
一个在具有间隙和非平稳性的真实数据上使用FEDOT和其他AutoML库的示例
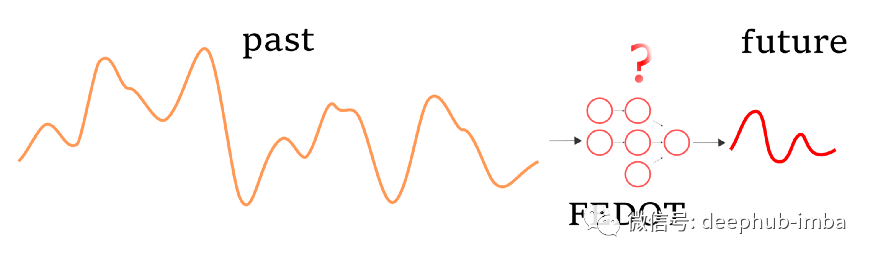
大多数现代开源AutoML框架并没有广泛地涵盖时间序列预测任务。本文中我们将深入地研究AutoML框架之一FEDOT,它可以自动化时间序列预测的机器学习管道设计。因此,我们将通过时间序列预测的现实世界任务详细解释FEDOT的核心正在发生什么。
FEDOT框架和时间序列预测
之前我们讨论过机器学习问题的管道。流水线是一个无环有向图。在FEDOT术语中,此图称为链,或组合模型,或管道。
FEDOT操作的基本抽象是:
操作是对数据执行的操作:它可以是对数据进行预处理(标准化、标准化、填补空白)的操作,也可以是给出预测的机器学习模型;
节点是放置操作的容器。一个节点中只能有一个操作。主节点只接受原始数据,而次要节点使用来自前一级节点的输出作为预测器;
链或管道是由节点组成的无循环有向图。FEDOT中的机器学习管道是通过Chain类实现的。
给定的抽象如下图所示:

机器学习模型和经典模型,如时间序列的自回归(AR),都可以插入到这样的管道的结构中。
我们知道如何解决分类或回归问题。我们甚至知道如何在FEDOT中制作一个模型的管道。但是我们如何进行时间序列预测呢?我们如何使用决策树呢?特色在哪里?
功能就在这里!要构建具有特性的表,您只需要使用滑动窗口遍历时间序列并准备一个轨迹矩阵。
值得指出的是,这不是我们的发明:您可以阅读使用这种转换的SSA方法。几乎所有用于时间序列的机器学习模型的应用都是构建这样的矩阵。
