

可解释的人工智能(explainable AI) 是机器学习领域热门话题之一。机器学习模型通常被认为是“黑盒”,具有内部不可知的特性。因此这些模型在应用时,往往需要首先获取人们的信任、明确其误差的具体含义、明确其预测的可靠性。本文中,我们将探讨 explainable AI 的内涵及其重要性,并且提供了几个案例以帮助理解。
可解释人工智能的含义
现阶段机器学习的工作流程(从训练到工业应用)大致如下:
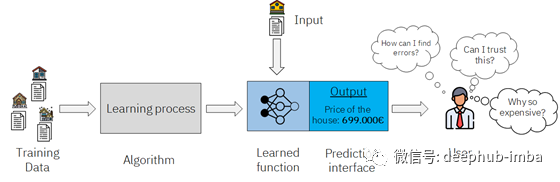
ML 工作流程
上图展示了:基于原始数据通过学习来对模型进行训练;其中学习过程依赖于学习函数,给其输入原始数据,能够输出对应的预测数据;而使用者主要接触并使用预测数据。
具体地,学习函数除了可以是人工神经网络,也可以是决策树、支持向量机、boosting model 等。
当学习函数通过原始数据训练确定后,就可以被用于输入新的数据并且进行预测。在此基础上,使用者便可以及基于预测数据做出决策或采取行动了。
但是其中涉及到的问题,正如图片中的若干问号所示:预测值的准确性及可信度。
通常,运用机器学习模型时,首先需要确定误差函数或者损失函数,通过真实数据和预测数据之间的距离来反映模型的性能。但是误差函数或者损失函数可以说明一切吗?
模型可能表现出较低误差或损失,但是仍然具有一定的偏差,可能不时产生一些奇怪的预测结果。当然,这些意外的预测结果可能让我们发现一些新的规律,但是也可能反映出模型存在某些错误,并且需要进行修正。
即使预测结果不存在问题,我们获得了良好的预测结果,但是这也远远不够。我们不仅仅局限于结果的预测,也倾向于想要知道所使用的模型的内部作用机制,即该模型是怎么做到准确预测的。
上述问题阐述了 Explainable AI 为何被人们所重视。当机器学习中采用 explainable AI 时,其工作流程如下:
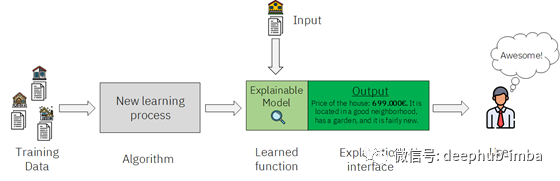
采用 explainable AI 的 ML 模型
上图展示了:采用新的学习机制来训练新的学习函数,形成新的 explainable 模型。这一新的学习函数不仅具有准确预测的能力,同时也能够对其预测结果产生的过程进行溯源解释。这样提供给使用者的就不仅仅是预测的结果,还将能够提供更多的细节。
explainable AI 为何重要?
当我们使用 AI 时,往往需要大量的参数实现对于原始数据的处理和分析,因此导致最后形成难以解释的“黑盒模型”。当然,建立开发该模型的数据科学家或工程师很清楚具体的计算处理过程,但是对于使用者而言,该模型是相对神秘和神奇的。使用者只需要输入数据,然后能够直接得到预测结果。
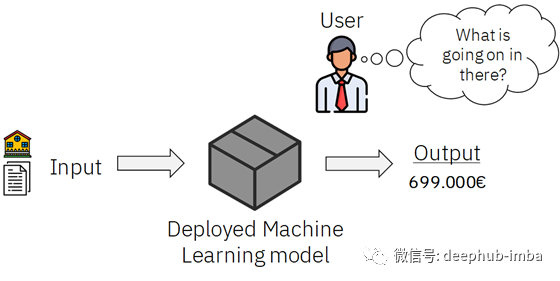
ML 模型=“黑盒”
在 AI 发展早期,人们更多关注于 AI 能不能给出很好的预测结果,因此即使它是“黑盒”也无所谓。但是随着技术的不断发展和深入,人们愈来愈重视 AI 的可解释性。人们想要知道 AI 是如何产生准确的预测结果的。发生这一变化的原因如下:
- 了解机器学习模型进行预测时的内部机制,有助于加快这些模型的广泛应用。
- 可解释性使得 AI 更易于被使用者所接受,让用户更加信任所使用的机器学习模型和系统。
- 对于某些行业,如保险业或银行业,有时会有公司层面的甚至是立法方面的限制,使得这些公司使用的模型必须能够解释。
- 在其他一些关键领域,比如医学领域,人工智能可以产生如此巨大的影响,并惊人地提高我们的生活质量,最基本的是,所使用的模型可以毫无疑问地得到信任。有一个Netflix推荐系统,有时输出奇怪的预测可能不会有很大的影响。但在医学诊断的情况下,不寻常的预测可能是致命的,因此使用者会有更多的质疑,而提供更多的信息能够有助于获得使用者的信任。
- 可解释的模型可以帮助用户更好地利用这些模型所提供的输出,使它们在业务、研究或决策中具有更大的影响力。
但是具有更好预测性能的模型往往具有更差的可解释性。以随机森林和决策树为例,随机森林方法的性能通常优于决策树,但是决策树具有更好的可解释性。
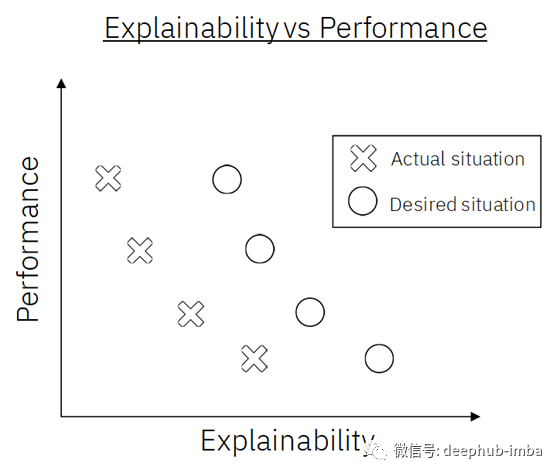
可解释性 VS 模型性能
如上图所示,可解释性和模型性能呈现反比例关系。但是基于这一事实,我们想要进一步实现从 X 到 O 的跃升,即在不降低模型性能的条件下提高模型的可解释性。
explainable AI 实例
为了实现在不降低模型性能的条件下提高模型的可解释性这一目的,可以采用如下方法:
- 使用可解释的模型,如决策树。
- 对难以解释的模型增加解释层以对模型进行解释,如随机森林。
接下来以房价预测为例进行 explainable AI 的阐述。
使用的数据集为:Kaggle 房价预测
该数据集包含了在爱荷华州艾姆斯市的住宅数据,79个解释性变量(几乎)描述了住宅的方方面面,需要基于该数据集预测部分住宅的最终价格。
因为本文的目的在于解释 explainable AI,所以只使用数据集当中的数值型数据,并且所采用的模型使用默认的超参数设定。
使用决策树进行房价预测
决策树是最容易解释的机器学习模型之一。其实现方法非常简单:通过递归地将数据分割成越来越小的组,这些组最终会出现在我们的子节点中。
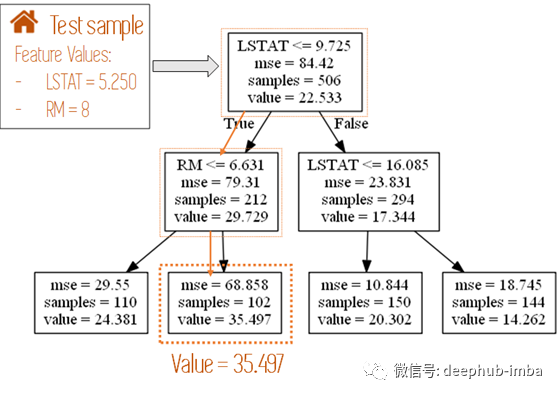
决策树使用示例
上图展示了通过决策树分析利用数据。决策树基于房价数据,依次判断 LSTAT 和 RM 参数,最后分类到最终的子节点中。
那么如何解释决策树的预测过程呢?显然,我们只需要基于样本分类的路径,就能够很好地解释预测结果是如何产生的。

