
一、kafka的应用场景
1、解耦(A服务可以直接生产消息,然后不等B的结果,去做别的事。B异步的去消费)
2、异步
3、削峰
二、消息队列的通信模式
1、推拉模式
推拉模式的时候指的是 Comsumer 和 Broker 之间的交互。
** 推模式**:消息从 Broker 推向 Consumer,即 Consumer 被动的接收消息,由 Broker 来主导消息的发送。
优点:
- 消息实时性高, Broker 接受完消息之后可以立马推送给 Consumer。
- 对于消费者使用来说更简单
缺点:
- 推送速率难以适应消费速率,推模式的目标就是以最快的速度推送消息,消费者可能消费不过来。
** 拉模式**:Consumer 主动向 Broker 请求拉取消息,即 Broker 被动的发送消息给 Consumer。
优点:
- 消费者可以根据自身的情况来发起拉取消息的请求。
- 拉模式下 Broker 就相对轻松了,它只管存生产者发来的消息。
- 拉模式可以更合适的进行消息的批量发送
缺点:
- 消息延迟,毕竟是消费者去拉取消息,但是消费者怎么知道消息到了呢。所以它只能不断地拉取,但是又不能很频繁地请求,太频繁了就变成消费者在攻击 Broker 了。因此需要降低请求的频率,比如隔个 2 秒请求一次,你看着消息就很有可能延迟 2 秒了。
- 消息忙请求,比如消息隔了几个小时才有,那么在几个小时之内消费者的请求都是无效的,在做无用功。
2、Kafka拉模式实现原理
RocketMQ 和 Kafka 都是利用“**长轮询**”来实现**拉模式**。Kafka 在拉请求中有参数,可以使得消费者请求在 “长轮询” 中阻塞等待。简单的说就是消费者去 Broker 拉消息,定义了一个超时时间。拉消息时,如果有的话马上返回消息,如果没有的话消费者等着直到超时,然后再次发起拉消息请求。
