1 头文件包含
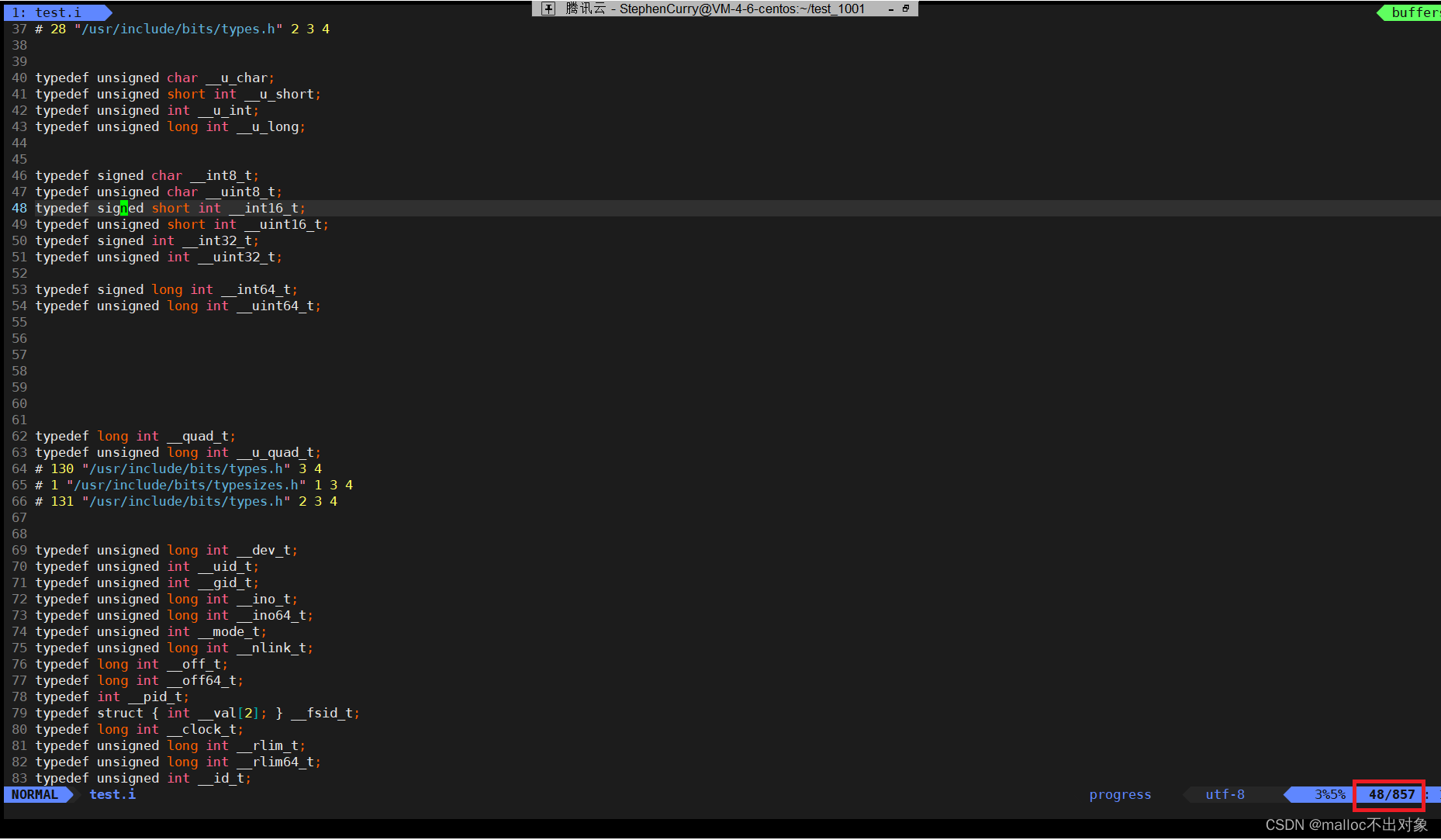
接下来输入
vim test.i
进入
test.i
文件查看里面的内容,我们发现里面的代码有800多行,那么这里面放的究竟是什么代码呢?
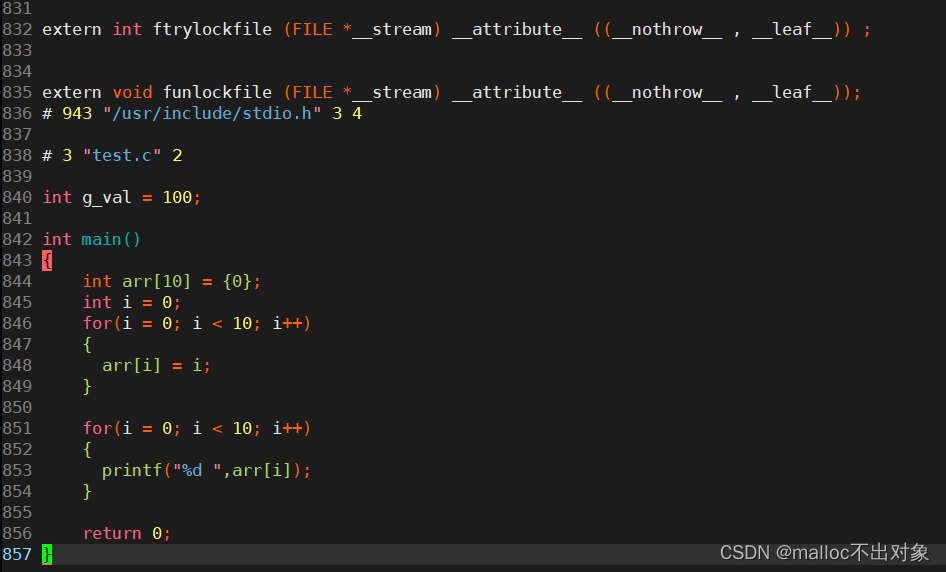
我们在命令模式下输入
G
跳转至文本末尾,我们看到的情况是这样的
接下来我们在命令模式下按下
Shift + :
,输入内容
vs test.c
,此时我们来对比两者一下,你发现什么问题了吗?
