
文章目录
一、前言
1.1写在前面的话
- 我们大家总是在聊优化优化,那么怎么优化?相信每个人都有自己的一套方法论。在我看来的话,可能就是存储、模型、sql、以及Hive Job 层面的一些优化,后者更多的可能是IO优化
- 今天我们来聊一聊执行计划,如果掌握了MapReduce,且开发者有一定的经验积累可以反推Compiler将SQL转换的MapReduce执行算法,并
借助explain来比对你构思的执行计划和实际生成的执行计划是否存在差异,并思考差异的原因是啥,慢慢就能够对生成的算法以及算法执行路径图是否合理给出一个自己的评判,同时也能提升自己对SQL的掌控
1.2为什么有hive
- FaceBook公司在使用Hadoop实现数据分析的时候,发现有个毛病:会做分析的人如业务人员、数据分析师,会用SQL;会用Hadoop实现分布式开发是开发人员 - 方案一:让开发人员教业务写代码,成本比较高- 方案二:让开发人员对Hadoop做一层封装,开发一个新的程序,封装以后新的程序提供SQL接口,在新的程序中用SQL进行开发,这个程序底层自动将SQL转为MapReduce程序提交给YARN去运行。最早的Hive就诞生了
1.3Hive的本质
- Hive的本质:对Hadoop做了封装,提供了SQL来操作Hadoop - 实现基于HDFS的分布式存储- 实现基于MR和YARN的分布式计算- 是一种特殊的Hadoop的客户端,最终的计算和存储还是由Hadoop来完成的,Hive实际上是一个翻译的角色,Hive的使用依赖于Hadoop
1.4hive架构
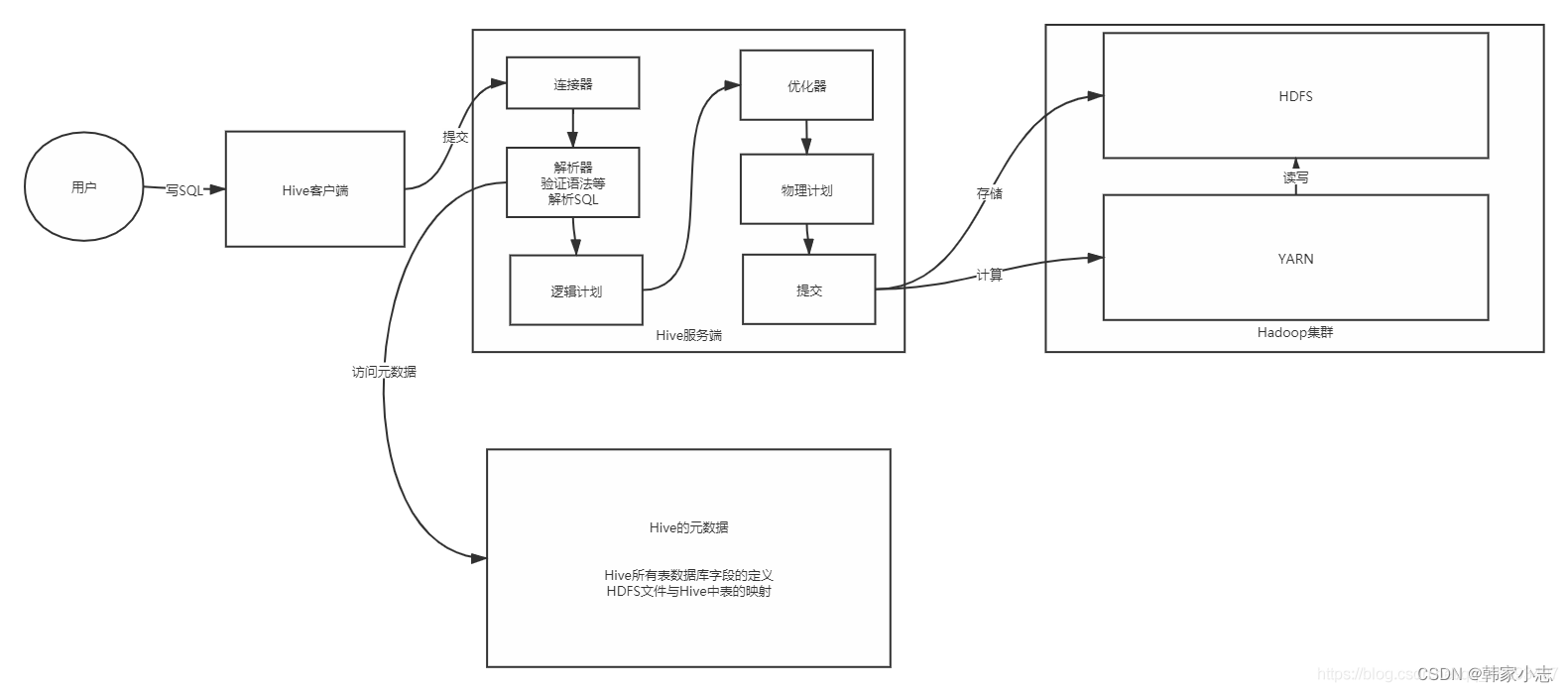
- 编译 SQL 的任务是在hive官网中( 较复杂,这里简单画一下)介绍的 COMPILER(编译器组件)中完成的。Hive将SQL转化为MapReduce任务,整个编译过程分为六个阶段: - 连接器:负责构建与客户端 的连接管理- 解析器:负责 解析整个SQL语句,也会做验证,表是否存在,语法是否正确 - 解析器最终得到一个解析以后的语法树- 逻辑计划:将SQL语句中的解析出来的语法数,变成对应的参数,赋予底层的MapReduce构建逻辑执行计划- 优化器:根据要实现的效果,选择一种最优的方式来构建物理计划- 物理计划:最终完整的Mapre程序- 提交运行:将程序提交给YARN
1.5MapReduce图解
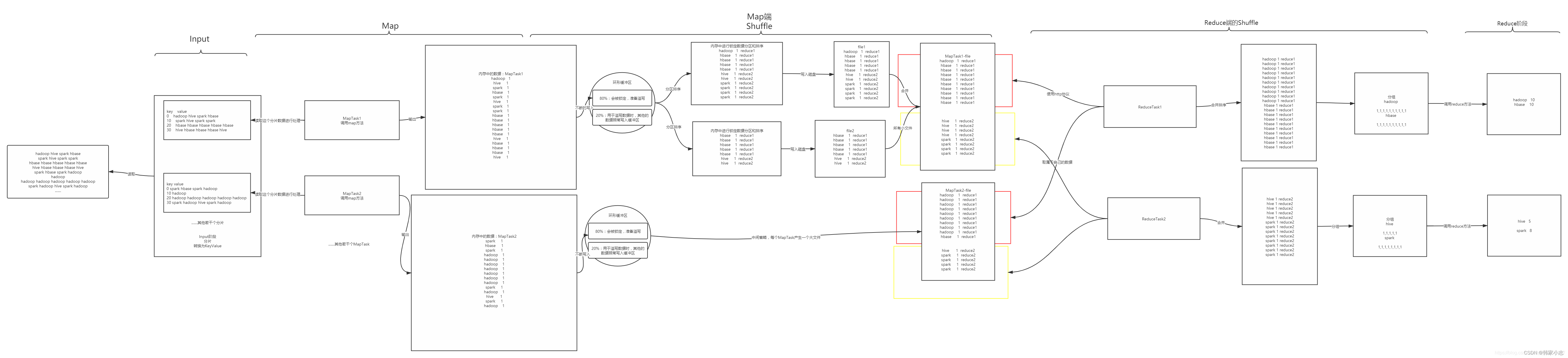
1.6SQL转化为MapReduce的过程

- step1词法、语法解析: - Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
- step2语义解析: - 遍历AST Tree,抽象出查询的基本组成单元QueryBlock
- step3生成逻辑执行计划: - 遍历QueryBlock,翻译为执行操作树OperatorTree- Hive 最终生成的MapReduce任务,Map阶段和Reduce阶段均有OpeatorTree组成。 - 基本操作符包括: - TableScanOperator- SelectOperator- FilterOperator- JoinOperator- GroupByOperator- ReduceSinkOperator- 由于Join/GroupBy/OrderBy均需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce Key/value, Partition Key。
- step4优化逻辑执行计划: - 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量- Hive中的逻辑查询优化可以大致分为以下几类: - 投影修剪- 推导传递谓词- 谓词下推- 将Select-Select,Filter-Filter合并为单个操作- 多路 Join- 查询重写以适应某些列值的Join倾斜
- step5生成物理执行计划: - 遍历OperatorTree,翻译为MapReduce任务- 生成物理执行计划即是将逻辑执行计划生成的OpeatorTree转化成MapReduce Jon的过程,主要分为下面几个阶段: - 对输出表生成MoveTask- 从OperatorTree的其中一个根节点向下深度优先遍历- ReduceSinkOperator标示Map/Reduce的界限,多个Job间的界限- 遍历其他根节点,遇过碰到JoinOperator合并MapReduceTask- 生成StatTask更新元数据- 剪断Map与Reduce间的Operator的关系
- step6优化物理执行计划: - 物理层优化器进行MapReduce任务的变换,生成最终的执行计划- Hive中的物理优化可以大致分为以下几类: - 分区修剪(Partition Pruning)- 基于分区和桶的扫描修剪(Scan pruning)- 如果查询基于抽样,则扫描修剪- 在某些情况下,在 map 端应用 Group By- 在 mapper 上执行 Join- 优化 Union,使Union只在 map 端执行- 在多路 Join 中,根据用户提示决定最后流哪个表- 删除不必要的 ReduceSinkOperators- 对于带有Limit子句的查询,减少需要为该表扫描的文件数- 减少用户提交的SQL查询所需的Tez作业数量- 如果是简单的提取查询,避免使用MapReduce作业- 对于带有聚合的简单获取查询,执行不带 MapReduce 任务的聚合- 重写 Group By 查询使用索引表代替原来的表- 当表扫描之上的谓词是相等谓词且谓词中的列具有索引时,使用索引扫描
二、什么是执行计划
2.1什么是执行计划
- 所谓执行计划,顾名思义,就是对一个查询任务(sql),做出一份怎样去完成任务的详细方案。
- 举个生活中的例子,我从上海要去新疆,我可以选择坐飞机、坐高铁、坐火车,甚至于自驾。具体到线路更是五花八门,现在我准备选择自驾了,具体什么路线怎样去划算(时间&费用),这是一件值得考究的事情。
- HIVE(我们的自驾工具)提供了EXPLAIN命令来展示一个查询的执行计划(什么路线),这个执行计划对于我们了解底层原理,hive 调优,排查数据倾斜等很有帮助。
2.2语法组成
- 官方对Hive Explain的英文解释- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
- 语法组成- explain +可选参数+查询语句
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
explain
查看执行计划的基本信息;
explain extended
查看执行计划的扩展信息;
explain cbo
输出由Calcite优化器生成的计划。CBO 从 Hive 4.0.0 版本开始支持;
explain ast
输出查询的抽象语法树,主要用于开发或者高级用户通过查看抽象语法树发现问题。
AST 在 Hive 2.1.0 版本删除了,存在bug,转储AST可能会导致OOM错误,将在4.0.0版本修复;
explain dependency
查看执行计划中输入源相关的额外信息;
以一个大JSON的方式展示处理,其中包含了input_tables 和 input_partitions两个字段,分别底层扫描的表和对应扫描的分区(如果表是分区表)
