
1. 引言
我们之前已经学习了Sarsa算法和Q-learning算法,我们知道这两者都是基于TD算法的,我们又知道TD算法效果改变受TD target影响,我们思考一下,如果我们选用包含真实信息更多的TD target,效果会不会更好呢?下面我们来进行数学推导。
2. 数学推导
一切都源于这个公式:,我们再使用这个公式将
展开得到
这个公式相较于前一个公式更加精确,因为它含有 两个真实信息,而前面的公式只有一个
,于是我们可以进一步递推这个公式,将其展开
次得到
这样我们便可以将Sarsa算法中的TD target 修正为
特别地当时我们得到之前推导TD target
将Q-learning算法中的TD target 修正为
特别地当时我们得到之前推导TD target
由于我们获得了更准确的TD target,所以我们需要付出一些代价,这些代价就是,我们需要计算更多的return,于是原来的transition
变成了
3. 文献
有文献表明[1],m-step TD target往往比1-step TD target效果更好
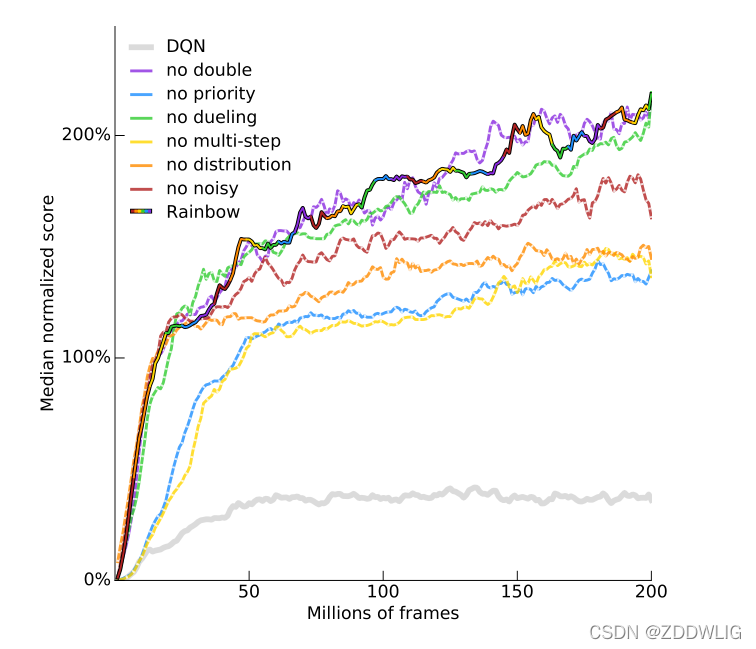
我们可以看到代表使用multi-step的Rainbow(彩虹线)比没有使用的no multi-step 的黄线得分更高,说明其效果更好
[1][1] Hessel, M. , Modayil, J. , Hasselt, H. V. , Schaul, T. , Ostrovski, G. , & Dabney, W. , et al. (2017). Rainbow: combining improvements in deep reinforcement learning.
标签:
深度学习
本文转载自: https://blog.csdn.net/ZDDWLIG/article/details/123763834
版权归原作者 ZDDWLIG 所有, 如有侵权,请联系我们删除。
版权归原作者 ZDDWLIG 所有, 如有侵权,请联系我们删除。