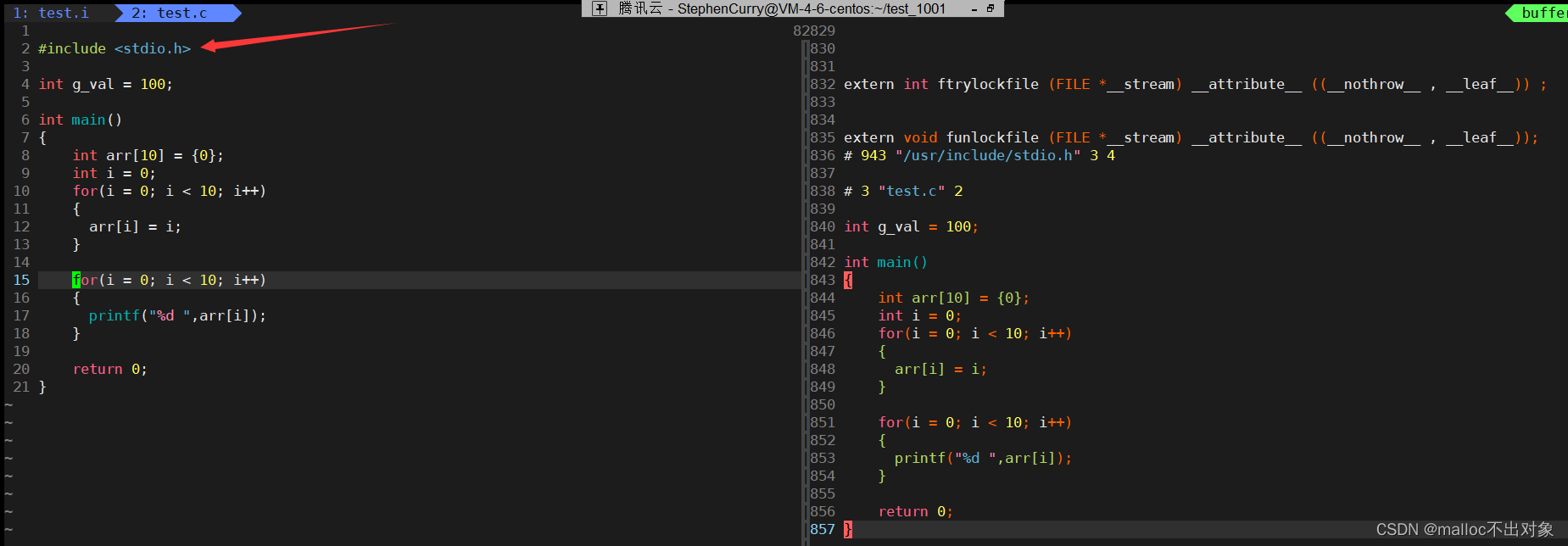
我们发现
test.i
中头文件不见了,但却出现了大量代码,你觉得是什么原因呢?我们想是不是源文件经过预处理将头文件
stdio.h
的内容全部包含进来了吗?下面我们来证明这个事实。
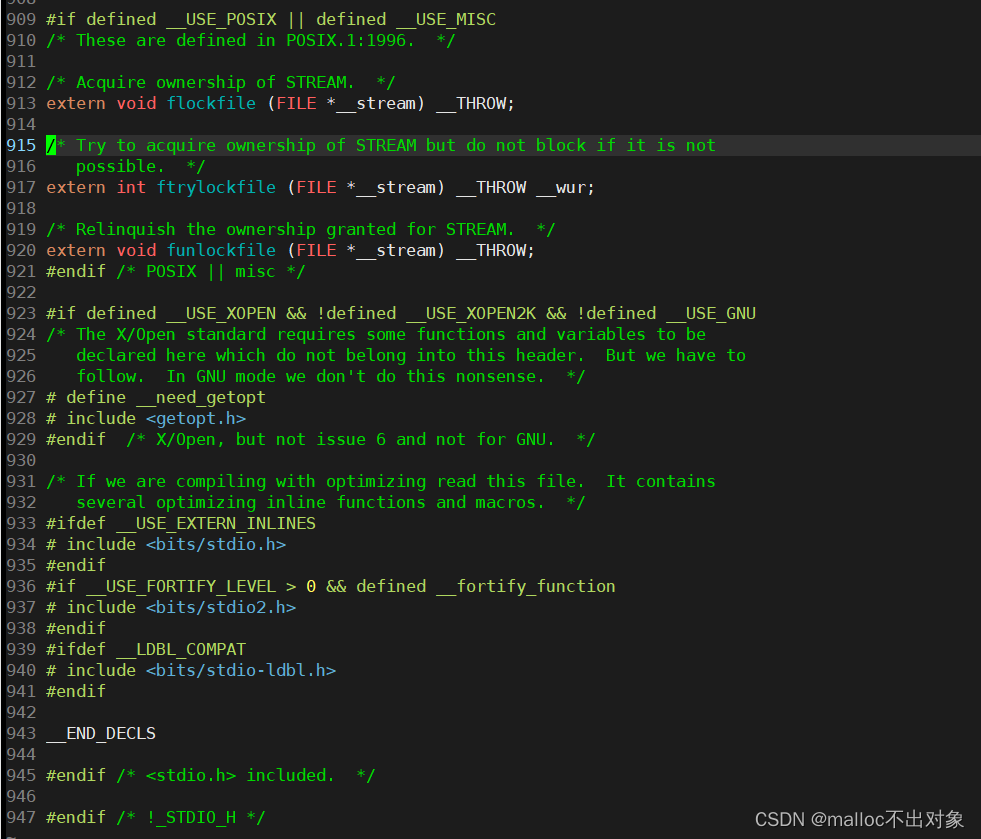
我们输入
vim /usr/include/stdio.h
进入到Linux环境中
stdio.h
头文件中,我们发现有900多行的代码包含在内
接下来我们对比
test.i
与
stdio.h
,发现它们两者之间有些内容确实是一样的,但可能由于其他原因我们观察到的可能不是完全一致,这里我们就不刨根挖底了,我们只需知道
test.i
里面的这些内容确实就是
stdio.h
中的就行了。
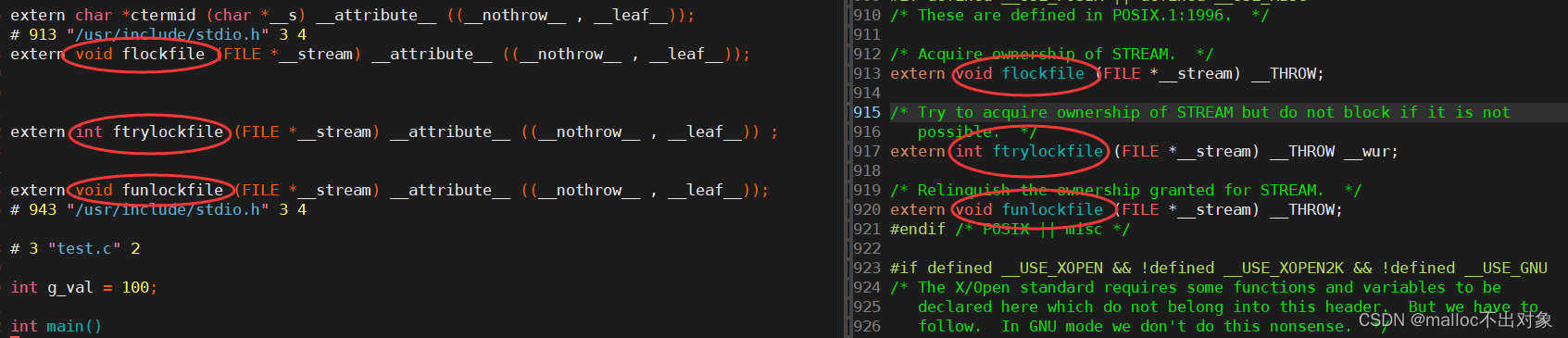
从这里我们就可以得出一个结论:预处理会将头文件中的内容拷贝进源文件,#include的本质就是把头文件中相关内容直接拷贝至源文件。
那么我就有一个疑问了,我们的
stdio.h
文件中都有900多行的代码,而你的
test.i
加上源代码都只有800多行,那么为什么会出现这种情况呢?先把这个问题放一放我们继续分析下面的过程。
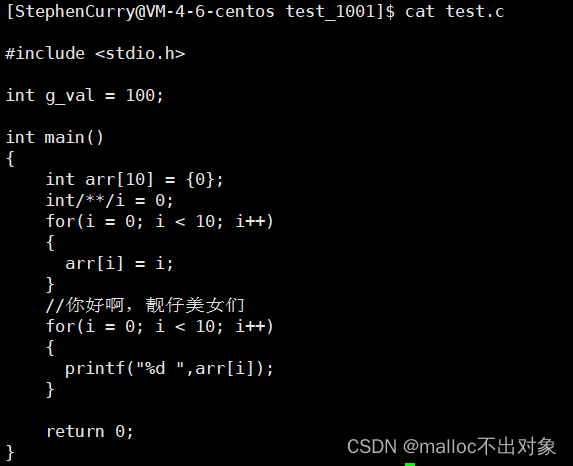