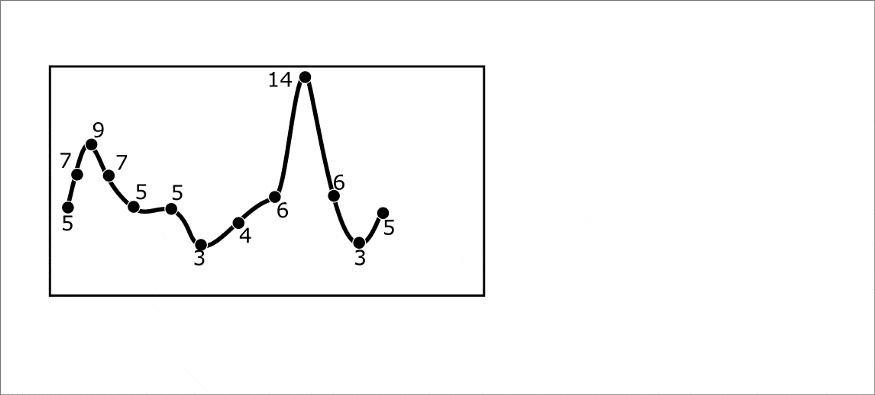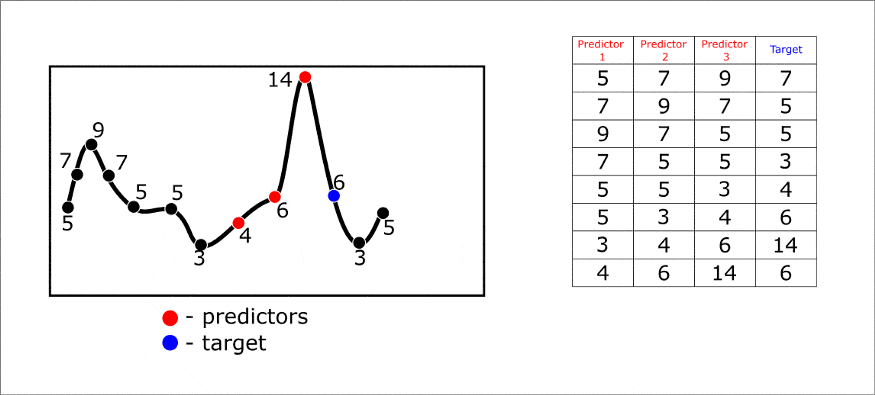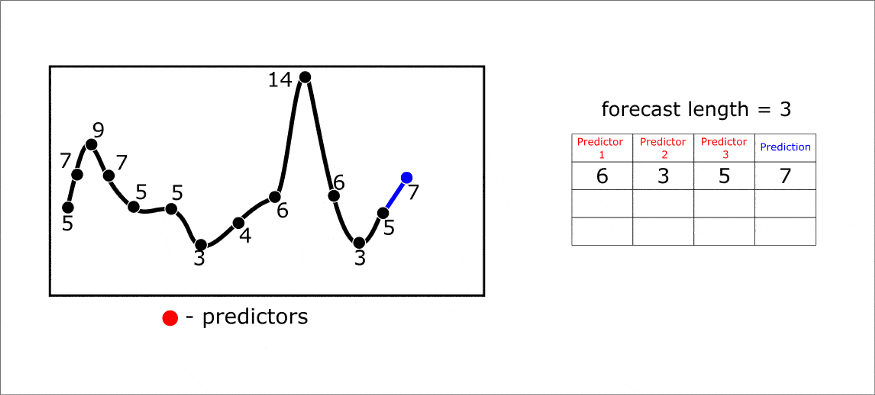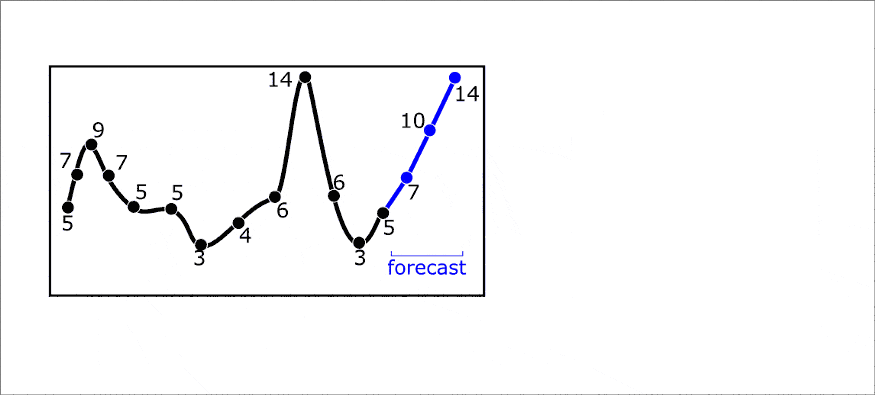
让我们更详细地分析这个级数变换的方法。时间序列是一系列的值,后续的值通常依赖于前一个值。因此,我们可以利用时间序列的当前和之前的元素来进行预测。让我们假设我们想要提前预测一个元素的序列,使用当前值和之前值:
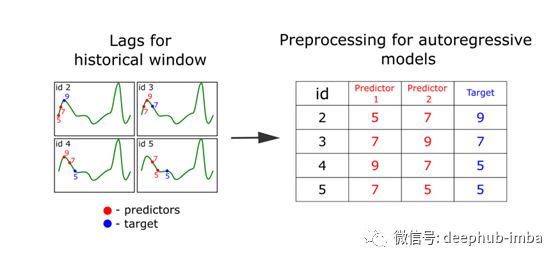
我们称这种变换为时间序列的“滞后变换”。在FEDOT中,我们把它放在一个单独的“滞后”操作中。重要的超参数是滑动窗口的大小,它决定了我们将使用多少先前的值作为预测器。
下面是一个多步预测一个元素的例子动画。然而,一步预测可以同时对多个元素进行预测。这样就解决了多目标回归问题。你可以看到从形成轨迹矩阵(或滞后表)到做出预测的整个预测过程:
任何机器学习模型都可以用作预测模型。但我们也在FEDOT中实现了几个特定的时间序列预测模型(如AR和ARIMA)。此外,还加入了特定于时间序列的预处理方法,如移动平均平滑或高斯平滑。
这里还没有自动机器学习。当它的智能部分 composer 启动时,该框架“活跃起来”。Composer 是制作管道的接口。在其中,它使用了一种优化方法,该方法实现了 AutoML 的“自动”部分。默认情况下,该框架使用基于遗传编程原理的进化方法。但是,如有必要,可以将任何搜索算法添加到 Composer,从随机搜索到贝叶斯优化。
AutoML的工作分为两个阶段:
组合是找到管道结构的过程。缺省情况下,使用进化算法。在这一阶段,节点中的操作被更改,子树从一些解决方案中删除,并“增长”到其他解决方案。节点操作的超参数也在这里发生突变;超参数调优是管道结构不变,但节点中的超参数在变化的过程。这个阶段在创作完成后开始。
