
1.测试优先编程
在我们深入研究之前,我们需要定义一些术语:
- 模块是软件系统的一部分,可以独立于系统的其余部分进行设计,实现,测试和推理。在本阅读中,我们将重点介绍由 Java 方法表示的函数模块。在以后的阅读中,我们将拓宽视野,考虑更大的模块,比如具有多个交互方法的类。
- 规范(或规范)描述模块的行为。对于函数,规范给出了参数的类型和它们的任何其他约束(例如,的参数必须是非负的)。它还给出了返回值的类型以及返回值与输入的关系。在 Java 代码中,规范由方法签名和其上方描述其功能的注释组成。
sqrt - 模块具有提供其行为的实现,以及使用该模块的客户端。对于函数,实现是方法的主体,客户端是调用该方法的其他代码。模块的规范同时约束客户端和实现。从现在开始,我们将对规范、实现和客户端进行更多介绍。
- 测试用例是输入的特定选择,以及规范所需的预期输出。
- 测试套件是模块的一组测试用例。
事实证明,从头开始设计程序时,这是一个很好的模式。在测试优先编程中,甚至在编写任何代码之前就编写了规范和测试。
单个函数的开发按以下顺序进行:
- 规范:为函数编写规范。
- 测试:编写执行规范的测试。
- 实现:编写实现。
一旦您的实现通过了您编写的测试,您就完成了。
测试优先编程的最大好处是避免错误。不要将测试留到开发结束时,那时您有一大堆未经验证的代码。将测试留到最后只会使调试更长,更痛苦,因为 Bug 可能存在于代码中的任何位置。在开发代码时测试代码要愉快得多。
2.系统测试
我们希望系统地进行测试,而不是详尽,随意或随机测试。系统测试意味着我们以原则性的方式选择测试用例,目标是设计一个具有三个理想属性的测试套件:
- 正确。正确的测试套件是规范的合法客户端,它接受规范的所有合法实现而不会有投诉。这使我们能够自由地更改模块在内部的实现方式,而不必更改测试套件。
- 彻底。一个完整的测试套件会发现实现中由程序员可能犯的错误引起的实际错误。
- 小。一个小型测试套件,只有很少的测试用例,首先可以更快地编写,并且如果规范不断发展,则更容易更新。小型测试套件的运行速度也更快。如果您的测试套件小而快速,您将能够更频繁地运行测试。
根据这些标准,详尽的测试是彻底的,但不可行。随意测试往往很小,但不彻底。随机测试只能以大尺寸为代价实现彻底性。
设计一个既彻底又小尺寸的测试套件需要有正确的态度。通常,当您编码时,您的目标是使程序正常工作。但作为测试套件设计人员,您希望让它失败。这是一个微妙但重要的区别。一个好的测试人员会故意戳到程序可能易受攻击的所有位置,以便消除这些漏洞。
采用测试态度的需求是测试优先编程的另一个论点。把你已经写的代码当作一个珍贵的东西,一个脆弱的蛋壳,然后非常轻描淡写地测试它,只是为了看看它是如何工作的,这太诱人了。但是,要进行彻底的测试,您必须保持残酷。测试优先编程允许您戴上测试帽子,并在编写任何代码之前采用这种残酷的观点。
3.通过分区选择测试用例
创建一个好的测试套件是一个具有挑战性和有趣的设计问题。我们希望选择一组足够小的测试用例,以便于编写和维护,并且运行速度快,但又足够彻底以查找程序中的错误。
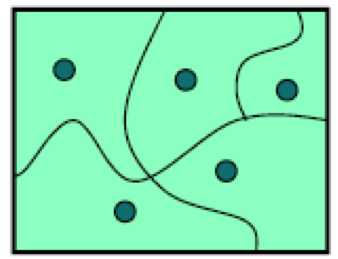
为此,我们将输入空间划分为子域,每个子域由一组输入组成。(名称子域来自这样一个事实,即它是域的子集,这是数学函数输入空间的另一个名称。总而言之,子域形成一个分区:完全覆盖输入空间的不相交集合,因此每个输入都位于一个子域中。然后,我们从每个子域中选择一个测试用例,这就是我们的测试套件。
子域背后的想法是将输入空间划分为程序具有相似行为的相似输入集。然后,我们使用每个集合的一个代表。此方法通过选择不同的测试用例并强制测试探索随机测试可能无法到达的输入空间区域,充分利用了有限的测试资源。
**例:
abs()
**
让我们从 Java 库中的一个简单示例开始:整数 abs() 函数,可在 Math 类中找到:
/** * ... * @param a the argument whose absolute value is to be determined * @return the absolute value of the argument. */publicstaticintabs(int a)
(这不是 的完整规范,因此我们稍后会回到这一点。但它将首先做。
abs
在数学上,此方法是以下类型的函数:
**
abs : int → int
**
该函数具有一维输入空间,由 的所有可能值组成。考虑绝对值函数的行为方式,我们可以从将输入空间划分为以下两个子域开始:
a
- a ≥ 0
- a < 0
在第一个子域上,应返回原封不动。在第二个子域上,应将其否定。
abs
a
abs
要为测试套件选择测试用例,我们从分区的每个子域中选择任意值,例如:
a
- a = 17 覆盖子域 a ≥ 0
- a = -3 覆盖子域 a < 0
**例:
max()
**
现在让我们看一下 Java 库中的另一个例子:整数 max() 函数,也可以在 Math 中找到。