explain authorization
查看SQL操作相关权限的信息;(存在授权失败的情况也会展示)
从 Hive 0.14.0 开始支持[HIVE-5961]
explain locks
这对于了解系统将获得哪些锁以运行指定的查询很有用。LOCKS 从 Hive 3.2.0 开始支持[HIVE-17683]
explain vectorization
查看SQL的向量化描述信息,从 Hive 2.3.0 开始支持;
explain analyze
用实际的行数注释计划。从 Hive 2.2.0 开始支持;
三、 explain query
3.0一个小实例
explainselect*from dim_cal_dt
where cal_dt='2023-02-08';
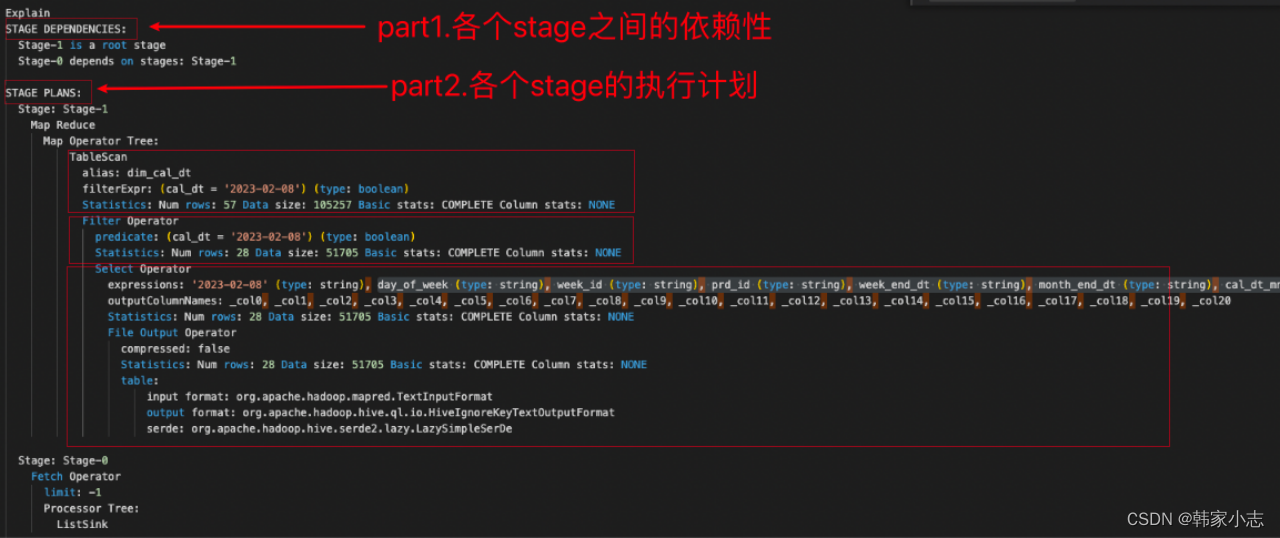
是不是猛地一下看不太懂,我们可以先简单看下3.1~3.6,再回头看这里
聊完stage和operator,回头看我们发现大概能得到如下信息
stage-1
1. Map Operator Tree,首先进行表扫描(Table scan),预计扫描的行 57 ,涉及的数据大小 105257 ,表别名为 dim_cal_dt (这里没有给别名,如果给别名就是别名)
2. Filter Operator,行过滤操作,过滤的表达式是 cal_dt = '2023-02-08' ,预计处理的行是 28 ,涉及的数据大小 51705
3. Select Operator,列过滤操作. 这个阶段,我建议采用这样的方式,先读最深的缩进。所以读起来是这样,
3.1 处理的表,输入格式(input format)是org.apache.hadoop.mapred.TextInputFormat,输出格式是org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat 文件的序列化格式org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
3.2 输出的文件预计是 28 行,数据大小是 51705
3.3 输出没有压缩
3.4 一共输出了 21 列,由于mapreduce中所有的列都是按占位符来表示,所以这里都是用_col[0-20]
3.5 输出每一列表述的数据格式(expressions)
stage-0
1. Fetch Operator这表示客户端的取数操作
- 好像有点不对啊 - 本表是ORC的格式,为什么解释计划给出来的TextInPutFormat- 文件预计 n 行(输入/输出) 是怎么来的?- 日期维表不会只有57的啊
- 回答这些问题前,大家要先有一个概念,执行计划是Hive根据统计信息所进行的简单描述,不是真正跑的执行计划,但是对了解其中的细节仍然有帮助。
- 简而言之,这个执行计划是假的,他能帮我们大致理解整个运行过程,却没法帮我们直接定位问题。
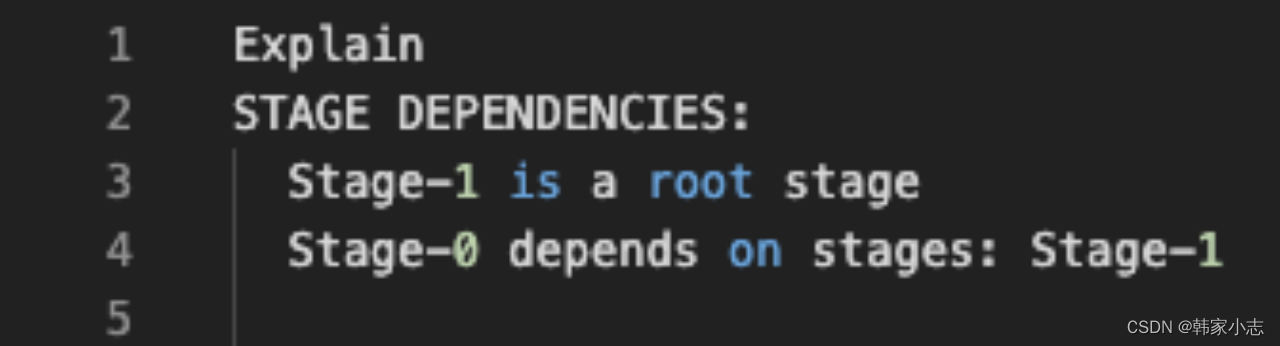
3.1两个部分
- stage dependencies : 各个stage之间的依赖性
- stage plan :各个stage的执行计划
3.2 Stage理解
- 结合对前面讲到的Hive对查询的一系列执行流程的理解,那么在一个查询任务中会有一个或者多个Stage.每个Stage之间可能存在依赖关系。没有依赖关系的Stage可以并行执行。
- Stage是Hive执行任务中的某一个阶段,那么这个阶段可能是一个MR任务,也可能是一个抽取任务,也可能是一个Map Reduce Local ,也可能是一个Limit。
3.4 何时划分Stage
- 那么Stage划分的时机其实是发生在逻辑计划转化OperatorTree转化成物理计划的阶段TaskTree,按照深度优先遍历OperatorTree,再结合具体执行引擎的Compiler(MR/Tez/Spark)应用规则生成对应的Task。
- Stage划分的界限决定于ReduceSinkOperator,在遇到ReduceSinkOperator之前的Operator都划分到Map阶段,同时也标识这Map阶段的结束。该ReduceSinkOperator到下一个ReduceSinkOperator阶段中间的部分划分为Reduce阶段。一个MR任务代表一个Stage(当然也包括其他非MR,如FetchTask、MoveTask、CopyTask)。
3.5划分规则(按照MR为例子):
- R1: TS% ---->生成MapRedTask对象,确定MapWork
- R2:TS%.*RS —>遇到第一个ReduceSinkOperator,划分Map阶段,确定ReduceWork
- R3:RS%.*RS% ---->生成新的MapRedTask,切分MapRedTask。这个时候已经生成一个Job
- R4:FS% ----> 连接MapRedTask和MoveTask。
- R5:UNION% ---->如果所有的子查询都是map-only,则把所有的MapWork进行合并连接。
- R6:UNION%.*RS% —>遇到ReduceSinkOpeartor,则合并Stage。
- R7:MAPJOIN%
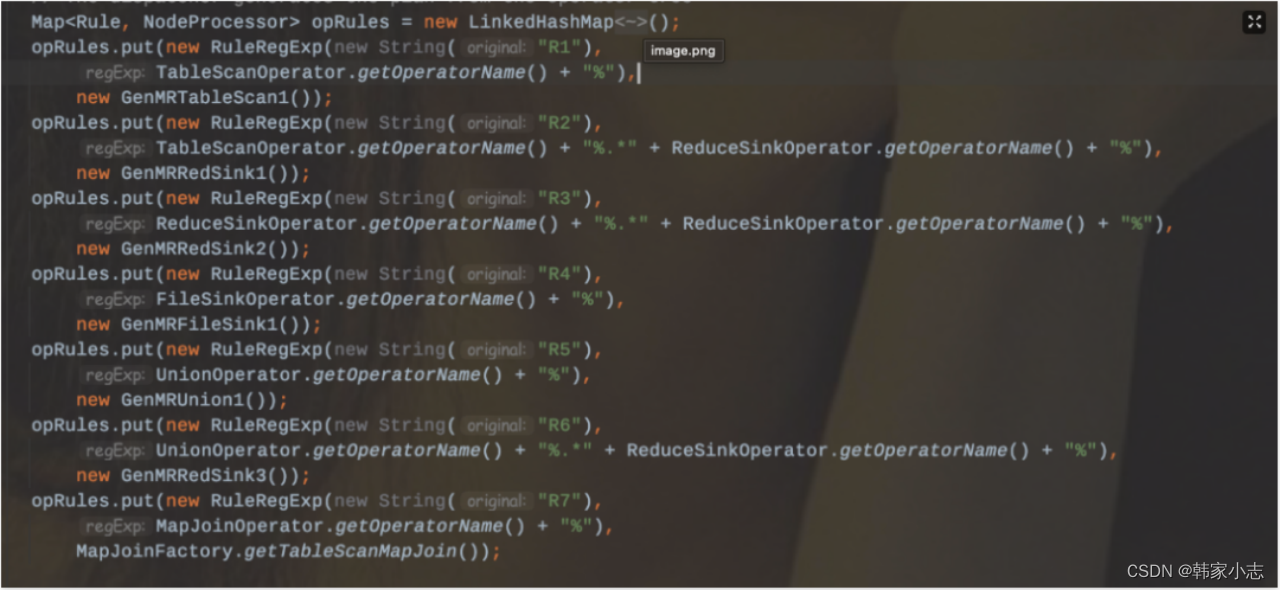
感兴趣的同学可以参考下这几篇文章
3.6常见Operator
TableScan:表扫描操作
- alias:表名称
- Statistics:表统计信息,包含表中数据条数,数据大小等
Select Operator:选取操作
- expressions:需要的字段名称及字段类型
- outputColumnNames:输出的列名称
- Statistics:表统计信息,包含表中数据条数,数据大小等
Group By Operator:分组聚合操作
- aggregations:显示聚合函数信息
- mode:聚合模式,值有 hash:随机聚合,就是hash partition;partial:局部聚合;final:最终聚合
- keys:分组的字段(如果没有分组,则没有此字段)
- outputColumnNames:聚合之后输出列名
- Statistics:表统计信息,包含分组聚合之后的数据条数,数据大小等
Reduce Output Operator:输出到reduce操作
- sort order:值为空 不排序;值为 + 正序排序,值为 - 倒序排序;值为 ± 排序的列为两列,第一列为正序,第二列为倒序
Filter Operator:过滤操作
- predicate:过滤条件,如sql语句中的where id>=1,则此处显示(id >= 1)
Map Join Operator:join 操作
- condition map:join方式 ,如Inner Join 0 to 1 Left Outer Join0 to 2
- keys: join 的条件字段
- outputColumnNames:join 完成之后输出的字段
- Statistics:join 完成之后生成的数据条数,大小等
File Output Operator:文件输出操作
- compressed:是否压缩
- table:表的信息,包含输入输出文件格式化方式,序列化方式等
Fetch Operator 客户端获取数据操作
