
WATERMARK 定义了表的事件时间属性,其形式为:
WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
rowtime_column_name 把一个现有的列定义为一个为表标记事件时间的属性。该列的类型必须为 TIMESTAMP(3)/TIMESTAMP_LTZ(3),且是 schema 中的顶层列,它也可以是一个计算列。
watermark是触发计算的机制,只要事件时间<= watermark,就会触发当前行数据的计算,watermark的形象描述如下:
watermark的窗口触发机制
watermark会根据数据流中event的时间戳发生变化。通常情况下,event都是乱序的,不按时间排序的。watermark的计算逻辑为:当前最大的 event time - 最大允许延迟时间(MaxOutOfOrderness)。在同一个分区内部,当watermark大于或者等于窗口的结束时间时,才能触发该窗口的计算,即watermark>=windows endtime。如下图所示: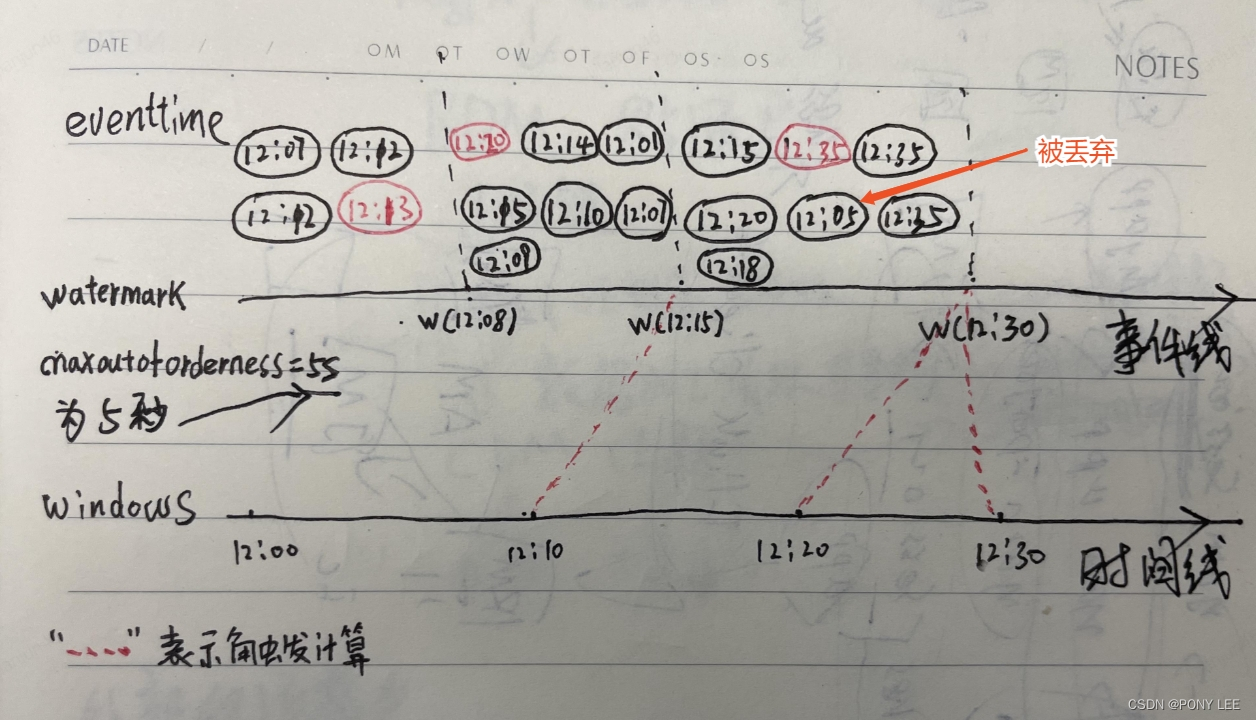
根据上图分析:
MaxOutOfOrderness = 5s,窗口的大小为:10s。
watermark分别为:12:08(12:07.999)、12:15(12:14.999)、12:30(12:29.999)
计算逻辑为:WM(12:08)=12:13 - 5s;WM(12:15)=12:20 - 5s;WM(12:30)=12:35 - 5s
- 对于 [12:00,12:10) 窗口,需要在WM=12:15时,才能被触发计算,参与计算的event为:event(12:07)/event(12:01)/event(12:07)/event(12:09),event(12:10)/event(12:12)/event(12:12)/event(12:13)/event(12:20)/event(12:14)/event(12:15)不参与计算,因为还未到窗口时间,也就是event time 为 [12:00,12:10] 窗口内的event才能参与计算。 注意,如果过了这个窗口期,再收到 [12:00,12:10] 窗口内的event,就算超过了最大允许延迟时间(MaxOutOfOrderness),不会再参与计算,也就是数据被强制丢掉了。
- 对于 [12:10,12:20] 和 [12:20,12:30] 窗口,会在WM=12:30时,被同时触发计算,参与**[12:10,12:20]** 窗口计算的event为:event(12:10)/event(12:12)/event(12:12)/event(12:13)/event(12:14)/event(12:15)/event(12:15)/event(12:18);参与 [12:20,12:30] 窗口计算的event为:event(12:20)/event(12:20);在这个过程中event(12:05)会被丢弃,不会参与计算,因为已经超了最大允许延迟时间(MaxOutOfOrderness)
迟到的事件的处理,在介绍watermark时,提到了现实中往往处理的是乱序event,即当event处于某些原因而延后到达时,往往会发生该event time < watermark的情况,所以flink对处理乱序event的watermark有一个允许延迟的机制,这个机制就是最大允许延迟时间(MaxOutOfOrderness),允许在一定时间内迟到的event仍然视为有效event。
WATERMARK rowtime_column_name 取值两种方式
rowtime_column_name为计算列
CREATETABLE pageviews (
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map < string, string >,
cur map < string, string >,
cus map < string, string >,
event_time as cast(TO_TIMESTAMP_LTZ(ts,3)ASTIMESTAMP(3)),--计算列,必须为TIMESTAMP(3)/TIMESTAMP_LTZ(3)类型
