
人类可以在图像中构建知识。每次我们看到一个想法或经验时,大脑都会立即对其进行视觉表示。同样,我们的大脑也在不断地在声音或纹理等感官信号与其视觉表现之间切换上下文。我们在视觉表示中思考的能力还没有完全扩展到人工智能 (AI) 算法。大多数 AI 模型都高度专业化于一种数据表示形式,例如图像、文本或声音。而我们研究的最终目的是将开始看到可以在不同数据格式之间有效转换以优化知识创造的人工智能形式。最近来自微软的 AI 研究人员发表了一篇论文,提出了一种基于短文本生成图像的方法。
我们从声音或文字描述中产生视觉表征的能力是人类认知的神奇元素之一。如果你被要求画一幅篮球比赛的图像,你可能会从三到四名球员的轮廓开始。即使没有直接指定,您也可以添加一些细节,如乌鸦、裁判或处于特定位置的球员。所有这些细节都丰富了基本的文本描述,以实现我们对篮球比赛的视觉版本。如果人工智能模型也能做到这一点,那不是很好吗?文本到图像(Text-to-Image, TTI)是深度学习的新兴学科之一,专注于从基本文本表示生成图像。虽然TTI领域还处于非常早期的阶段,但我们已经看到了一些切实的进展,一些模型已经在非常具体的场景中被证明是熟练的。然而,这些都是TTI模型中仍然需要解决的非常具体的挑战。
从文本生成图像:挑战和注意事项
有几个相关的挑战传统上阻碍了TTI模型的发展,但它们中的大多数可以归类为以下类别之一?
1)挑战:TTI模型高度依赖文本和可视化分析技术,尽管近年来它们取得了很大进展,但要实现主流方法,仍有很多工作要做。从这个角度来看,TTI模型的功能通常会受到底层文本分析和图像生成模型的具体限制。
2)概念-对象关系:TTI模型中难以解决的一个问题是从文本描述中提取的概念与其对应的可视对象之间的关系。实际上,可以有一个不定式数量的对象匹配一个特定的文本描述。确定概念和对象之间的正确匹配仍然是TTI模型的关键挑战。