- limit,值为 -1 表示不限制条数,其他值为限制的条数
四、实战
4.0 准备数据
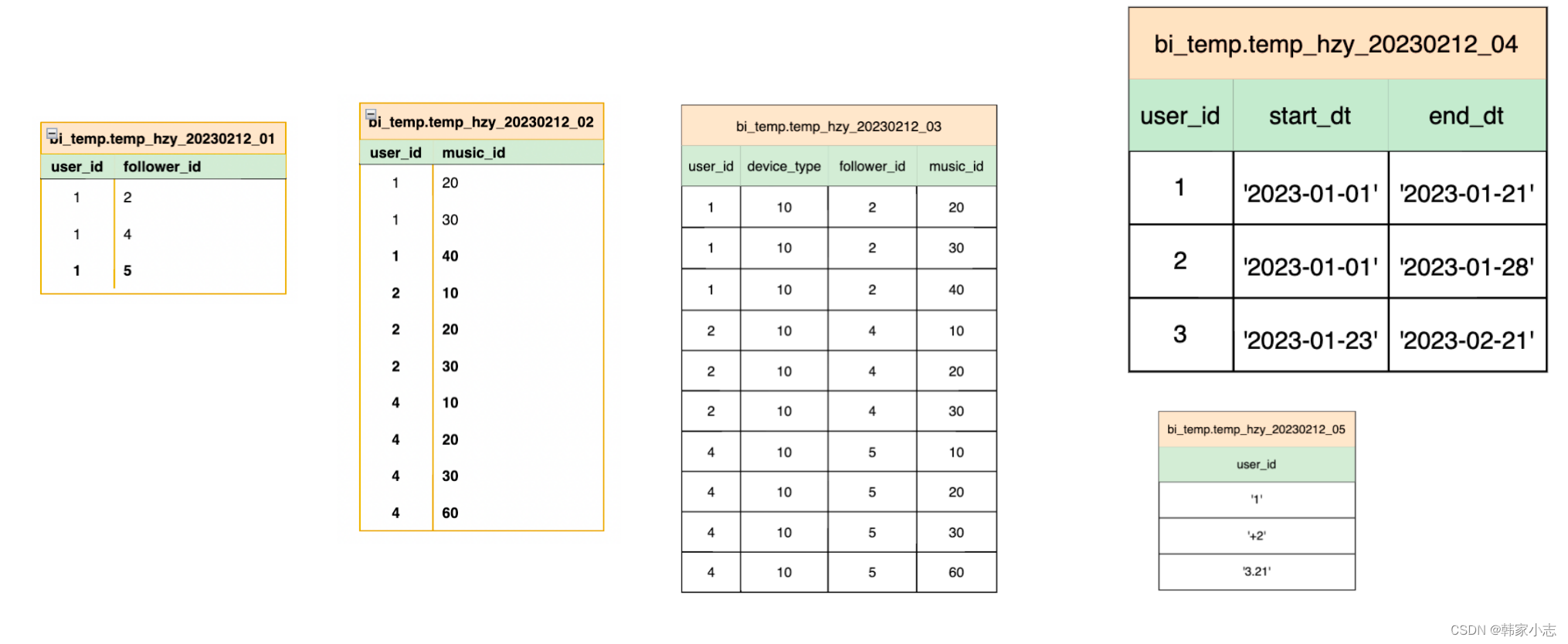
droptableifexists bi_temp.temp_hzy_20230212_01;createtable bi_temp.temp_hzy_20230212_01 asselect1as user_id,2as follower_id unionallselect1as user_id,4as follower_id unionallselect1as user_id,5as follower_id
;droptableifexists bi_temp.temp_hzy_20230212_02;createtable bi_temp.temp_hzy_20230212_02 asselect1as user_id,20as music_id unionallselect1as user_id,30as music_id unionallselect1as user_id,40as music_id unionallselect2as user_id,10as music_id unionallselect2as user_id,20as music_id unionallselect2as user_id,30as music_id unionallselect4as user_id,10as music_id unionallselect4as user_id,20as music_id unionallselect4as user_id,30as music_id unionallselect4as user_id,60as music_id
;droptableifexists bi_temp.temp_hzy_20230212_03;createtable bi_temp.temp_hzy_20230212_03 asselect1as user_id,10as device_type,2as follower_id,20as music_id unionallselect1as user_id,10as device_type,2as follower_id,30as music_id unionallselect1as user_id,10as device_type,2as follower_id,40as music_id unionallselect2as user_id,10as device_type,4as follower_id,10as music_id unionallselect2as user_id,10as device_type,4as follower_id,20as music_id unionallselect2as user_id,10as device_type,4as follower_id,30as music_id unionallselect4as user_id,10as device_type,5as follower_id,10as music_id unionallselect4as user_id,10as device_type,5as follower_id,20as music_id unionallselect4as user_id,10as device_type,5as follower_id,30as music_id unionallselect4as user_id,10as device_type,5as follower_id,60as music_id
;droptableifexists bi_temp.temp_hzy_20230212_04;createtable bi_temp.temp_hzy_20230212_04 asselect1as user_id,'2023-01-01'as start_dt,'2023-01-21'as end_dt unionallselect2as user_id,'2023-01-01'as start_dt,'2023-01-28'as end_dt unionallselect3as user_id,'2023-01-23'as start_dt,'2023-02-21'as end_dt
;droptableifexists bi_temp.temp_hzy_20230212_05;createtable bi_temp.temp_hzy_20230212_05 asselect'1'as user_id unionallselect'+2'as user_id unionallselect'3.21'as user_id
;
4.1简单sql的执行计划
- 带普通函数SQL的执行计划和select-from-where型简单的SQL一样,都只有Map阶段,都是在Map端过滤,都是本地计算。
-- 简单SQL的执行计划explainselect*from dim_cal_dt
where cal_dt='2023-02-08';-- 带普通函数SQL的执行计划explainselect cal_dt
,date_add(cal_dt,1)as add_cal_dt
from dim_cal_dt
where cal_dt='2023-02-08';

- lateral view 属于普通函数吗?你知道有个outer关键字吗? - Lateral view与UDTF函数一起使用,UDTF对每个输入行产生0或者多个输出行。Lateral view首先在基表的每个输入行应用UDTF,然后连接结果输出行与输入行组成拥有指定表别名的虚拟表。- 大家可以随便测试一下,会发现Lateral view explode 没有reduce任务,不会产生shuffle,所以有时候我们是可以改写sql的
4.1.1join操作改普通函数
- 很容易就能写出
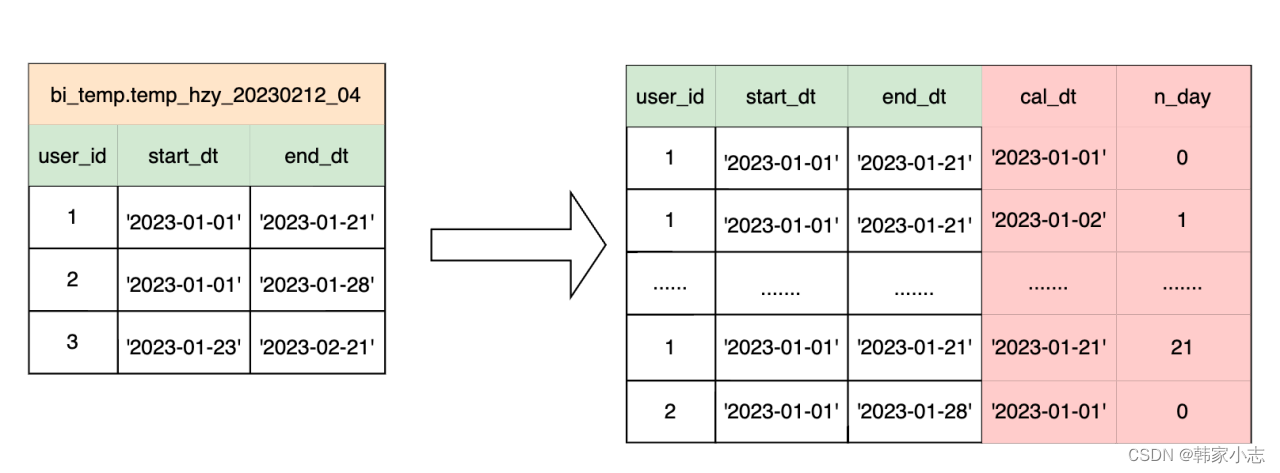
explainselect a.user_id
,a.start_dt
,a.end_dt
,b.cal_dt
,datediff(b.cal_dt,a.start_dt)as n_day
from bi_temp.temp_hzy_20230212_04 a
join bi_dim.dim_cal_dt b
where a.start_dt <=b.cal_dt
and b.cal_dt<=a.end_dt
orderby a.user_id,n_day
;
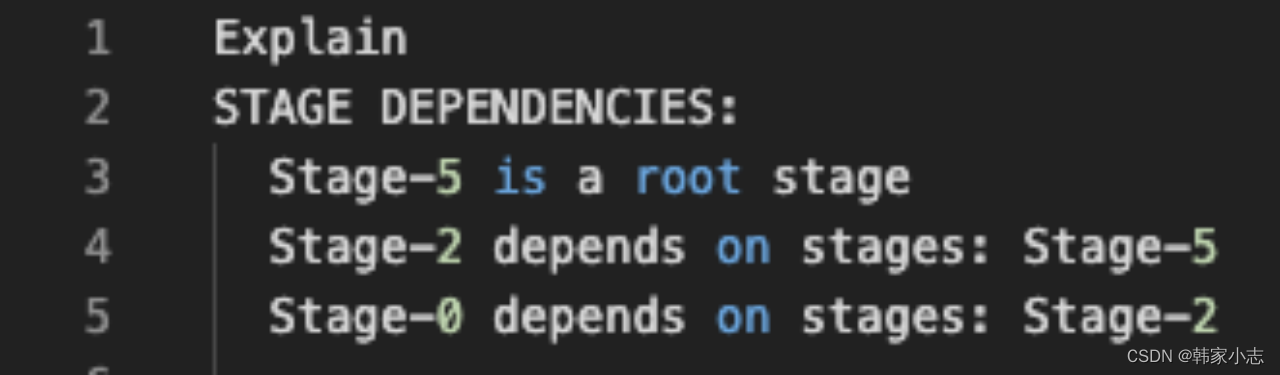
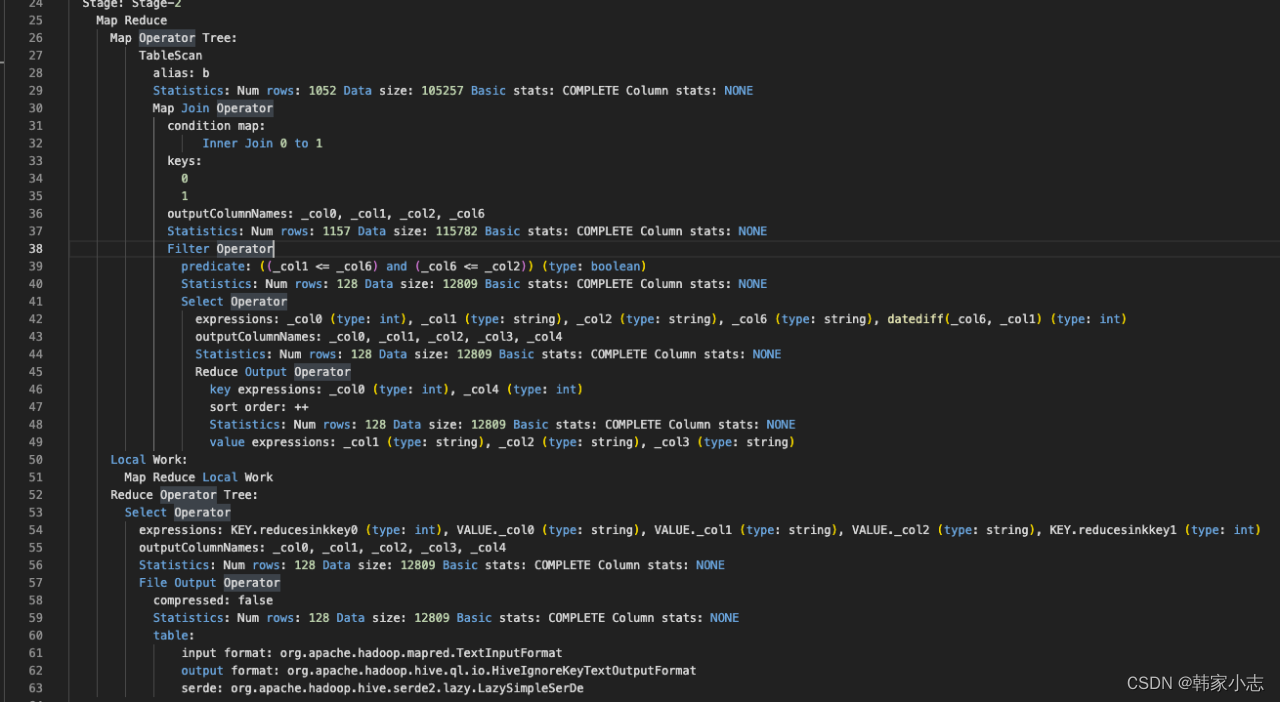
- 能不能优化?减少stage或者说减少shuffle,答案是可以的
explainselect a.user_id
,a.start_dt
,a.end_dt
,date_add(a.start_dt,tab.pos)as cal_dt
,tab.pos as n_day
from bi_temp.temp_hzy_20230212_04 a
lateral view posexplode(split(repeat(',',datediff(a.end_dt,a.start_dt)),',')) tab as pos,val