1.1.2 注释删除
我将这份代码稍微改动一下,添加几行注释,在
test.i
里面观察与
test.c
的变化。
此时我们的
test.c
文件已经改变,所以接下来我们重新进行
gcc -E test.c -o test.i
生成
test.i
文件, 我们发现在预处理过后,
test.c
里面的注释都被空格替换了。
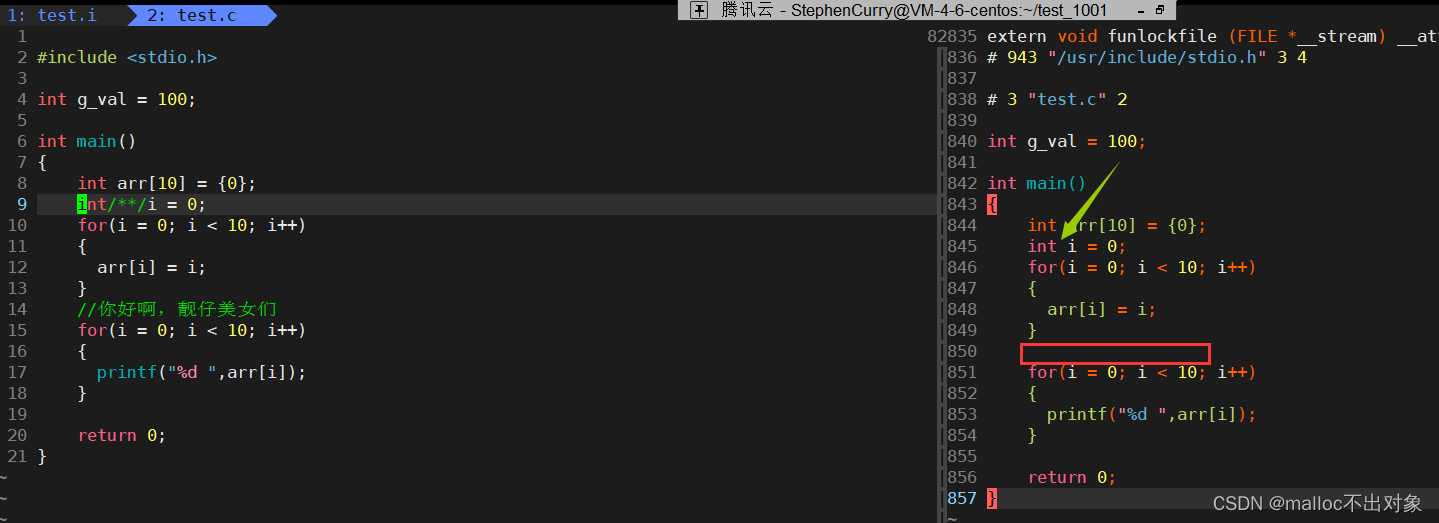
由此我们得出结论:实际编译器是不关心注释的,所以在预处理阶段是要被删除的;注释只是写给程序员或者其他人员看的,并不参与到程序运算当中。
1.1.3 预处理指令的文本替换
这里以
#define
为例,我们将代码再稍加修改一下,通过对比我们发现
#define
对文本进行了直接宏替换,并且预处理完之后就消失了。
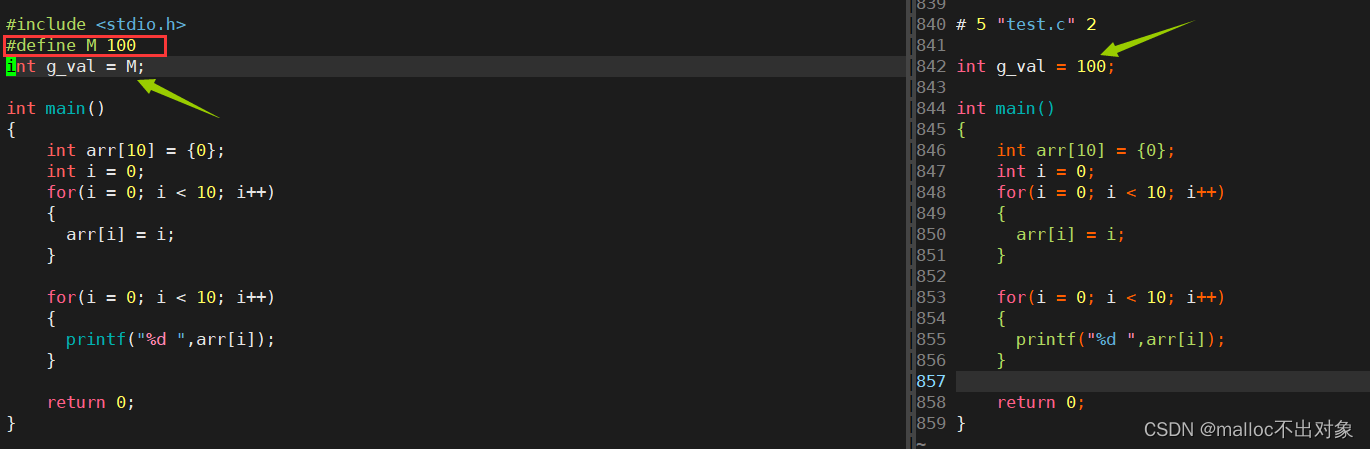
那么回到上面那个问题,你知道为什么
stdio.h
文件的代码行数比
test.i
中代码数要多了吗🙈🙈
综上:
- 预处理过程实质上是处理“#”,将#include包含的头文件直接拷贝到.i文件当中;
- 将代码中没用的注释部分删除;
- 将#define定义的宏进行替换、执行条件编译等预处理指令
注:预处理阶段进行的都是文本操作。
1.2 翻译
上述代码经过预处理之后,接下来就是翻译阶段,我们输入