并且 Broker 也得配合,如果消费者请求过来,有消息肯定马上返回,没有消息那就建立一个延迟操作,等条件满足了再返回。
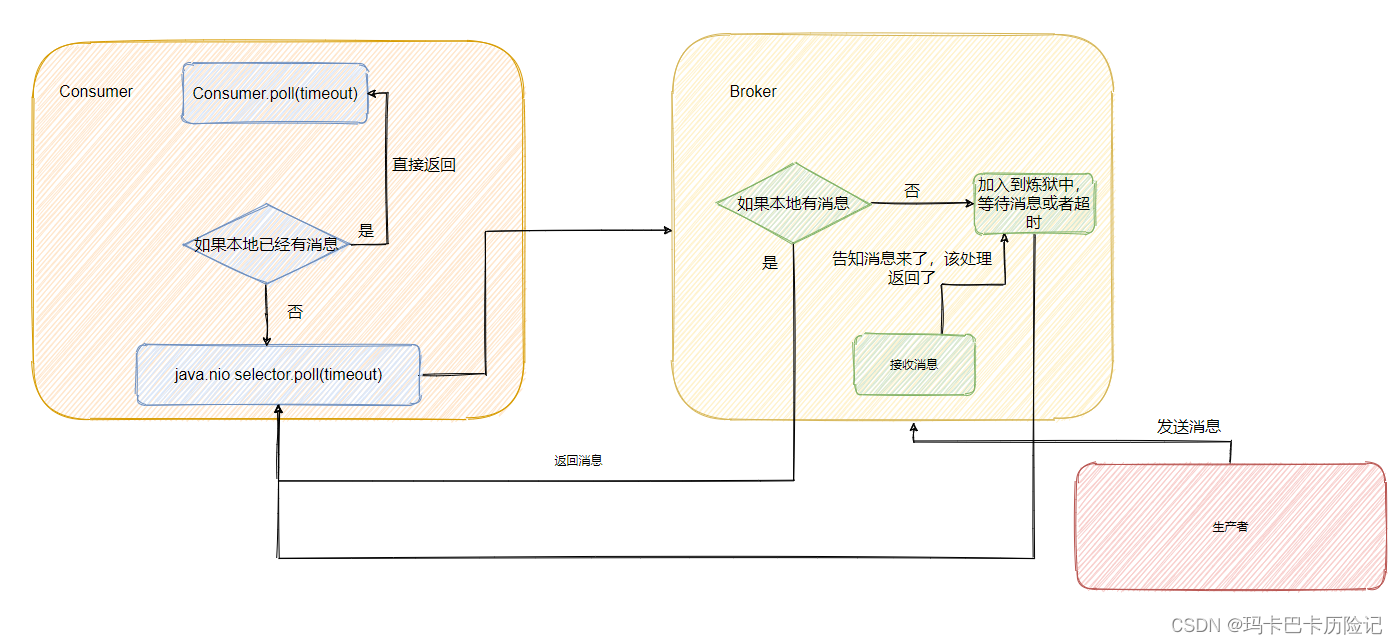
参考:消息队列之推还是拉,RocketMQ 和 Kafka 是如何做的?_kafka_yes_InfoQ写作社区
2.1、消费端实现逻辑
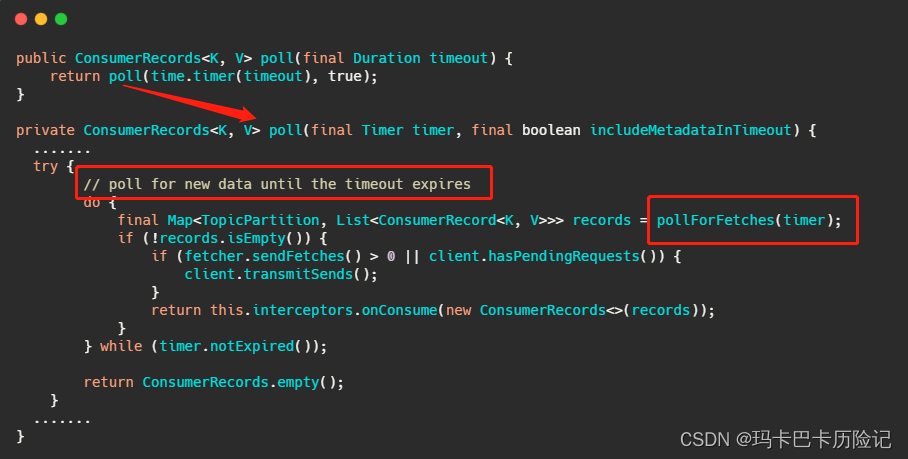
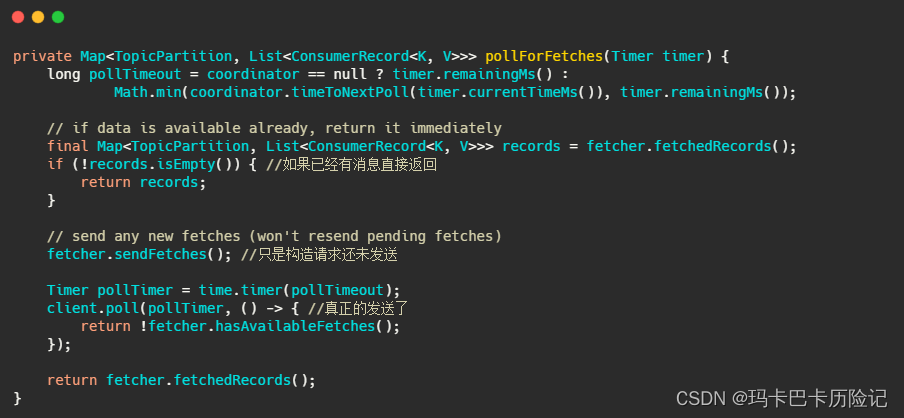
client.poll() 方法如下。实际调用的是kafka的包装过的selector。最终会调用到 Java nio的select(timeout)
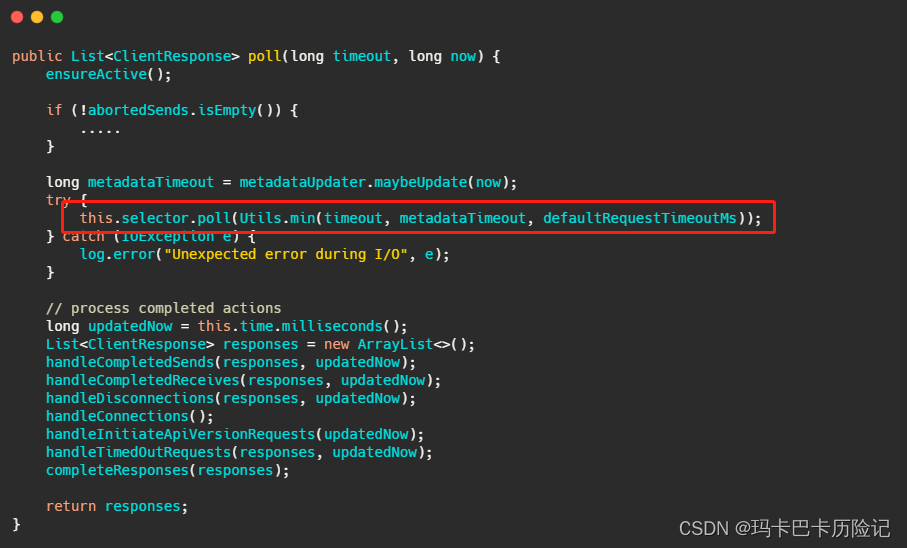
2.2、Kafka实现逻辑
KafkaApis.scala 文件的 handle方法:
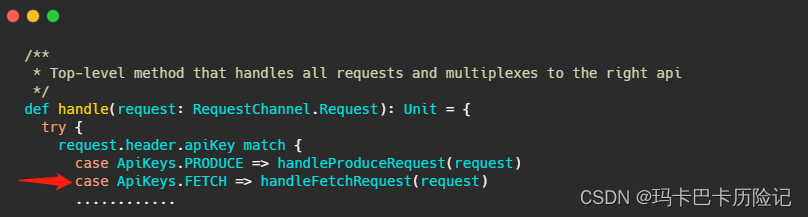
handleFetchRequest的重要部分源码如下:
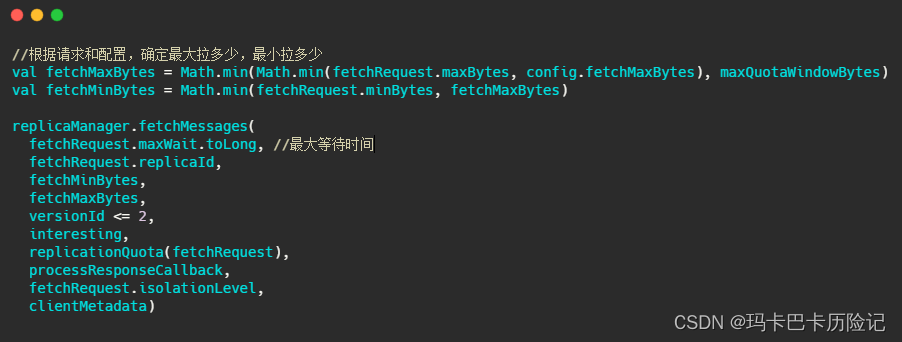
fetchMessages实现如下:

3、点对点和发布订阅
在**点对点系统**中,消息保留在队列中。一个或者多个消费者可以消费队列中的消息,但是**特定消息只能由一个消费者消费**,一旦该消息被一个消费者消费,他就会从队列中消失[不会将消息落磁盘]。
