
Paimon集成并封装了flink CDC,并实现了多种cdc同步功能,如实时增量数据入湖,整库同步,表结构变更等。Paimon支持通过多种模式演化将数据提取到Paimon表中的方法,业务系统中增加的列会实时同步到Paimon中。
可以直接使用Paimon封装好的paimon-cdc-flink插件,配置提交参数即可,不用再去使用API编写flink的cdc程序了。目前Paimon主要用到和支持的cdc同步如下:
● MySQL同步表:将MySQL中的-一张或多张表同步到一张Paimon表中。
●MySQL同步数据库:将整个MySQL数据库同步到一个Paimon数据库中。
●API同步表:将您的自定义DataStream输入同步到一张Paimon表中。
●Kafka同步表:将-一个Kafkatopic的表同步到一张Paimon表中。
●Kafka同步数据库:将一个包含多表的Kafka主题或多个各包含一表的主题同步到一个Paimon数据库中。
(目前0.8版本的cdc也支持了mongodb、pg、pulsar等),本文将主要介绍MySQL的cdc同步。
环境准备
1、添加flink的mysql-cdc jar 包到flink的lib目录
下载地址:Index of /org/apache/flink/flink-sql-connector-mysql-cdc

2、启动flink集群即可使用
3、使用paimon的action jar 包提交任务
MySQL数据同步
官方文档:Mysql CDC | Apache Paimon
一、表同步
Paimon使用flink 的action jar 来执行cdc同步任务,使用到的类是MySqlSyncTableAction,用户可以将 MySQL 中的一张或多张表同步到一张 Paimon 表中。提交命令如下:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.8.2.jar \
mysql_sync_table
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition_keys <partition_keys>] \