/** * ... * @param a an argument * @param b another argument * @return the larger of a and b. */publicstaticintmax(int a, int b)
从数学上讲,此方法是两个参数的函数:
**
max : int × int → int
**
因此,我们有一个二维输入空间,由所有整数对(a,b)组成。现在让我们对它进行分区。从规范中,选择以下子域是有意义的:
- a < b
- a > b
因为规范要求每个规范具有不同的行为。但我们不能止步于此,因为这些子域还不是输入空间的分区。分区必须完全覆盖一组可能的输入。因此,我们需要添加:
- a = b
然后,我们的测试套件可能是:
- (a, b) = (1, 2) 覆盖一个< b
- (a, b) = (10, -8) 覆盖一个> b
- (a, b) = (9, 9) 以覆盖 a = b
4.在分区中包括边界
错误通常发生在子域之间的边界处。一些例子:
- 0 是正数和负数之间的边界
- 数值类型的最大值和最小值,如或
int``````double - 集合类型的空,如空字符串、空列表或空集
- 序列的第一个和最后一个元素,如字符串或列表
为什么 Bug 经常发生在边界上?一个原因是程序员经常犯一个接一个的错误,比如用写而不是,或者将计数器初始化为0而不是1。另一个是,某些边界可能需要在代码中作为特殊情况进行处理。另一个是边界可能是代码行为中不连续的地方。例如,当变量增长到超过其最大正值时,它会突然变成负数。
<=
<
int
事实证明,Java中的函数在其中一个边界上以非常出乎意料的方式运行,规范将其描述如下:
abs
/** * ... * Note that if the argument is equal to the value of Integer.MIN_VALUE, * the most negative representable int value, the result is that same value, * which is negative. * ... */
因此,可以返回负整数!这是二进制补码二进制表示的一个特征。理解它的一个简单方法是-2
abs
Integer.MIN_VALUE
31但为 2
Integer.MAX_VALUE
31-1,所以 的否定就在 .我们当然应该在测试中包括这些边界值。
Integer.MIN_VALUE
int
我们将边界作为单元素子域合并到分区中,以便测试套件必然包含边界值作为测试用例。对于 ,我们将为每个相关边界添加子域:
abs
- a = 0,因为正数和负数的行为不同
abs - a = ,最负的可能值,因为规范在那里调用了一些异常行为
Integer.MIN_VALUE``````int - a = ,最大正值,表示对称性和完整性
Integer.MAX_VALUE``````int
然后,我们原来的子域将缩小以排除边界值:
- a 为正数,即 0 < a <
Integer.MAX_VALUE - a 为负数,即 << 0
Integer.MIN_VALUE
这是现在输入空间的分区:五个子域是不相交的,完全覆盖了空间。
abs
然后,我们的测试套件可能是:
- a = 0
- o s
Integer.MIN_VALUE - o s
Integer.MAX_VALUE - a = 17 覆盖子域 0 <<
Integer.MAX_VALUE - a = -3 覆盖< 0 <子域
Integer.MIN_VALUE
**例:
BigInteger.multiply()
**
让我们看一个稍微复杂一点的例子。BigInteger 是 Java 库中内置的一个类,可以表示任何大小的整数,这与基元类型不同,并且只有有限的范围。BigInteger 有一个乘法方法,可以将两个 BigInteger 值相乘:
int
long
/** * @param val another BigInteger * @return a BigInteger whose value is (this * val). */public BigInteger multiply(BigInteger val)
例如,以下是它的使用方法:
BigInteger a = new BigInteger("9500000000"); // 9.5 billion
BigInteger b = new BigInteger("2");
BigInteger ab = a.multiply(b); // should be 19 billion
此示例显示,即使方法的声明中只显式显示一个参数,它实际上是两个参数的函数:要对其调用方法的对象(在上面的示例中)和在括号中传递的参数(在本示例中)。在 Python 中,接收方法调用的对象将被显式命名为方法声明中调用的参数。在 Java 中,您不会在参数中提及接收对象,而是调用它而不是 .
