

探索性数据分析(Exploratory Data Analysis ,EDA)是对数据进行分析并得出规律的一种数据分析方法。它是一个数据试图讲述的故事。EDA是一种利用各种工具和图形技术(如柱状图、直方图等)分析数据的方法。

根据Tukey****的说法(1961年的资料分析)
“分析数据的程序,解释此类程序结果的技术,计划数据收集以使其分析更容易,更精确或更准确的方法,以及适用于分析数据的(数学)统计的所有机制和结果。”
Python中的EDA
在python中有很多可用的库,例如pandas,NumPy,matplotlib,seaborn等。借助这些库,我们可以对数据进行分析并提供有用的见解。我将同时使用这些库和Jupyter Notebook。
数据集介绍
我使用的数据集是“汽车”数据集,它具有汽车的不同特征,例如型号,年份,发动机和其他属性以及价格。它具有1990年至2017年的28年数据。
数据集地址:https://www.kaggle.com/CooperUnion/cardataset
数据描述
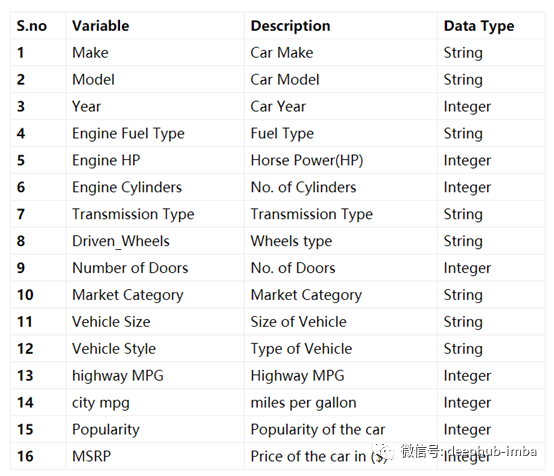
本文的目的是探索数据并为建模做好准备。
让我们开始吧!!!
Python****中的探索性数据分析
首先,我们将导入EDA(探索性数据分析)所需的所有库。这是要做的第一件事也是最重要的事情。如果不导入库,我们将无法执行任何操作。
导入库
数据加载
导入库后,下一步是将数据加载到数据框中。要将数据加载到数据框中,我们将使用pandas库。它支持各种文件格式,例如逗号分隔值(.csv),excel(.xlsx,.xls)等。
要读取数据集,可以将数据文件存储在同一目录中并直接读取,或者在读取数据时提供数据文件所在数据文件的路径。
前5行
现在,数据已加载。让我们检查数据集的前5行。
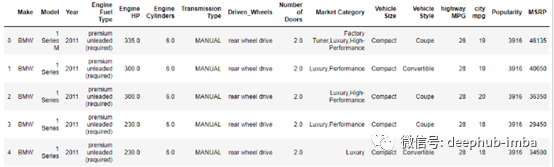
根据以上结果,我们可以看到python中的索引从0开始。
底部5行
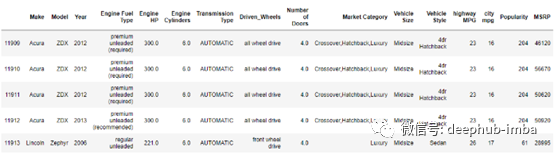
要检查数据框的维数,让我们检查数据集中存在的行数和列数。
数据形状
数据集中共有11914行和16列
数据集的简明信息
现在,检查数据类型以及数据集中所有变量的摘要。它包括存在的非空值的数量。

如果变量中存在字符串,则数据类型将作为对象存储。另外,如果数据分别具有数值和十进制值,则它将为int或float。MSRP(汽车价格)存储为int数据类型,而Driven_wheels存储为对象数据类型。
以上结果表明,许多变量(例如发动机燃料类型,发动机HP,发动机汽缸,门数和市场类型)在数据中缺少值。
我们可以通过另一种方法检查数据类型:

打印数据集的列

由于列的名称很长,让我们重命名它们。
重命名列
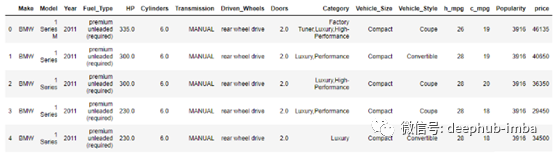
删除列

删除数据框不需要的列。数据中的所有列不一定都相关。在这个数据中,受欢迎程度、门的数量、车辆大小等列不太相关。所以从数据集中删除这些变量。
缺失值:

上述结果表明,在12个变量中,Fuel_type、HP和cylinder这3个变量有缺失值。
让我们检查一下列中缺失数据的百分比
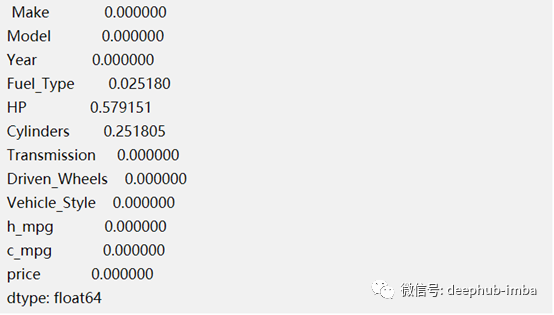
有许多方法可以处理这些缺失的值。
- 删除
- 插补
我们可以删除存在缺失值的行,也可以将缺失值替换为平均值,中位数或众数等值。
由于丢失的数据百分比非常少,我们可以从数据集中删除那些行。

默认情况下,如果任何变量的值缺失,则drop函数将删除整行。
删除缺失值之后,现在缺失值的计数为0。这意味着数据集中不存在缺失值。
删除缺失值后,检查存在的行数。

原来的行数是11914,现在剩下的行数是11813。
统计摘要
现在,让我们找出数据集的统计总结或五点总结。五点总结给出描述性总结,包括每个变量的均值、中位数、众数、编号、行数、最大值和最小值。
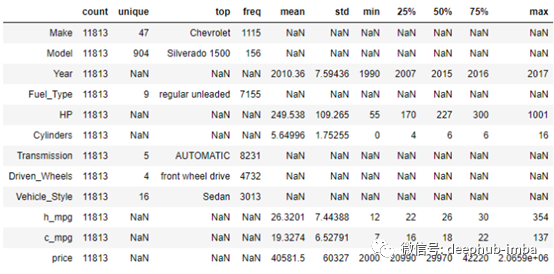
对于具有对象数据类型变量的Mean, standard deviation, max, and percentile values设为NaN 。
对于具有int数据类型变量的 unique, top, frequency设为NaN 。
从描述摘要得出,共有47种车和904款车型。数据显示雪佛兰拥有最多的11115辆汽车。该车的平均价格为40581.5美元。价格的第50 百分位数或中位数是29970。价格的平均值和中位数之间存在巨大差异。这说明价格变量高度偏斜,我们可以使用直方图直观地进行检查。
数据可视化
顾名思义,数据可视化是使用各种类型的图,图形等观察数据。各种图包括直方图,散点图,箱线图,热图等。我们将使用matplotlib和seaborn一起可视化一些变量
直方图(分布图)
直方图用于显示数值变量的形状和分布。对于类别变量,它显示变量中存在的类别计数。
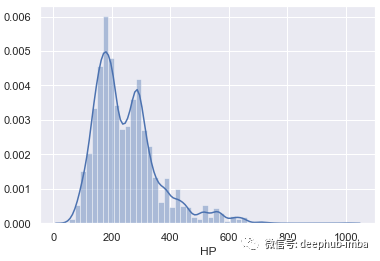
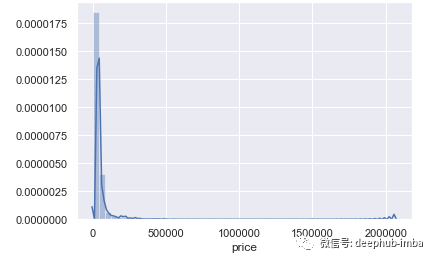
从两个直方图中都可以看出,HP变量分布很均匀。它有点向右倾斜。这意味着它有些偏右,但分布正常。但是,价格变量高度偏斜。
分类变量的直方图
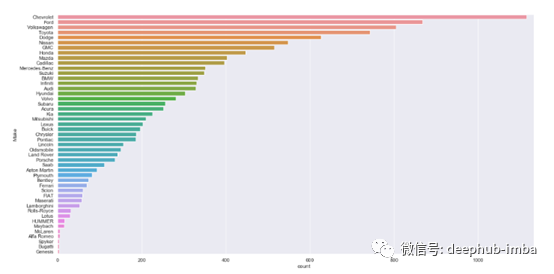