[--primary_keys <primary-keys>] \
[--type_mapping <option1,option2...>] \
[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \
[--metadata_column <metadata-column>] \
[--mysql_conf <mysql-cdc-source-conf> [--mysql_conf <mysql-cdc-source-conf> ...]] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]
主要参数
1、warehouse:paimon仓库路径
2、database&table:数据库&表信息
3、partition_keys: 分区键
4、primary_keys: 主键列
5、mysql_conf:mysql 配置,包括主机、用户、密码等数据库连接配置
6、catalog_conf: paimon的catalog配置
7、table_conf: paimon:表的sink配置
8、computed_column:计算列配置,用于对某些字段进行特定的计算转换
9、如果指定的paimon表不存在,会自动建表,其schema会从指定的mysql表派生,如果paimon表已经存在,则会比较其与mysql的schema异同。
同步测试
1、mysql需要开启binlog,使用下面语句检查,ON则为开
show variables like '%log_bin%';
2、mysql创建测试表
CREATE TABLE order_detail (
order_id bigint,
user_id bigint(255),
sku_id bigint(255),
sku_num INT,
payment_amount DECIMAL(10, 3),
order_time TIMESTAMP,
payment_time TIMESTAMP,
create_time TIMESTAMP,
update_time TIMESTAMP,
PRIMARY KEY (order_id)
);
insert into order_detail values
(1,10001,1,10,3000,now(),now(),now(),null),
(2,10002,1,5,400,now(),now(),now(),null)
3、编写提交命令
这里使用的是paimon的hive的calalog,因此需要开启hive的metastore服务
nohup hive --service metastore > /opt/model/hive/logs/metastore.log 2>&1 &
观察flink集群的UI,发现任务已经成功提交上去了
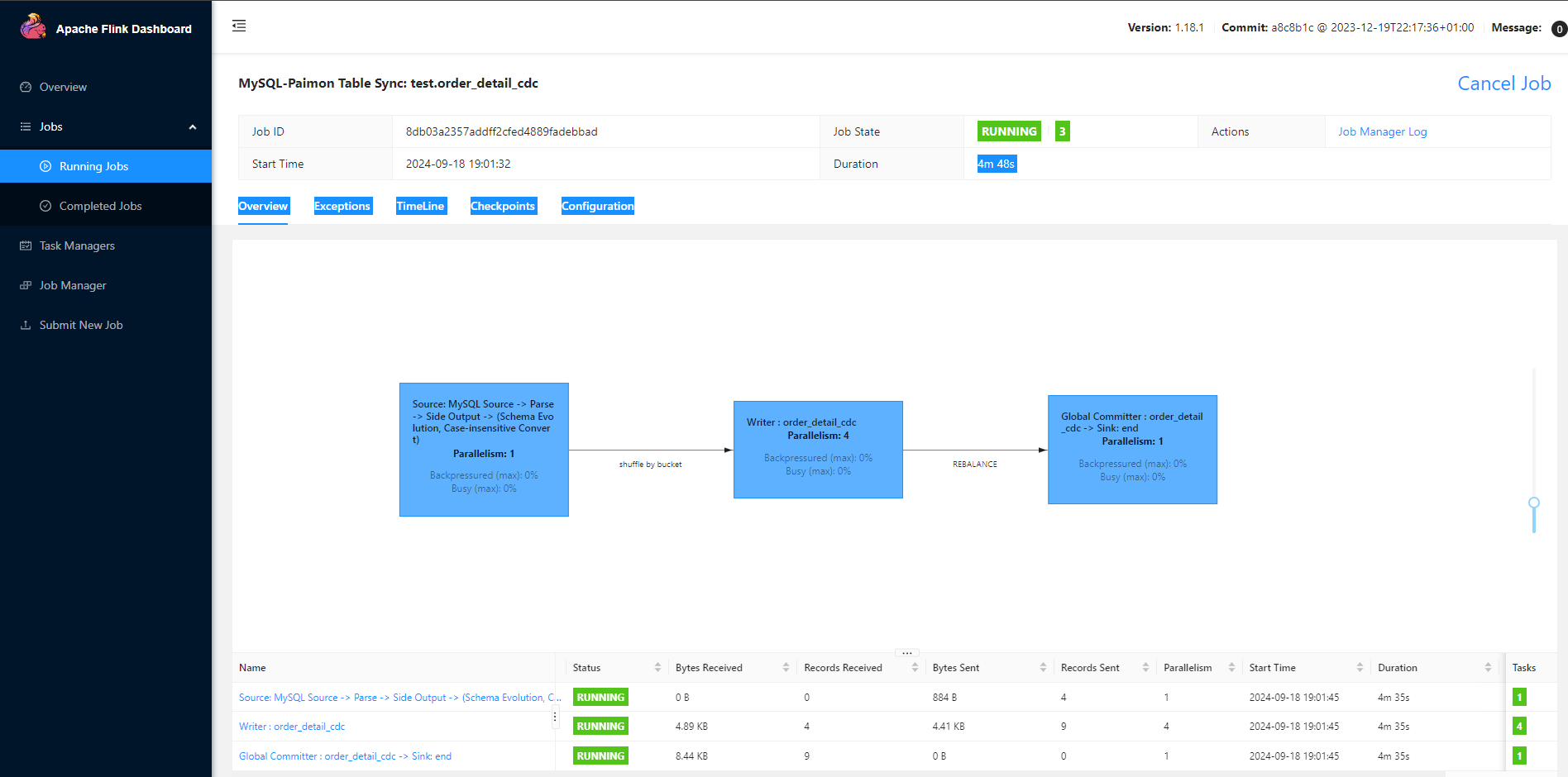
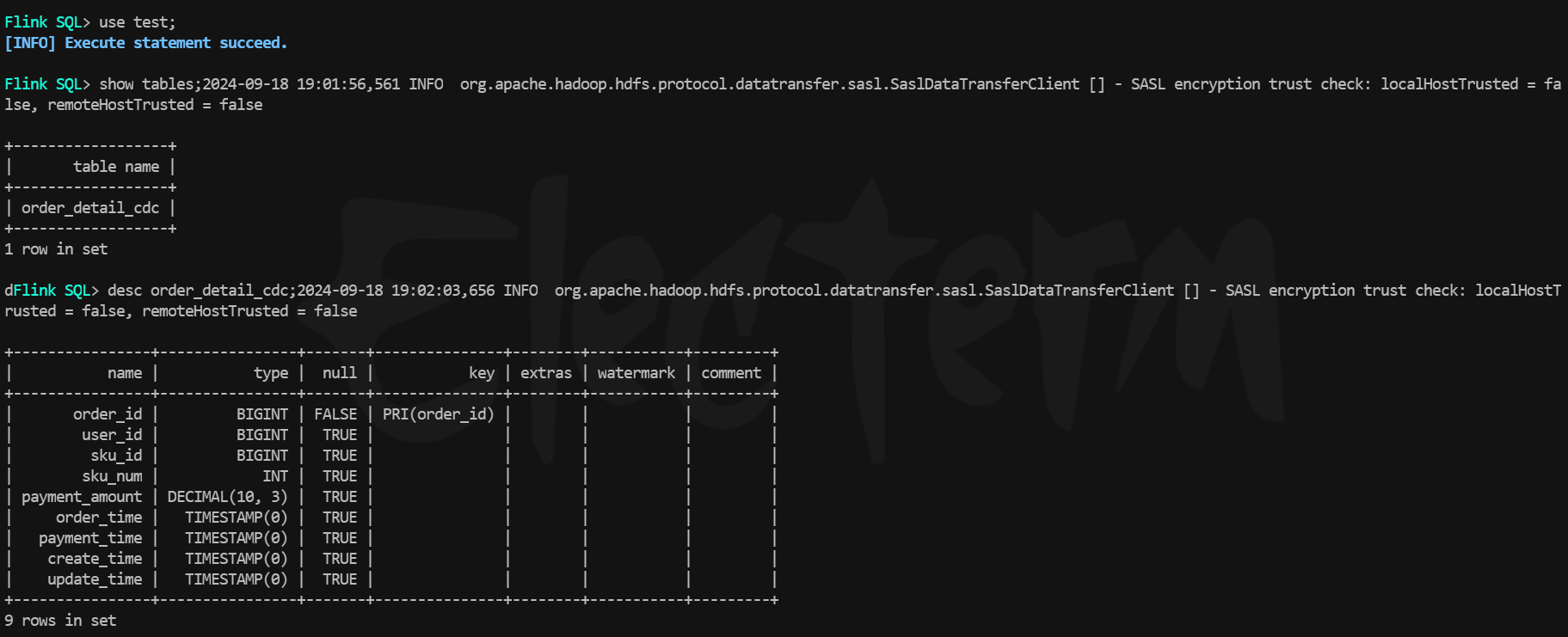
在flink的sql客户端中进行查询,可以看到paimon表已经被自动创建了,字段也均映射正确,执行查询,历史数据已经被同步过来了。
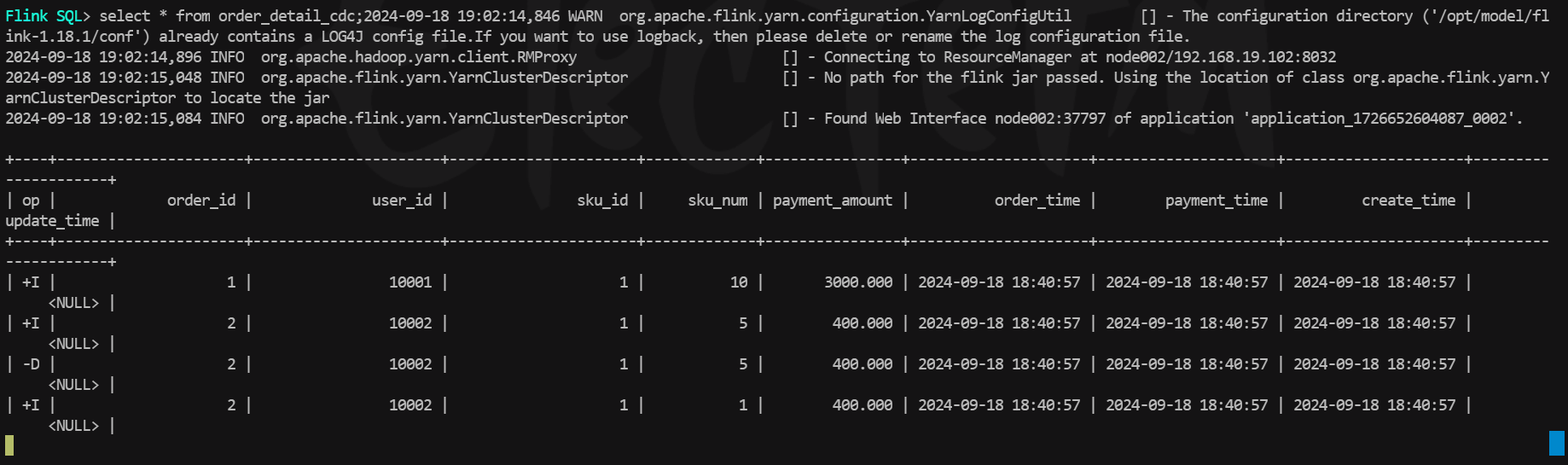
测试在mysql中修改一条订单数据,在flink中查询paimon表,发现数据变化被实时的同步过来了。
如果在提交命令中mysql中指定了多张表同步(表名类似,使用正则,如order_*,但paimon的目标表只有一个,则默认会将mysql这几张表的字段做并集,然后在paimon中建成一张表,如果希望将mysql中不同的几张表分别同步到paimon对应的数据湖表中,可以使用下面的库同步,并进行表名过滤就可以了,类似于flink-cdc的api写法中的table-list。
二、数据库同步
Paimon支持整库同步的方式,将mysql某个数据库的表一次性同步到paimon中,并且支持自动
主要参数
bin/flink run \
/opt/model/flink-1.18.1/opt/paimon-flink-action-0.8-20240709.052248-82.jar \
mysql-sync-table \