gcc -S test.i -o test.s
这个指令,翻译完成之后就停下来,结果保存在
test.s
中。
接下来我们输入
vim test.s
进入
test.s
文件进行观察。
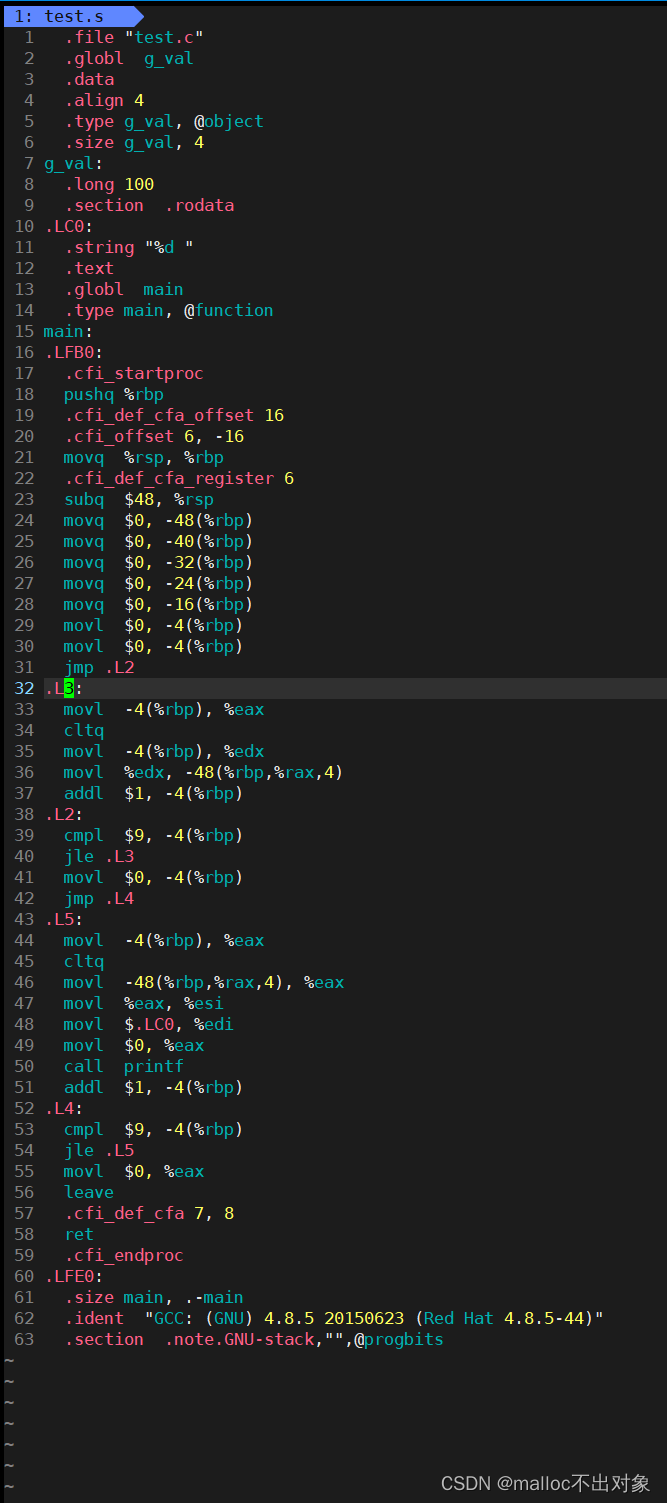
我们能发现什么?虽然我们可能看不懂这些代码,可是你有没有发现它跟我们在Windows环境中一些基本的汇编指令很相似,例如:
mov、push、call、jmp
等,实际上这些就是汇编代码。
好了,那么此时我们就能得出一个结论:笼统的讲,翻译阶段就是把C语言代码翻译成汇编代码,而这个过程实际是经过以下几个步骤来完成转换的:语法分析、词法分析 、语意分析、符号汇总。
前三点很好理解,我们要将C语言代码翻译成汇编代码肯定是需要建立在C语言语法基础上才能准确的进行转换。下面我将这段代码进行修改故意的写错,看看到底能不能通过编译形成
test.s
文件。
接下来输入
gcc -E test.c -o test.i
看下能不能形成
test.i
文件
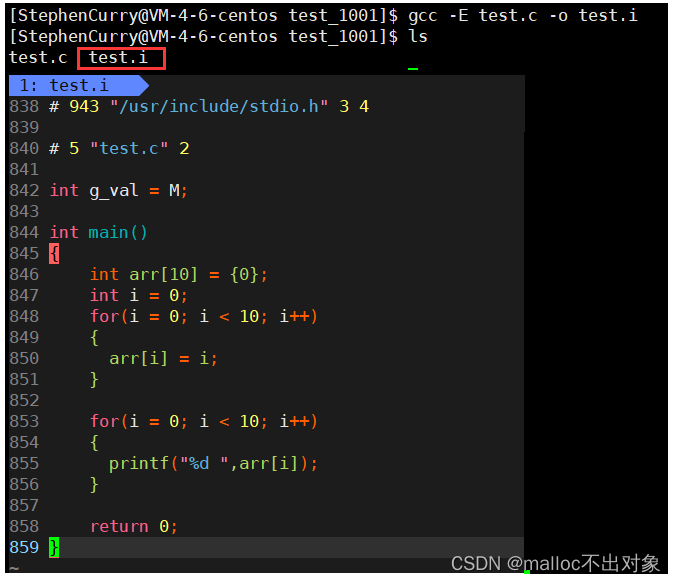
我们发现即使是在语法有问题的情况下经过预处理之后也形成了
test.i
文件,这说明什么?
说明预处理根本不进行语法语意等的分析与检查,它只需要干好自己应该做的事就可以了。
那么你明白了之前我们讲过为什么在一定程度上要少使用
#define
的指令吗?