这是“ 制造变量” 的计数图。每个条形图都显示数据集中存在的类别计数。
离群值检查
离群值是与其他值或观察值明显不同的值。离群值会在建模中产生重大问题。因此,有必要找到异常值并对其进行处理。
异常值可以使用箱线图进行检测。箱线图使用四分位数描述变量分布。它也被称为盒须图。
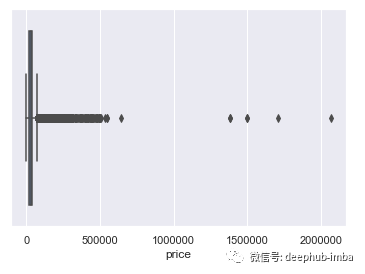
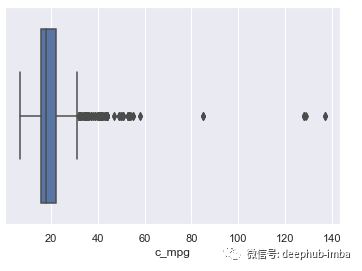
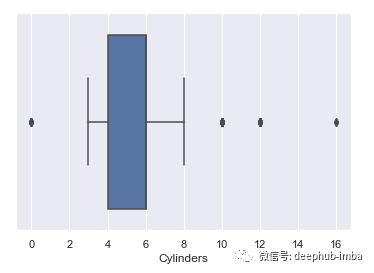
以上所有箱线图显示,price和c_mpg变量中存在许多异常值。在Cylinders变量中,只有4个观测值是异常值。
根据箱形图,超出Q1(25个百分位数)和Q3(75个百分位数)或IQR(四分位数间距)范围之外的任何观测值均被视为异常值。
如果数据集中存在大量异常值,则必须对异常值进行处理。像地板,封盖之类的方法可用于估算离群值。
相关图
计算相关系数,找出两个变量之间的关系强度。相关范围从-1到1。-1相关值为强负相关,1为强正相关。0表示两个变量之间没有关系。
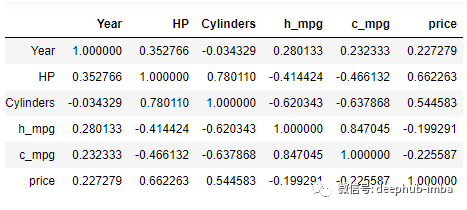
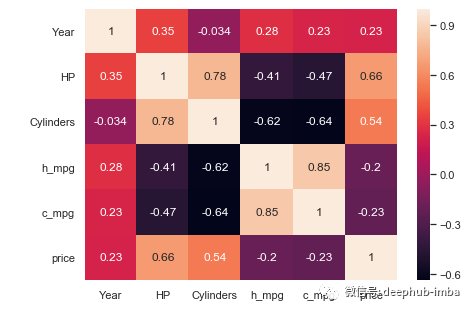
从以上的相关图中可以看出,有很多变量之间是紧密相关的。例如,c_mpg与h_mpg之间的相关值为0.85,接近于1。这意味着他们之间有很强的正相关关系。同理,Cylinders和c_mpg呈负相关。
散点图
使用Pairplot找出变量之间的关系。它绘制每个变量之间的散点图。散点图也可以单独使用。而pairplot将给出一行中所有数值变量之间的关系图。
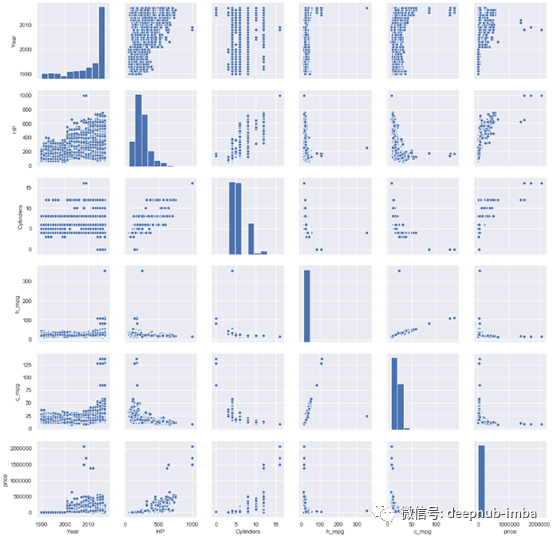
尾注
以上所有步骤都是EDA的一部分。这不是EDA的终点。上面执行的所有步骤都是在进行特征工程或建模之前必须执行的基础数据分析。
EDA是整个数据科学过程中的重要步骤之一。据说模型构建大部分时间都用于EDA和特征工程。如果您想从数据中获取大量的信息,则需要进行大量的EDA。
作者:Manorama Yadav
deephub翻译组:gkkkkkk
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********