multiply
a
b
self
this
self
因此,我们应该将其视为一个函数,该函数采用两个输入,每个输入类型为 ,并产生一个类型的输出:
multiply
BigInteger
BigInteger
**
multiply : BigInteger × BigInteger → BigInteger
**
我们再次有一个二维输入空间,由所有整数对(a,b)组成。考虑符号规则如何与乘法一起工作,我们可以从这些子域开始:
- a 和 b 均为正数
- a 和 b 均为负数
- a 为正,b 为负
- a 为负,b 为正
还有一些乘法的边界值,我们应该检查:
- a 或 b 为 0,因为结果始终为 0
- a 或 b 为 1,乘法的恒等值
最后,作为一个试图发现错误的可疑测试人员,我们可能会怀疑BigInteger的实现者可能会尝试通过使用或在可能的情况下在内部使其更快,并且只有在值太大时才回退到昂贵的通用表示形式(如数字列表)。因此,我们应该确保尝试非常大的整数,大于最大的整数,大约为2
int
long
long
63,则为 19 位十进制整数。
- a 或 b 的大小较小或较大(即,小到足以用值表示,或者对于 a 而言太大)
让我们将所有这些观察结果整合到整个空间的单个分区中。我们将选择并独立于:
(a,b)
a
b
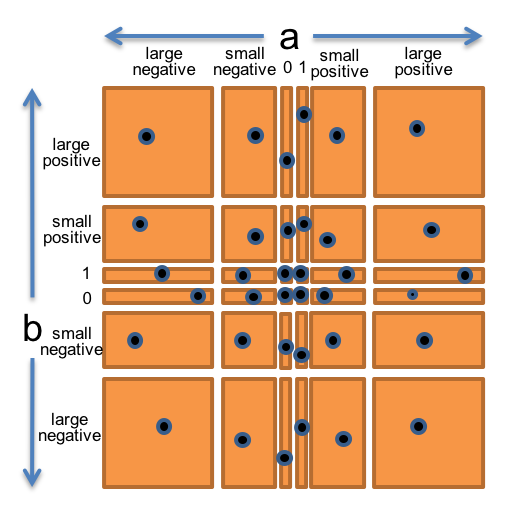
- 0
- 1
- 小正整数 (≤
Long.MAX_VALUE) - 小负整数 (≥
Long.MIN_VALUE) - 大正整数 (>
Long.MAX_VALUE) - 大负整数 (<
Long.MIN_VALUE)
因此,这将产生 6 个 × 6 = 36 个子域,这些子域对整数对的空间进行分区。
为了从这个分区生成测试套件,我们将从网格的每个正方形中选择一个任意对(a,b),例如:
- (a,b) = (0, 0) 以覆盖 (0, 0)
- (a,b) = (0, 1) 覆盖 (0, 1)
- (a,b) = (0, 8392) 覆盖 (0, 小正整数)
- (a,b) = (0, -7) 覆盖 (0, 小负整数)
- ...
