
爬取大学排名
有些网页源码中找不到相应的要爬的数据,其实这不是什么被反扒了,只是网页有可能是动态加载出来,这时候我们可以找到相应的数据接口,找到真正的目标url一样能找到包含我们想要的数据的真正url,就像我今天要讲的这个案例。
右键查看网页源码,我们会发现数据虽然存在于网页源码中,但是,我们点一下翻页功能,再观察
第一页
第二页
我们会发现,无论我们怎么翻页,url 都是不变的,这个时候,我们应该考虑网页是不是动态加载出来的。在 “开发者工具”->“网络” 中找看看有没有相应的数据接口,一找果然是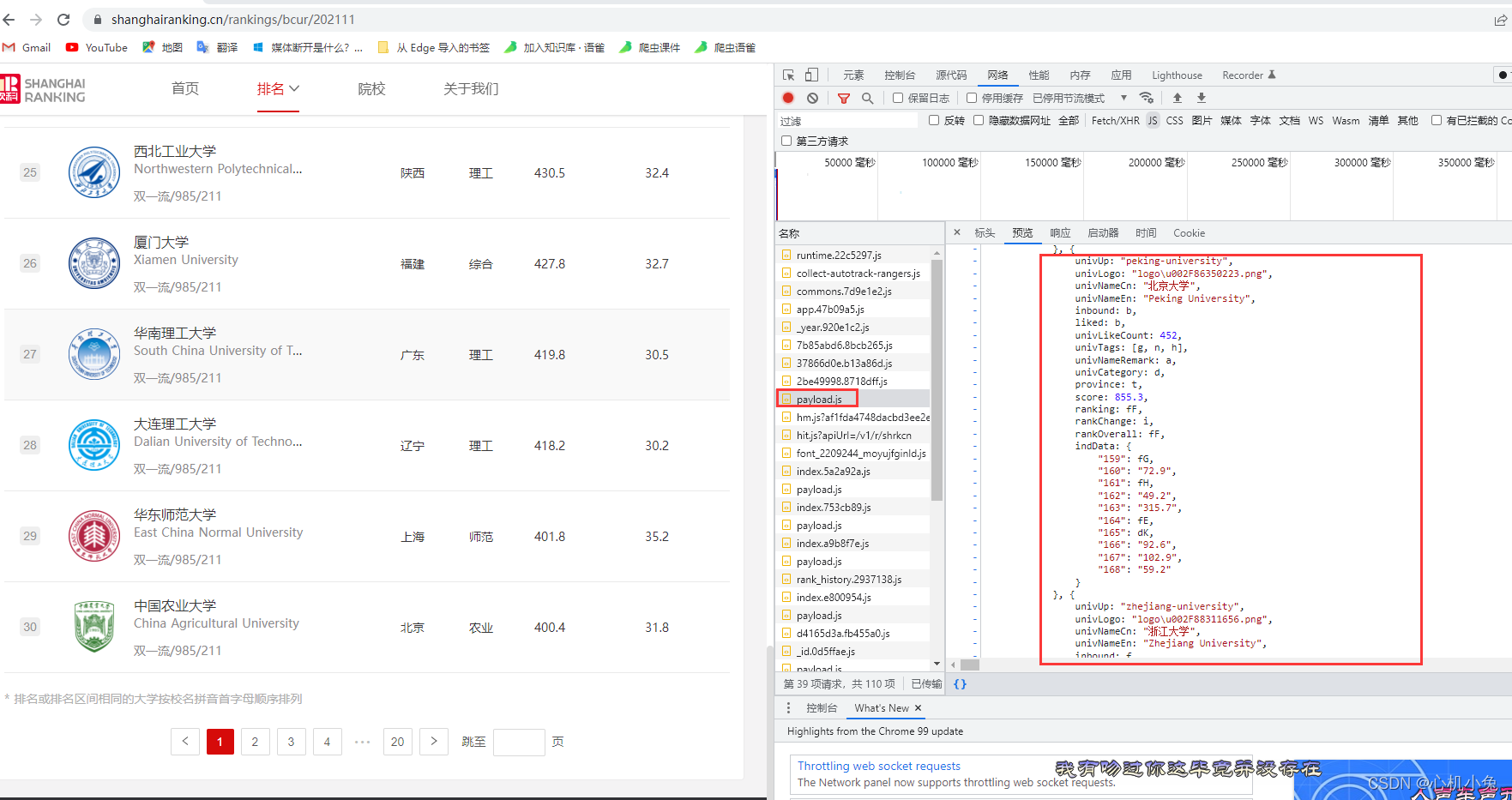
发现数据是保存在一个js格式的文件中的,下面才是它真正url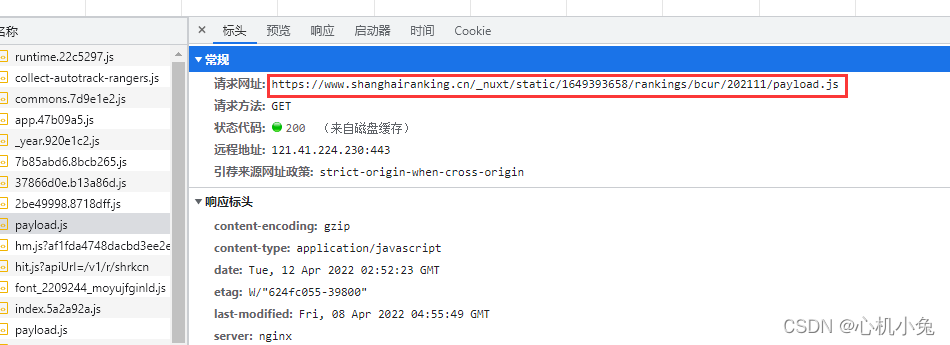
如果用传统的方法去爬,就会经历一个较为繁琐的数据解析过程。所以这时候,selenium的好处就体现出来了,直接获取页面元素,虽然有点慢,但是我们不用再经历繁琐的解析过程。
页面分析
直接查看页面元素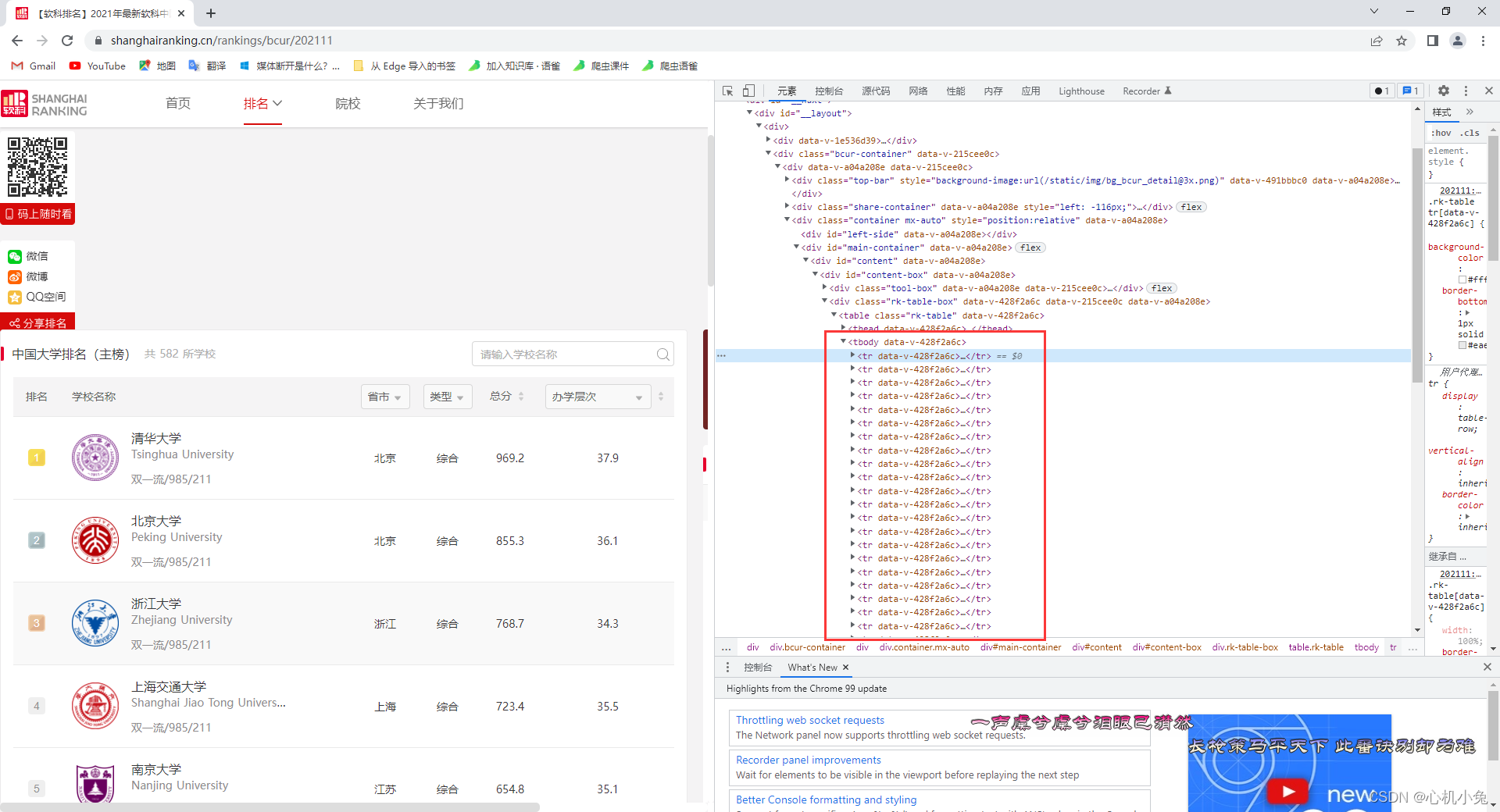
发现每个大学的数据信息都是保存在一个 tr 标签中的,再分析就会发现,每个大学的详细信息分别保存在一个 td 标签中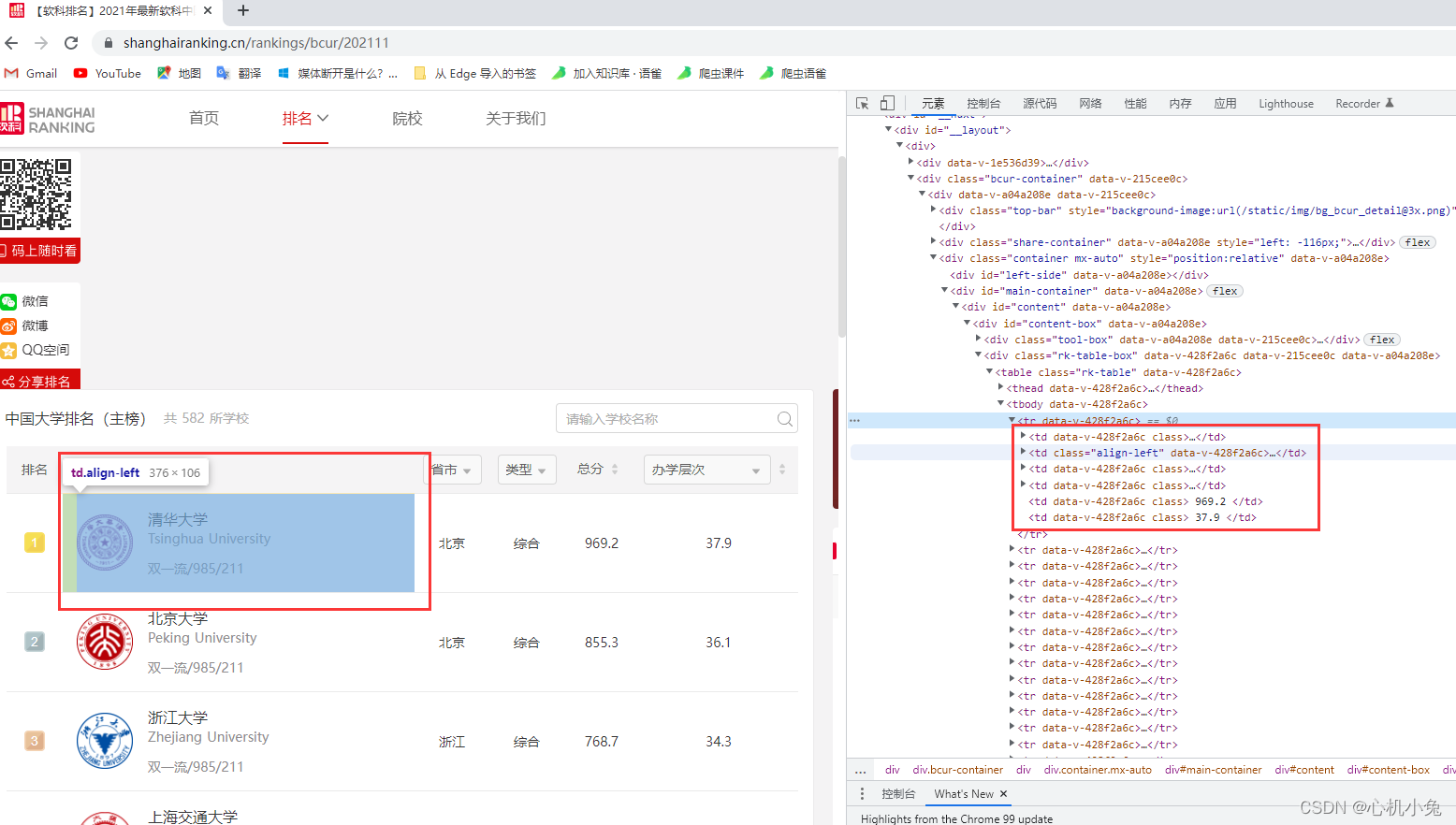
需求
(一)获取大学排名、名称、类型、地点等信息
(二)以csv文件格式保存文件
(三)以面向对象的形式实现
实现代码