--warehouse hdfs://node001:8020/paimon/hive \
--database test \
--tableorderinfocdc \
--primary-keys id \
--mysql-conf hostname=node003 \
--mysql-conf username=root \
--mysql-confpassword=123456 \
--mysql-confdatabase-name=test \
--mysql-conf table-name='order_detail' \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://node001:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4 \
1、warehouse: paimon的仓库地址
2、database: 数据库的名称
3、ignore_incompatible: 是否忽略不匹配项,如果paimon中的表和mysql的表schema,不忽略的话就会报错,忽略则会跳过
4、including_tables: 筛选表列表
5、excluding_tables:忽略表列表
6、mysql_conf: mysql的配置
7、catalog_conf:paimon catalog的配置
8、table_prefix:同步表名的前缀
9、table_suffix:同步表名的后缀
同步测试
1、测试同步mysql的test库中的user_info和order_detail两张表,每张表用4个并行度写入(这里并行度最好和paimon表的bucket数量保持一致,可以1对1写入),将checkpoint-producder设置为输入(input)的,并将paimon表加上ods前缀和cdc后缀,mysql的表清单如下

2、编写flink的提交命令如下
bin/flink run \
/opt/model/flink-1.18.1/opt/paimon-flink-action-0.8-20240709.052248-82.jar \
