
华为云耀云服务器L实例-大数据学习-hadoop 正式部署
产品官网:云耀云服务器L实例 _【最新】_轻量云服务器_轻量服务器_轻量应用服务器-华为云

今天我们采用可靠更安全、智能不卡顿、价优随心用、上手更简单、管理特省心的华为云耀云服务器L实例为例,演示单台服务器模拟配置hadoop集群
Hadoop 是一个开源的分布式存储和计算框架,旨在处理大规模数据集。它是 Apache 软件基金会的一个顶级项目,为用户提供了一种可靠、可扩展且高效处理大数据的方式。
Hadoop Distributed File System(HDFS): HDFS 是 Hadoop 的分布式文件系统,设计用于存储大规模数据集。它将数据划分为块(block)并分布存储在多台机器上,提供了高容错性和可靠性。
MapReduce: MapReduce 是 Hadoop 的计算模型,用于并行处理大规模数据集。它将计算任务分解为 Map 和 Reduce 阶段,通过在分布式环境中执行这些任务来实现数据处理。
YARN(Yet Another Resource Negotiator): YARN 是 Hadoop 的资源管理器,负责集群资源的管理和调度。它允许多个应用程序共享同一集群,从而更有效地利用集群资源。
Hadoop生态系统: Hadoop 生态系统包含许多其他工具和框架,如 Hive、Pig、HBase、Spark 等,用于支持不同类型的数据处理和分析需求。
扩展性: Hadoop 具有良好的可扩展性,可以轻松地在集群中添加新的节点以处理不断增长的数据量。它支持在普通硬件上搭建集群,使得大规模数据处理变得更加经济高效。
开源和社区支持: Hadoop 是开源软件,由全球的开发者社区维护和支持。它拥有庞大的用户社群和活跃的开发者社区,不断推动框架的发展和改进。
Hadoop 被广泛应用于处理大规模数据,包括数据存储、数据分析、机器学习等各种场景。它的设计理念使得它适用于在常规硬件上搭建的大规模集群,并为用户提供了一种可靠、高效、可扩展的大数据处理解决方案。
步骤 1:安装包下载
官方网址: https://hadoop.apache.org ,使用 3.3.4 版。

步骤 2:上传与解压
使用finalshell工具将安装包上传至华为云耀云服务器L实例,执行以下命令进行解压:
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
cd hadoop


解压完成后的目录如图所示
步骤3 :修改配置文件
- 配置workers文件
# 进入配置文件目录
cd etc/hadoop
# 编辑 workers 文件
vim workers
# 填入如下内容
node1


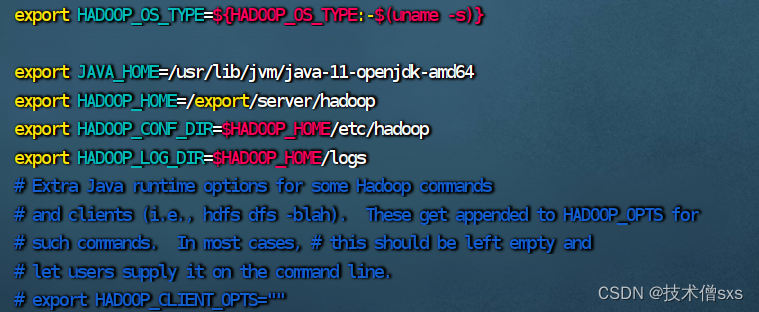
- 配置hadoop-env.sh文件
填入如下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
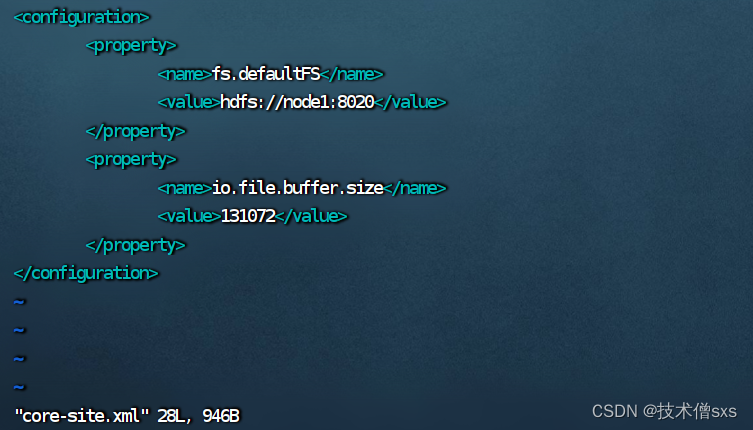
- 配置 core-site.xml 文件
在文件内部填入如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
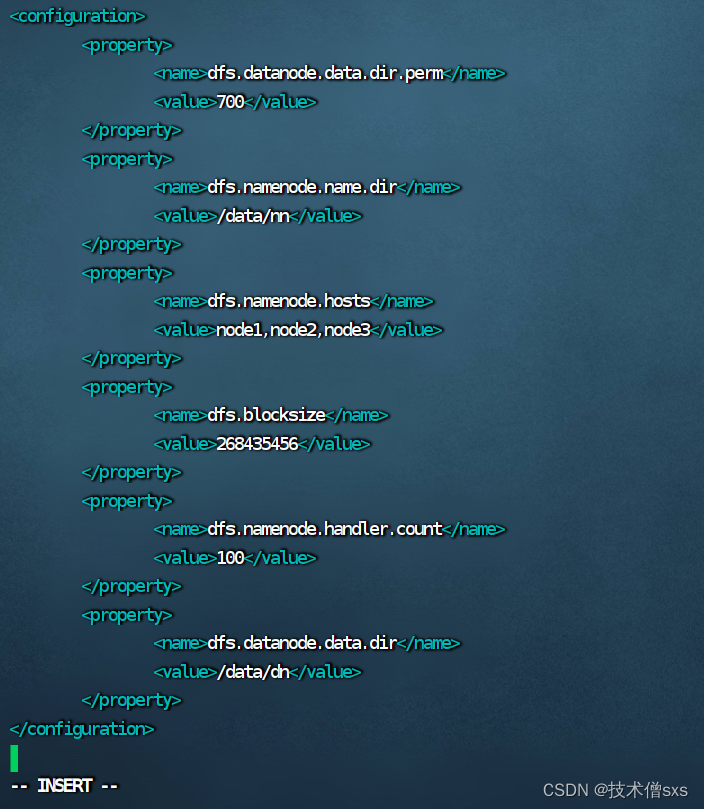
- 配置 hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
- 准备数据目录
mkdir -p /data/nn
mkdir /data/dn

- 配置环境变量
(1)vim /etc/profile
# 在 /etc/profile 文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

- 授权为 hadoop 用户
至此,hadoop 部署的准备工作基本完成,为了确保安全, hadoop 系统不以 root 用户启动,我们以普通用户 hadoop 来启动整个 Hadoop ,现在对文件权限进行授权。
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export

- 格式化并启动
(1)格式化 namenode
# 确保以 hadoop 用户执行
su - hadoop
# 格式化 namenode
hadoop namenode -format

(2)启动
# 一键启动 hdfs 集群
start-dfs.sh
# 一键关闭 hdfs 集群
stop-dfs.sh
# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh

至此,华为云耀云服务器L实例上的hadoop服务已经部署完毕,且成功启动。接下来,我们将尝试入门的实践。
版权归原作者 技术僧sxs 所有, 如有侵权,请联系我们删除。