决策树某一样本的分类路径
上图展示了决策树某一样本的分类路径,该样本的房价为 212545 美元。基于路径,可以生成如下解释性语句:“优质建筑,地面生活面积小于1941平方英尺,地下室小于1469平方英尺,车库大于407平方英尺,一楼大于767平方英尺。1978年之后,它被重新改造过。因此,预计价格为212542美元。”
增加解释层(Shapley Values)
决策树虽然能够较为方便地解释结果,但是其预测能力不够强大。往往不能得出最好的预测结果。
使用同样的数据集,用随机森林方法进行预测。将随机森林和决策树的误差函数进行对比:
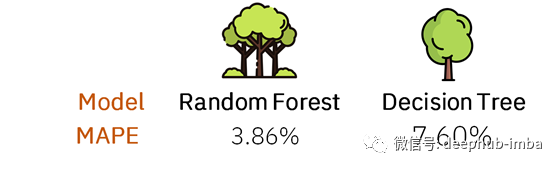
随机森林方法 VS 决策树方法
可以看出,决策树方法的误差几乎是随机森林方法的两倍。
虽然随机森林方法具有更好的预测能力,但是却也更加复杂,如何对其进行解释呢?针对这一问题,可以在模型中增加一个解释层以实现解释的目的。
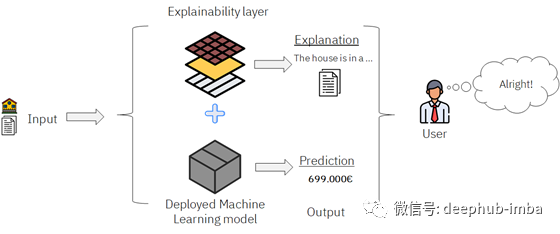
"黑盒"模型中增加解释层
通常,可以使用 Shapley Values 归因算法作为解释层。Shapley Values 来源于游戏理论,主要作用在于反映游戏中每个玩家的贡献大小。被用于机器学习中,则反映每个特征值对于预测结果的贡献大小。
通过 Python 中的 SHAP 库,我们可以调用相关的函数实现指定输入数据的 Shapley Values。在房价预测案例中,我们只需要向 Shapley Explainer 中输入训练数据,该训练数据与 ML 模型中的训练数据一致,并且声明使用的 ML 模型(随机森林方法)。然后 Shapley Explainer 就会生成各个特征值的贡献大小。

Shapley Values
上图显示了各个特征值对于预测结果的贡献大小。粉色和蓝色交汇的点便是模型预测值。最接近粉色和蓝色交汇点的变量是对特定预测影响最大的变量。
粉色的变量及其对应值有助于提高房价,而蓝色的变量及其对应值有助于降低房价。正如我们在这里看到的,最有助于提高房价的变量是 OverallQual,其值为7。
在这种情况下,房屋的质量和建造年份(2003年)是房屋最相关的积极特征。地下室和一层面积的较小值是最相关的负特征。总之,所有这些变量及其值都证明了预测的正确性。
这些信息都可以生成相应的解释性文本,有助于更精确和复杂的模型的解释说明。
当然,除了 Shapley Values 以外,还有其他的解释层方法,如:Permutation Importance、LIME。
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********