mysql-sync-database \
--warehouse hdfs://node001:8020/paimon/hive \
--database test \
--table-prefix "ods_" \
--table-suffix "_cdc" \
--mysql-conf hostname=node003 \
--mysql-conf username=root \
--mysql-conf password=123456 \
--mysql-conf database-name=test \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://node001:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4
--including_tables 'order_detail|user_info'
3、执行flink-run,发现任务已经被成功提交到flink集群
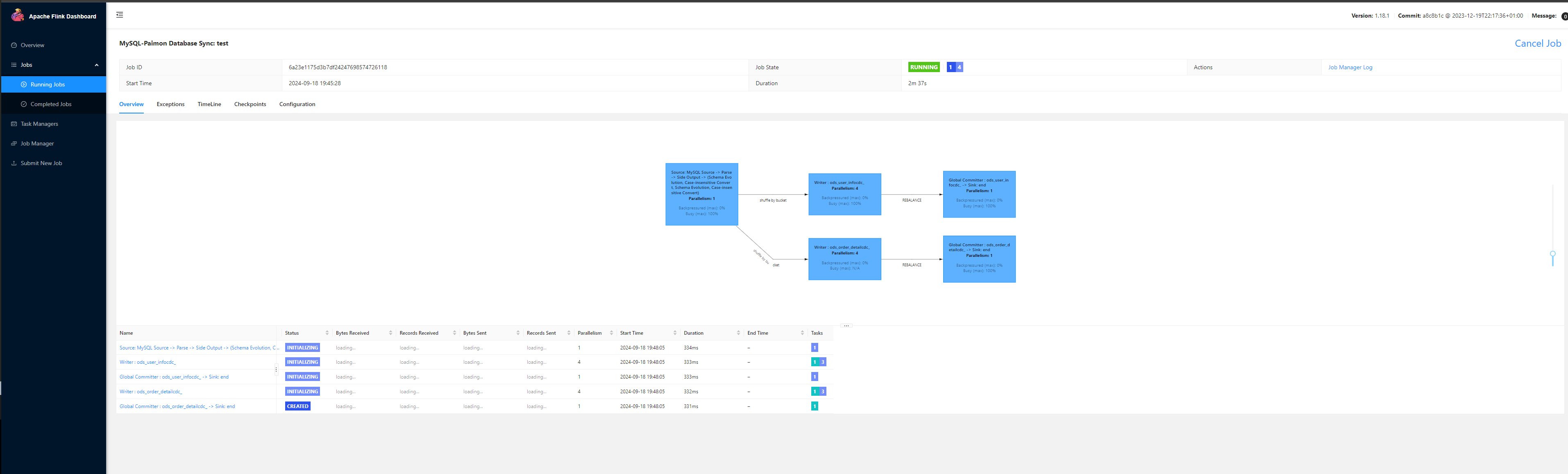
4、在sql客户端中查询,可以看到paimon表已经成功自动被创建,对应mysql数据库中的order_detail和user_info,schema映射正确,这里的(cdc后缀之前打错了,忽略这个细节),执行查询,历史数据也均被同步了过来。

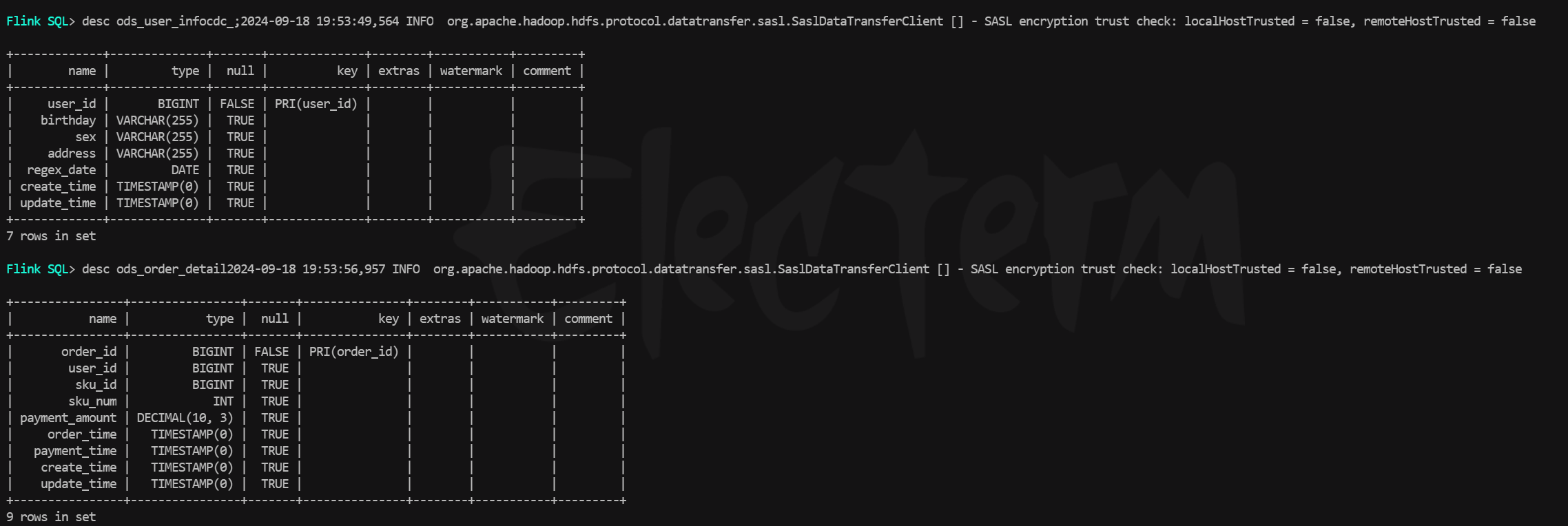
5、对整库同步模式下的mysql表中进行数据修改,发现paimon表中也可以实时增量同步。
6、在进行数据库同步时,如果后续又想增加新的数据表进行同步,如果直接把运行的flink任务停掉,增加新表后从启,会造成其他表的重复处理与资源浪费,这种情况下,可以首先对该任务手动触发savepoint,持久化到hdfs上后,再停掉任务,然后增加新表,并且在提交命令上增加参数 --fromsavepoint path,任务重启后就可以快速的从快照恢复,提高效率。
版权归原作者 祺嘉朱 所有, 如有侵权,请联系我们删除。