在**发布订阅系统**中,**消息被保存在topic中**。与点对点的不同的是,消费者可以订阅多个topic,**一个topic中的消息可供多个消费组消费**。

Kafka是一种高吞吐量的分布式发布订阅消息系统。具有高性能、持久化、多副本备份、横向扩展能力。
QA:kafka怎么实现点对点?
参考:Kafka如何实现点对点消息和发布订阅消息?-阿里云开发者社区
实现点对点:通过不同的消费者消费不同的partiton实现。
三、kafka的工作原理
1、基本概念及结构

kafka集群结构图
producer:消息的生产者
consumer:消息的消费者
kafka cluster:
** Broker:**是kafka的实例,每个服务器上有一个或者多个Broker。假设一台机器一个Broker实例,每个Broker都有一个不重复的编号
** Topic:**消息的主题,可以理解为消息的分类。kafka的数据就保存在topic中。在每个Broker上都可以创建多个Topic。
** Partition:**Topic的分区。每个Topic可以有多个分区。分区的作用是做负载,提高kafka的吞吐量。同一个Topic的每个分区中的数据是不重复的,partition的表现形式是一个一个文件夹。每个partition只能被一个consumer消费。
** Replication:**每一个分区有多个副本,当Leader故障时,会选择一个follower成为leader。kafka的最大默认副本数是10,且副本的数量不能 > broker的数量。每个partition的副本和leader绝对不在同一台机器上。
2、kafka生产消息的流程
Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!