下面是在组合阶段在管道上执行的突变转换的示例:

在进化过程中,选择最准确的模型。所以,在组合结束时会有一个固定结构的管道,我们只需要在节点中配置超参数。
使用 hyperopt 库中的优化方法,在管道的所有节点中同时调整超参数:
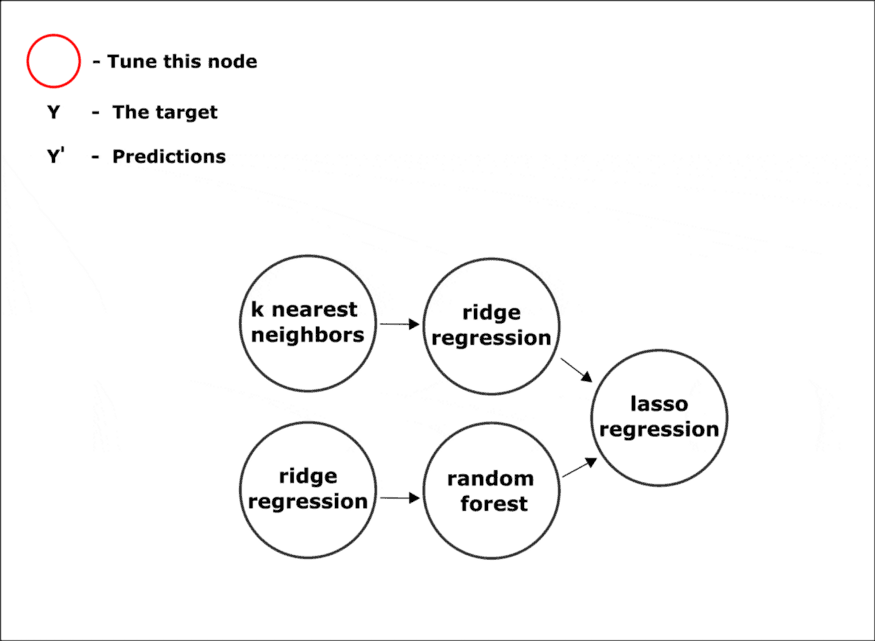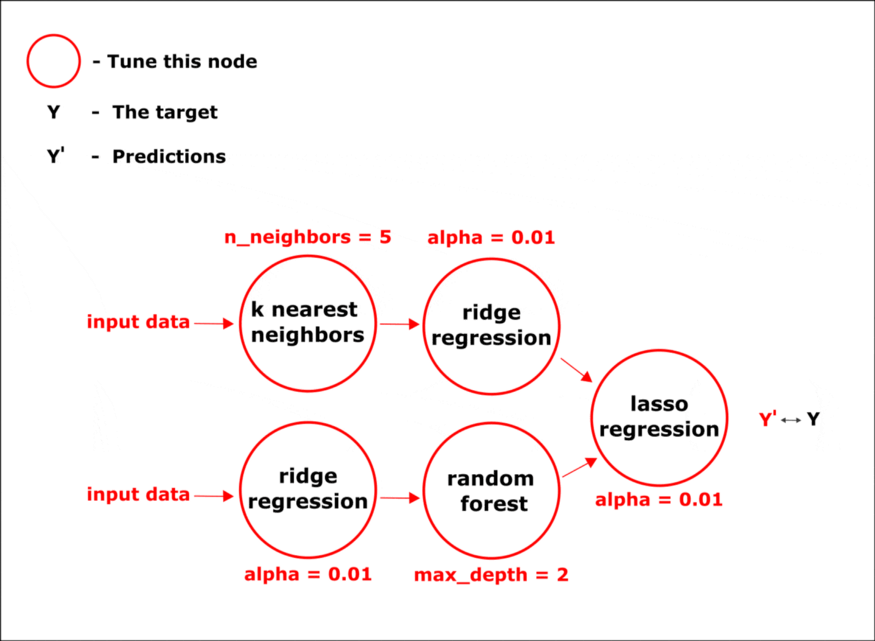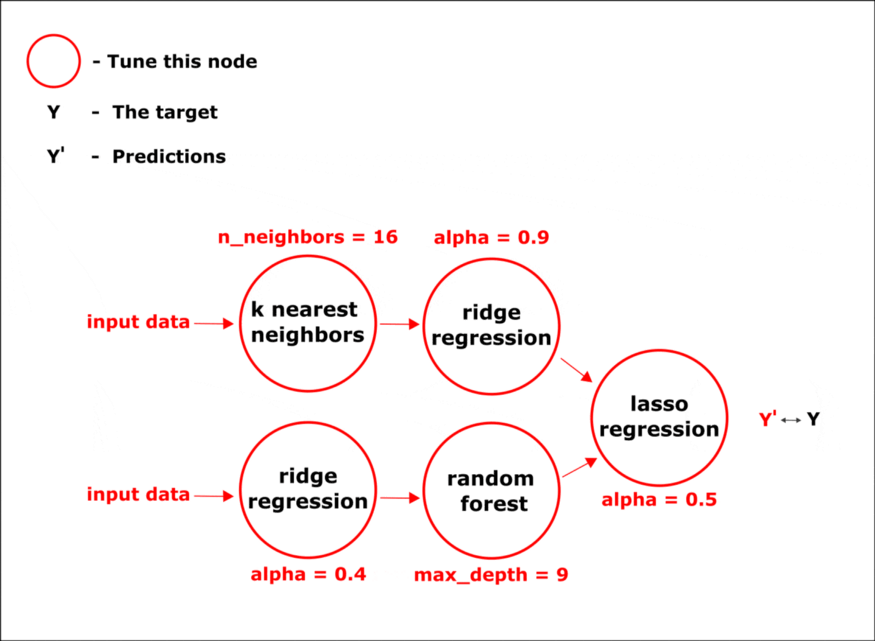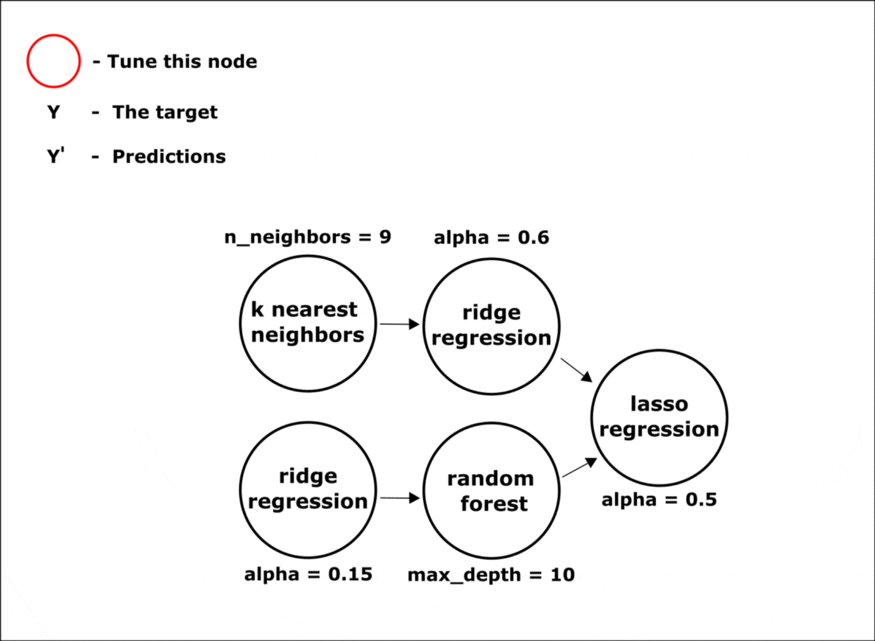
完成所有阶段后,我们将获得最终的管道。
现在让我们开始正式的例子
在机器学习(非科学)文章中,广泛使用相对简单的时间序列来证明算法的有效性。最受欢迎的一个是“US airline passengers”,下面是例子,它显示了它的样子:
展示该库对此类时间序列的能力让人看起来是非常强大的,但是其实大多数稍微复杂的模型将能够提供足够的预测。所以我们决定从现实世界中获取一个数据集——以显示AutoML算法的所有功能。我们希望,这个例子对于演示来说足够好了。。
有两个时间序列:第一个是风电场的平均日发电量。第二个是柴油发电机的平均日发电量。这两个参数都是以千瓦时为单位测量的。
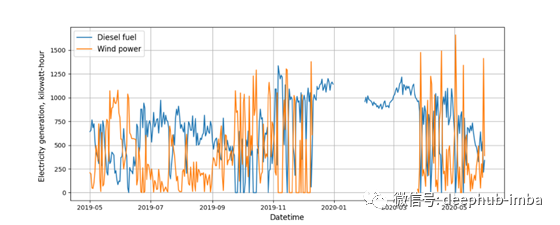
风力发电机的发电高度依赖风速。如果风速降低,柴油发电机就会启动以维持足够的发电水平。因此,当风力涡轮机的输出功率下降时,柴油发电机的输出功率会上升,反之亦然。同样值得注意的是,时间序列有间隙。