3)物物关系:任何图像都是以视觉的形式表达物体之间的关系。为了反映给定的叙述,TTI模型不仅要生成正确的对象,还要生成它们之间的关系。在文本到图像的生成技术中,生成包含多个具有语义意义的对象的更复杂的场景仍然是一个重大的挑战。
Object-Driven Attentive GAN
为了解决TTI模型的一些传统挑战,微软研究院依赖于日益流行的生成对抗网络(gan)技术。gan通常由两种机器学习模型组成——一个生成器从文本描述生成图像,另一个判别器使用文本描述判断生成图像的真实性。生成器试图让假照片通过鉴别器;另一方面,辨别器不希望被愚弄。通过共同努力,鉴别器将生成器推向完美。微软在传统的GAN模型上进行了创新,引入了自下而上的注意力机制。Obj-GAN模型开发了一个对象驱动的注意力生成器和一个面向对象的识别器,使gan能够合成复杂场景的高质量图像。
Obj-GAN的核心架构通过两个步骤进行TTI合成:
1)生成语义布局:这个阶段包括生成类标签、包围框、突出物体的形状等元素。这个功能由两个主要组件完成:Box Generator和Shape Generator。
2)生成最终图像:这个功能是由一个多级图像生成器和一个鉴别器完成的。
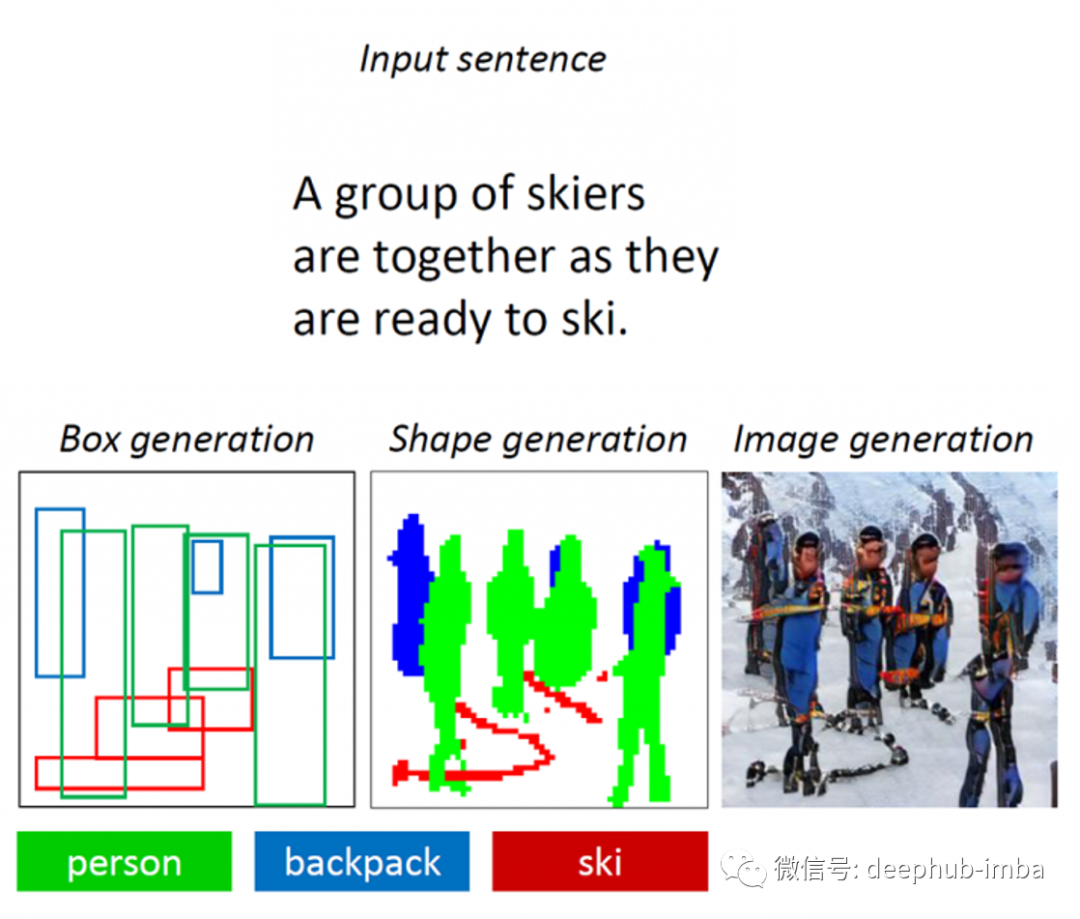
下图提供了Obj-GAN模型的高级架构。该模型接收一个带有一组标记的句子作为输入,然后将其编码为单词向量。在此之后,输入经过三个主要阶段进行处理:框生成、形状生成和图像生成。
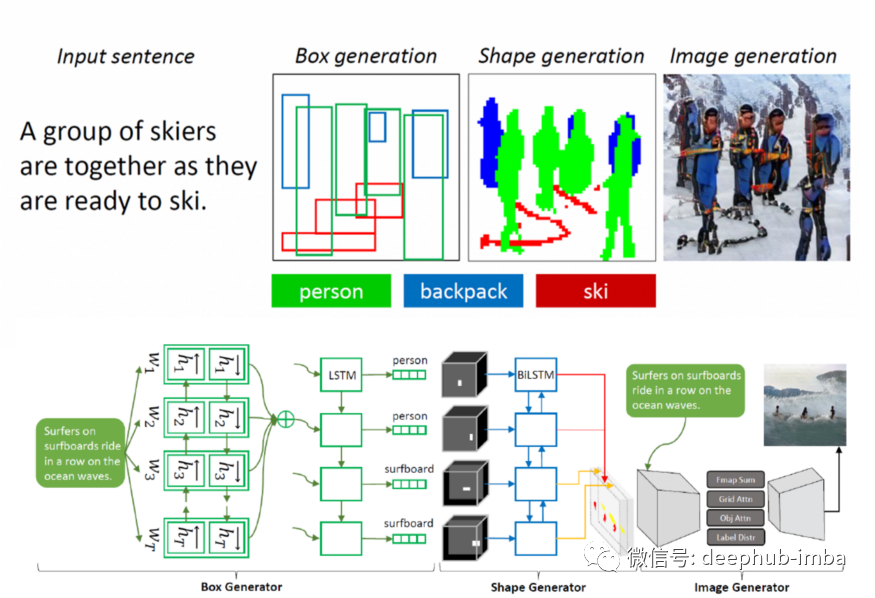