因为一旦使用宏替换出现错误时,我们在调试时其实看到的已经是经过预处理过后的代码了,所以根本无法迅速判断错误出在哪,这也就增大了我们的维护成本。
接下来我们输入
gcc -S test.i -o test.s
,看能不能通过翻译形成
test.s
文件。

结果显而易见是不能通过编译的,在翻译阶段进行语法词义分析发现了错误故不能生成
test.s
文件。由此,我们要记住源代码是在翻译阶段进行语法语意等的分析的。
接下来我们调整回原来的代码来简单的谈谈符号汇总,首先将源文件和
test.s
文件进行对比。
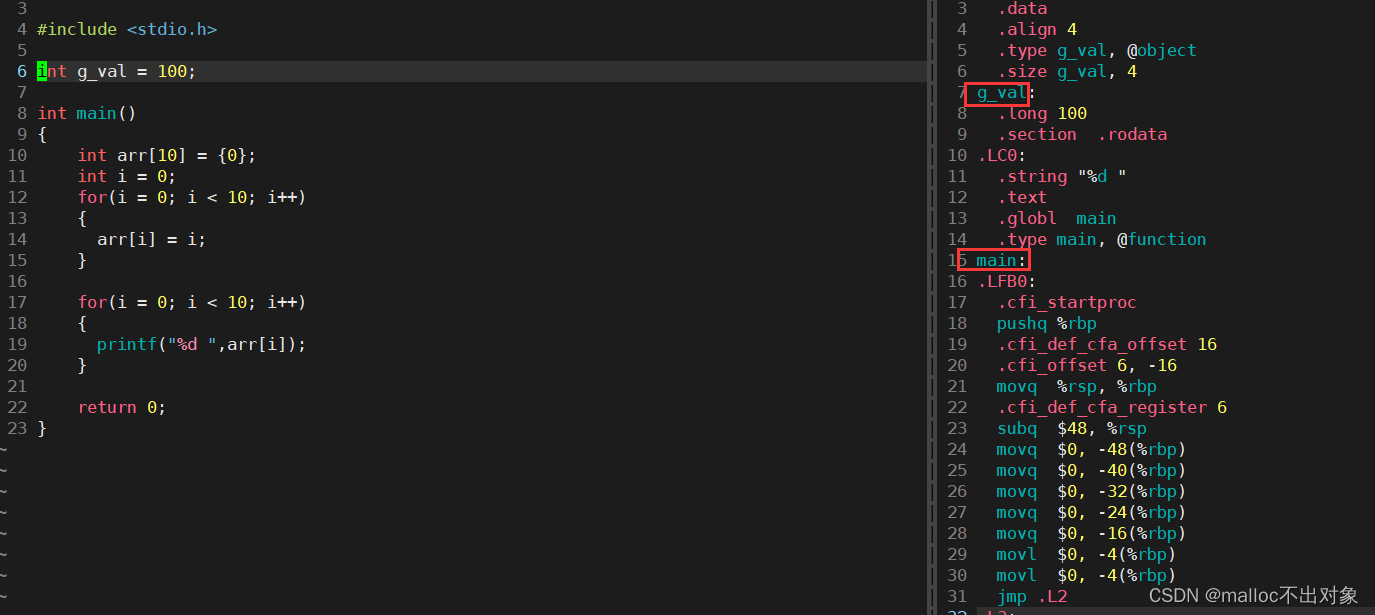
我们发现其实在
test.s
中只有俩个是我们所熟悉的变量或者函数,全局变量
g_val
和
main
函数;其他的局部变量什么
arr数组
、
i
什么的都不在
test.s
里面,那么符号汇总是干什么的呢?大概的我们想是将这些全局变量啊函数啊这些符号进行拆解之后全部汇总起来,最后进行链接操作的时候全部链接起来形成一个可执行程序,后续在讲到链接的时候我们再来谈论这个问题。
1.3 汇编
经过翻译阶段,编译器要执行的最后一步就是汇编了,我们输入
gcc -c test.s -o test.o
指令,接下来
vim test.o
进入文件观察现象。

我们发现
test.o
里面我们什么都看不懂,其实它就是二进制代码,Windows当中
.obj
与这个
.o
文件其实是一样的里面都是放的二进制代码。
那么我们就可以得出结论了:汇编过程实际上是将汇编代码转换成二进制代码生成一个目标文件。
其实汇编阶段还会形成一个符号表,这个符号表就是由翻译阶段进行符号汇总而来的,里面包含了符号的地址信息等,之后到了链接阶段链接器就从多个
.o/.obj