只需要用到两个包,selenium.webdriver和csv模块。详细的实现步骤我都在代码中做了注释,就不再多做说明了
要强调的是翻页的处理,分别分析一下最后一页和其他页下的“下一页”按钮有什么区别
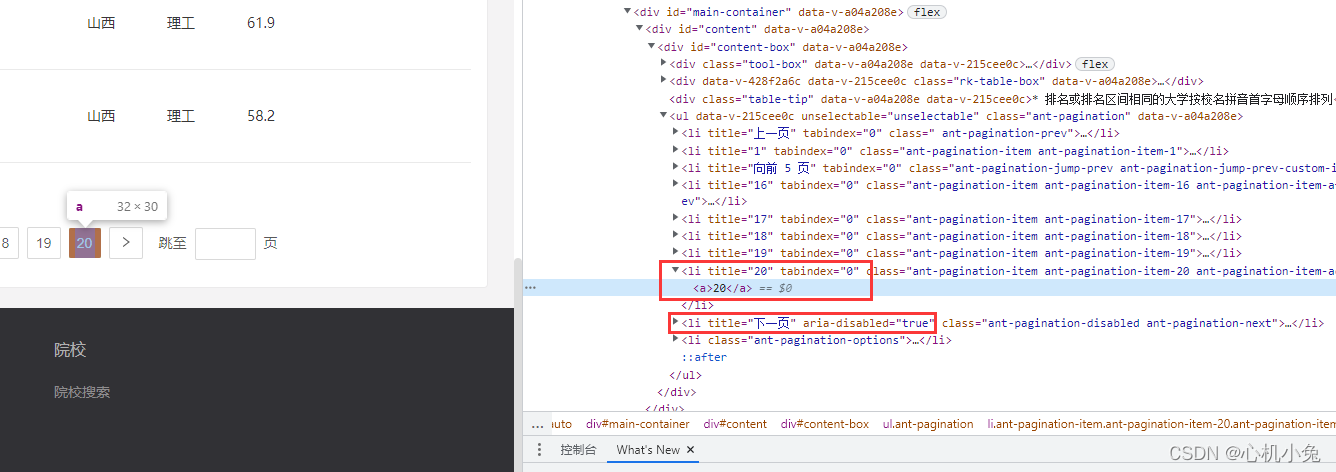
我们会发现,在没到达最后一页时,下一页标签中没有 aria-disabled="true"这个值,到了最后一页才出现的,也就说明,当我们到达最后一页后,下一页按钮就不能再点了,所以找到了这个翻页就相当简单了,话不多说,上代码
# 心机小兔的python之路from selenium import webdriver # 导入selenium,用于实现网页的爬取import csv # 导入csv模块,用于保存文件classUnivercity(object):# 定义一个类方法def__init__(self):# 重写__init__
self.driver = webdriver.Chrome()# 加载谷歌驱动
self.driver.maximize_window()# 浏览器窗口最大化处理# 定义csv文件的列名
self.header =['Rank','Cn','En','Rate','Location','Type']# 用于接收爬取到的数据
self.data =[]# 后期代码基本实现后,把浏览器设置成无头模式,也就是不打开浏览器
options = webdriver.ChromeOptions()# 创建chrome的设置对象