;
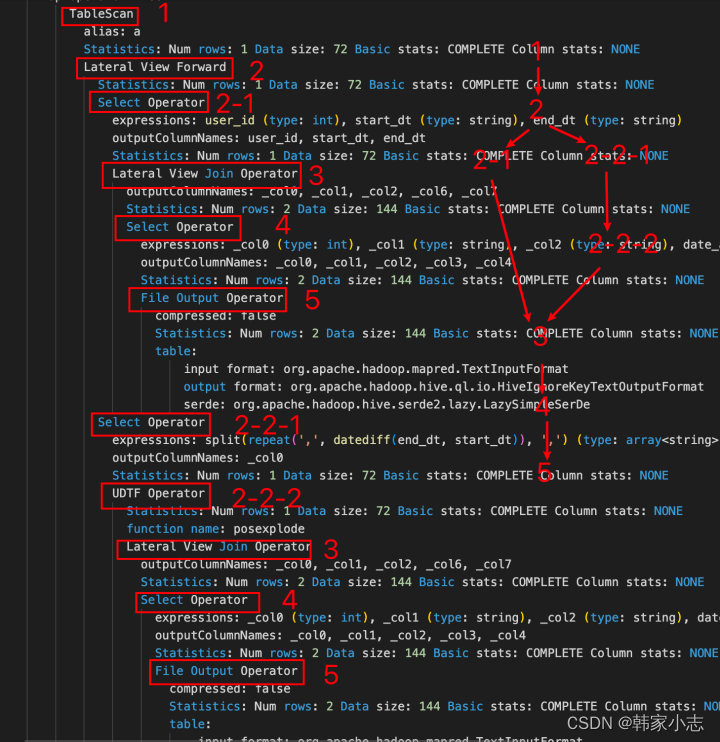
- Map端过滤,本地计算,没有shuffle。
- Lateral view与UDTF函数一起使用,UDTF对每个输入行产生0或者多个输出行。Lateral view首先在基表的每个输入行应用UDTF,然后连接结果输出行与输入行组成拥有指定表别名的虚拟表。
- 以这个例子我们可以看到- 2-1、左侧SelectOperator - 筛选出你需要的非explode的列:user_id、start、end_dt- 2-2 - 2-2-1、右侧SelectOperator - 筛选出explode的列:(split(repeat(‘,’,datediff(a.end_dt,a.start_dt)),‘,’))- 2-2-2、右侧UDTFOperator - udtf :function name: posexplode- 3 LateralViewJoinOperator,这里的join也是简单的List.addAll
- 有没有个问题?刚才看到有个Lateral View Join Operator,如果udtf的输出为null,还会有数据吗?
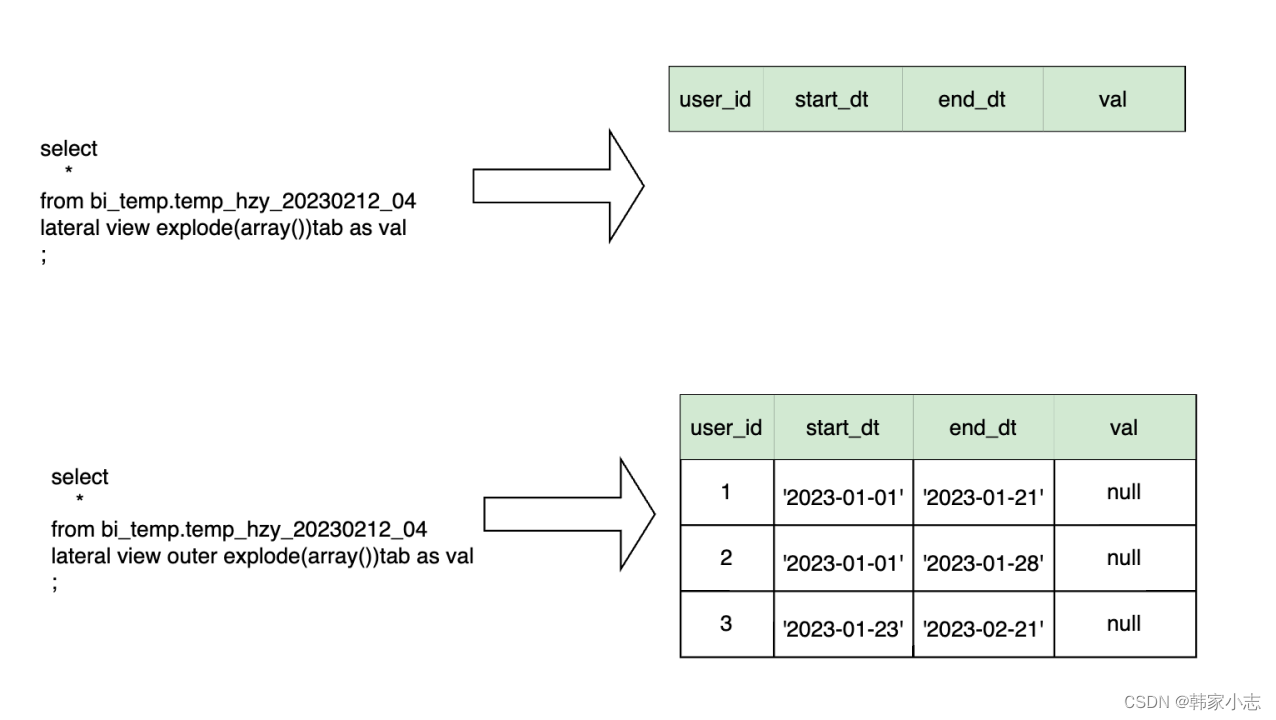
- tips:当UDTF不产生任何行时,比如explode()函数的输入列为空,LATERALVIEW就不会生成任何输出行。在这种情况下原有行永远不会出现在结果中。
- OUTRE可被用于阻止这种情况,输出行中来自UDTF的列将被设置为NULL。
4.1.2union all操作改普通函数
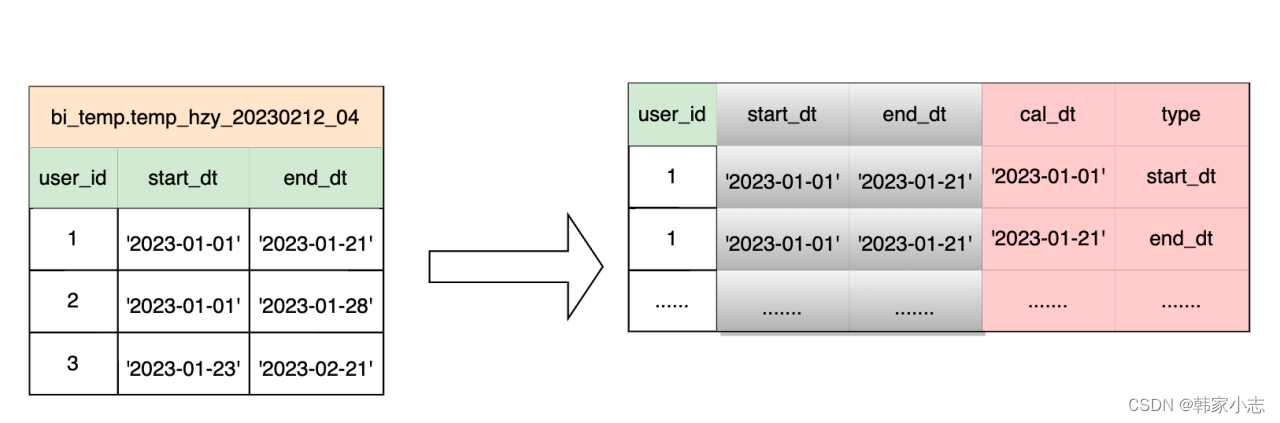
很容易就写出
explainselect user_id,start_dt as cal_dt,'start'astypefrom bi_temp.temp_hzy_20230212_04
unionallselect user_id,end_dt as cal_dt,'end'astypefrom bi_temp.temp_hzy_20230212_04
unionallselect user_id,start_dt as cal_dt,'start2'astypefrom bi_temp.temp_hzy_20230212_04
unionallselect user_id,end_dt as cal_dt,'end2'astypefrom bi_temp.temp_hzy_20230212_04
unionallselect user_id,start_dt as cal_dt,'start3'astypefrom bi_temp.temp_hzy_20230212_04
unionallselect user_id,end_dt as cal_dt,'end3'astypefrom bi_temp.temp_hzy_20230212_04
;
- 如果想要实现列转行,我们可能第一反应就是union all了~
- 这里只是举例子union all了这么多,实际工作中各个 type 可能是对应的字段名
- 在这里我们其实可以看到表扫描了6次
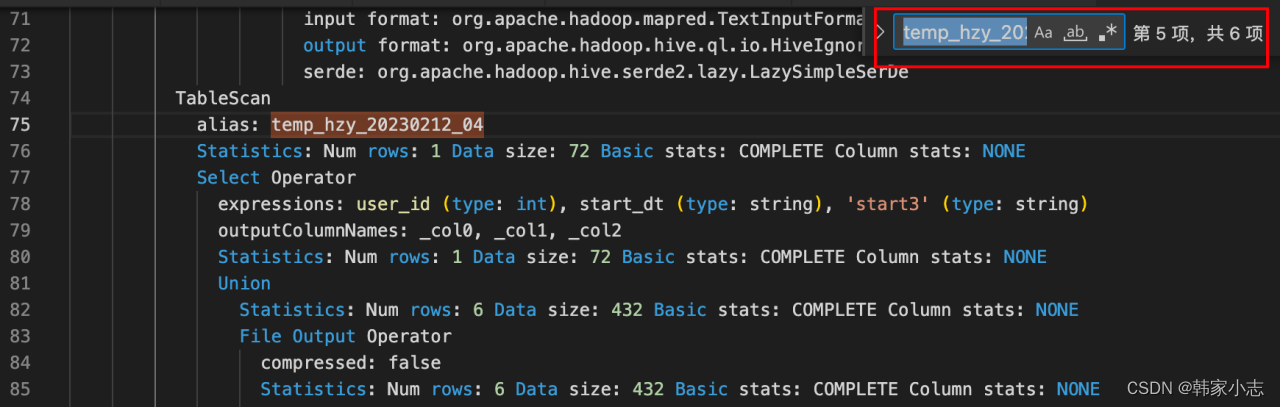
- 我们可以进行改写
select a.user_id
,tab.val as cal_dt
,casewhen tab.pos=0then'start'when tab.pos=1then'end'when tab.pos=2then'start2'when tab.pos=3then'end2'when tab.pos=4then'start3'when tab.pos=5then'end3'when tab.pos=6then'start4'when tab.pos=7then'end4'when tab.pos=8then'start5'when tab.pos=9then'end5'endastypefrom bi_temp.temp_hzy_20230212_04 a
lateral view
posexplode(array(start_dt,end_dt
,start_dt,end_dt,start_dt,end_dt
,start_dt,end_dt,start_dt,end_dt)) tab as pos,val
;
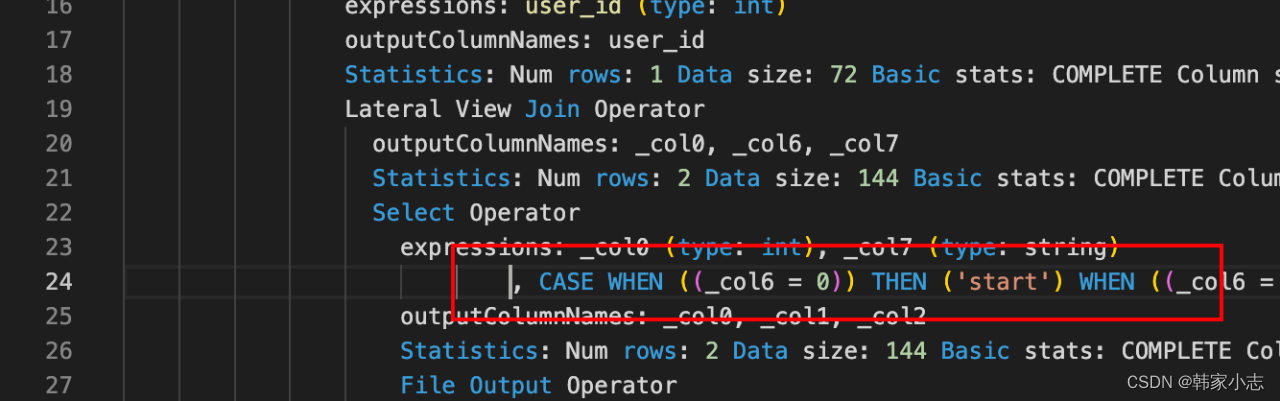
- 那换成lateral view ,哪怕增加了几个字段 - 1.代码改动量小,看起来比较优雅- 2.看执行计划基本上不变~- 而 之前的union all写法 就会增加扫表次数
- 聊到这里,我们似乎在为减少stage,减少operator而努力着,那么越少就越好吗 - 答案显而易见,如果越少越好,那么数据倾斜似乎就会来了~- 同理越多越好也是不合理的,就像map个数小文件问题等,适合的才是最好的~
- 大数据的核心解决思路是分而治之,在此基础上我们考虑移动存储不如移动计算等减少io的操作,而不能一味追求减少。所以优化一定是对症下药~~~
- 下面我们拿这count distinct 的优化来讨论这个问题
4.2带聚合函数SQL的执行计划
explainselect user_id
,count(distinct music_id) num
from bi_temp.temp_hzy_20230212_02
where user_id <>4groupby user_id
;
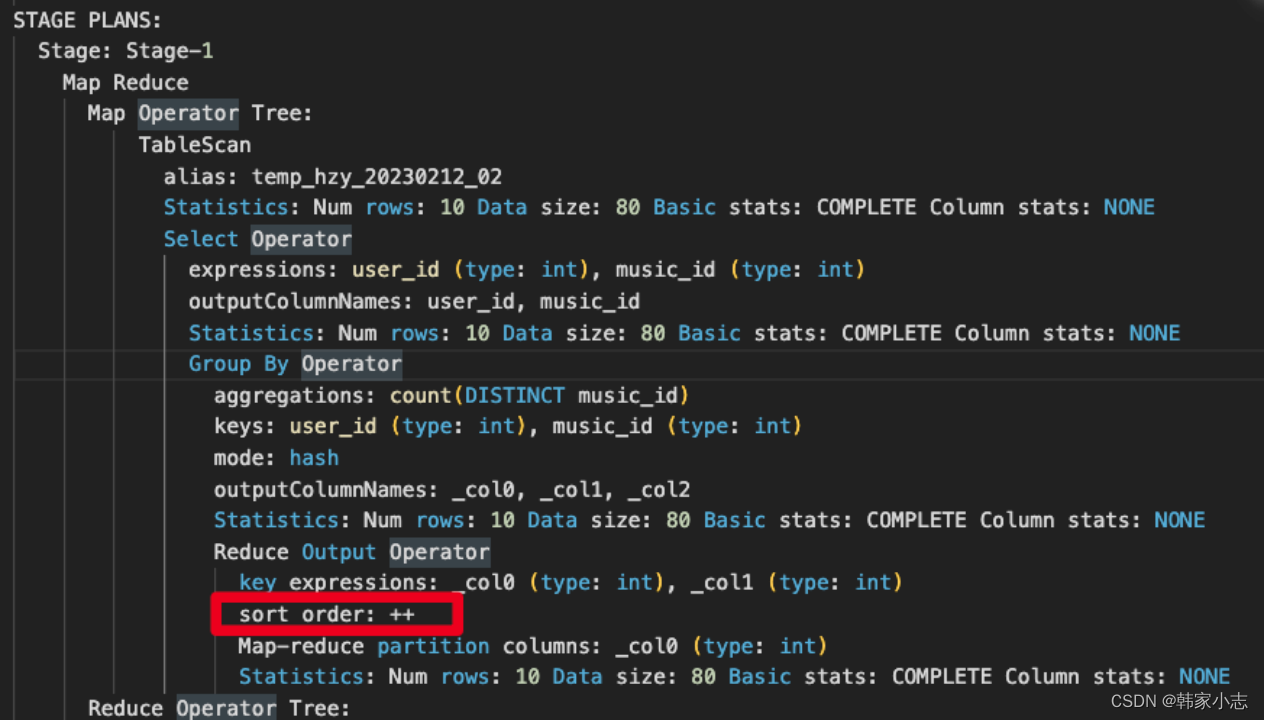
4.2.1group by 分组语句会进行排序吗?
- 会
4.2.2聚合函数sql有哪些Operator?对应MR的过程呢?
查看我们集群的map端聚合
set hive.map.aggr;-- true
为了看一下没有map聚合的情况,我们可以先关闭
set hive.map.aggr=false;explainselect user_id
,count(distinct music_id) num
from bi_temp.temp_hzy_20230212_02
where user_id <>4groupby user_id
;
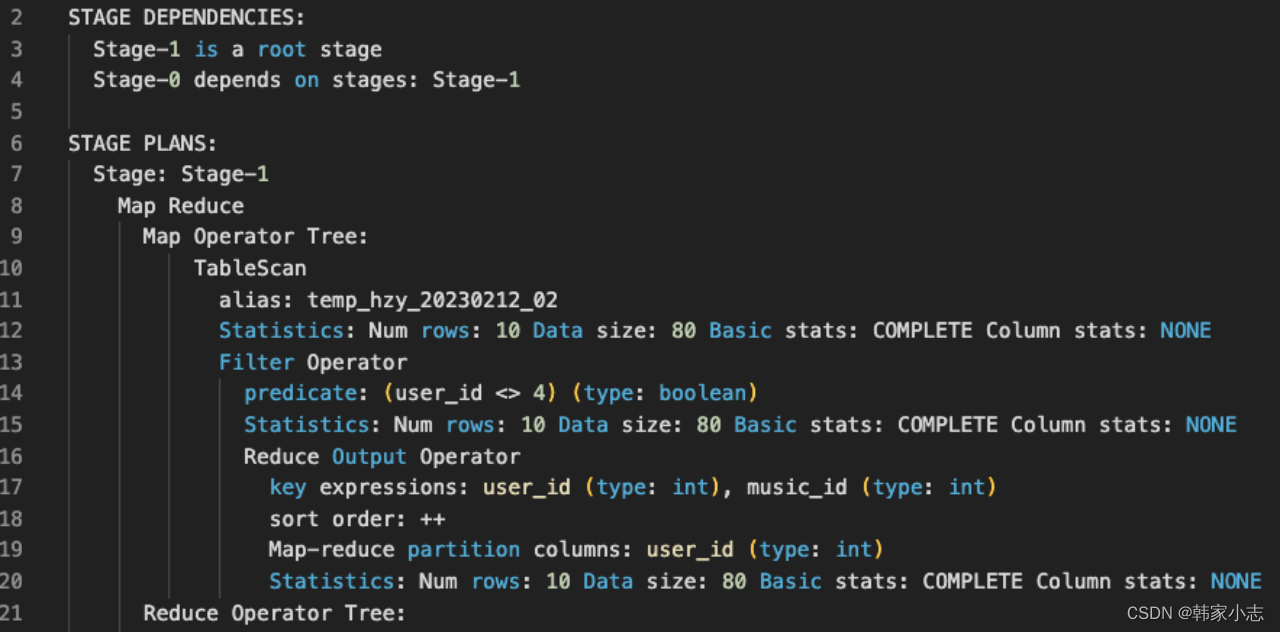
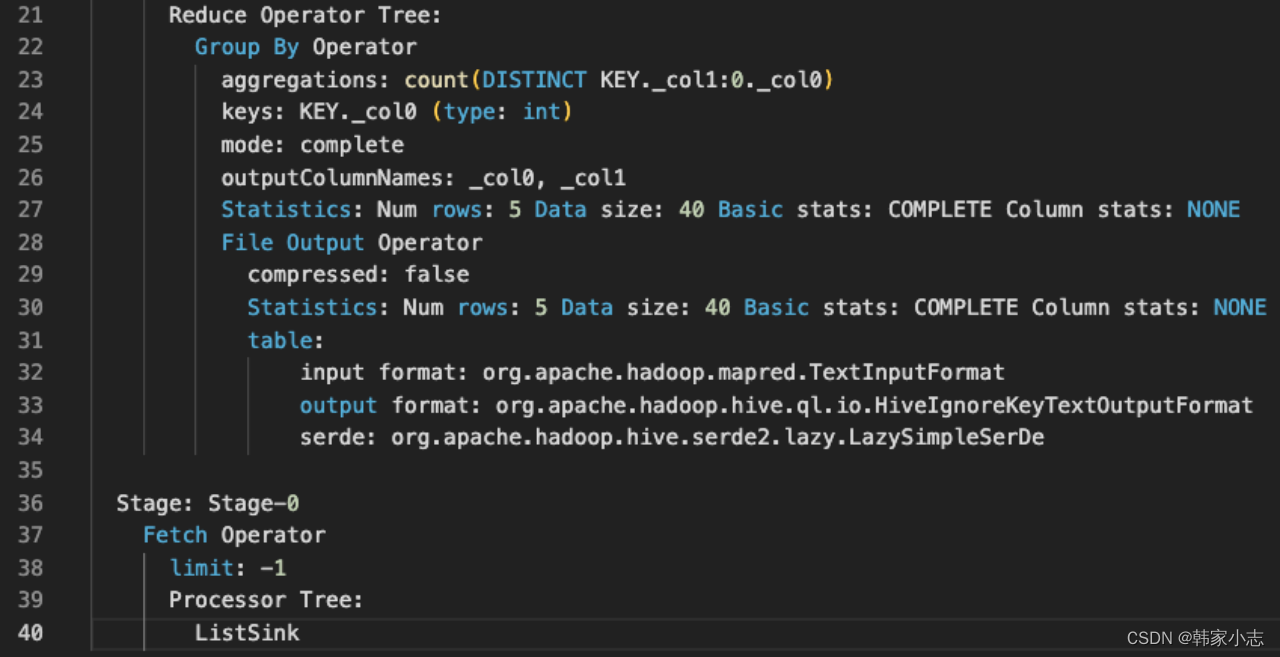
我们可以画出: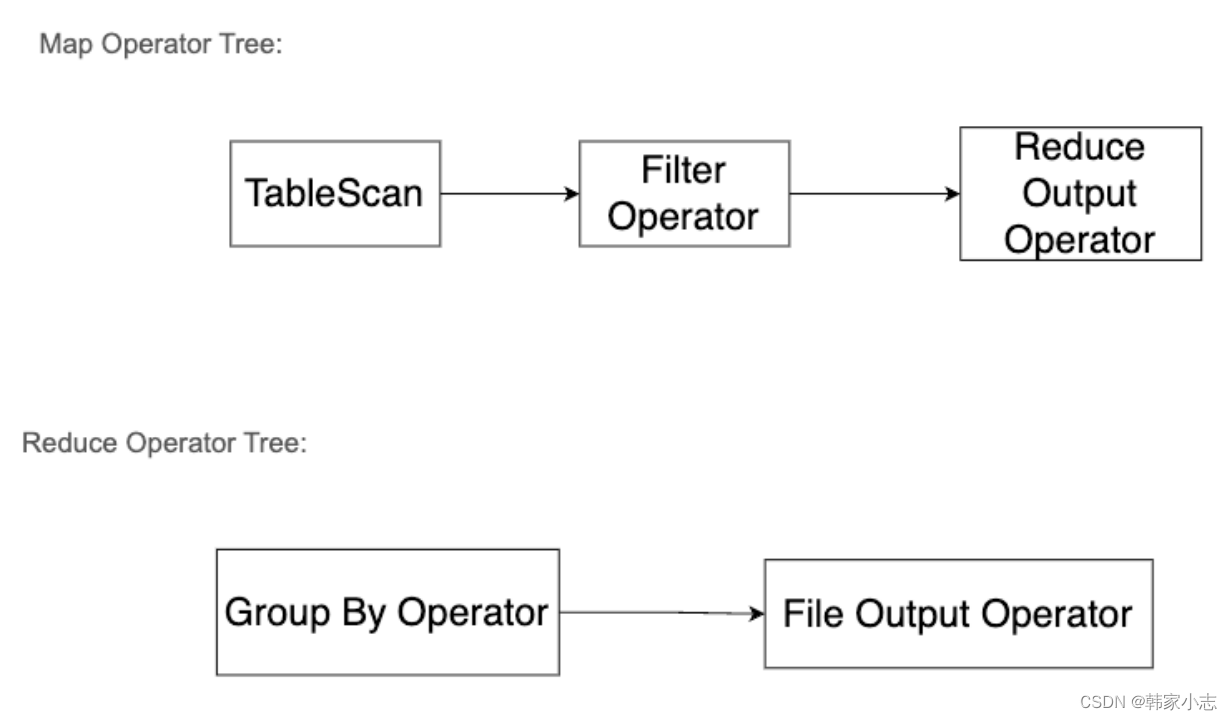
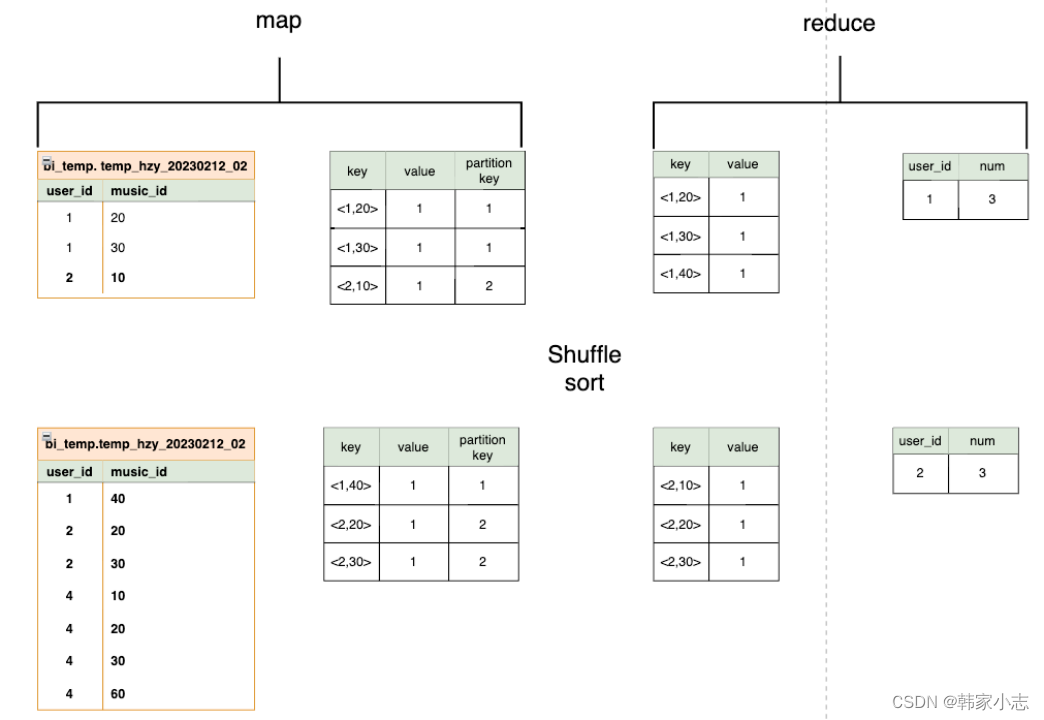
- 如果关闭map端聚合,不考虑Map阶段的Hash GroupBy - 只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作为reduce的key,在reduce阶段保存LastKey即可完成去重:- Hive 在处理 COUNT 这种全聚合计算时,会忽略用户指定的 Reduce Task 数,强制使用 1 个 Reduce,也就是上图中的reduce只有一个~~那么如果数据量大我们就需要考虑优化了
- 如果开启map端聚合hive.map.aggr=true,并生效,则map端有Group By Operator,从而减少数据量。
4.2.3针对count distinct 我们怎么优化?