编程代码将不会在这篇文章下面列出。然而,为了更好的感知,我们已经准备了大量的可视化。完整版本的编程代码,其中所有的技术方面都有更详细的描述,可以在jupiter笔记本中找到。
任务
任务是建立柴油发电提前14天预测的模型。
间隙缺口
出现的第一个问题是原始时间序列中存在缺口。在FEDOT时间序列间隙填充中,有三组方法可用:
- 线性插值等简单方法;
- 基于单时间序列预测模型的迭代预测方法
- 填补空白的先进预测方案。
第一组方法工作速度快,但精度低。第二组的方法不考虑问题的细节,相当于简单地预测一个时间序列。最后一组方法考虑了前一种方法的缺点。所以我们将进一步应用第三组的方法。复合模型使用双向时间序列预测来填补空白。

为了填补时间序列的空白,我们创建了一个简单的高斯平滑、滞后变换和ridge 回归的管道。然后我们训练这条管道,以便对“未来”做出预测。
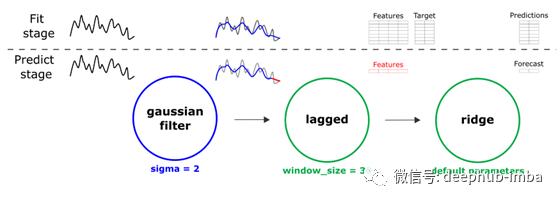
然后在相反的方向重复这个动作——训练管道来预测“过去”。然后,我们可以结合两个预测,使用平均。
这种方法中的操作顺序可以描述如下。首先,使用时间序列中位于间隙左侧的部分。该部分训练了一个复合模型,以预测前面存在缺口的元素数量。然后,对正确的部分重复上述步骤。为了做到这一点,需要对时间序列的已知部分进行反演,训练模型,进行预测,并对得到的预测进行反演。综合预测采用加权平均法进行。因此,值越接近预测时间序列中已知部分的向量权重越大。也就是说,当平均时,红色的预测(图中)将在通道的左边部分有更多的权重,而绿色的在右边部分有更多的权重。
应用gap-filling算法后,得到如下结果:

很不错,不是吗?但是第二个时间序列的中心部分仍然有一个缺口。我们也可以应用前面的方法来解决这个问题,但是还有另一种方法。我们采用成对回归法对两个时间序列的值进行匹配,并以柴油发电机作为单个预测器恢复风力发电机发电量(目标)的值。我们还将使用FEDOT框架解决这个回归问题。
经过所有这些填补空白的程序,我们得到以下结果:
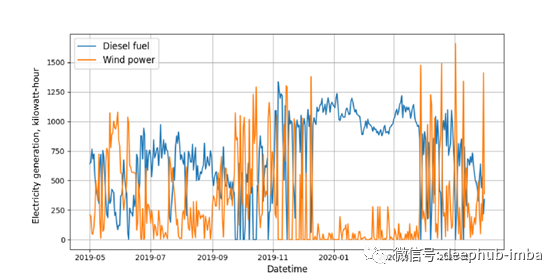
现在这两个时间序列都没有间隙,可以进一步使用。
预测
让我们使用上面描述的所有FEDOT特性,并在我们的数据上运行AutoML算法。我们已经推出了FEDOT与默认配置的时间序列预测,只使用适合和预测方法从API。现在让我们看看结果预测并计算指标:平均绝对误差(MAE)和平均平方误差(RMSE)的根:MAE - 100.52,和RMSE - 120.42。
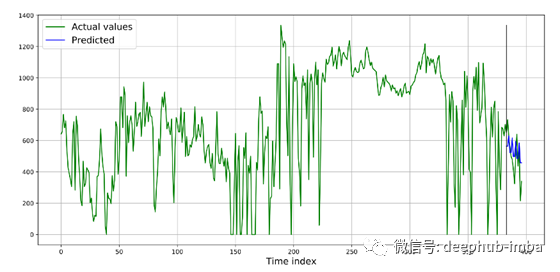
如果我们观察图表和指标的值,问题就出现了:这个模型是好的还是不好的?
回答:很难算出来。最好不要在一个小样本上验证模型——那里只有14个值。最好至少计算几次度量。例如,3乘以14(也就是42)。要做到这一点,你应该使用样本内预测。
先进的验证
下面是一个动画,可以帮助你理解样本外和样本内预测的区别:

因此,我们的模型可以提前预测14个值。但是我们想提前得到28个值的预测——在本例中,我们可以迭代两次对14个元素进行预测。在这种情况下,第一次迭代(样本外)中预测的值将作为第二次预测的预测器。
如果我们想要验证模型,我们将使用样本内预测。使用这种方法,我们可以预测时间序列中已知的部分(测试样本)。但是,在迭代预测中,使用已知的值来形成下一步的预测器,而不是前一步的预测值。
在FEDOT中,也实现了这种方法-所以现在我们将在三个块上测试算法,每个块有14个值。为此,我们将分割示例并再次运行编写器。预测结果如下图所示。重要的是要澄清,进化算法是随机的,因此来自AutoML模型的输出可能不同。