- (a,b) = (-1060, -10810) 以覆盖(大负片、大负片)
右图显示了二维 (a,b) 空间如何被此分区划分,这些点是我们可以选择完全覆盖分区的测试用例。
5.使用多个分区
到目前为止,这些示例在整个输入空间中仅使用了一个分区(一个不相交子域的集合)。对于具有多个参数的函数,这可能会变得昂贵。每个参数可能具有有趣的行为变化和多个边界值,因此从每个参数上的行为的笛卡尔积形成输入空间的单个分区会导致生成的测试套件大小的组合爆炸。我们已经在 中看到了这一点,其中笛卡尔积分区已经有 6 个× 6 = 36 个子域,需要覆盖 36 个测试用例。对于具有 n 个参数的函数,笛卡尔积方法生成一个大小为 n 的指数级测试套件,这对于手动测试创作来说很快就变得不可行。
另一种方法是将每个输入的特征视为输入空间的两个独立分区。一个分区只考虑 以下值:
a
b
a
- (a,b) 使得 a = 0、1、小正、小负、大正、大负
而另一个分区只考虑以下值:
b
- (a,b) 使得 b = 0、1、小正、小负、大正、大负
右边说明了这两个分区。每个输入对只属于每个分区中的一个子域。
(a,b)
我们仍然希望用一个测试用例覆盖每个子域,但现在单个测试用例可以覆盖来自不同分区的多个子域,从而使测试套件更加高效。我们只需 6 个测试用例即可完全覆盖这两个分区,如右图所示。
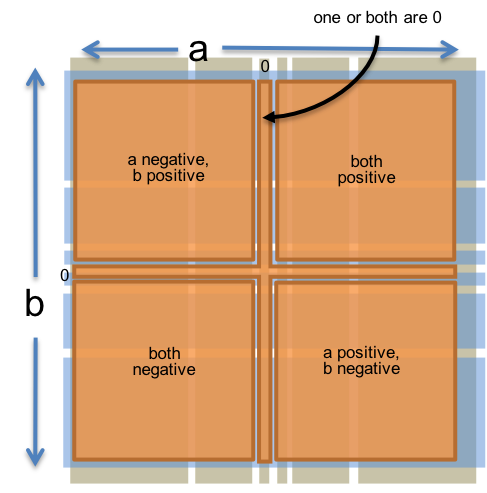
分区和独立地增加了您不再测试它们之间的交互的风险。例如,乘法中的符号处理是 bug 的可能来源,结果的符号取决于 和 的符号。但是我们可以添加一个额外的分区来捕获这种交互:
a
b
a
b
- a 和 b 都是正数;均为阴性;a 为正,b 为负;a 为负,b 为正;一个或两个均为 0
现在我们有三个分区,每个分区有 6、6 和 5 个子域,但我们不需要 6 个× 6 个× 5 个测试用例的笛卡尔积来覆盖它们。具有 6 个精心挑选的测试用例的测试套件可以覆盖所有三个分区的子域。
我们可以继续以这种方式添加分区,因为我们更多地考虑规范并观察可能导致错误的其他行为变化。通过仔细选择测试用例,其他分区应该只需要很少(如果有的话)额外的测试用例。
作为测试优先编程的起点,一个小型测试套件覆盖几个精心选择的分区的每个子域,在大小和彻底性之间取得了很好的平衡。然后,测试套件可能会随着玻璃盒测试,代码覆盖率测量和回归测试而进一步发展,我们将在本文后面看到。
6.使用 JUnit 进行自动化单元测试
经过良好测试的程序将对其包含的每个模块进行测试。如果可能,单独测试单个模块的测试称为单元测试。
JUnit 是一个被广泛采用的 Java 单元测试库,我们将在 6.031 中大量使用它。JUnit 单元测试编写为一个方法,前面是注释 。单元测试方法通常包含对正在测试的模块的一个或多个调用,然后使用 、、 和 等断言方法检查结果。
@Test
assertEquals
assertTrue
assertFalse
例如,我们为上面选择的测试在为 JUnit 实现时可能如下所示:
max
publicclassMaxTest {
...
