

“今晚吃什么?”——这是经常困惑人们的问题之一。而Meal Kit 烹饪食材配送服务 则完美解决了人们的这一问题,为人们提供了一条非常便捷的方式,使得人们能够不用特意制定用餐计划和外出购物,就能够直接在家完成烹饪。Meal Kit 烹饪食材配送服务目前已经是一个15亿美元的市场,而且呈不断增长的趋势。四分之一的美国人都表示曾经使用过 Meal Kit 烹饪食材配送服务。

该项目由哥伦比亚大学MS商业分析项目的Aditi Khandelwal、Amrita Dutta、Aneesh Goel和Simran Kalera完成。本文的目的是基于历史数据,通过机器学习的方法实现对于每周需求的预测。主要目标在于开发一个模型用于减少配送损失。
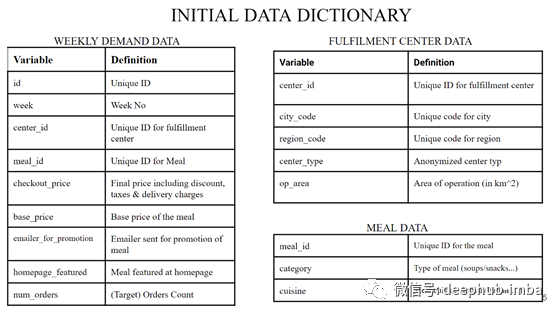
数据词典
首先,我们有三个烹饪食材配送服务相关的数据集。
- 145 周的每周需求数据
- 每个供应中心的地理数据
- 每个订单的食材种类(小吃/汤...)及类别(印度/意大利...)
第一步包括合并三个数据集并查找缺失的值。在时间序列中,缺失的数据可能会隐藏起来,因为数据可能在时间步长(1周)内不一致,这将在构建模型时可能会导致问题。对每个供应中心标识的数据进行分组。其中一些食材并非每周订购/提供的,那么将这几周的需求量取为0,但是价格设置为组内食材的平均值。我们假设这些食材在缺失的几周内是有提供的,但是没有人买。
在研究了餐盒市场后,人们意识到大部分成本来自易腐商品。对于一个企业来说,在当前一周内了解下一周的需求是很重要的。这将帮助他们订购/安排新的库存,并为下周的订单管理物流。
特征工程
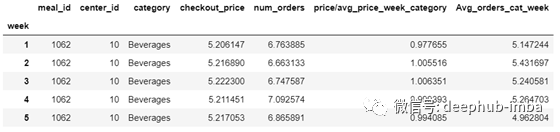
在进行探索性数据分析后,将价格和需求数据进行对数处理,得到各项的正态分布数据。这些数据中有很多是类型数据,因此需对其进行一定的处理,便于反映捕捉这些变量的每周平均需求的特性,如:Avg_orders_cat_week。
根据不同类别,制定了反映周价格波动的比率。例如,price/avg_price_week_category 的比率表明,第1周1062餐的价格比同一周所有饮料的平均价格低0.977。这里反映出价格低廉的饭菜可能需求量更大。
我们提出的第二类特征是超前和滞后特征,这是时间序列预测的核心。一个显而易见的问题是,我们将数据滞后多少时间步?
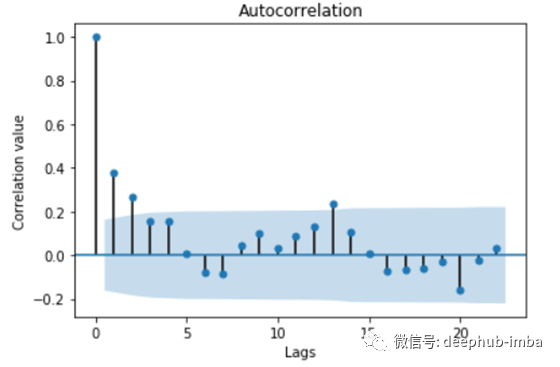
需求的自相关图显示,最佳滞后数为2(如果这些值不在锥体范围内,则相关性在统计上显著,否则可能是偶然的)。
在选择了最优滞后参数后,我们创建了超前-滞后特征,并建立了预测模型所需的数据库。下图中的每一行都是输入模型的内容。假设我们在第4周,我们要预测第5周的需求(lead)。我们使用了第4周的一些特性,第3周的一些特性,以及第5周本身的一些特性(假定餐费、折扣等能够在一周前确定)。