options.add_argument('--headless')# 设置成无界面,也就是不打开浏览器
self.driver = webdriver.Chrome(options=options)# 解析网页页面函数defparse_html(self,url):
self.driver.get(url)# 从类的入口函数接收目标url,也就是下面的self.main()函数
self.driver.implicitly_wait(1)# 隐式等待whileTrue:# 当未到达最后一页,一直执行# 先获取每一页的所有tr标签
tr_list = self.driver.find_elements_by_xpath('.//*[@id="content-box"]/div[2]/table/tbody/tr')# 从每一个 tr 标签中分别获取到详细信息for tr in tr_list:
items ={}# 定义一个空字典,存储每一个大学的详细信息# 通过xpath方式获取大学排名 .//表示在当前的xpath路径下寻找
items['Rank']= tr.find_element_by_xpath('.//td/div').text
# 通过寻找属性名的方式,获取大学的中文名
items['Cn']= tr.find_element_by_class_name('name-cn').text
# 通过寻找属性名的方式,获取大学的英文名
items['En']= tr.find_element_by_class_name('name-en').text
# 这里获取大学是否为985/211的时候,就得做一些异常处理,因为到后面很多高校是非985/211的,就是说标签里面是空的,如果为空,将其定义为空字符try:
items['Rate']= tr.find_element_by_class_name('tags').text
except:
items['Rate']=""# 通过xpath获取大学的地点
items['Location']= tr.find_element_by_xpath('.//td[3]').text
# 通过xpath获取大学的类型,综合、理工、师范等
items['Type']= tr.find_element_by_xpath('.//td[4]').text
# 将一个大学的数据添加到列表中
self.data.append(items)# 翻页处理,page_source.find()返回的是一个布尔值,如果在每一页中没找到标签属性为 nt-pagination-disabled ant-pagination-next 的元素则会返回 -1,到了最后一页的时候则为真,跳出循环if self.driver.page_source.find('ant-pagination-disabled ant-pagination-next')==-1:
self.driver.find_element_by_class_name('ant-pagination-next').click()
self.driver.implicitly_wait(2)else:break# 数据保存操作defsave_data(self,header,data):withopen('test.csv','a', newline='', encoding='utf-8')as f:
writer = csv.DictWriter(f, fieldnames=header)# 提前预览列名,当下面代码写入数据时,会将其一一对应。
writer.writeheader()# 写入列名
writer.writerows(data)# 一列一列写入数据# 函数入口defmain(self):
url ='https://www.shanghairanking.cn/rankings/bcur/202111'
self.parse_html(url)# 调用解析函数
self.save_data(self.header,self.data)# 调用保存数据函数if __name__ =='__main__':
u = Univercity()# 实例化一个对象
u.main()# 函数入口
实现效果

到这,这个案例就算结束了,是不是很简单?
本文转载自: https://blog.csdn.net/little_Muxue/article/details/124118737
版权归原作者 心机小兔 所有, 如有侵权,请联系我们删除。
版权归原作者 心机小兔 所有, 如有侵权,请联系我们删除。