- 假设现在有个需求: - 每天统计当月的活跃用户数——“当月活跃用户数”(当月访问过app就为活跃用户)
-- 很容易就写出selectcount(distinct uuid)as mau
from detail_sdk_session t
where t.partition_date >='2023-02-01'and t.partition_date <='2023-02-28';
- 好像有点不对? - 结合之前聊的,所有的uuid都会被分配给1个reduce- 所以我们需要考虑的可能是怎么去增大这个reduce数~很明显其实这里调整reduce个数的参数已经不生效了~只能去改写sql- 方法一
1.每天去重到细粒度的(日),再聚合到粗粒度(月)
selectcount(distinct uuid)from(select partition_date,uuid
from detail_sdk_session t
where t.partition_date >='2023-02-01'and t.partition_date <='2023-02-28'groupby partition_date,uuid
)t
;
- 方法二
2.先聚合到细粒度的(同一特征),再聚合到粗粒度(所有)
2.1selectsum(mau_part) mau
from(select substr(uuid,1,3) uuid_part -- 这里数据量越大,可以切的位数越长,count(distinct substr(uuid,4))as mau_part
from detail_sdk_session
where partition_date >='2023-02-01'and partition_date <='2023-02-28'groupby substr(uuid,1,3),hash(uuid)%50) t
;
- 方法三
2.2-- 第三层 :对所有分组进行求和。selectsum(s.mau_part) mau
from(-- 第二层 :按照标记进行分组,统计每个分组下uuid的个数。select tag
,count(1) mau_part
FROM(-- 第一层 :对uuid进行去重,并为去重后的uuid打上整数标记。select uuid
,cast(rand()*100asint) tag -- 为去重后的uuid打上标记,这里数据量越大,可以标记范围越大from detail_sdk_session
where partition_date >='2023-02-01'and partition_date <='2023-02-28'groupby uuid -- 通过GROUP BY,保证去重) t
groupby tag
) s
;
- 如果多个呢?实际工作中我们经常会碰到多列 count(distinct),那这时候怎么优化呢?再讲下去就跑题了,大家可以自己思考一下
- 可以思考 union all + group by + row_number + 普通的聚合函数 代替所有的count(distinct)
4.3表连接的执行计划