涉及到的主要特征有:
- 第四周的需求(demand)
- 第三周的需求(demand_lag1)
- 之前各周的平均需求(expanding_mean)
- 第三周和第四周订单的加权平均(weighted_average_2w)
- 第二周、第三周、第四周订单的加权平均(weighted_average_3w)
- 第四周的折扣(perc_diff)
- 第五周的折扣(perc_diff_lead1)
将数据库分为训练数据、验证数据、测试数据。其中训练数据集包含第3周到第142周的数据;验证数据集包含第144周到145周的数据。下图展示了不同模型的性能:
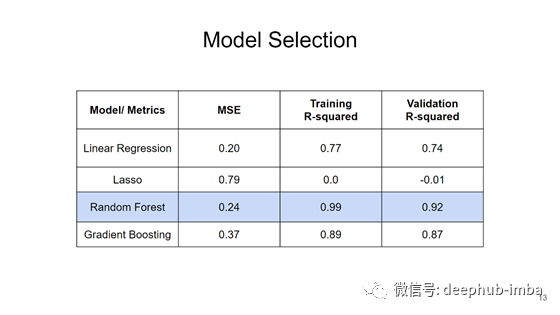
随机森林在均方误差和R平方方面都给出了可比较的结果,并且可以进一步调整,因此本文主要选择随机森林算法。
在微调最大深度参数过后,我们重新在训练集和验证集上进行训练,最后将模型用于测试集的预测。得到的均方根误差为0.31;R平方误差为:0.89。
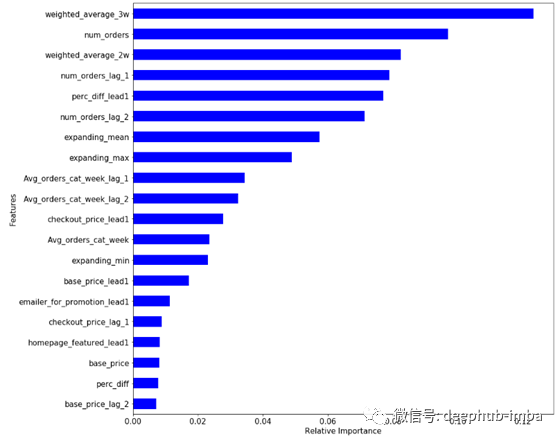
特征重要性图直观显示出滞后特征是下周需求最重要的预测因子。
使用预测模型的价值
这个行业亏损的主要原因是易腐物品的保质期有限。如果需求预测不准确,可能会导致订单预测过高或过低。假设我们的随机森林回归预测结果显示订单是5个,而实际观察到的销售额是6个,我们低估了我们的需求,因此失去了一个订单,我们称之为“订单损失”。类似地,如果我们的模型预测5个订单,实际销售额是4个,这是一个过度预测的情况,这将导致我们所说的由于变质易腐物品产生的“库存损失”,。
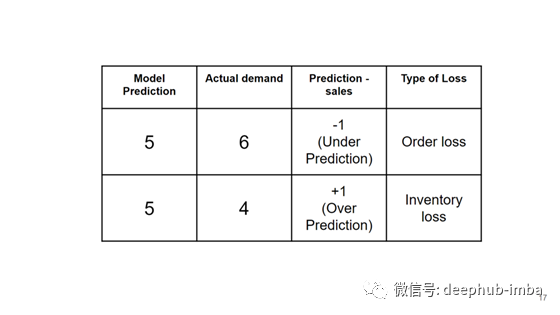

我们对这个商业模式做了一些假设,如上图所示。存货损失就是我们在高估存货成本的情况下所发生的损失。另一方面,订单损失是由于预测不足而造成的损失,我们无法满足需求,从而损失了利润。
那么如果公司没有预测模型呢?
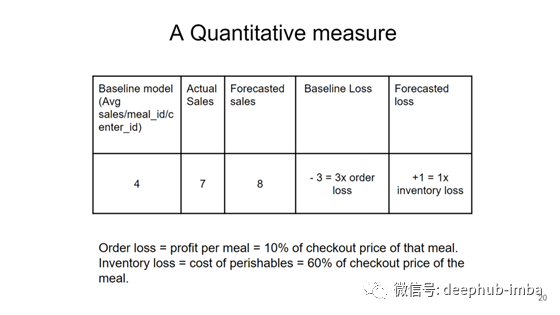
基线比较:如果一家公司根本没有任何预测模型,那么我们假设他们会取第1周到第144周的订单平均值,并基于平均值预测下一周的订单。
如果基准模型预测的需求为4,而实际需求为7,我们将得到-3的基准损失,这是我们利润的3倍。如果我们的集成模型预测需求为8,那么这将导致库存损失的1倍。然后,通过计算所有进餐ID和中心ID的累计损失总和来计算总基线损失和预测损失。
预测模型的实际效果
基准模型的损失:386015 美元。
集成模型的损失:279384 美元。
通过预测模型,可以实现帮助公司每周减少106631美元的损失。
附加用例:判断价格变化下的需求弹性。
现在,我们已经实现了尽量减少损失的目标,我们探索的另一个用例是:如果成本增加25%,我们的模型能预测需求的变化吗?
在一个理想的世界里,我们需要一个模型,它能给出一个完美的预测,不会给我们带来损失,但这样的理想情景并不存在。考虑到我们的模型的预测是准确的,我们将支付价格提升25%,然后再运行我们的模型。结果显示,这使得每周减少了46000个订单,因为这些客户可能都是对价格敏感的客户。
同样,如果我们推出50%的黑色星期五销售,我们预计将每周增加40524个订单。
可以看出,预测模型除了能够对时间序列进行预测以外,还能够对于需求的价格敏感性进行量化。
作者:Aditi Khandelwal
本文代码地址:https://github.com/aditi310896/Demand-Forecasting
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********