
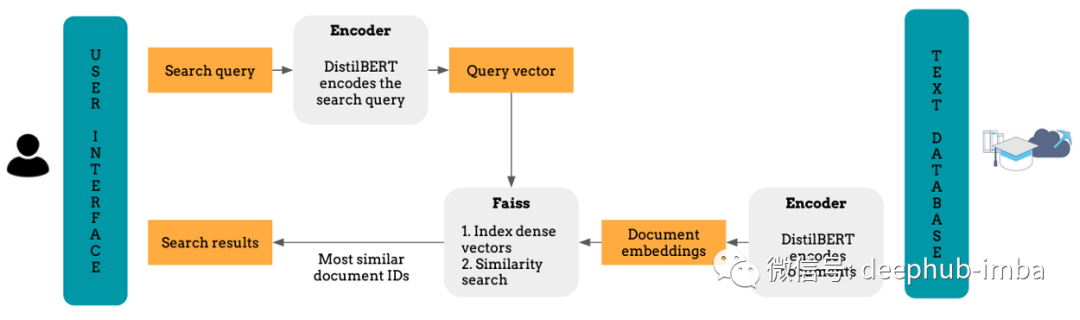
介绍
您是否曾经想过如何使用Sentence Transformers创建嵌入向量,并在诸如语义文本相似这样的下游任务中使用它们?
在本教程中,您将学习如何使用Sentence Transformers和Faiss构建一个基于向量的搜索引擎。代码地址会在本文的最后提供
为什么要构建基于向量的搜索引擎?
基于关键字的搜索引擎很容易使用,在大多数情况下工作得很好。你要求机器学习论文,他们会返回一堆包含精确匹配或接近变化的查询结果,就像机器学习一样。其中一些甚至可能返回包含查询的同义词或出现在类似上下文中的单词的结果。其他的,如Elasticsearch,可以快速、可伸缩地完成所有这些功能,甚至更多。然而,基于关键词的搜索引擎通常会遇到以下问题:
- 复杂查询或具有双重含义的单词。
- 长查询,如论文摘要或博客中的一段。
- 不熟悉某个领域术语的用户或想要进行探索性搜索的用户。
基于向量(也称为语义)的搜索引擎通过使用最先进的语言模型找到文本查询的数字表示,在高维向量空间中对它们进行索引,并度量查询向量与索引文档的相似程度,从而解决了这些缺陷。
索引、矢量化和排序方法
在深入学习本教程之前,我将简要解释基于关键字和基于向量的搜索引擎如何进行以下工作的
- 索引文档(即以一种容易检索的形式存储它们
- 向量化文本数据
- 衡量文档与查询的相关性
这将帮助我们突出两种系统之间的差异,并理解为什么基于矢量的搜索引擎可以为长文本查询提供更有意义的结果。
1、基于关键字搜索引擎
让我们以一个过于简化的Elasticsearch为例。Elasticsearch使用标记器将文档分割成标记(即有意义的文本单位),这些标记映射到数字序列,并用于构建反向索引。

反向索引:与检查每个文档是否包含查询词不同,反向索引使我们能够查找一个词并检索包含该词的所有文档列表。源
同时,Elasticsearch用一个高维加权向量表示每个索引文档,其中每个不同的索引项是一个维度,它们的值(或权重)是用TF-IDF计算的。
为了找到相关文档并对其进行排序,Elasticsearch将布尔模型(BM)与向量空间模型(VSM)结合在一起。BM标记包含用户查询的文档,VSM评分它们的相关性。在搜索过程中,使用相同的TF-IDF管道将查询转换为向量,文档d对查询q的VSM得分为加权查询向量V(q)和V(d)的余弦相似度。
这种度量相似度的方法非常简单,而且不可扩展。Elasticsearch背后的工作机器是Lucene,它使用了各种技巧,从增强领域到改变矢量的标准化方式,以加快搜索速度和提高其质量。
Elasticsearch在大多数情况下工作得很好,然而,我们希望创建一个系统,也关注单词的上下文。这把我们带到了基于矢量的搜索引擎。
2、基于矢量的搜索引擎
我们还需要创建考虑单词上下文的文档表示。我们还需要一种高效可靠的方法来检索存储在索引中的相关文档。
创建密集的文档向量
近年来,NLP社区在这方面取得了长足的进步,许多深度学习模型都是开源的,并通过像Huggingface 's transformer这样的软件包进行分发,这些软件包提供了最先进的、经过预先训练的模型。使用预先训练好的模型有很多优点:
- 它们通常生成高质量的嵌入,因为它们是在大量文本数据上训练的。
- 它们不需要您创建自定义标记器,因为转换器有自己的方法。
- 根据您的任务对模型进行微调很简单
这些模型为文档中的每个标记生成一个固定大小的向量。我们如何获得文档级向量呢?这通常通过平均或汇集单词向量来实现。然而,这些方法产生低于平均的句子和文档嵌入,通常比平均GloVe向量差。
为了构建我们的语义搜索引擎,我们将微调基于BERT的模型,以生成语义上有意义的长文本序列嵌入。
建立一个指数并衡量相关性
检索相关文档最简单的方法是测量查询向量和数据库中每个文档向量之间的余弦相似度,然后返回得分最高的那些。不幸的是,这在实践中非常缓慢。
首选的方法是使用Faiss,一个有效的相似度搜索和聚类密集向量库。Faiss提供了大量的索引和复合索引。此外,给定一个GPU, Faiss可扩展到数十亿个向量!