4.3.1表连接的SQLjoin 语句会过滤 null 的值吗?
explainselect t1.follower_id
,t2.music_id
from bi_temp.temp_hzy_20230212_01 t1
join bi_temp.temp_hzy_20230212_02 t2
on t1.user_id=t2.user_id
;
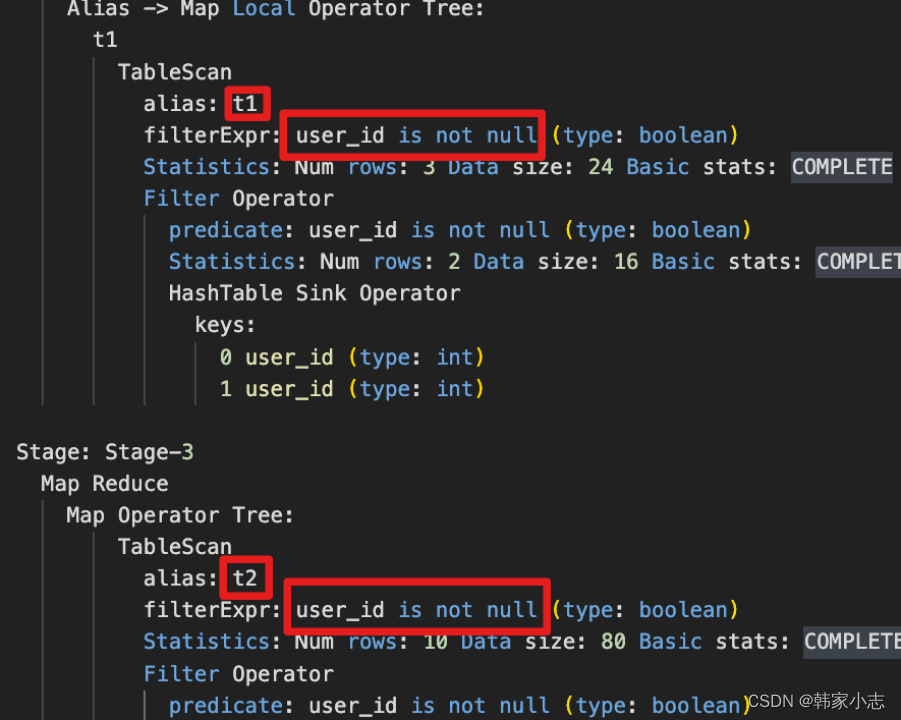
- is not null 这样一行,说明 join 时会自动过滤掉关联字段为 null 值的情况
- left join 呢?full join呢? - left join 或 full join 是不会自动过滤的,大家可以自行尝试下。
4.3.2join有哪些Operator?对应MapReduce的过程呢?
查看我们集群的mapjoin
set hive.auto.convert.join;-- trueset hive.mapjoin.smalltable.filesize;-- 25000000
为了看一下CommonJoin的情况,我们可以先关闭
set hive.auto.convert.join=false;explainselect t1.follower_id
,t2.music_id
from bi_temp.temp_hzy_20230212_01 t1
join bi_temp.temp_hzy_20230212_02 t2
on t1.user_id=t2.user_id
;
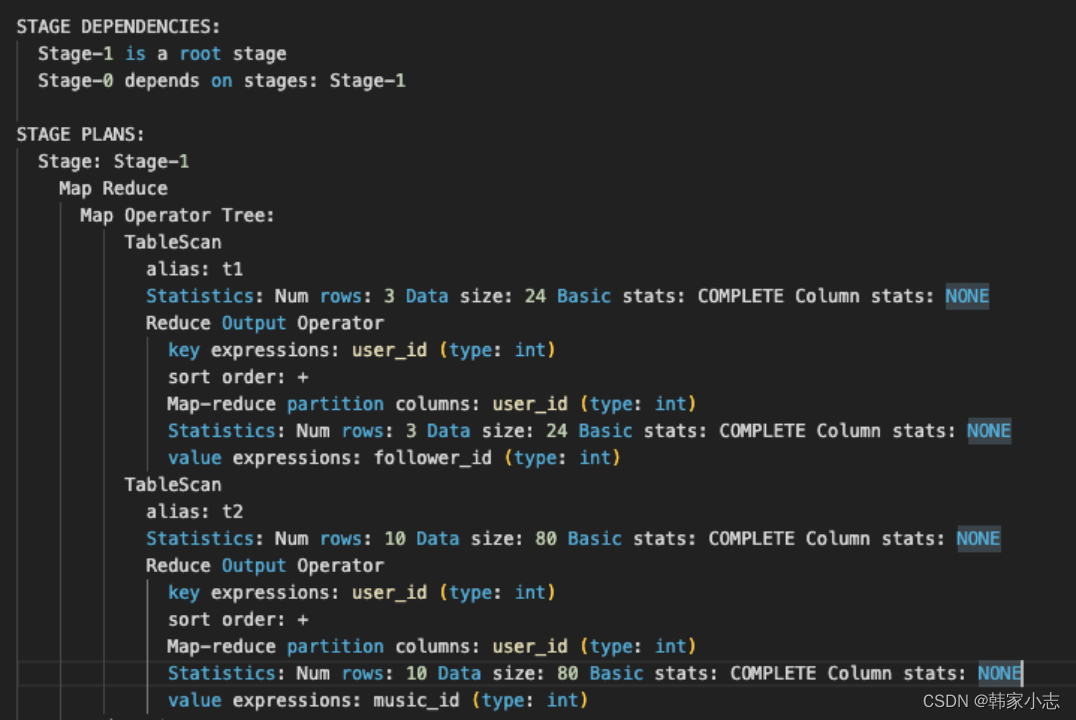
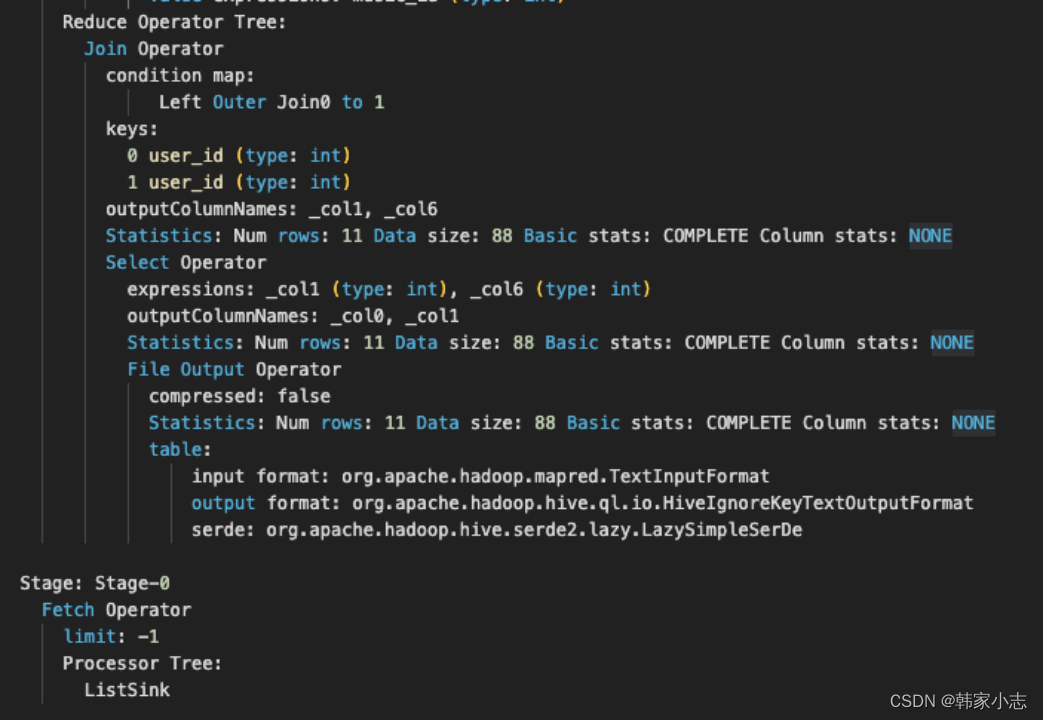
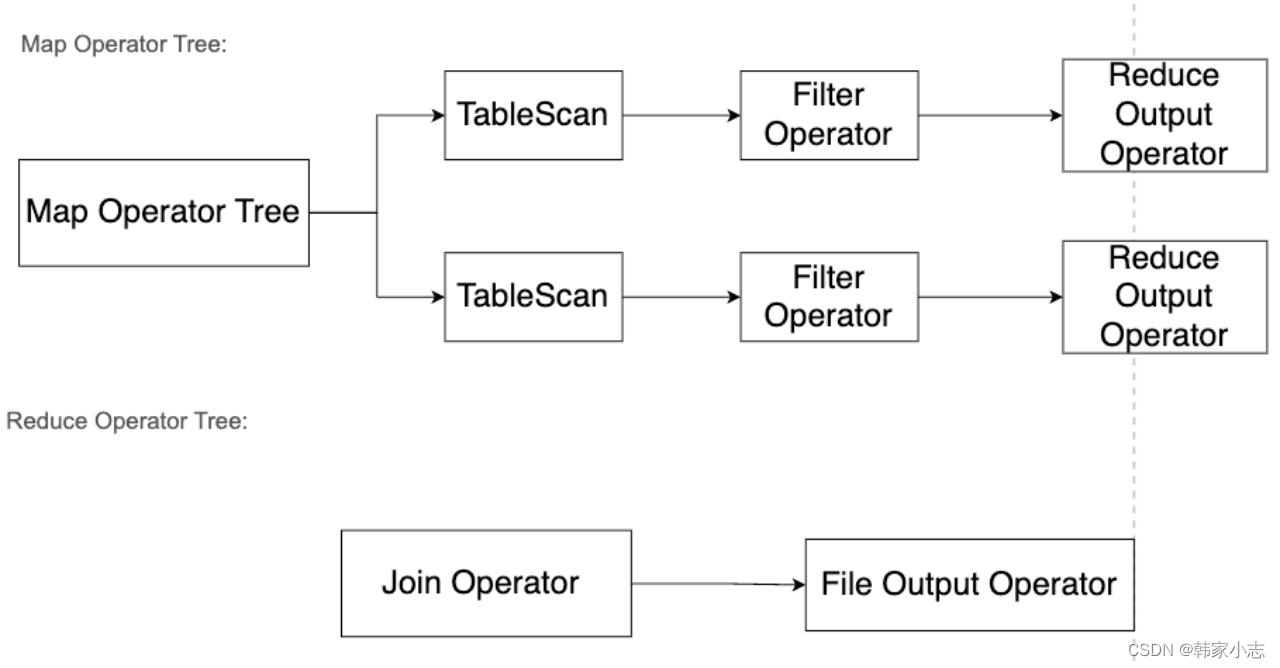
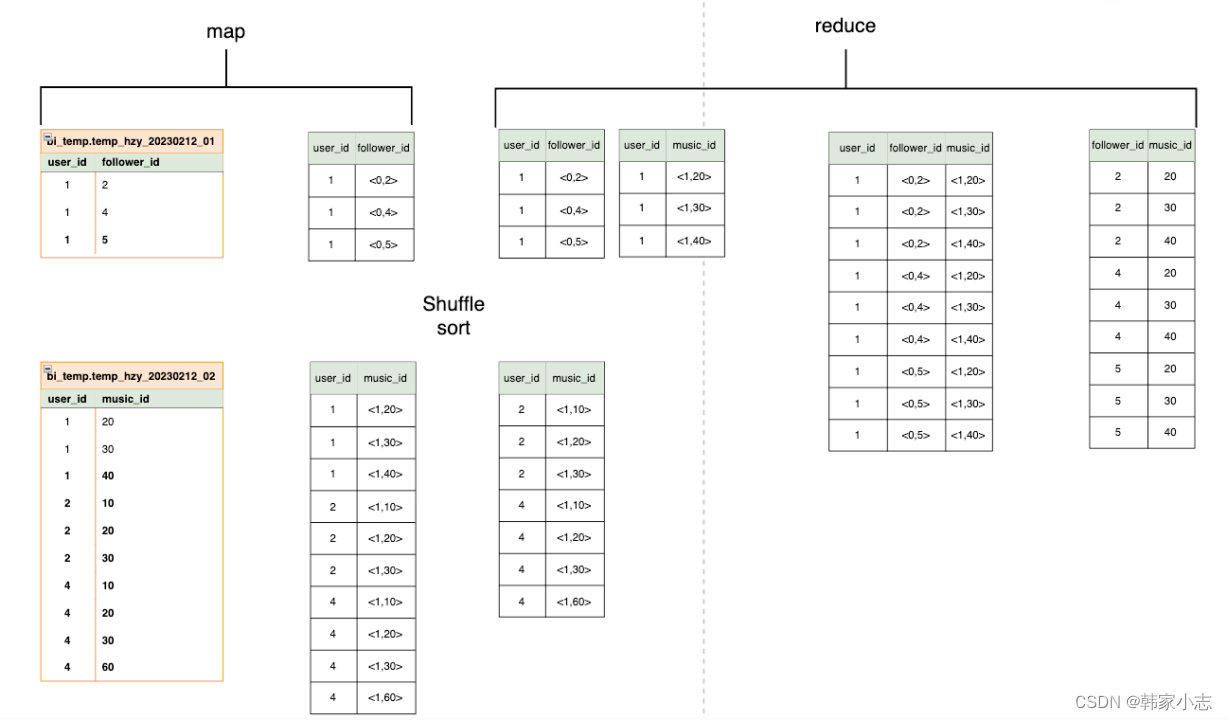
- map中两张表的相同的key的数据进入到一个reduce,但是reduce不知道每行的数据是表a的还是表b的,所以表标号0和1,来进行区分。
- set hive.auto.convert.join; 这个参数默认是true。 - 如果一个表小于某个值,则会进行缓存,就是MapJoin的原理,不会在reduce中join。
- 不知道大家有没有一种感觉,很多优化都是针对io的优化,尽量减少shuffle,减少数据传输,然后利用 并行处理,充分发挥hadoop特性分而治之~
- 所以大家写sql的时候应该尽量去减少reduce端join的数据量~
4.3.3表连接的字段类型不同隐式转换
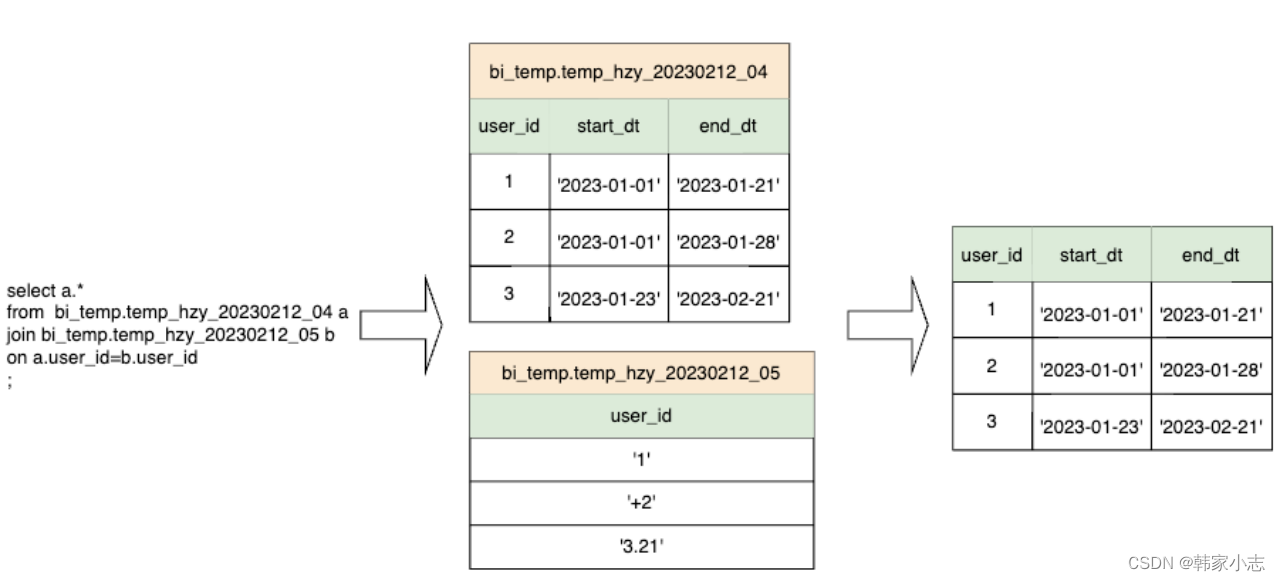
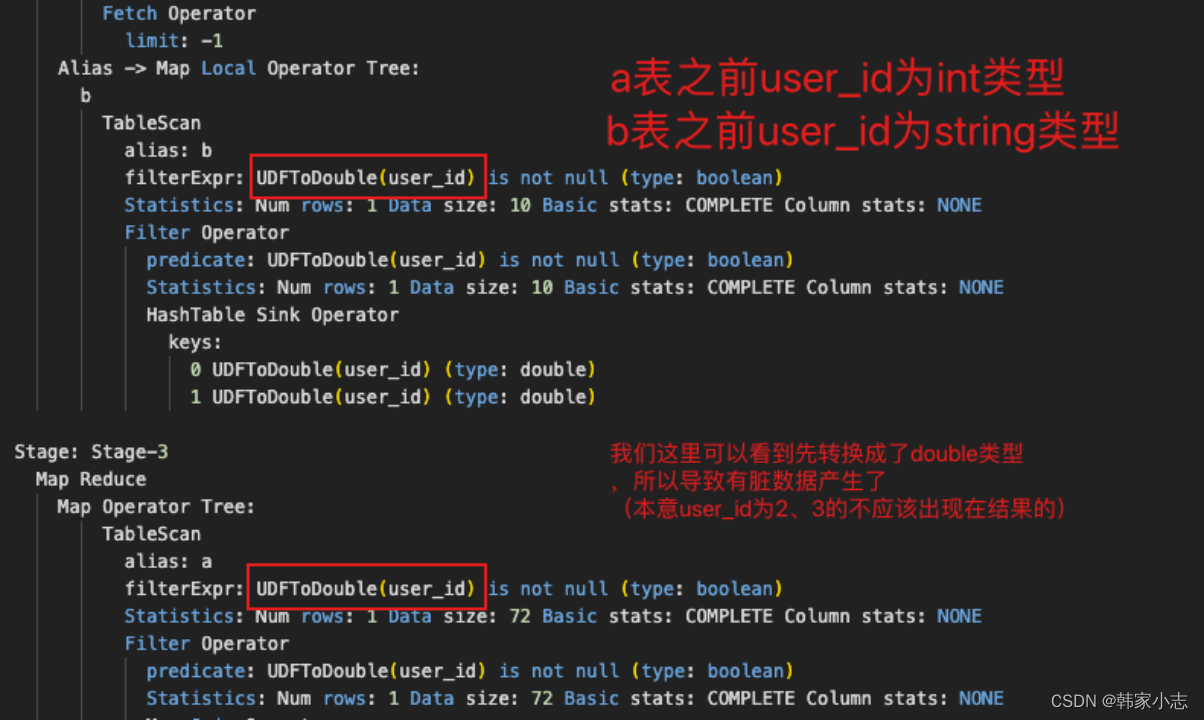
- 从执行计划我们可以看到转换成了double类型,那么就和我们想要的数据不一样了
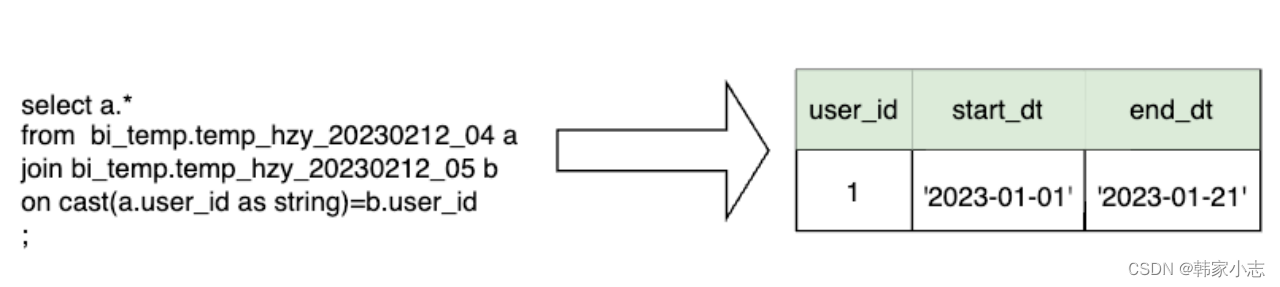
- 因此我们可以考虑都显式转换成string类型
4.4开窗函数的执行计划
4.4.1开窗函数sql有哪些Operator?对应MapReduce的过程呢?