@TestpublicvoidtestALessThanB() {
assertEquals(2, Math.max(1, 2));
}
@TestpublicvoidtestBothEqual() {
assertEquals(9, Math.max(9, 9));
}
@TestpublicvoidtestAGreaterThanB() {
assertEquals(10, Math.max(10, -9));
}
}
请注意,参数的顺序很重要。第一个参数应该是测试想要看到的预期结果,通常是一个常量。第二个参数是实际结果,代码实际执行的操作。如果切换它们,则 JUnit 将在测试失败时生成令人困惑的错误消息。JUnit 支持的所有断言始终遵循以下顺序:预期第一,实际第二。断言还可以将可选的消息字符串作为最后一个参数,您可以使用该参数使测试失败更清晰。
assertEquals
如果测试方法中的断言失败,则该测试方法将立即返回,JUnit 将记录该测试的失败。测试类可以包含任意数量的方法,这些方法在使用 JUnit 运行测试类时独立运行。即使一种测试方法失败,其他测试方法仍将运行。
@Test
7.记录您的测试策略
最好记下用于创建测试套件的测试策略:分区、它们的子域以及每个测试用例选择涵盖的子域。写下策略会使测试套件的彻底性对读者更加明显。
在 JUnit 测试类顶部的注释中记录分区和子域。例如,为了记录我们的测试策略,我们将写在:
max
MaxTest.java
publicclassMaxTest {
/* * Testing strategy * * Partitions max(a,b) as follows: * a < b, a > b, a = b */
每个测试用例上方都应该有一个注释,说明它覆盖了哪些子域,例如:
// covers a < b@TestpublicvoidtestALessThanB() {
assertEquals(2, Math.max(1, 2));
}
大多数测试套件将具有多个分区,并且大多数测试用例将涵盖多个子域。例如,下面是 的策略,其中我们将其分解为比上面更多的分区:
multiply
publicclassMultiply {
/* * Testing strategy * * Partitions a.multiply(b) as follows: * a is positive, negative, or 0 * b is positive, negative, or 0 * a = 1 or != 1 * b = 1 or != 1 * a fits in a long value or not * b fits in a long value or not * a and b are both positive; both negative; different signs; one or both are 0 */
请注意,此列表上的每个条目都是一个分区。如果我们只写并省略,它就不会覆盖输入空间。
a = 1
!= 1
然后,每个测试用例都有一个注释,用于标识它选择涵盖的子域,例如:
// covers a is positive,// b is negative, // a and b fit in long value,// a and b have different signs@TestpublicvoidtestDifferentSigns() {
assertEquals(new BigInteger("-146"), new BigInteger("73").multiply("-2"));
}
// covers a = 1,// b != 1,// a and b have same sign@TestpublicvoidtestIdentity() {
assertEquals(new BigInteger("33"), new BigInteger("1").multiply("33"));
}
8.黑匣子和玻璃盒测试
从上面回想一下,规范是对函数行为的描述 - 参数类型,返回值的类型以及它们之间的约束和关系。
黑盒测试意味着仅从规范中选择测试用例,而不是从函数的实现中选择测试用例。这就是我们到目前为止在示例中所做的。我们在 、 中进行了分区和查找边界,而没有查看这些函数的实际代码。事实上,遵循测试优先的编程方法,我们甚至还没有为这些函数编写代码。
abs
max
multiply
玻璃盒测试意味着在选择测试用例时了解功能的实际实现方式。例如,如果实现根据输入选择不同的算法,则应围绕选择不同算法的点进行分区。如果实现保留了一个内部缓存,该缓存记住了以前输入的答案,那么您应该测试重复的输入。
对于 的情况,当我们最终实现它时,我们可能已决定用值表示小整数,用十进制数字列表表示大整数。此决定引入了新的边界值,大概是在 和 处,并在它们周围引入一个新的分区。
BigInteger.multiply
int
Integer.MAX_VALUE
Integer.MIN_VALUE
在进行玻璃盒测试时,您必须注意测试用例不需要规范未明确要求的特定实现行为。例如,如果规范说“如果输入格式不正确,则引发异常”,那么您的测试不应该仅仅因为这是当前实现所做的而专门检查 a。在这种情况下,规范允许引发任何异常,因此您的测试用例同样应该是通用的,以便正确,并保持实现者的自由。我们将在规范类中对此进行更多说明。
NullPointerException
9.Coverage
判断测试套件的一种方法是询问它对程序的彻底程度。这个概念称为覆盖率。以下是三种常见的保险类型:
- 语句覆盖率:每个语句是否都由某个测试用例运行?
- 分支覆盖范围:对于程序中的每个或语句,某些测试用例是否都采用了真方向和假方向?
if``````while - 路径覆盖率:分支的每个可能组合(通过程序的每条路径)是否都被某个测试用例采用?