用Transformers 和Faiss构建一个基于向量的搜索引擎
在这个实际的例子中,我们将使用真实的数据。通过使用Orion查询微软的学术图表,我创建了一个包含8,430篇发表于2010年至2020年的关于错误信息、虚假信息和假新闻的学术文章的数据集。
我检索了论文的摘要、标题、引用、发表年份和ID。我做了最少的数据清理,比如删除没有摘要的论文。数据是这样的:

导入Python包并从S3读取数据
让我们导入所需的包并读取数据。该文件是公开的,所以您可以在谷歌Colab上运行代码,或者通过访问GitHub repo在本地运行代码!
# Used to import data from S3.
import pandas as pd
import s3fs
# Used to create the dense document vectors.
import torch
from sentence_transformers import SentenceTransformer
# Used to create and store the Faiss index.
import faiss
import numpy as np
import pickle
# Used to do vector searches and display the results.
from vector_engine.utils import vector_search, id2details
# Use pandas to read files from S3 buckets!
df = pd.read_csv('s3://vector-search-blog/misinformation_papers.csv')
使用Sentence Transformers对文档进行矢量化
接下来,我们对论文摘要进行编码。Sentence Transformers提供了许多预先训练过的模型,其中一些可以在这个电子表格中找到。在这里,我们将使用base-nli- stbs -mean-tokens模型,该模型在语义文本相似度任务中表现出色,而且比BERT要快得多,因为它要小得多。
我们将做如下的工作:
- 通过将模型名作为字符串传递来实例化transformer。
- 切换到GPU,如果它是可用的。
- 使用' .encode() '方法对所有论文摘要进行向量化。
# Instantiate the sentence-level DistilBERT
model = SentenceTransformer('distilbert-base-nli-stsb-mean-tokens')
# Check if CUDA is available ans switch to GPU
if torch.cuda.is_available():
model = model.to(torch.device("cuda"))
print(model.device)
# Convert abstracts to vectors
embeddings = model.encode(df.abstract.to_list(), show_progress_bar=True)
建议使用GPU对文档进行矢量转换。
用Faiss索引文档
Faiss包含的算法可以在任意大小的向量集合中搜索,甚至是那些无法放入RAM的向量。要了解更多关于Faiss的信息,你可以在arXiv阅读他们的论文。
Faiss是围绕索引对象构建的,索引对象包含可搜索向量,有时还对其进行预处理。它处理一个固定维数d的向量集合,通常是几个10到100。
Faiss只使用32位浮点矩阵。这意味着在构建索引之前,我们必须更改输入的数据类型。
在这里,我们将使用IndexFlatL2索引来执行暴力的L2距离搜索。它在我们的数据集上工作得很好,但是,对于大型数据集,它会非常慢,因为它会随着索引向量的数量线性扩展。Faiss也提供快速索引!