explainselect user_id
,device_type
,row_number()over(partitionby follower_id orderby music_id) rk
from bi_temp.temp_hzy_20230212_03
;
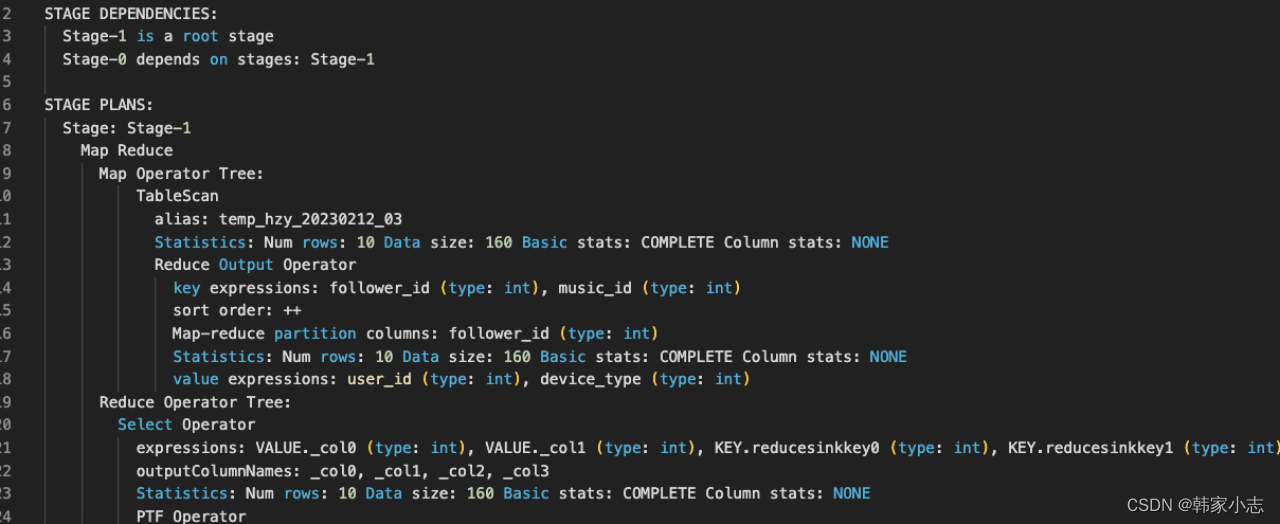
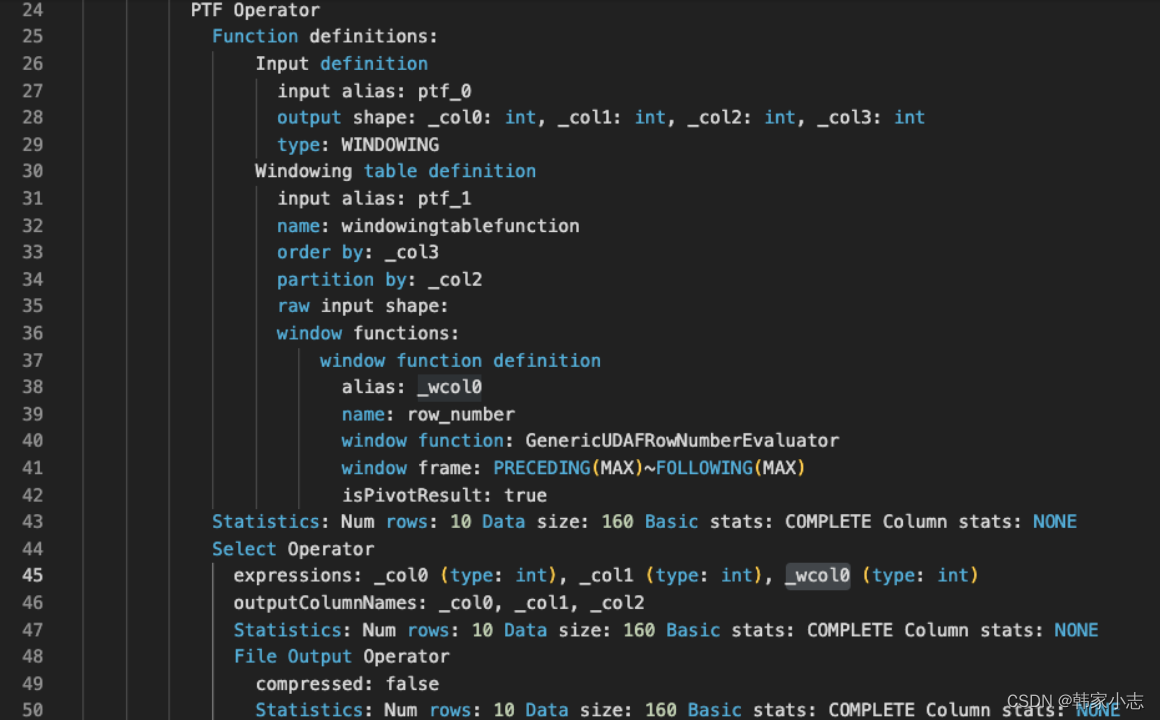
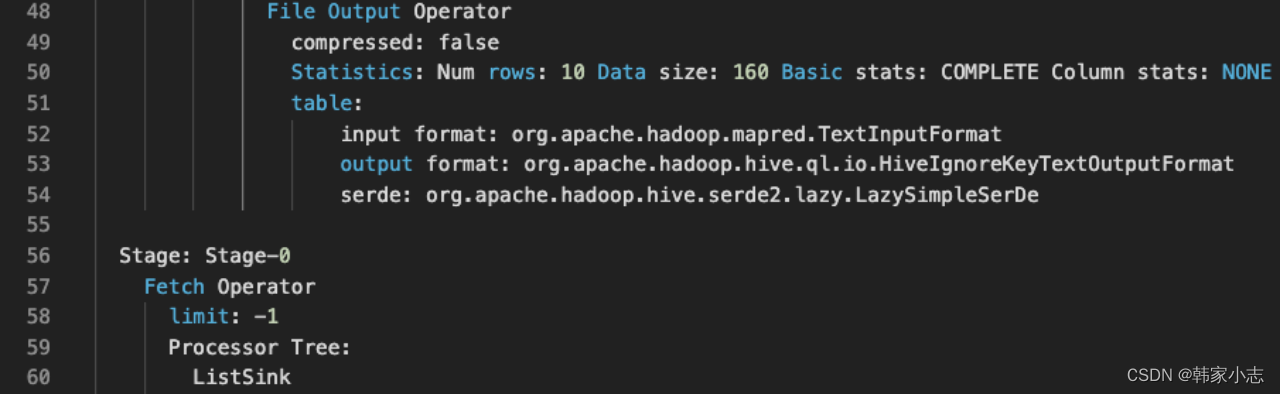
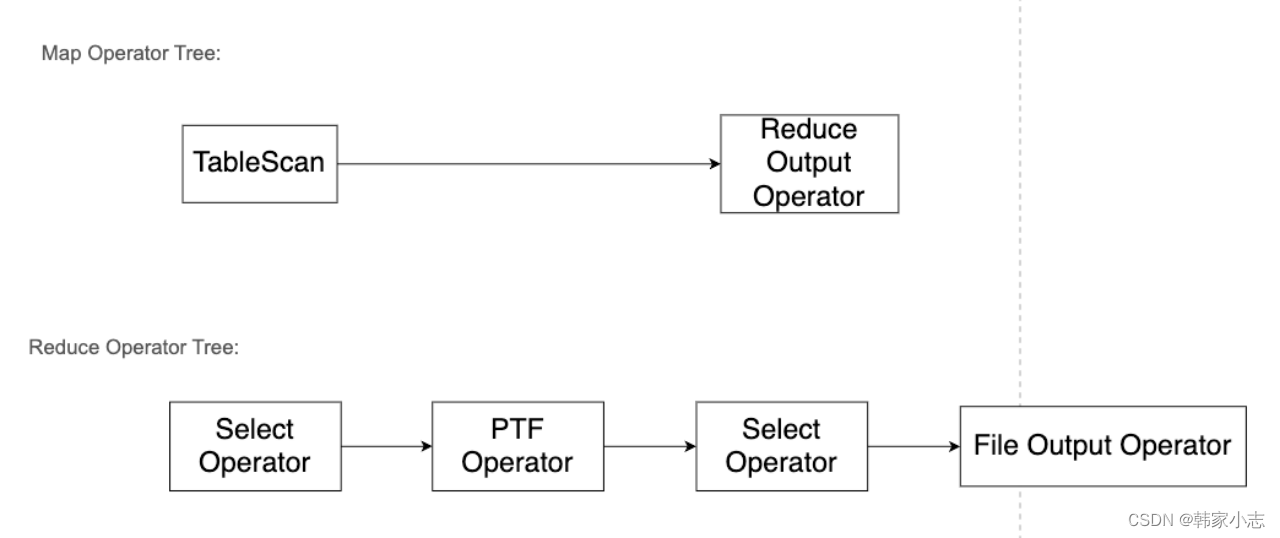
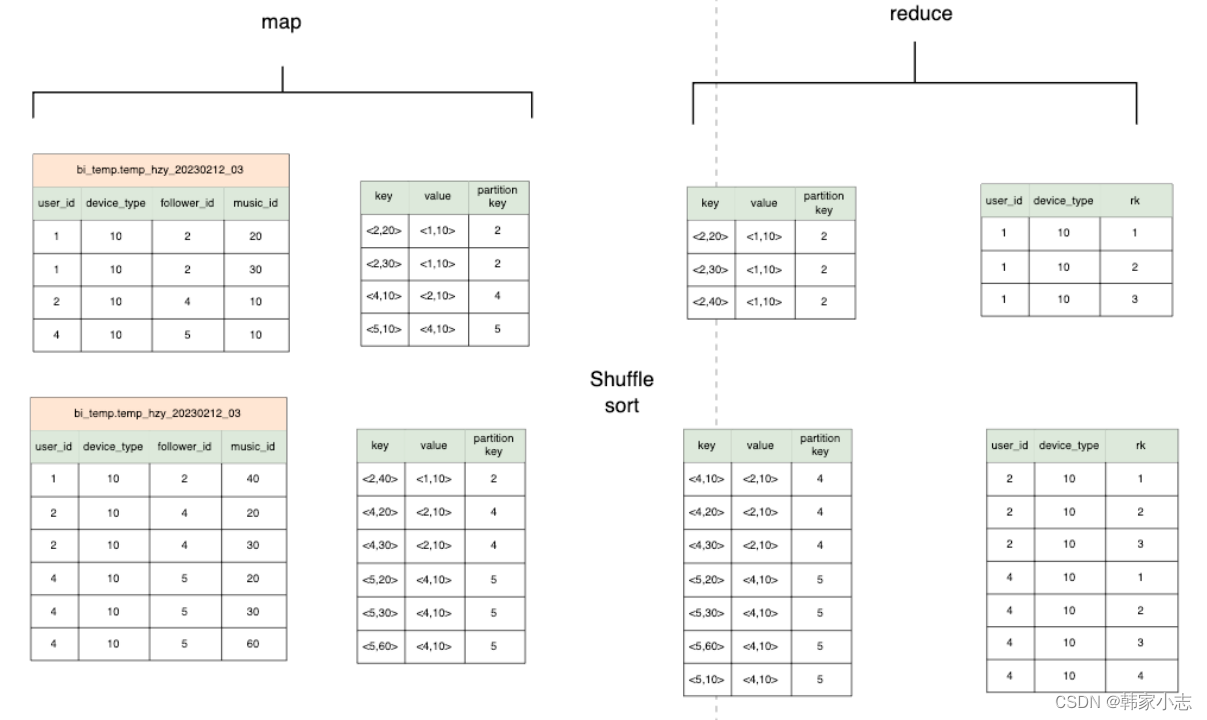
- map端输出row_number() over内的两个参数当作key,select 的字段 当作value
- row_number() over内的两个参数都要进行排序。
- 所以我们有多个开窗的时候,应该尽量让over内的两个参数 保持一致
4.4.2开窗合函数SQL的优化
explainselect user_id ,device_type,follower_id,music_id
,row_number()over(partitionby follower_id
orderby music_id,user_id)as rk1
,row_number()over(partitionby follower_id
orderby device_type)as rk2
,sum(user_id)over(partitionby follower_id
orderby music_id)as s1
from bi_temp.temp_hzy_20230212_03 ;
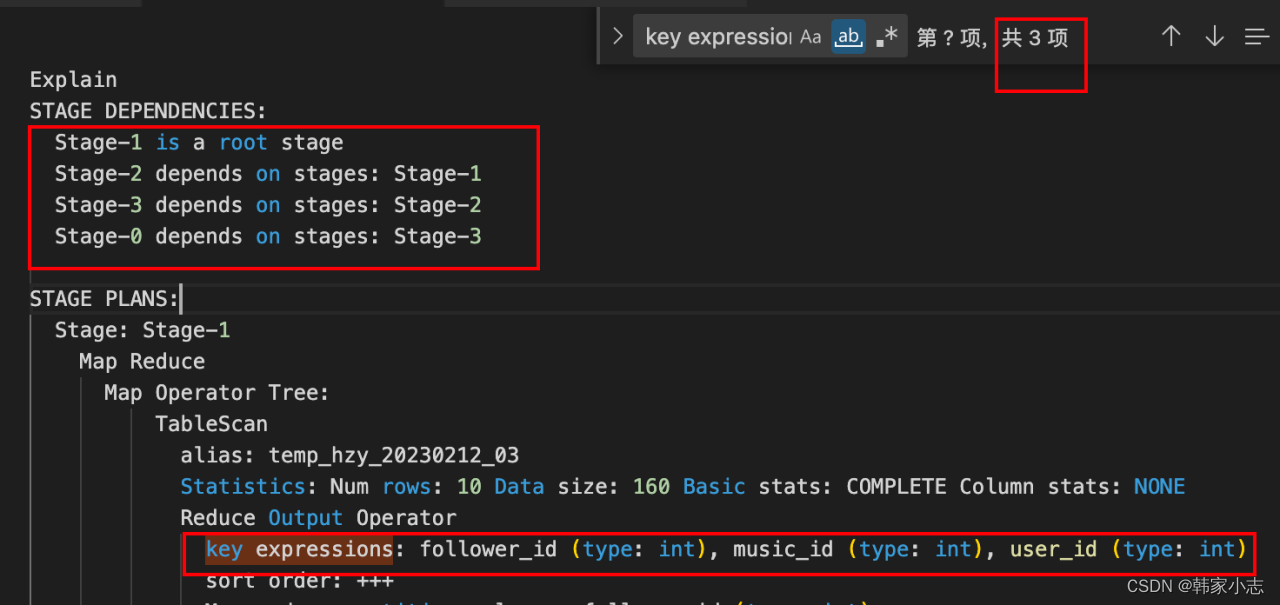
- 似乎很容易就能想到优化就是把 s1 这里的order by 字段 和 rk1 保持一直
- 当我们写出来时会报错 SemanticException Range based Window Frame can have only 1 Sort Key
- 我们也知道 - 不指定窗口时,不排序默认第一行到最后一行,排序默认第一行到当前行- 指定窗口时 --rows between 起始位置 and 结束位置
- 所以似乎我们指定窗口,就不会报错了~又优化了一下sql,简直太美了
explainselect user_id ,device_type,follower_id,music_id
,row_number()over(partitionby follower_id
orderby music_id,user_id)as rk1
,row_number()over(partitionby follower_id
orderby device_type)as rk2
,sum(user_id)over(partitionby follower_id
orderby music_id,user_id
rowsbetweenunboundedprecedingandcurrentrow)as s1
from bi_temp.temp_hzy_20230212_03
;
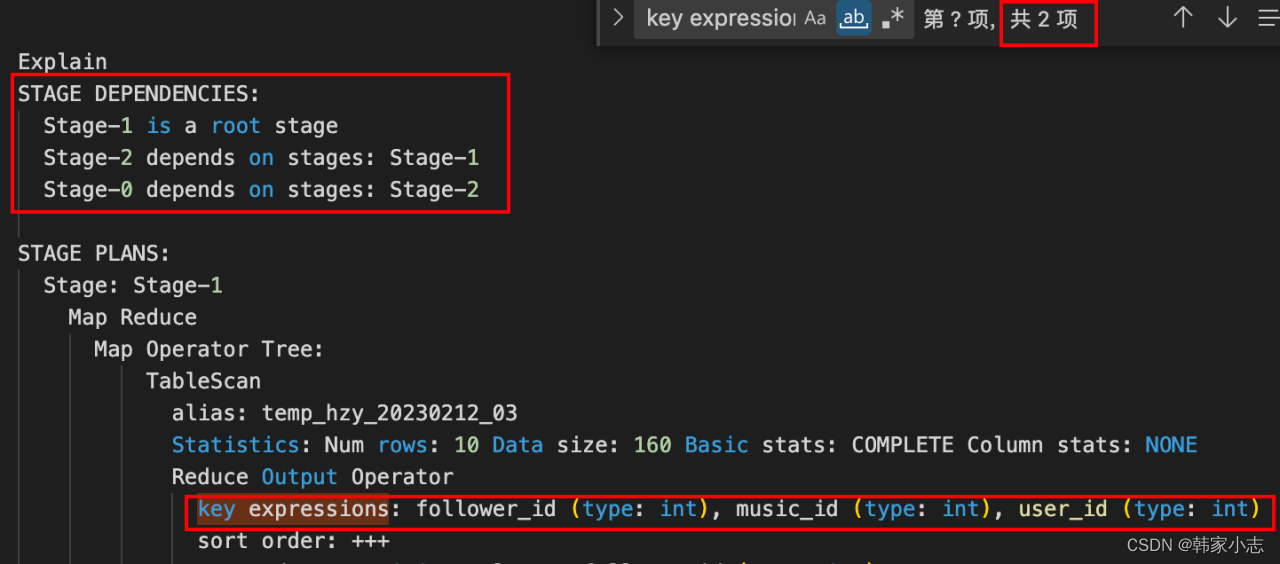
- 从结果看发现数据表现也是一致的~~
- 那么会不会有坑呢??? - 答案是也许有的
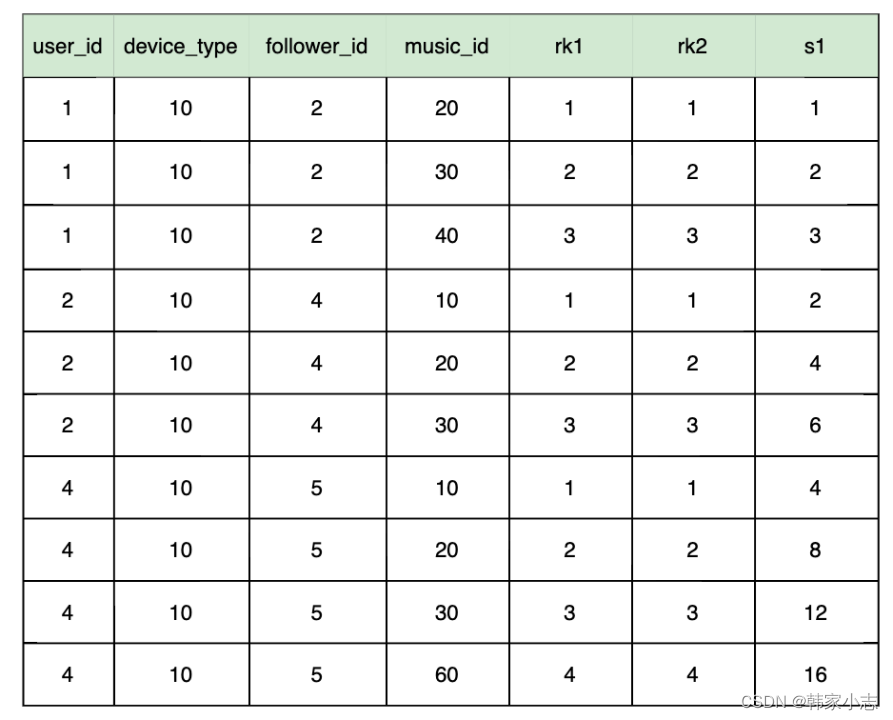
4.4.3开窗合函数SQL的优化坑点
explainselect user_id ,device_type,follower_id,music_id
,row_number()over(partitionby follower_id
orderby device_type,user_id)as rk1
,row_number()over(partitionby follower_id
orderby device_type)as rk2
,sum(user_id)over(partitionby follower_id