分支覆盖率比语句覆盖率强(需要更多的测试才能实现),路径覆盖率比分支覆盖率强。在工业中,100%的语句覆盖率是一个共同的目标,但由于无法访问的防御代码(如“永远不要到达这里”断言),即使这样也很少实现。100%的分支覆盖率是非常可取的,安全关键型行业代码具有更严格的标准(例如,MC / DC,修改的条件/决策覆盖率)。不幸的是,100%的路径覆盖率是不可行的,需要指数大小的测试套件才能实现。
标准的测试方法是添加测试,直到测试套件达到足够的语句覆盖率:即,程序中的每个可访问语句都由至少一个测试用例执行。在实践中,语句覆盖率通常由代码覆盖率工具来衡量,该工具计算测试套件运行每个语句的次数。使用这样的工具,玻璃盒测试很容易;您只需测量黑盒测试的覆盖率,并添加更多测试用例,直到所有重要语句都记录为已执行。
Eclipse的一个很好的代码覆盖率工具是EclEmma,如右图所示。在 EclEmma 中,测试套件已执行的行显示为绿色,尚未覆盖的行为红色。包含仅在一个方向上执行的分支的线 - 始终为真但从不为假,反之亦然 - 被着色为黄色。如果您在覆盖工具的右侧看到结果,则下一步是提出一个测试用例,使测试至少为真一次,并将其添加到测试套件中,以便黄线和红线变为绿色。
if
10.单元测试与集成测试和存根
到目前为止,我们一直在谈论单独测试单个模块的单元测试。单独测试模块可以简化调试。当模块的单元测试失败时,您可以更确信该 bug 是在该模块中发现的,而不是在程序中的任何位置。
与单元测试相反,集成测试测试测试模块的组合,甚至整个程序。如果您拥有的只是集成测试,那么当测试失败时,您必须寻找错误。它可能在程序中的任何位置。集成测试仍然很重要,因为程序可能会在模块之间的连接处失败。例如,一个模块可能期望的输入与它从另一个模块实际获得的输入不同。但是,如果你有一套全面的单元测试,让你对各个模块的正确性充满信心,那么你要做的搜索就会少得多。
假设您正在构建一个文档搜索引擎。您的两个模块可能是 ,它加载一个文件,以及 ,它将文档拆分为其组件词:
load()
extract()
/** @return the contents of the file */publicstatic String load(File file) { ... }
/** @return the words in string s, in the order they appear, * where a word is a contiguous sequence of * non-whitespace and non-punctuation characters */publicstatic List<String> extract(String s) { ... }
另一个模块可以使用这些方法来制作搜索引擎的索引:
index()
/** @return an index mapping a word to the set of files * containing that word, for all files in the input set */publicstatic Map<String, Set<File>> index(Set<File> files) {
...
for (File file : files) {
String doc = load(file);
List<String> words = extract(doc);
...
}
...
}
在我们的测试套件中,我们希望:
- 单元测试只是为了在各种文件上测试它
load - 单元测试只是为了在各种字符串上测试它
extract - 在各种文件集上测试它的单元测试
index
程序员有时会犯的一个错误是编写测试用例,使测试用例依赖于正确的方式。例如,测试用例可能用于加载文件,然后将其结果作为输入传递给 。但这不是 的单元测试。如果测试用例失败,则我们不知道失败是否是由于 或 中的 bug 引起的。
extract
load
load
extract
extract
load
extract
最好是孤立地思考和测试。使用涉及实际文件内容的测试分区可能是合理的,因为这是程序中实际使用的方式。但实际上不要从测试用例调用,因为可能有错误!相反,应将文件内容存储为文本字符串,并将其直接传递给 。这样,您就可以编写一个独立的单元测试,如果它失败,您可以更确信该 bug 位于它实际测试的模块中。
extract
extract
load
load
extract
请注意,不能以这种方式轻松隔离 的单元测试。当一个测试用例调用时,它不仅在测试里面的代码的正确性,还在测试所有调用的方法的正确性。如果测试失败,则 Bug 可能存在于这些方法中的任何一个中。这就是为什么我们需要对 和 进行单独的测试,以增加我们对这些模块的信心,并将问题本地化为将它们连接在一起的代码。