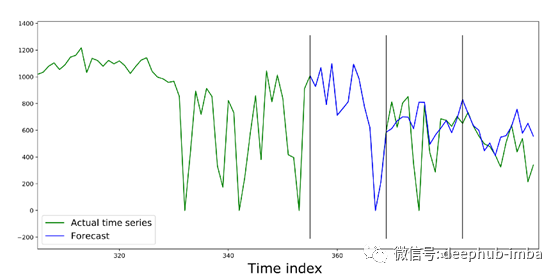
在第一个验证块上的预测完全重复了时间序列的实际值。这似乎很奇怪,但当我们看到获得的管道结构时,一切都变得清晰起来。
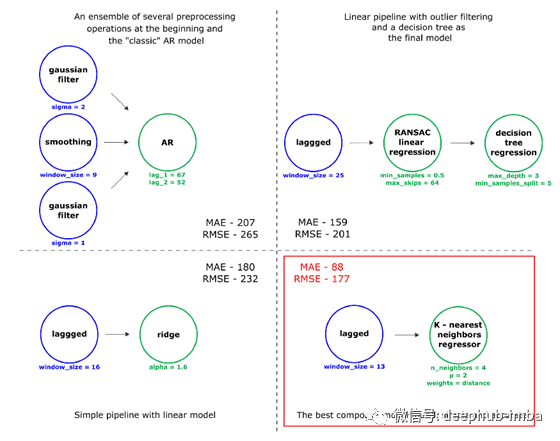
从图中可以看出,更复杂的管道并不总是提供最低的错误度量。因此,发现的最佳管道是短的,但是验证的错误值很小。在此基础上,我们得出结论,这对这个时间序列是足够的。
由于最后的模型是k -最近邻算法,管道能够很好地重复训练样本中的时间序列模式。这种模型可能会出现问题,例如,根据趋势,时间序列不是平稳的。在这种情况下,k -最近邻模型将无法从训练样本中充分推断相关性。这个时间序列还有一个特征——它在方差上是非平稳的。
然而,它的结构包含相对同构的部分,与执行验证的时间序列的部分没有太大的区别。
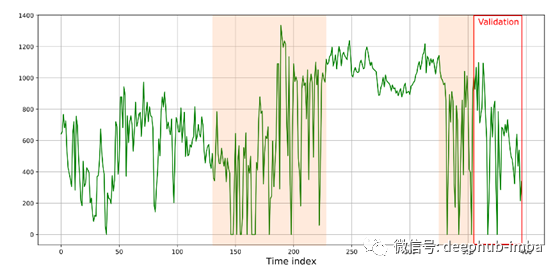
在这些部分,存在重复的模式,时间序列是趋势平稳的-值在平均值附近波动,然后上升到1000 kWh以上的值,然后下降到0。因此,为所构建的管道重现这些模式的能力非常重要。但没有必要去猜测时间序列的低频波动(例如趋势或季节性)。KNN模型适用于这些任务。链组成后的预测质量指标MAE - 88.19, RMSE - 177.31。
值得注意的是,我们已经准备了一个自动模式的解决方案,并没有向搜索算法添加任何额外的专家知识。这个任务只需在笔记本电脑上运行框架5分钟就可以解决。毫无疑问,对于大数据集,构建一个好的管道需要更多的时间。
与其他框架比较