要用抽象向量创建索引,我们将:
将抽象向量的数据类型更改为float32。
建立一个索引,并传递它将要操作的向量的维数。
将索引传递给IndexIDMap,该对象使我们能够为索引的向量提供id的自定义列表。
将抽象向量及其ID映射添加到索引。在我们的例子中,我们将从Microsoft Academic Graph将向量映射到它们的论文id。
为了测试索引是否按预期工作,我们可以使用索引向量查询它,并检索其最相似的文档以及它们的距离。第一个结果应该是我们的查询!
# Step 1: Change data type
embeddings = np.array([embedding for embedding in embeddings]).astype("float32")
# Step 2: Instantiate the index
index = faiss.IndexFlatL2(embeddings.shape[1])
# Step 3: Pass the index to IndexIDMap
index = faiss.IndexIDMap(index)
# Step 4: Add vectors and their IDs
index.add_with_ids(embeddings, df.id.values)
# Retrieve the 10 nearest neighbours
D, I = index.search(np.array([embeddings[5415]]), k=10)
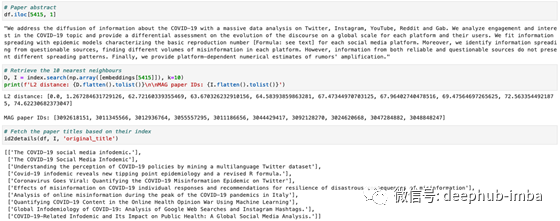
由于我们使用索引向量查询Faiss,因此第一个结果必须是查询,并且距离必须等于零!
搜索用户输入的查询
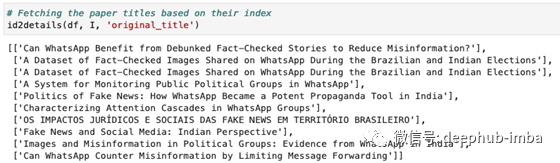
让我们尝试为新搜索查询找到相关的学术文章。在此示例中,我将使用WhatsApp的第一段查询索引,这可以从揭穿事实核查的故事中受益,以减少错误信息?

要检索学术文章以进行新的查询,我们必须:
- 使用与抽象向量相同的句子DistilBERT模型对查询进行编码。
- 将其数据类型更改为float32
- 使用编码的查询搜索索引
为了方便起见,我将这些步骤包装在vector_search()函数中。
import numpy as np
def vector_search(query, model, index, num_results=10):
"""Tranforms query to vector using a pretrained, sentence-level
DistilBERT model and finds similar vectors using FAISS.
Args:
query (str): User query that should be more than a sentence long.
model (sentence_transformers.SentenceTransformer.SentenceTransformer)
index (`numpy.ndarray`): FAISS index that needs to be deserialized.
num_results (int): Number of results to return.
Returns:
D (:obj:`numpy.array` of `float`): Distance between results and query.
I (:obj:`numpy.array` of `int`): Paper ID of the results.
"""
vector = model.encode(list(query))
D, I = index.search(np.array(vector).astype("float32"), k=num_results)
return D, I
def id2details(df, I, column):
"""Returns the paper titles based on the paper index."""
return [list(df[df.id == idx][column]) for idx in I[0]]
# Querying the index
D, I = vector_search([user_query], model, index, num_results=10)
我们输入的文字讨论了错误信息,事实检查,WhatsApp和巴西和印度的选举。我们希望基于矢量的搜索引擎返回有关这些主题的结果。通过检查论文标题,大多数结果看起来与我们的查询非常相关。我们的搜索引擎可以正常工作!
结论
在本教程中,我们使用Sentence Transformers和Faiss构建了一个基于矢量的搜索引擎。我们的索引效果很好,并且相当简单。我们可以使用像SciBERT这样的领域特定的转换器来提高嵌入的质量,该转换器已在语义库的语料库上的论文中进行了预训练。我们还可以在返回结果之前删除重复项并尝试其他索引。
对于使用Elasticsearch的人员,Open Distro引入了近似的k-NN相似性搜索功能,该功能也是AWS Elasticsearch服务的一部分。
最后,您可以在GitHub上找到代码(https://github.com/kstathou/vector_engine),并通过Google Colab进行尝试(https://colab.research.google.com/github/kstathou/vector_engine/blob/master/notebooks/001_vector_search.ipynb)。
作者:Kostas Stathoulopoulos
deephub翻译组