index
index
index
index
load
extract
index
如果我们编写它调用的模块的存根版本,则可以隔离更高级别的模块。例如,的存根根本不会访问文件系统,而是返回模拟文件内容,无论传递给它什么。类的存根通常称为模拟对象。存根是构建大型系统时的重要技术,但我们通常不会在 6.031 中使用它们。
index
load
File
11.自动化测试和回归测试
没有什么比完全自动化更能使测试更容易运行,也更可能运行了。自动测试意味着运行测试并自动检查其结果。
在模块上运行测试的代码是测试驱动程序(也称为测试工具或测试运行程序)。测试驱动程序不应是提示您输入并打印出结果以供手动检查的交互式程序。相反,测试驱动程序应在固定测试用例上调用模块本身,并自动检查结果是否正确。测试驱动程序的结果应为“所有测试正常”或“这些测试失败:...”一个好的测试框架,如JUnit,允许你使用一套自动化测试来构建和运行这种测试驱动程序。
请注意,像JUnit这样的自动化测试框架使运行测试变得容易,但你仍然需要自己想出好的测试用例。自动测试生成是一个难题,仍然是计算机科学积极研究的主题。
实现测试自动化后,在修改代码时重新运行测试非常重要。软件工程师从痛苦的经历中知道,对大型或复杂程序的任何更改都是危险的。无论您是要修复另一个错误,添加新功能,还是优化代码以使其更快,保留正确行为基线的自动化测试套件(即使只是几个测试)都将节省您的培根。在更改代码时频繁运行测试可防止程序回归 - 在修复新错误或添加新功能时引入其他错误。在每次更改后运行所有测试称为回归测试。
每当发现并修复 Bug 时,请获取引发该 Bug 的输入,并将其作为测试用例添加到自动测试套件中。这种测试用例称为回归测试。这有助于用良好的测试用例填充测试套件。请记住,如果测试引发了错误,那么测试是好的 - 并且每个回归测试都在一个版本的代码中完成!保存回归测试还可以防止重新引入 Bug 的反转。该错误可能很容易犯错误,因为它已经发生过一次。
这个想法也导致了测试优先的调试。当 Bug 出现时,立即为其编写一个引出该 Bug 的测试用例,并立即将其添加到测试套件中。找到并修复 Bug 后,所有测试用例都将通过,你将完成调试并针对该 Bug 进行回归测试。
在实践中,这两个想法,自动化测试和回归测试,几乎总是结合使用。回归测试只有在测试可以经常自动运行时才实用。相反,如果您已经为项目进行了自动化测试,那么您也可以使用它来防止回归。因此,自动化回归测试是现代软件工程的最佳实践。
12.迭代测试优先编程
让我们重新审视一下我们在阅读开始时引入的测试优先编程理念,并对其进行完善。有效的软件工程不遵循线性过程。练习迭代测试优先编程,在编程中,您准备返回并修改前面的步骤中的工作:
- 编写函数的规范。
- 编写执行规范的测试。发现问题时,请迭代规范和测试。
- 编写一个实现。发现问题时,请迭代规范、测试和实现。
每个步骤都有助于验证前面的步骤。编写测试是理解规范的好方法。规范可能不正确、不完整、模棱两可或缺少角情况。尝试编写测试可以在您浪费时间实现错误规范之前尽早发现这些问题。同样,编写实现可以帮助您发现缺失或不正确的测试,或者提示您重新访问和修改规范。
由于可能需要迭代前面的步骤,因此在进入下一步之前花费大量时间使一个步骤完美是没有意义的。规划迭代:
- 对于大型规范,首先只编写规范的一部分,继续测试和实现该部分,然后使用更完整的规范进行迭代。
- 对于复杂的测试套件,首先选择几个重要的分区,然后为它们创建一个小型测试套件。继续进行通过这些测试的简单实现,然后循环访问具有更多分区的测试套件。
- 对于棘手的实现,首先编写一个简单的暴力实现来测试您的规范并验证您的测试套件。然后继续进行更难的实现,并确信您的规范是好的,您的测试是正确的。
迭代是每个现代软件工程过程(如敏捷和Scrum)的一个特征,对其有效性具有良好的经验支持。迭代需要一种与学生解决家庭作业和考试问题时不同的心态。迭代不是试图从头到尾完美地解决问题,而是意味着尽快达成一个粗略的解决方案,然后稳步地完善和改进它,这样你就有时间丢弃并在必要时返工。当问题很困难并且解决方案空间未知时,迭代可以充分利用您的时间。
13.心得体会
在这次阅读中,我有如下收获
- 测试优先编程。在编写代码之前编写测试。
- 使用分区和边界值进行系统测试,以设计正确、彻底和小巧的测试套件。
- 玻璃盒测试和声明覆盖率,用于填写测试套件。
- 对每个模块进行单元测试,尽可能隔离。
- 自动回归测试,防止错误再次出现。
- 迭代开发。计划重做一些工作。
版权归原作者 weixin_45790830 所有, 如有侵权,请联系我们删除。