文件中选择性的从符号表中挑选所需要的符号信息来进行链接,最终形成一个可执行程序。
下图是在VS中创建的两个源文件,我对简单做了一下分析。
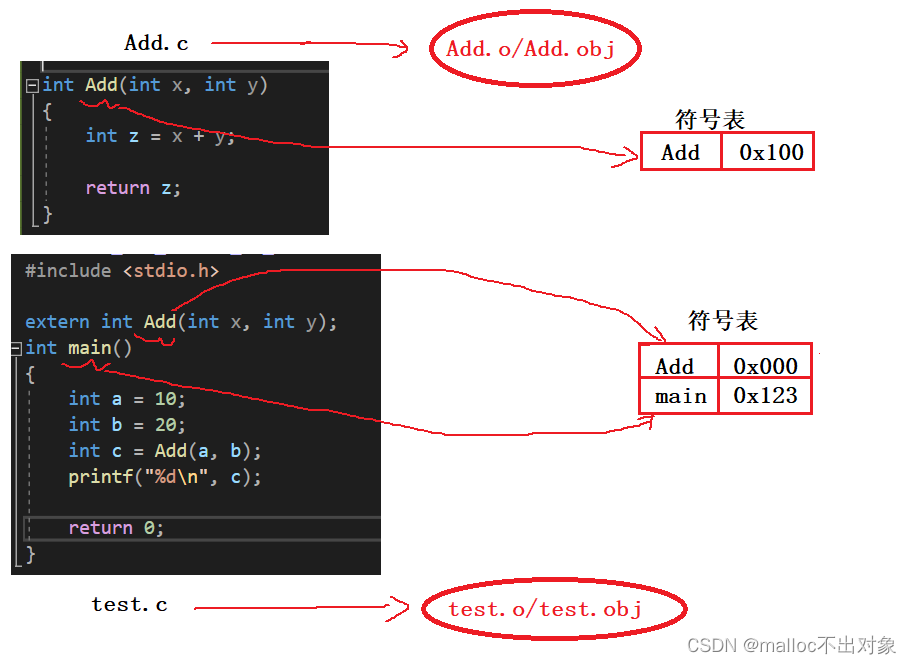
2. 链接
链接过程是由链接器来完成的,它又分为合并段表、符号表的合并和重定位。
2.1 合并段表
我们经过编译器翻译之后形成了一个或者多个目标文件,而每个目标文件它其实是有固定格式的,这个格式也叫做
elf文件格式
,
readelf
是读取
elf
的一个工具,下面我们一起来看看目标文件
test.o
的
elf
文件格式:
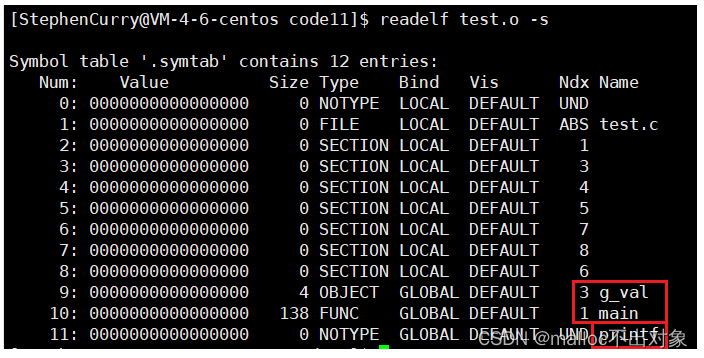
我们发现全局变量
g_val
、
main
函数以及库函数
printf
是我们所熟悉的,此时它们充当的就是符号,我们也就能跟翻译阶段进行符号汇总和汇编阶段形成符号表联系在一起了。
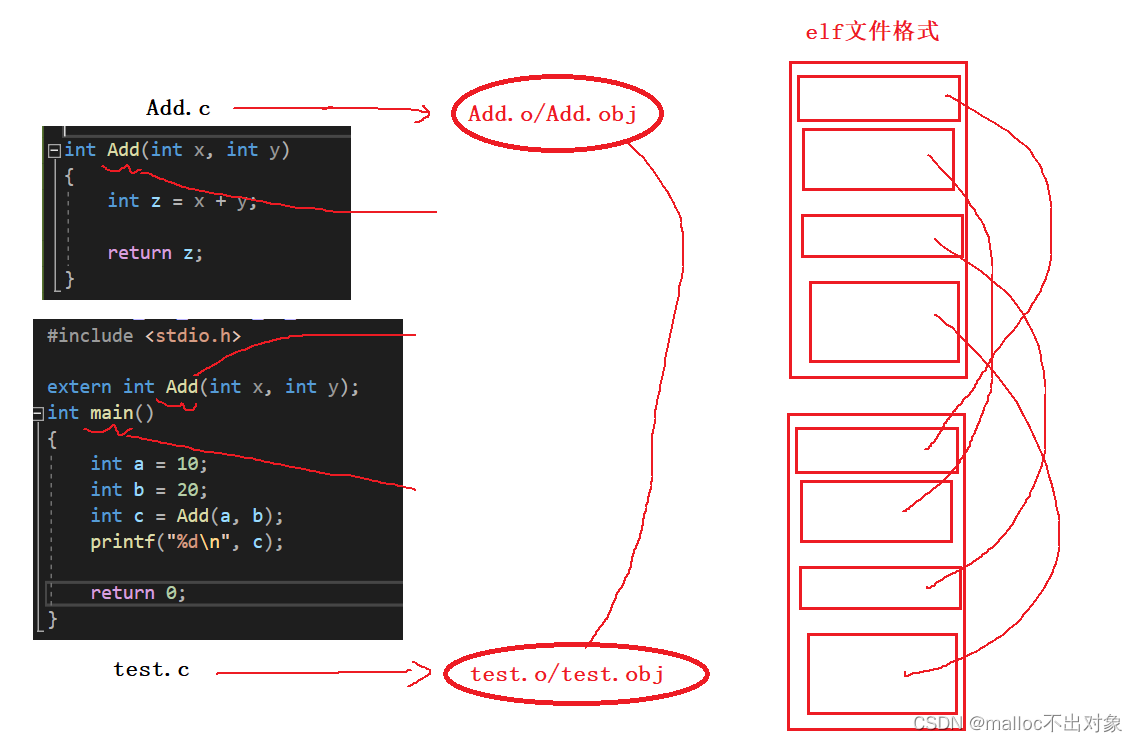
所谓段表就是它会把自己分成几个段一样的保存着不同的信息,之后在链接过程中会将对应的段表合并起来。这里举了一个简单的例子:
这样一推理,既然
test.o
是
elf
文件格式,那么在链接之后形成的可执行程序是不是也为
elf
文件格式呢?我们一起来看下吧,输入命令
gcc test.c
产生了
a.out
这个默认的可执行程序,接下来我们用readelf工具进行读取查看。
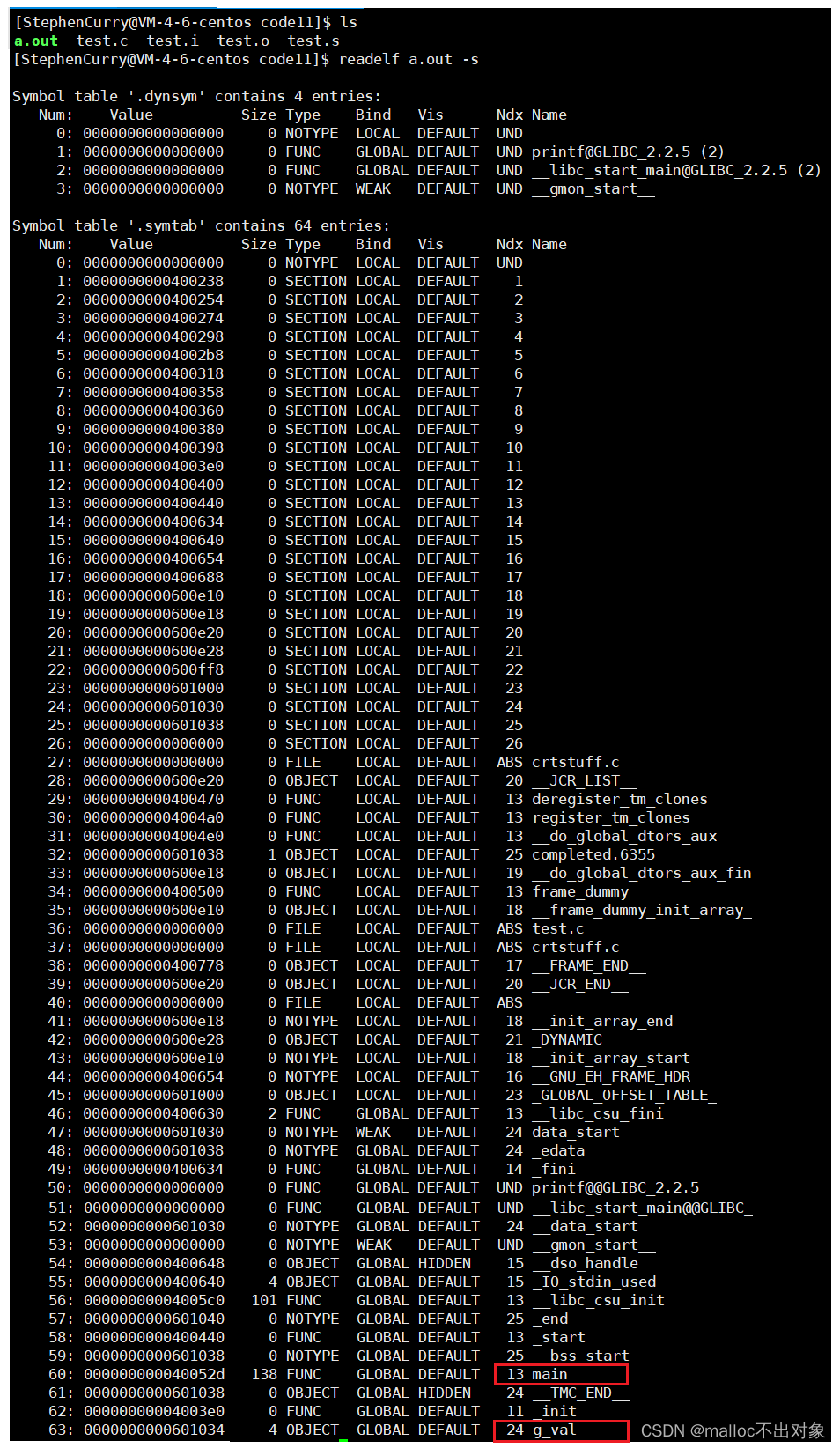
同样的我们在可执行程序中发现了全局变量g_val和main函数的符号名。
2.2 符号表的合并和重定位
每个
.o/.obj
文件中都形成了各自的符号表,链接过程我们对它们进行合并,以下图为例我们发现Add函数冲突了,那么到底该用哪一个目标文件中的信息呢?