kafka发送消息流程图
1、producer先从集群获取分区的leader 2、producer将消息发送给分区的leader 3、leader将消息写入本地文件 4、follower从leader poll拉取消息 5、follower将消息写入本地后,向leader发送ack 6、leader收到所有副本的ack后向producer发送ack
注意点:
注意1: 消息写入leader后,follower是主动去leader进行同步的。
注意2: producer采用push模式将消息发布到broker,每条消息追加到分区中,顺序写入磁盘。所以每个分区内的数据是有序的。
问题1: 如果某个topic有多个partition,怎么按照partition写入数据的?
1、producer发送消息的时候指定partition
2、如果producer发送消息的时候没有指定partition。但是设置了key,会通过key值hash出一个partition
3、如果producer发送消息时没指定partition,也没有设置key,会轮询选出一个partition
问题2: kafka怎么保证消息不丢失的?
通过上面生产消息的流程可知,producer向leader发送消息,leader将消息写入本地后会发送ACK。所以保证消息不丢的关键是**ACK应答机制**。生产者向队列写入消息的时候可以设置参数来确定kafka是否收到消息。这个参数有三个值。
0: 表示producer发送给leader就返回,不等待leader写入文件成功就返回ACK。安全性最低但是效率最高。
1: 表示producer发送给leader后,leader写入文件成功就返回ACK。producer可以接着写入下一条。
**all: **表示producer发送给leader后,leader写入文件成功并且所有follower都写入文件成功返回ACK之后,leader再给producer返回ACK。安全性最高,但是效率最低。
问题3: 如果往不存在的topic写入消息会咋样?
kafka会自动新建一个topic,默认partition为1,默认副本数为1.
四、kafka的消息数据是怎么存储的
1、消息存储时机:
producer将消息写入kafka之后,集群就需要对数据进行保存了,kafka会将数据保存在磁盘中。可能在我们的认知中,写入磁盘是一个很耗时的操作,不应该在这种高并发的组件中使用。但是kafka初始会单独开辟出一块磁盘空间,顺序的写入数据(顺序写入比随机写入的效率更高。为啥?)
2、Partition结构
每个topic可以有多个partition,Partition在服务器上的表现形式是**一个一个的文件夹**。每个partition文件夹下面有**很多组的segment文件**。一组segment文件里面包含**.index文件、.log文件、.timeindex文件**。其中 **.log文件** 就是存储message的地方,.index文件和.timeindex文件是索引文件,主要用于检索消息。

Partition文件示意图
如上图所示,这个partition有**三组segment**文件,每个 .log文件 的大小是一样的,但是里面存储的消息条数可能不相同(可能消息的大小不一致)。.log文件 命名前缀是以文件中 message **最小的 offset 命名**。这种方式其实类似二分查找,通过**segment分段 + 索引**的方式来优化查询消息的效率。
3、Message结构
message是存在 .log 文件中的。里面主要存了
offset:占位 8 byte,是一个有序ID,他可以确定一条消息在 partition中的具体位置
消息大小:占位4 byte,用于描述消息大小
消息体:消息体存放的实际是消息数据,被压缩过。占用的空间根据具体的消息大小不一样。
4、存储策略
1、基于时间,默认保存7天。7天之后会删除
2、基于大小,默认保存配置是 1073741824(1G)
** 注意:kafka读取特定消息的时间复杂度是 o(1), 所以删除过期文件并不会提升kafka 的性能。**
5、消费数据
消息存储在 .log 文件 之后就可以开始消费了,kafka采用的是**点对点**通信模式,即消费者**主动**去集群拉取消息消费,与生产消息类似,**消费者也是从leader拉取数据消费**。同一个topic的消息者会组成一个消费组,消费组内的每个消费者可以消费一个或者多个partition,但是,**同一个topic下的每个partition只会被消费组中的一个消费者消费**。所以性能最强的方案是消费组内的消费者个数 == partition 个数(即一台机器消费一个partition)。

consumer消费消息示意图
问题1: kafka怎么快速查找到指定的一条message?(这一切都是建立在 offset 有序的基础上)

segment文件内容展示图
1、通过 offset 找到在那个segment文件组。可以通过 .log文件 的前缀,用二分查找确定。
2、在segment文件组中,打开 .index 文件,查找 <= 相对索引 的那条数据(用的是稀疏索引)在 .log 文件中的位置。
3、在 .log文件 中按照顺序往后查找,找到offset那条数据即可。
如查找368801的offset消息。先通过二分查找找到segment2,368801 - 368796 = 5,即368801在 .log 文件中的相对offset为5。 从 .index 的稀疏索引中找出 <= 5 的最大值,得到 4.256 定位到368800 offset处。然后通过顺序查找,找到368801.