Obj-GAN模型的第一步以句子为输入,生成语义布局,即由其边界框指定的对象序列。模型的边框生成器负责生成一个包围边框序列,然后由形状生成器使用。给定一组边界框作为输入,形状生成器预测相应框中每个对象的形状。由形状生成器产生的形状被图像生成器GAN模型使用。
Obj-GAN包括一个基于两个主生成器的多级图像生成神经网络。基生成器首先根据全局句子向量和预先生成的语义布局生成低分辨率图像。第二个生成器通过关注最相关的单词和预生成的类标签来细化不同区域的细节,并生成更高的分辨率。
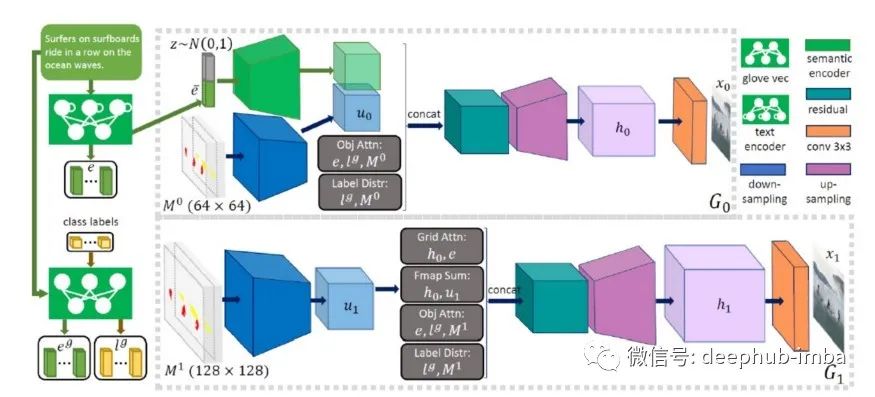
到目前为止,您可能想知道架构的对抗性组件在哪里发挥作用?这就是对象鉴别器的作用。该组件的作用是充当训练图像生成器的对手。Obj-GAN模型包括两个主要鉴别器:
·Patch-Wise Discriminator:这个Discriminator用于训练盒子和形状生成器。第一个鉴别器尝试评估生成的边界框是否与给定的句子相对应,而第二个鉴别器做同样的工作来评估边界框与形状之间的对应关系。
·object - wise Discriminator:该Discriminator使用一组边界框和对象标签作为输入,并尝试确定生成的图像是否与原始描述相对应。
对抗式生成器-鉴别器组合用于边框、形状和图像的生成,使Obj-GAN优于其他传统TTI方法。微软对Obj-GAN与最先进的TTI模型进行了评估,结果非常显著。只要看看生成的图像的质量和它们与原始句子的对应关系就知道了。

创建给定叙述的视觉表示的能力将是下一代文本和图像分析深度学习模型的一个重要重点。Obj-GAN等理念无疑为这一深度学习领域带来了相关创新。
微软论文地址:
本文作者:Jesus Rodriguez