
问题:编写爬虫时,使用selenium碰到一个问题,不使用代理ip时是可以打开网站的,但是使用代理ip时会打不开网站,网站会显示“无法访问该网站”。但是用requests库则可以爬取到内容
原因:我从网上免费爬取到的http代理不支持访问https协议。
让代理服务器支持HTTPS很难吗?_鲲鹏Web数据抓取 - 专业Web数据采集服务提供商
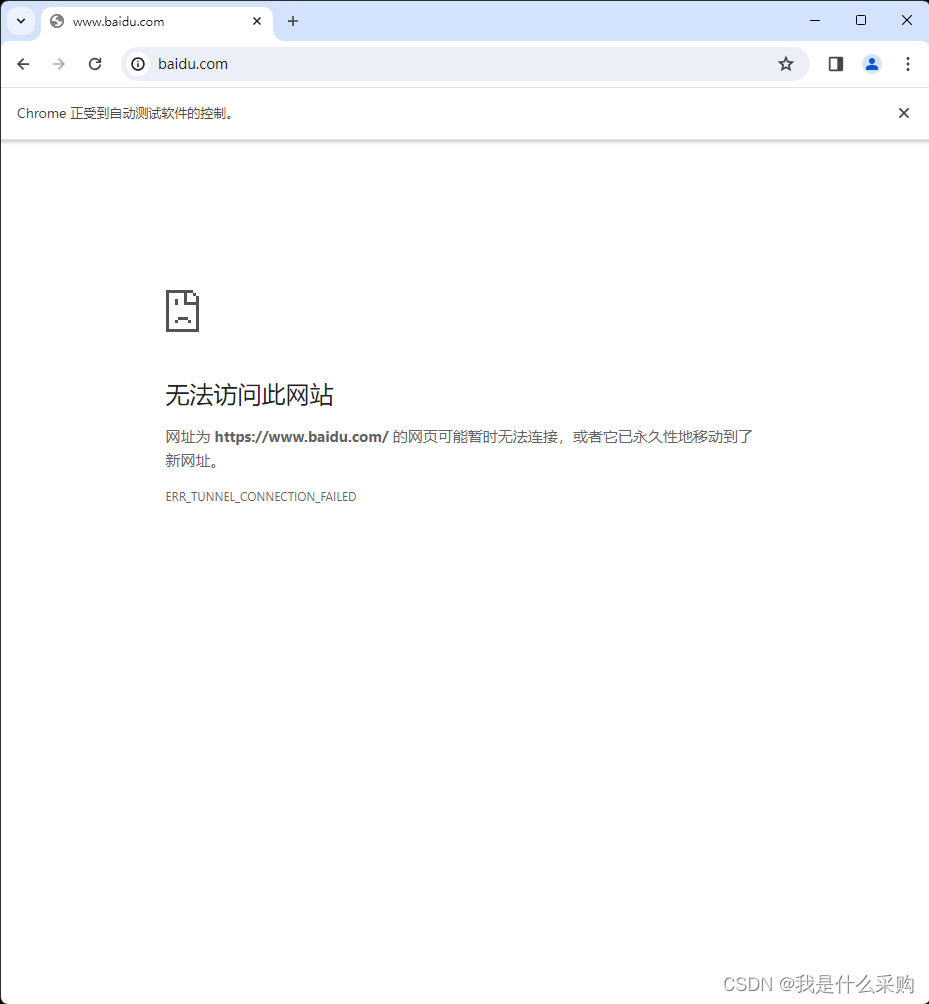
附上代码:
from selenium import webdriver
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument('--proxy-server=http://117.160.250.138:8899')
# chromeOptions.add_experimental_option(
# "excludeSwitches", ["enable-automation"])
# chromeOptions.add_experimental_option('useAutomationExtension', False)
# chromeOptions.add_argument('lang=zh-CN,zh,zh-TW,en-US,en')
chromeOptions.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36')
# preferences = {
# "webrtc.ip_handling_policy": "disable_non_proxied_udp",
# "webrtc.multiple_routes_enabled": False,
# "webrtc.nonproxied_udp_enabled": False
# }
# chromeOptions.add_experimental_option("prefs", preferences)
driver=webdriver.Chrome(chrome_options=chromeOptions)
driver.get('http://www.baidu.com')
为了确认是否ip失效,我使用了requests库进行爬取
header={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'}
res=requests.get('https://blog.csdn.net/zise_xingkong/article/details/112350327',proxies={"http":"http://221.6.139.190:9002"},headers=header)
print(res.url)
print(res.text)
结果是可以拿到内容,我同样尝试过使用httpbin.org/ip进行ip查询,确认是否采用了代理ip
import time
import random
from selenium import webdriver
class SetProxyModel():
test_url = "http://httpbin.org/ip"
with open('E:\project\自用ip代理\pythonProject\可用代理IP.txt') as file:
ips = file.readlines()
max_len = len(ips)-1
def __init__(self):
self.options = webdriver.ChromeOptions()
self.options.add_argument(
'user-agent=”Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36“')
# 设置代理
self.ip = self.ips[random.randint(0, self.max_len)]
print(self.ip)
self.options.add_argument('--proxy-server=' + self.ip)
self.driver = webdriver.Chrome(chrome_options=self.options)
self.driver.maximize_window()
def set_proxy(self):
self.driver.get(self.test_url)
time.sleep(random.randint(2, 5))
print(self.driver.page_source)
cookies = self.driver.get_cookies()
print(cookies)
def close(self):
time.sleep(5)
self.driver.close()
if __name__ == '__main__':
sp = SetProxyModel()
sp.set_proxy()
time.sleep(random.randint(3, 5))
sp.close()
确认了是采用了代理ip。
因此,目前暂时不清楚问题出在什么地方,有没有大佬支支招。
本文转载自: https://blog.csdn.net/qq_67560490/article/details/137472503
版权归原作者 我是什么采购 所有, 如有侵权,请联系我们删除。
版权归原作者 我是什么采购 所有, 如有侵权,请联系我们删除。