
在本文中,我将首先介绍基于AI的音乐生成的最新发展,然后介绍我创建的系统并讨论其组成,包括Yi Yu等人的“Lyrics-to-Melody” AI模型等。。[6]和Google的Music Transformer模型[7]。然后,我将演示一个示例,该示例从(Robert Frost)的诗歌中生成歌曲,并介绍其他生成的歌曲的集合。
背景
在过去的五个月中,我一直在研究如何将人工智能(AI)和机器学习(ML)用于创新活动。
尽管最先进的人工智能模型可以生成优秀的图片和文字,但到目前为止,人工智能模型在作曲方面还没有那么好。有些音乐生成模型还不错,比如谷歌[3]的various Magenta models,OpenAI[4]的MuseNet模型,以及AIVA[5]的商业产品。但大多数产生AI模型的音乐输出往往是杂乱无章和不连贯的。似乎缺少的是歌曲的整体结构。让我们看看我们是否可以通过注入抒情诗歌来弥补这一点。

系统总览
我使用的是由Yi Yu和她的同事设计和训练的Lyrics-to-Melody AI模型。他们称之为有条件的LSTM-GAN,用于从歌词中生成旋律[6]。
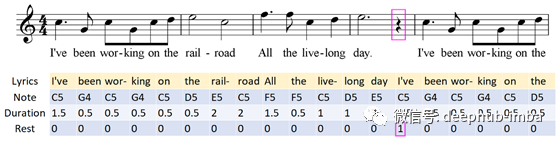
系统接受了约12K带有歌词的MIDI歌曲进行训练。它使用单词及其音节作为输入,并经过训练以预测音乐的音符,持续时间和静息持续时间作为输出。这是对“I’ve Been Working on the Railroad”的五个条形的分析,以黄色显示输入,以蓝色显示预期输出。请注意,“ day”一词之后的其余部分如何与下一个音节“ I've”相关联。
我使用的第二个主要系统是Music Transformer [7],它是谷歌的Magenta模型套件的一部分。该模型自动为给定的旋律生成音乐伴奏。它训练了作为雅马哈年度电子钢琴比赛[8]的一部分数据,大约400个由约翰·塞巴斯蒂安·巴赫的合唱团和1100个由专家钢琴家捕捉的表演。
下面是一个组件图,它显示了整个系统的流程,左边是作为文本的一首诗歌,右边是作为MIDI文件生成一首新歌。
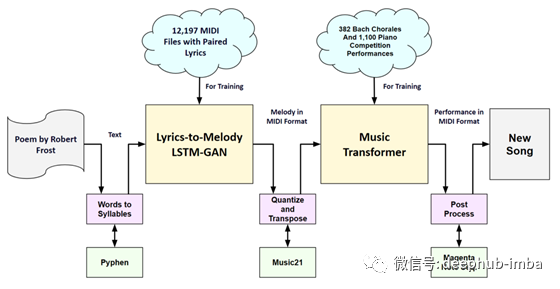
每一行选定的诗被输入系统,一次一行。它使用一个名为Pyphen的模块,使用Hunspell连字符字典[9]将行中的每个单词分解成音节。将结果输入到歌词到旋律模型中。该模型是GAN和长短期记忆(LSTM)模型之间的混合体,用来进行MIDI格式的音符生成。
使用MIT的Music21库[10]分析所得的乐句,确定其所处的音调。然后将该乐句转换为C大调(或A Minor),并使用Music21量化为十六分音符。生成所有音乐行之后,将生成的MIDI文件输入到Music Transformer模型中,该模型添加一个伴随的音乐声部,并以具有表现力的键盘速度和定时来营造人性化的感觉。
最后,使用谷歌的Magenta 库[11]对最终的MIDI文件进行一些后处理,比如分配乐器声音。
在下一节中,我将详细介绍这些步骤,并显示为自定义处理编写的Python代码。
系统演练
在演练中,我们将使用Robert Frost的一首简短而完整的诗歌,称为“Plowmen” [12]。我将展示用于将这首诗转换为歌曲的Python代码的主要摘要。
准备诗歌
处理的第一步涉及将每个单词分解为音节,并创建要嵌入到LSTM-GAN中的单词嵌入。
这是示例诗。
PlowmenA plow, they say, to plow the snow.They cannot mean to plant it, no–Unless in bitterness to mockAt having cultivated rock.- Robert Frost
这是将每个单词分解为音节并将其输入LSTM-GAN的代码段。您可以看到它使用Word2Vec [13]为单词和音节创建并输出了嵌入内容。Google表示:“事实证明,通过Word2Vec学习到的嵌入在各种下游自然语言处理任务上都是成功的。”
from gensim.models import Word2Vec
syllModel = Word2Vec.load(syll_model_path)
wordModel = Word2Vec.load(word_model_path)
import pyphen
dic = pyphen.Pyphen(lang='en_US')
poem = '''A plow, they say, to plow the snow.