WATERMARK FOR event_time AS event_time -INTERVAL'60'SECOND)WITH('connector'='kafka','properties.bootstrap.servers'='***','topic'='topic1','format'='json','properties.group.id'='*****','scan.startup.mode'='earliest-offset'-- 取值 : group-offsets latest-offset earliest-offset);
rowtime_column_name为事件时间属性
CREATETABLE dataGen(
uuid VARCHAR(20),
name INT,
age INT,
ts TIMESTAMP(3),--事件时间属性,字段类型为TIMESTAMP(3)
WATERMARK FOR ts AS ts
)with('connector'='datagen','rows-per-second'='10','number-of-rows'='100','fields.age.kind'='random','fields.age.min'='1','fields.age.max'='10','fields.name.kind'='random','fields.name.min'='1','fields.name.max'='10');
watermark使用demo
CREATETABLE kafka_table(
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map < string, string >,
cur map < string, string >,
cus map < string, string >,
group_name asCOALESCE(cur['group_name'], src['group_name']),
batch_number asCOALESCE(cur['batch_number'], src['batch_number']),
event_time as cast(TO_TIMESTAMP_LTZ(ts,3)ASTIMESTAMP(3)),-- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
WATERMARK FOR event_time AS event_time -INTERVAL'2'MINUTE--SECOND)WITH('connector'='kafka','properties.bootstrap.servers'='***','topic'='topic1','format'='json','properties.group.id'='*****','scan.startup.mode'='earliest-offset'-- 取值 : group-offsets latest-offset earliest-offset);
watermark在over聚合中的使用
--RANGE:每个group_name计算当前group_name前10分钟内收到的同一group_name的所有总数select
group_name
,event_time
,COUNT(group_name)OVER w1 as cnt
from kafka_table
where UPPER(opt)<>'DELETE'
WINDOW w1 AS(PARTITIONBY group_name
ORDERBY event_time
RANGE BETWEENINTERVAL'10'MINUTEPRECEDINGANDCURRENTROW)
watermark在windows聚合中的使用
--求每10分钟的滚动窗口内同一group_name的所有总数createview tmp asSELECT group_name,event_time FROM kafka_table where UPPER(opt)<>'DELETE';select window_start,window_end,window_time,group_name,count(*)as cnt fromTABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time),INTERVAL'10' MINUTES))groupby window_start,window_end,window_time,group_name
参考:
Window Aggregation
Over Aggregation
版权归原作者 PONY LEE 所有, 如有侵权,请联系我们删除。