问题2:稀疏索引和稠密索引的区别?
首先对密集索引和稀疏索引的区分在于**是否为每个索引键的值都建立索引**,简单来说就是比如有一列**有序**的值如下:1、2、3、4、5、6、7
密集索引的做法是为这7个值建立索引记录,那么就有7条索引记录,抽象索引记录如下:
1:到1的指针 2:到2的指针 .... 7:到7的指针
稀疏索引的做法是将这个6个值分组,1、2、3和4、5、6和7分为不同的3组,取这三组中最小的索引键值作为索引记录中的索引值,抽象索引记录如下:
1:到顺序存储1、2、3的起始位置的指针 4:到顺序存在4、5、6的起始位置的指针 7:到顺序存储7的起始位置的指针
这两种索引都要通过折半查找或者叫做二分查找来确定数据位置,不同的是密集索引,只需要通过二分查找到搜索值=索引的索引记录就能确定准确的数据位置,而稀疏索引则需要先定位到搜索值>索引值的最小的那个,然后在通过起始位置去定位具体的偏移量。
这是两种不同的索引实现,**一种建立了索引值与数据位置的1:1的关系,一种建立了索引值与数据位置1:n的关系**。在大多数场景密集索引查询效率更高,在大多数场景稀疏索引占用空间更小。
五、offset管理
1、offset分类
offset主要分为 **Current Offse**t 和 **Committed Offset**。Current Offset 主要是consumer用来poll()消息的,**保证不拉取到重复的消息**。Committed Offset 主要是用于 consumer rebalance。如果一个partition被重新rebalance,那么新的consumer就应该从Committed Offset开始消费新消息, **避免了重复消费**。
current offset: 是由consumer维护的,表示下一条希望收到的消息序号,仅仅在 poll() 方法中使用。例如第一次poll() 了20条消息,那么current offset就被设置成了20,下一次poll希望收到序号为20的消息。
commited offset: 保存在broker的,_consumer_offset 的topic里面。表示consumer确认已经消费过的消息序号。主要通过commitSync 和 commitAsync API 来操作。
2、Group Coordinator
Group Coordinator是运行在Kafka集群中每一个Broker内的一个进程。它主要负责Consumer Group的管理,Offset位移管理以及Consumer Rebalance。
对于每一个Consumer Group,Group Coordinator都会存储以下信息:
1、订阅的topics列表
2、Consumer Group配置信息,包括session timeout等
3、组中每个Consumer的元数据。包括主机名,consumer id
4、每个Group正在消费的topic partition的当前offsets
5、Partition的ownership元数据,包括consumer消费的partitions映射关系
问题1: Consumer Group如何确定自己的coordinator是谁呢?
1、确定Consumer Group offset信息将要写入__consumers_offsets topic的哪个分区。具体计算公式:partition = Math.abs(groupId.hashCode() % offsets.topic.num.partitions) 。默认50个分区
2、该分区leader所在的broker就是被选定的coordinator
3、offset 存储模型
由于一个partition只能被一个consumerGroup 中的一个consumer消费。所以 kafka保存offset时并不直接为每个消费保存。而是以 group_id-topic-partition(key) -> offset(value) 的方式将 consumerGroup 和 partition 对应的offset 以消息的形式保存在 _consumer_offset 的topic里面。

offset存储模型
4、offset 查询
通过 offset Cache。consumer 提交offset的时候,kafka Offset manager会首先追加一条新的conmit消息到 _consumer_offset topic中,然后更新对应的缓存,读offset时从缓存中读取,而不是直接读取 _consumer_offset topic。

Offset Cache
问题1:如果kafka中没有对应的offset信息(有可能offset被删除了),消费者应该从何处开始消费?