They cannot mean to plant it, no–
Unless in bitterness to mock
At having cultivated rock.'''
lines = poem.split('\n')
for line in lines:
line = re.sub(r'[^a-zA-Z ]+', '', line.strip())
line = re.sub(' +', ' ', line)
words = line.split(' ')
lyrics = []
for word in words:
syllables = dic.inserted(word).split('-')
if len(syllables) > 0:
for syllable in syllables:
if len(syllable) is 0:
continue
lyric_syllables.append(syllable)
if syllable in syllModel.wv.vocab and word in wordModel.wv.vocab:
lyrics.append([syllable, word])
else:
lyrics.append(["la", "la"])
else:
lyric_syllables.append(word)
if len(syllable) is 0:
continue
if word in wordModel.wv.vocab and syllable in syllModel.wv.vocab:
lyrics.append([word, word])
else:
lyrics.append(["la", "la"])
您还可以看到我是如何处理不在字典中的单词的嵌入。如果一个单词没有在字典里,我只需要用“la”来代替正确的音节数。这是词曲作者的一个传统,当他们还没有写完所有的歌词。
这是这首诗诗句的音节。
A plow, they say, to plow the snow.
['A', 'plow', 'they', 'say', 'to', 'plow', 'the', 'snow']
They cannot mean to plant it, no–
['They', 'can', 'not', 'mean', 'to', 'plant', 'it', 'no']
Unless in bitterness to mock
['Un', 'less', 'in', 'bit', 'ter', 'ness', 'to', 'la']
At having cultivated rock.
['At', 'hav', 'ing', 'la', 'la', 'la', 'la', 'rock']
你可以看到单词mock和cultivated变成了la。
生成旋律
一旦单词和音节的嵌入设置好了,就很容易产生旋律。这里的代码。
length_song = len(lyrics)
cond = []
for i in range(20):
if i < length_song:
syll2Vec = syllModel.wv[lyrics[i][0]]
word2Vec = wordModel.wv[lyrics[i][1]]
cond.append(np.concatenate((syll2Vec, word2Vec)))
else:
cond.append(np.concatenate((syll2Vec, word2Vec)))
flattened_cond = []
for x in cond:
for y in x:
flattened_cond.append(y)
pattern = generate_melody(flattened_cond, length_song)
length_song变量设置为文本行传递的音节数。该模型经过硬编码,可以容纳20个音节,因此代码将限制输入,并在必要时通过重复最后一个音节来填充输入。注意,该填充将被模型忽略,并且我们将得到一个音符向量,该音符等于行中音节的数量。这是旋律。
处理旋律
LSTM-GAN的输出非常好,但存在一些问题:音乐没有量化,而且每一行的键都在变化。LSTM-GAN系统的原始代码具有将旋律“离散化”并将其转置为统一键的功能。但是我选择使用Music21库来执行这些功能。
下面的代码显示了如何将每个音符量化为十六分音符(第12和13行),以及如何将最后一个音符扩展到小节的末尾(第22行)。
import music21
def transpose_notes(notes, new_key):
midi_stream = music21.stream.Stream(notes)
key = midi_stream.analyze('key')
interval = music21.interval.Interval(key.tonic, new_key.tonic)
new_stream = midi_stream.transpose(interval)
return new_stream.notes
# quantize the start times and note durations
for c, n in enumerate(pattern):
n.offset = int(float(n.offset)*4+0.5) / 4
n.quarterLength = int(float(n.quarterLength)*4+0.5) / 4
n.offset += song_length
new_notes.append(n)
pattern_length += n.quarterLength
# stretch the last note out to hold the time
pattern_length_adjusted = float(pattern_length-0.125)
new_length = 4 * (1 + pattern_length_adjusted//4)
diff = new_length - float(pattern_length)
new_notes[-1].quarterLength += diff
the_key = music21.key.Key("C") # C Major
# transpose
new_notes = transpose_notes(new_notes, the_key)
您还可以看到如何使用Music21(第27行在第3行调用该函数)将每行换位到C大调中。这是生成的旋律。
下一步是将旋律传递到Music Transformer以创建一个伴随的轨道,并使旋律更人性化。这里的代码。
model_name = 'transformer'
hparams_set = 'transformer_tpu'
ckpt_path = 'gs://magentadata/models/music_transformer/checkpoints/melody_conditioned_model_16.ckpt'
class MelodyToPianoPerformanceProblem(score2perf.AbsoluteMelody2PerfProblem):
@property
def add_eos_symbol(self):
return True
problem = MelodyToPianoPerformanceProblem()
melody_conditioned_encoders = problem.get_feature_encoders()
inputs = melody_conditioned_encoders['inputs'].encode_note_sequence(melody_ns)
