
Sharded是一项新技术,它可以帮助您节省超过60%的内存,并将模型放大两倍。
深度学习模型已被证明可以通过增加数据和参数来改善。即使使用175B参数的Open AI最新GPT-3模型,随着参数数量的增加,我们仍未看到模型达到平稳状态。
对于某些领域,例如NLP,最主要的模型是需要大量GPU内存的Transformer。对于真实模型,它们只是不适合存储在内存中。微软的Zero论文介绍了称为Sharded的最新技术,他们开发了一种技术,可以使我们接近1万亿个参数。
在本文中,我将给出sharded工作原理,并向您展示如何利用PyTorch 在几分钟内用将使用相同内存训练模型参数提升一倍。
由于Facebook AI Research的FairScale团队与PyTorch Lightning团队之间的合作,PyTorch中的此功能现已可用。
本文大纲
- 本文适用于谁?
- 如何在PyTorch中使用Sharded
- Sharded后的工作原理
- Sharded与模型并行
本文适用于谁?
本文适用于使用PyTorch训练模型的任何人。Sharded适用于任何模型,无论它是哪种类型的模型,无论是NLP,视觉SIMCL,Swav,Resnets还是语音。
以下是这些模型类型在Sharded时可以看到的性能提升的快速快照。

SwAV是计算机视觉中自我监督学习的最新方法。
DeepSpeech2是最先进的语音方法。
图像GPT是最先进的视觉方法。
Transformer 是NLP的最新方法。
如何在PyTorch中使用Sharded
对于那些没有足够的时间来了解Sharded工作原理的人,我将在前面解释如何在您的PyTorch代码中使用Sharded。但是,我鼓励您通读本文结尾,以了解Sharded的工作原理。
Sharded意味着可以与多个GPU一起使用以获得所有好处。但是,在多个GPU上进行训练会比较复杂,并且会造成巨大的痛苦。
使用Sharded为代码添加代码的最简单方法是将模型转换为PyTorch Lightning(这只是一个简单的重构)。
完成此操作后,在8个GPU上启用Sharded就像更改一个标志一样简单,因为无需更改代码。
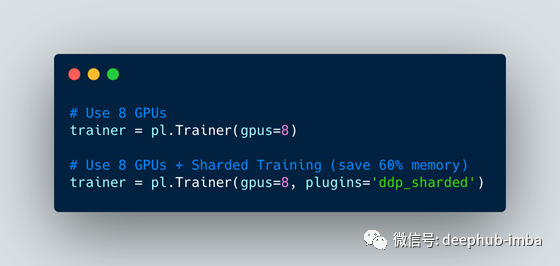
如果您的模型来自另一个深度学习库,那么它仍然可以与Lightning(NVIDIA Nemo,fast.ai,huggingface transformers)一起使用。您需要做的就是将该模型导入LightningModule并运行训练。
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
Sharded的工作原理
在许多GPU上进行有效训练有几种方法。在一种方法(DP)中,每批都分配给多个GPU。这是DP的说明,其中批处理的每个部分都转到不同的GPU,并且模型多次复制到每个GPU。
但是,这种方法很糟糕,因为模型权重是在设备之间转移的。此外,第一个GPU维护所有优化器状态。例如,Adam 优化器会保留模型权重的完整副本。
在另一种方法(分布式数据并行,DDP)中,每个GPU训练数据的子集,并且梯度在GPU之间同步。此方法还可以在许多机器(节点)上使用。在此示例中,每个GPU获取数据的子集,并在每个GPU上完全相同地初始化模型权重。然后,在向后传递之后,将同步所有梯度并进行更新。
但是,该方法仍然存在一个问题,即每个GPU必须维护所有优化器状态的副本(大约是模型参数数量的2-3倍)以及所有向前和向后激活。
Sharded消除了这些冗余。除了仅针对部分完整参数计算所有开销(梯度,优化器状态等)外,它的功能与DDP相同,因此,我们消除了在所有GPU上存储相同的梯度和优化器状态的冗余。
因此,每个GPU仅存储激活,优化器参数和梯度计算的子集。
使用分布式模式

通过使用这些优化方法中的任何一种,可以通过多种方法来压缩分布式训练中的最大效率。
好消息是,所有这些模式都可在PyTorch Lightning中使用,而零代码更改则可用。您可以尝试其中的任何一种,并根据需要根据您的特定模型进行调整。
最后论文在这里:https://arxiv.org/abs/1910.02054
作者:William Falcon
deephub翻译组译