读取 auto.offset.reset 参数
1、earliest: 从最早的offset开始消费 2、latest: 从最近的offset开始消费 3、none: 报错
问题2: 如果consumer消费了5条消息,然后宕机,重新连接后从哪个位置开始消费?
从第6条消息开始消费,这是因为重启后读取 commited offset 为5,防止重复消费从6开始
问题3: 如果consumer第一次接入一个已经存在的topic,此时kafka中不存在这个consumer的消费offset信息,从哪开始消费?
看消费的哪个partition,按照groupid+topic+partation 去 consumer_offset 查找commited_offset 存在就继续消费,不存在按照 auto.offset.reset 参数配置的开始消费。
六、Rebalance
在新建一个Consumer时,我们可以通过指定groupId来将其添加进一个Consumer Group中。Consumer Group是为了实现多个Consumer能够并行的消费一个Topic,并且一个partition只能被一个Consumer Group里的一个固定的Consumer消费。
1、触发场景
1、有新的消费者加入Consumer Group。
2、有消费者主动退出Consumer Group。
3、Consumer Group订阅的任何一个Topic出现分区数量的变化
2、Rebalance策略
默认情况下,Kafka提供了两种分配策略:Range和RoundRobin。且Rebalance过程中,所有consumer都不可以消费。举个例子,比如有两个消费者C0和C1,两个topic(t0,t1),每个topic有三个分区p(0-2)。那么采用Range策略,分配出的结果为:
C0: [t0p0, t0p1, t1p0, t1p1]
C1: [t0p2, t1p2]
采用RoundRobin策略(所有topic一起排序),分配出的结果为:
C0: [t0p0, t0p2, t1p1]
C1: [t0p1, t1p0, t1p2]
QA:用db设计实现Kafka,表结构应该是咋样的?需要加什么索引?
对kafka来说,最主要的有两点:
- 按照topic + consumerGroupId + partition: 唯一键获取当前的commit offset。
- 按照topic+ partition + offset: 查到对应的消息。
CREATE TABLE `commit_offset_manage_detail` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '数据库自增主键', `topic` varchar(32) NOT NULL DEFAULT '' COMMENT '消息Topic', `consumer_group_id` varchar(32) NOT NULL COMMENT '消费组ID', `partition` int(10) NOT NULL COMMENT 'topic分区', `commit_offset` bigint(10) NOT NULL COMMENT '消费组已提交的offset', `consumer_ip` varchar(32) NOT NULL COMMENT '消费组中消费者ip', `created_at` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间', `updated_at` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '更新时间', PRIMARY KEY (`id`), UNIQUE KEY `uk_topic_group_id_partition` (`topic`,`consumer_group_id`,`partition`), KEY `idx_created_at` (`created_at`), KEY `idx_updated_at` (`updated_at`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='消费组管理明细表'; -- 可以按照 topic分库,partition分表进行水平扩展 CREATE TABLE `manage_detail` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '数据库自增主键', `topic` varchar(32) NOT NULL DEFAULT '' COMMENT '消息Topic', `partition` int(10) NOT NULL COMMENT 'topic分区', `offset` bigint(10) NOT NULL COMMENT 'offset', `message_size` int(10) NOT NULL COMMENT '消息大小', `message` varchar(526) NOT NULL DEFAULT '' COMMENT '消息体', `created_at` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间', `updated_at` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '更新时间', PRIMARY KEY (`id`), UNIQUE KEY `uk_topic_partition_offset` (`topic`,`partition`,`offset`), KEY `idx_created_at` (`created_at`), KEY `idx_updated_at` (`updated_at`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='消费明细表';
Kafka Consumer Group和Consumer Rebalance机制
Kafka 读写原理与存储结构
Kafka消息送达语义详解
Kafka事务特性详解
Kafka常见问题精选
Kafka架构设计
版权归原作者 玛卡巴卡历险记 所有, 如有侵权,请联系我们删除。