# Generate sample events.
decode_length = 4096
sample_ids = next(melody_conditioned_samples)['outputs']
# Decode to NoteSequence.
midi_filename = decode(
sample_ids,
encoder=melody_conditioned_encoders['targets'])
accompaniment_ns = note_seq.midi_file_to_note_sequence(midi_filename)
前11行代码将设置transformer。代码的其余部分采用名为melody_ns的音符序列,并生成与原旋律合并为伴奏的音轨。
处理的最后步骤是分配乐器并通过保留最后的音符作为额外的措施来创建结尾。这是最后步骤的代码。
def find_closest_note(n, notes):
closest = None
smallest_diff = float("inf")
for x in notes:
if n.pitch == x.pitch:
diff = abs(n.start_time - x.start_time)
if (diff < smallest_diff):
closest = x
smallest_diff = diff
return closest
for n in accompaniment_ns.notes:
n.instrument = 1
n.program = 2 # piano
closest_notes = []
for n in melody_ns.notes:
closest_note = find_closest_note(n, accompaniment_ns.notes)
closest_note.instrument = 0
closest_note.program = 26 # guitar
closest_notes.append(closest_note)
lyric_times.append(closest_note.start_time)
lyric_pitches.append(closest_note.pitch)
# map to the closest notes in the original melody
for c in range(len(closest_notes)-1):
if (closest_notes[c].end_time > closest_notes[c+1].start_time and
closest_notes[c+1].start_time > closest_notes[c].start_time):
closest_notes[c].end_time = closest_notes[c+1].start_time
# hold the last 5 notes to create an ending
pitches = []
for i in range(1,6):
n = accompaniment_ns.notes[-i]
if n.pitch not in pitches:
n.end_time += 4
由于原始旋律的时序在转换器中发生了变化,因此我不得不编写一个小函数来映射两个音序之间最接近的音符。然后,我使用该功能查找更改的音符,以将乐器设置为吉他。最后一个代码块保留了最后五个注释,这是一个额外的措施。这是一个提示歌曲结束的小技巧。
Music Transformer的伴奏确实为乐曲增添了深度和色彩。通过改变MIDI音符的开始时间和速度,该模型还给乐曲带来更人性化的感觉。
结果
通常,这种音乐生成方法会产生不错的效果。
经过调转和调整旋律线的时间,LSTM-GAN似乎为诗歌产生了良好的旋律。诗歌具有成为好音乐的品质,如韵律、结构和抒情流。LSTM-GAN既获取仪表的音节,又获取含义的单词作为输入。来自两种输入的质量导致良好的旋律。请注意,此模型非常一致,因为在给定相同输入文本的情况下,它将生成几乎相同的旋律。
然而,对于Music Transformer同一输入旋律的输出变化很大,有的伴奏效果很差。
引用
[1] S. Hendrix, “Robert Frost wrote this masterpiece in about 20 minutes. It belongs to all of us now.”, The Washington Post, 2019,
[2] R. Frost, “New Hampshire”, 1923, en.wikisource.org/wiki/New_Hampshire_(Frost)
[3] Google, Colab Notebooks, 2019, magenta.tensorflow.org/demos/colab
[4] C. M. Payne, “MuseNet”, OpenAI, 2019, openai.com/blog/musenet
[5] AIVA, “The Artificial Intelligence composing emotional soundtrack music”, 2016
[6] Y. Yu, A. Srivastava, and S. Canales, “Lyrics-Conditioned Neural Melody Generation”, 2019, arxiv.org/pdf/1908.05551.pdf
[7] C.A. Huang, A. Vaswani, J. Uszkoreit, N. Shazeer, I. Simon, C. Hawthorne, A.M. Dai, M.D. Hoffman, M.Dinculescu, and D. Eck, “Music Transformer: Generating Music with Long-Term Structure”, 2018, arxiv.org/pdf/1809.04281.pdf
[8] Yamaha, e-Piano Competition, 2002–2011
[9] Pyphen, Python Hyphenator, 2014
[10] MIT, Music21, 1995
[11] Google, Magenta, 2016
[12] R. Frost, “Plowmen”, A Miscellany of American Poetry, 1920,
[13] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient Estimation of Word Representations in Vector Space”, 2013,
作者:Robert A. Gonsalves
本文代码:https://github.com/robgon-art/Frost-Songs
deephub翻译组
访问原文获取更多信息:https://towardsdatascience.com/frost-songs-using-ai-to-generate-melodies-from-poems-636d26685f0a