我们发现
test.o/test.obj
文件当中Add是无效的,因为我们只是对它进行了声明并没有定义,既然没有定义那就没有一个有效的地址,所以我们选择的是
Add.o/Add.obj
文件中的Add符号信息,这叫做重定位,最终我们的符号表再进行合并。
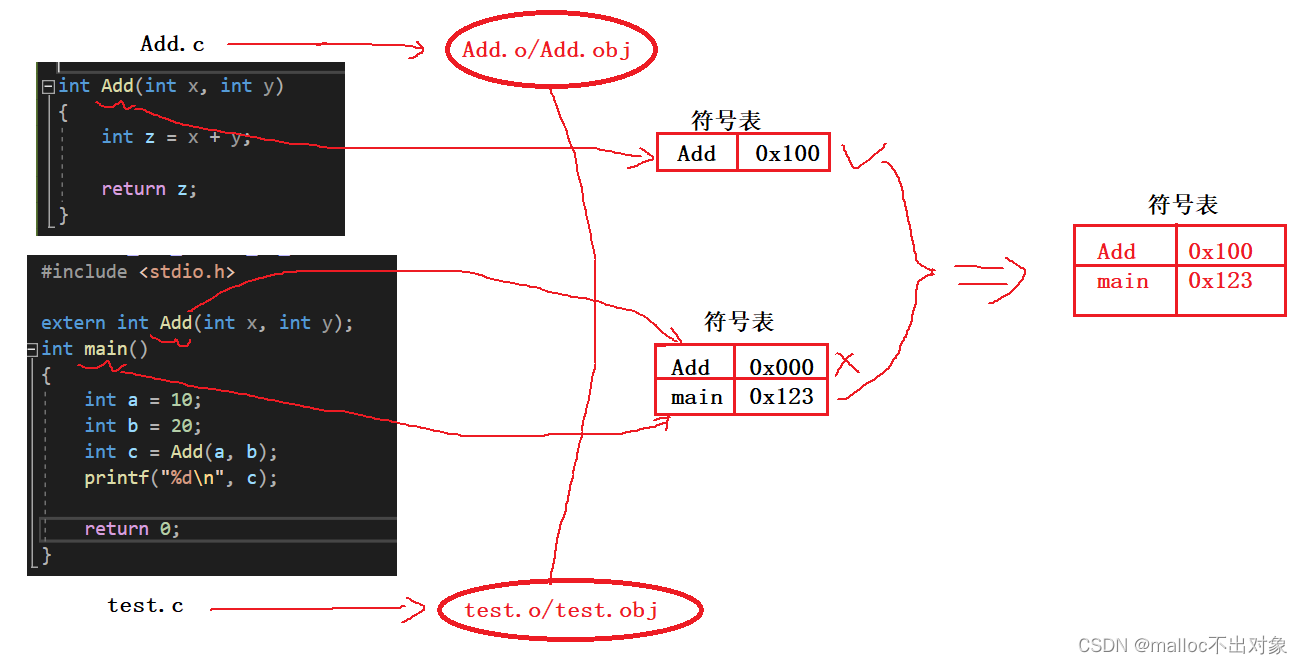
我们先来看下正确的例子,它得到了正确答案:
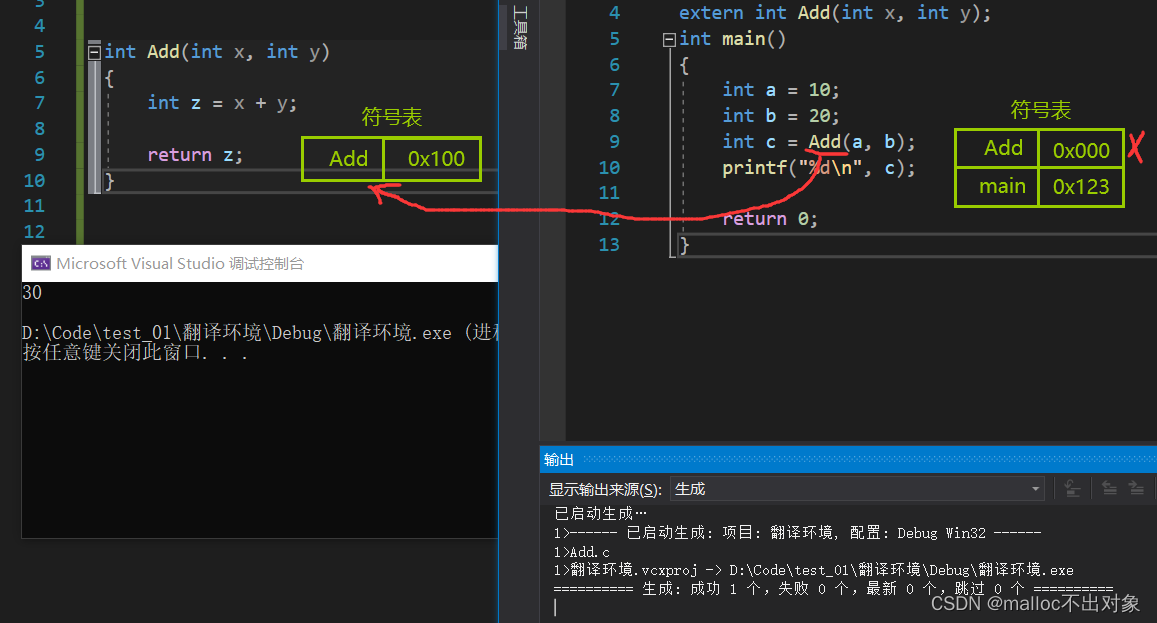
下面我将Add函数注释掉看看会发生什么情况
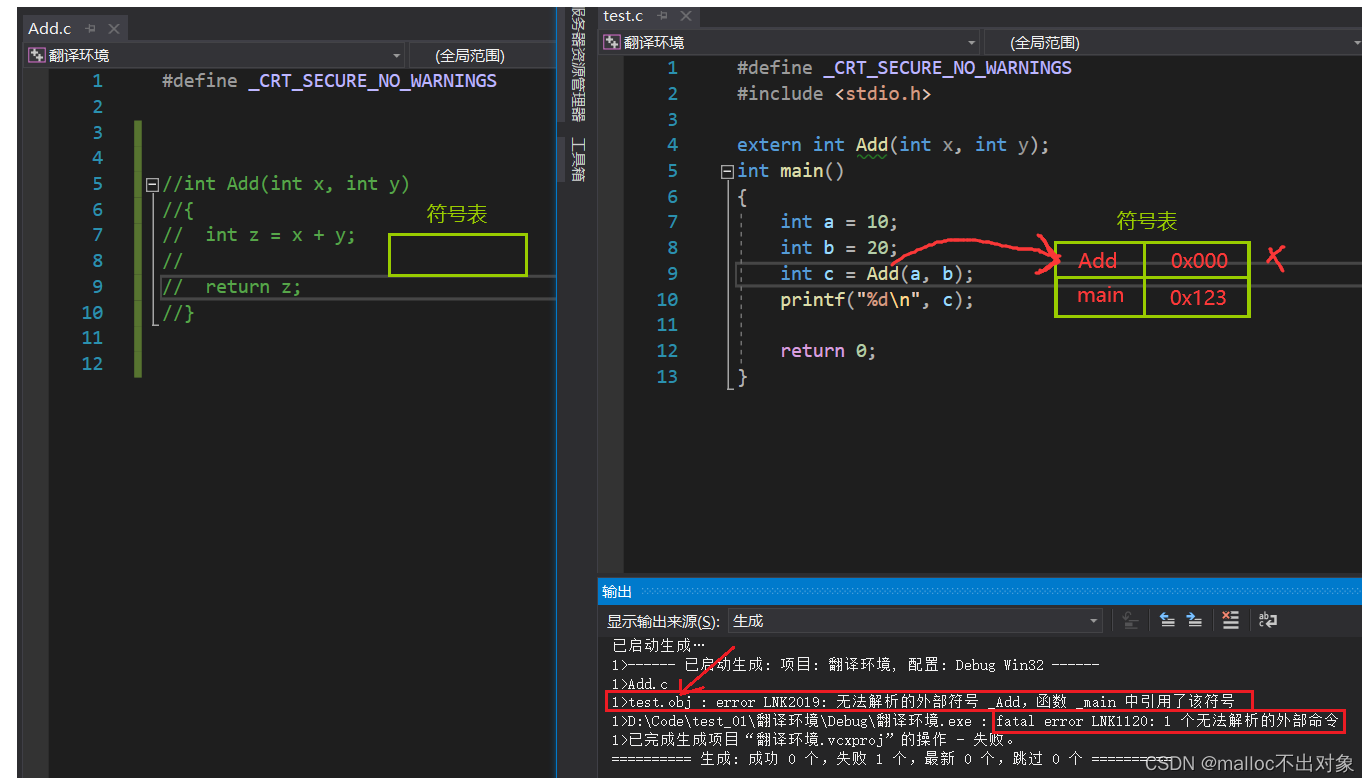
答案显然而知肯定是发生了链接错误,因为
test.c
当中的Add函数的地址是无效的,自然就不能找到且调用Add函数了。
如上例子整个过程如下:
好了,关于翻译环境就讲到这了,我们通过下图来简单的总结一下: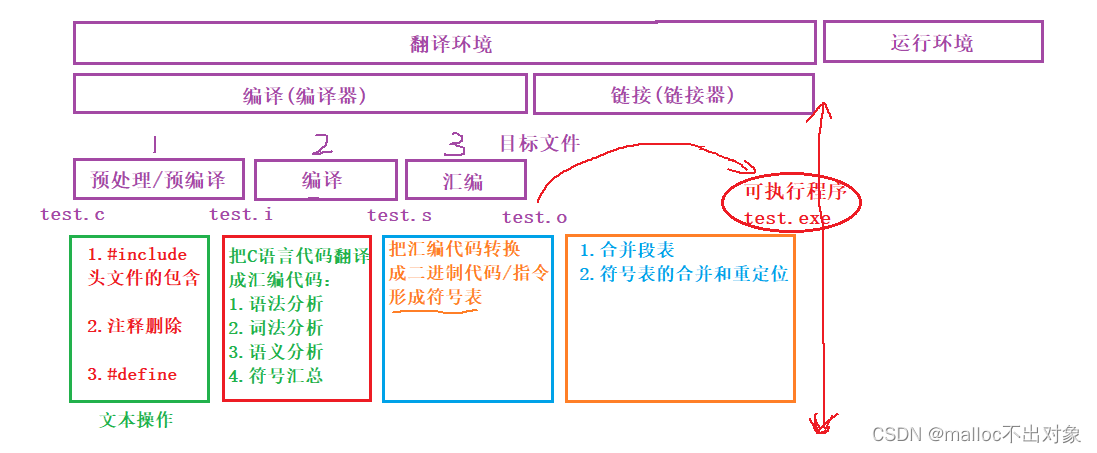
二. 程序的执行环境
运行环境不是我们今天的重点,我们就稍微了解一下就行了。
程序执行的过程:
1. 程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
2. 程序的执行便开始。接着便调用main函数。
3. 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返>回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过>程一直保留他们的值。
4. 终止程序。正常终止main函数;也有可能是意外终止。
好了,今天的文章内容就到这儿了,如有疑问或文章有错误的地方请各位大佬及时指正🙈🙈
版权归原作者 malloc不出对象 所有, 如有侵权,请联系我们删除。