
概述
kafka是由scala语言编写的一个分布式且具备高可用、高性能、可持久化、可水平扩展、支持流数据处理等众多特性的消息系统,常活跃于大数据生态中,而且大名鼎鼎的rocketmq就是参考了kafka的设计原理。
目前越来越多的开源分布式中间件都支持与kafka集成(elk、spark、storm、canal......)。接下来咱们就深入看下为何它如此受青睐。
架构设计
kafka它由这几个部分组成:若干个producer、若干个consumer、若干个broker、zookeeper集群。
producer负责发送消息,broker负责将消息持久化和将消息推送给消费者,consumer负责消费消息其架构图如下:
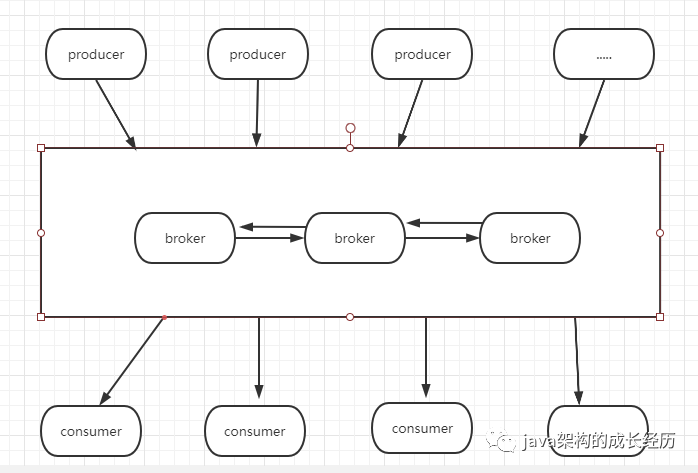
broker没有绝对的主从之分,它是根据topic的分区来区分的主从概念。默认分区是1个副本可以在创建topic的时候通过replication-factor参数去指定副本数量,理论上副本数量越多安全度越高,当然也要结合broker的节点数量,比如就三个broker节点,副本设置2个其实安全度是最好的。
副本越多一定越好吗?因为副本越多的话会增加broker的压力和写入的tps。特别是当ack参数为-1的时候。
高可用、高性能原理
高可用这个体现在上面说的分区之间的副本概念,当一个分区中的主分区所在的broker挂掉以后,此时通过zookeeper进行选举操作,将其副本中某一个升级为主分区,这样就可以继续写入了。
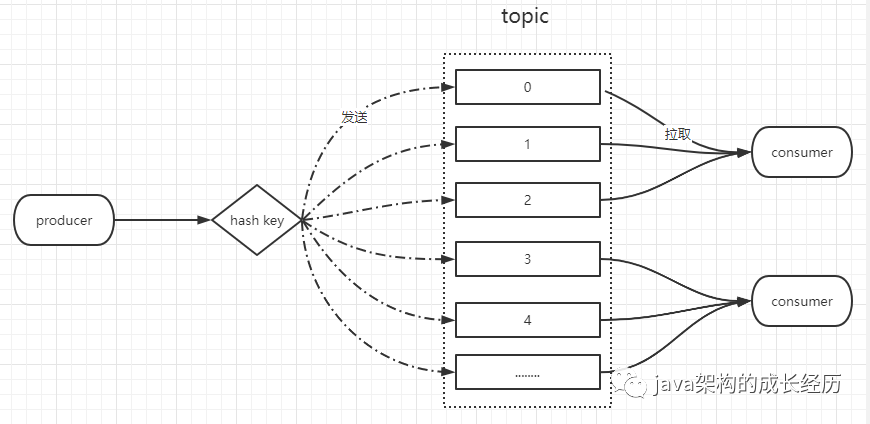
那高性能怎么体现呢:从2个角度看第一生产角度broker采用的是顺序写盘再加上 topic设置多分区每个分区的文件是各自落档的,所以最大程度的发挥磁盘性能。
消费角度 可以并发的从不同的分区中拉取消息,其次可以通过增加分区的副本主要在isr列表内的副本都可以为消费提供消息,并且消费者可以横向扩展,只要数量小于分区数就可以保证每个消费者都可以消费到消息,这行消费性能得到成倍的提升。
并且可以通过指定key将相同用户或者模数相同的数据发送到同一个分区中,做到分区内有序,架构图如下:
什么是ISR列表
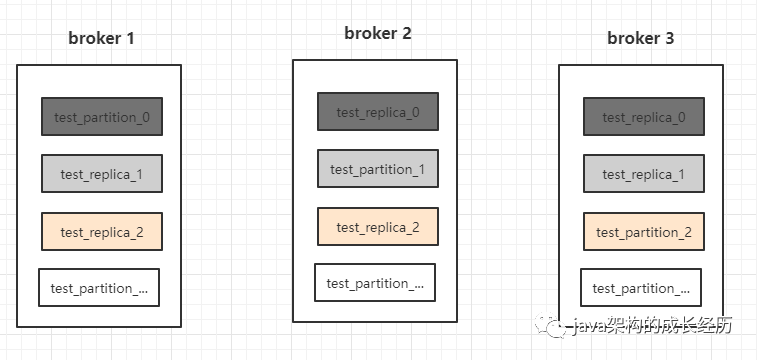
ISR全称:In-Sync Replicas 是一个副本的集合,比如我们创建一个topic :test 分区数为9,replication-factor 副本为3,如果在理想状态下,所有副本的数据都跟上主分区,那此时topic test的ISR中应该是有3个replication-factor ,但是随着业务量上涨,各节点承载的性能越来越大,高峰期写入tps陡增时就会出现副本同步不及时的问题。
默认当副本延迟10秒以后就会将其踢出ISR列表中,可以通过参数 replica.lag.time.max.ms设置,架构图如下:
我们不难得出结论这个列表是一直动态伸缩的,当部分节点数据差异很大的时候就会被踢出,当数据同步跟上主分区后又被重新加入到列表内,那它有什么影响呢?
当我们生产者端的ack参数设置为all或者-1的时候此时写请求会等到ISR列表内所有节点都响应后才会给客户端响应成功,这样可以确保消息在生产阶段不丢失。
这样一来的话就大大降低了生产者写入的tps,如果列表内小于min.insync.replicas的值此时topic就禁止写入了。
ISR总结
Kafka Broker在处理消息写入时需更新HW,此时需要申请leaderIsrUpdateLock的读锁,消费者在拉取消息时也需要申请leaderIsrUpdateLock的读锁,这是互补影响的,但是ISR列表在伸缩的同时,主分区需要维护ISR中的HW那么此时就需要申请leaderIsrUpdateLock的写锁,此时会与消息发送、消费客户端消费消息、分区副本消息复制发送锁竞争,并发度急剧下降,这样TPS急剧下降。
可以通过增大replica.lag.time.max.ms的值来解决此问题,或者增大参数num.replica.fetchers该值默认1,即将replication-factor复制线程数量调大,进而加快同步性能,降低ISR的伸缩频率。

版权归原作者 Lv_Jin_Gang 所有, 如有侵权,请联系我们删除。