免责声明:本节中的比较远非详尽无遗。为了证明一个框架比另一个更好或更差,您需要进行更多的实验。建议使用多个数据源,应用交叉验证,多次使用相同的参数在相同的数据上运行算法(使用指标的平均值)。这里我们有一个介绍性的比较:我们展示了替代解决方案如何处理任务。
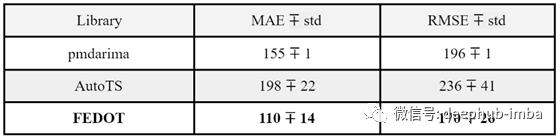
让我们试着将FEDOT与其他时间序列预测的开源框架AutoTS和pmdarima进行比较。代码在后面给出。因为不是所有库都在多个块上实现验证功能,所以我们决定只对时间序列的一个片段进行这个小的比较。每个算法运行3次,并取误差度量的平均值。带有度量的表是这样的(单元格显示std - standard deviation):
图中还显示了对其中一个实验的预测:
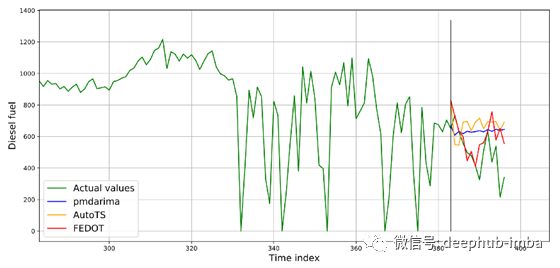
从图中可以看出,用FEDOT得到的预测更“接近实际数据”。
总结
所以,今天我们关注的是AutoML这个越来越受欢迎的机器学习领域。在这篇文章中,我们回顾了现有的ML管道自动生成的解决方案,并找出如何将它们用于时间序列预测任务。
我们还尝试了AutoML在FEDOT框架下预测发电量序列的例子:我们恢复了缺失的值,使用进化算法建立了一个管道,并验证了解决方案。最后,将FEDOT与其他框架进行了简单的比较。
本文作者:Mikhail Sarafanov
本文代码:https://github.com/ITMO-NSS-team/fedot_electro_ts_case/tree/main/case
框架对比代码:https://github.com/ITMO-NSS-team/fedot_electro_ts_case/blob/main/case/ts_case_others.ipynb