orderby device_type)as s1
from bi_temp.temp_hzy_20230212_03 ;
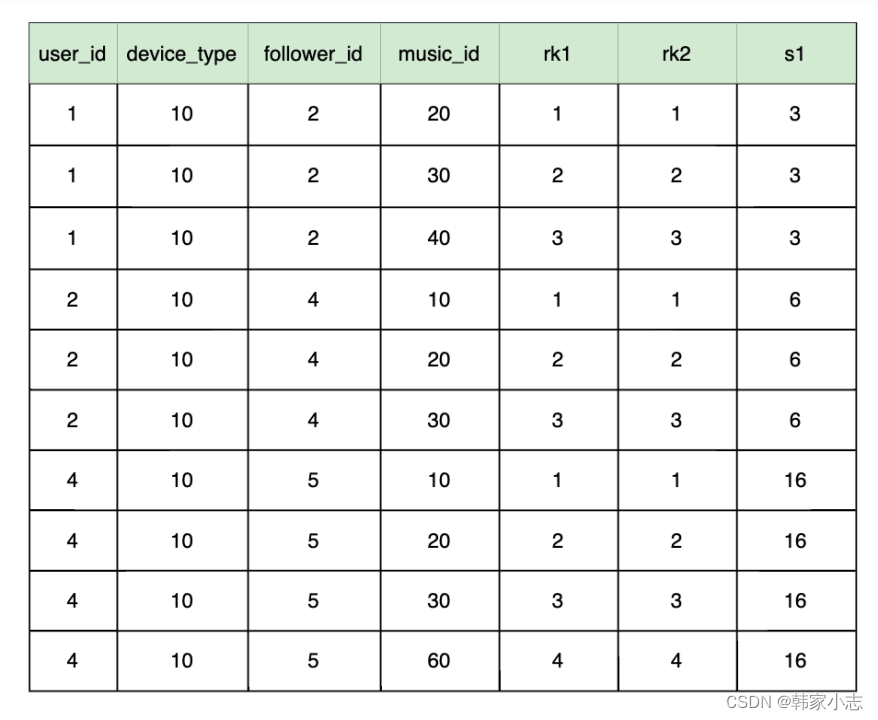
- 这里我们还是一样的思路进行改写,发现结果不一样了~~
explainselect user_id ,device_type,follower_id,music_id
,row_number()over(partitionby follower_id
orderby device_type,user_id) rk1
,row_number()over(partitionby follower_id
orderby device_type)as rk2
,sum(user_id)over(partitionby follower_id
orderby device_type,user_id
rowsbetweenunboundedprecedingandcurrentrow)as s1
from bi_temp.temp_hzy_20230212_03
;
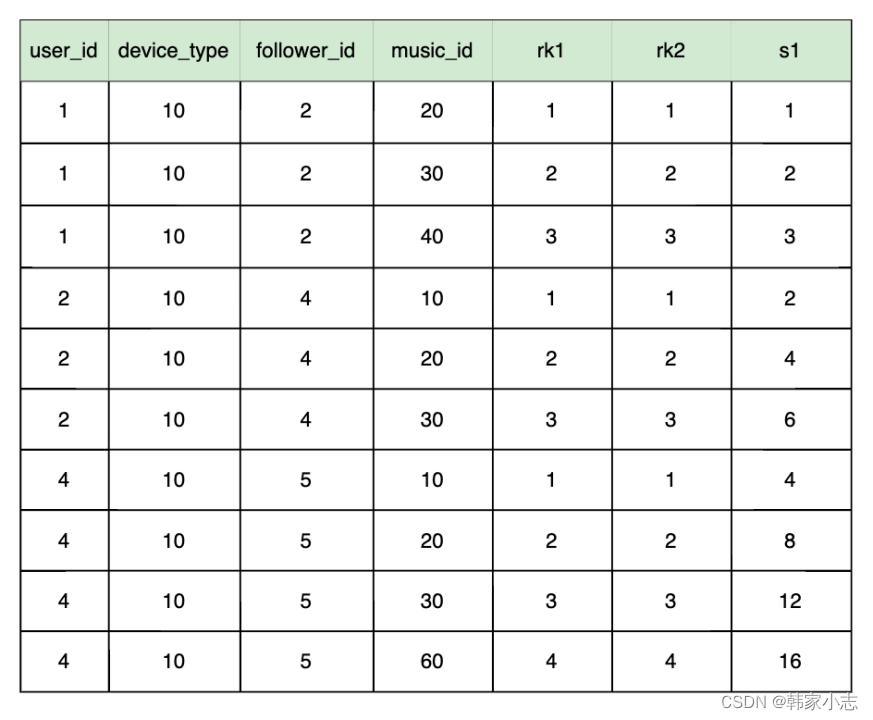
- 这其实可以看出来 - 分组列表,组内按排列顺序求累加和, 每组的相同level(排序字段)分享同一累加值。- 如果level(排序字段)有相同,需要注意是否是你想要的结果,是否需要考虑指定窗口位置
- 所以,优化也要考虑是否等价,以及业务数据~~
4.5子查询过滤和join后过滤性能差别
explainselect t1.*from bi_temp.temp_hzy_20230212_01 t1
join bi_temp.temp_hzy_20230212_02 t2
on t1.user_id=t2.user_id
where t1.follower_id=4;
explainselect t1.*from(select*from bi_temp.temp_hzy_20230212_01
where follower_id=4) t1
join bi_temp.temp_hzy_20230212_02 t2
on t1.user_id=t2.user_id
;
- 有人说第一条sql执行效率高,因为第二条sql有子查询,子查询会影响性能;
- 有人说第二条sql执行效率高,因为先过滤之后,在进行join时的条数减少了,所以执行效率就高了。
- 到底哪条sql效率高呢,我们直接在sql语句前面加上 explain,看下执行计划
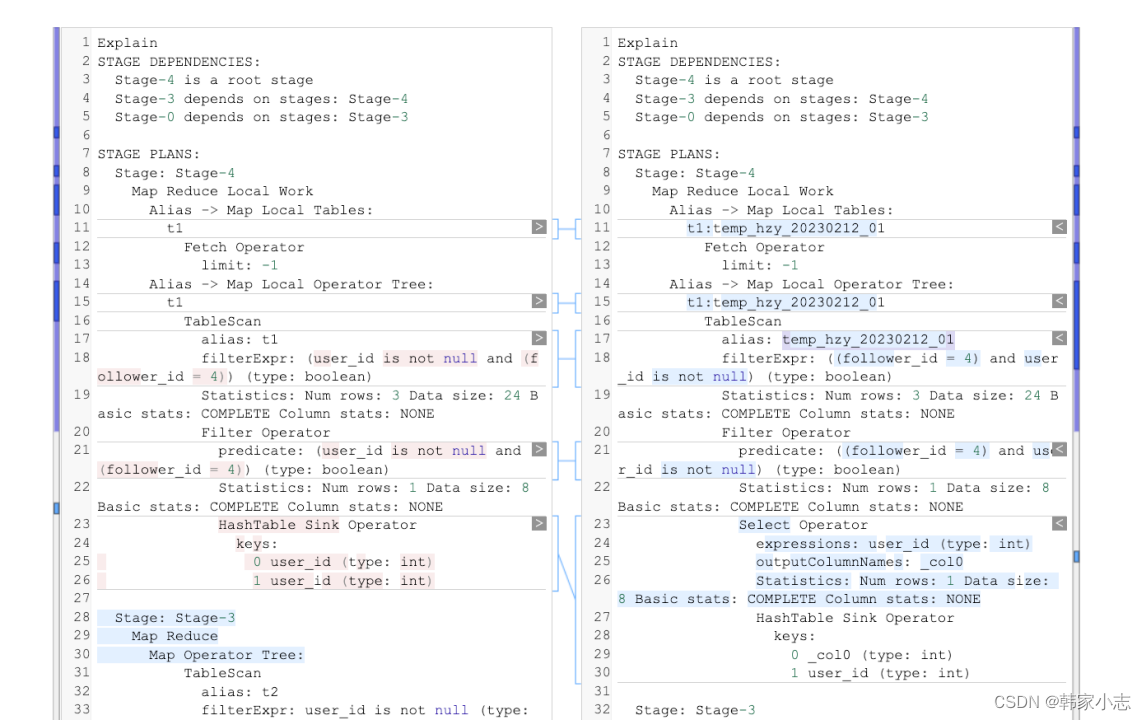
- 对比一下发现除了表别名不一样,其他的执行计划完全一样,都是先进行 where 条件过滤,在进行 join 条件关联。
- 结论:说明 hive 底层会自动帮我们进行优化,所以这两条sql语句执行效率是一样的。
- 但是不同的版本不同的优化器可能会导致不一样的哦~所以建议从写法上就进行规范(先过滤~),所以这也是我比较喜欢代码中少写*,只写需要的字段的原因~(哪怕有列裁剪等优化)
4.6真实的HiveSql执行顺序
explainselect t1.follower_id
,count(t1.user_id)as cnt
,sum(t2.music_id)as sum_f
from bi_temp.temp_hzy_20230212_01 t1
leftjoin bi_temp.temp_hzy_20230212_02 t2
on t1.user_id=t2.user_id
where t1.follower_id >2groupby t1.follower_id
having cnt >2orderby sum_f
limit1;
- part1:先看第一部分代表stage之间的依赖关系
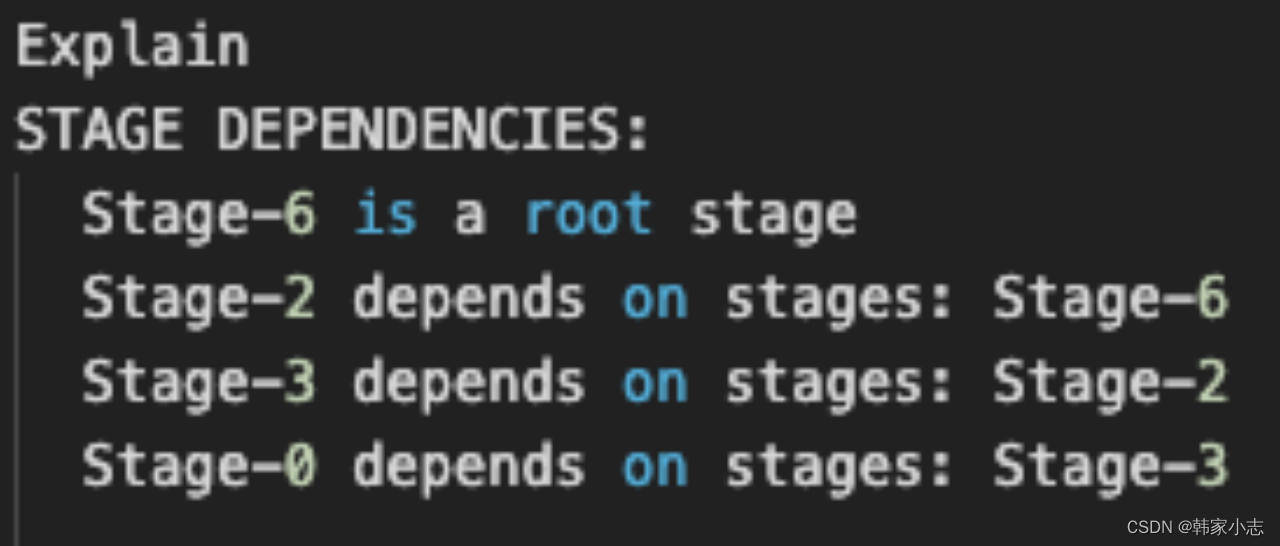

- part2:Stage-6
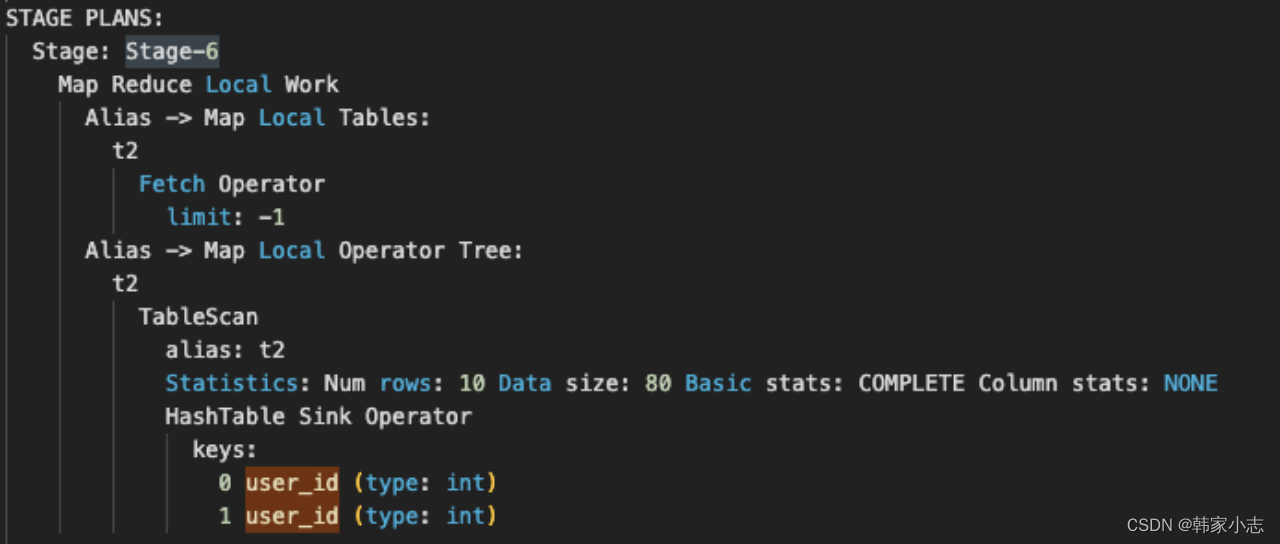
- part3:Stage-2
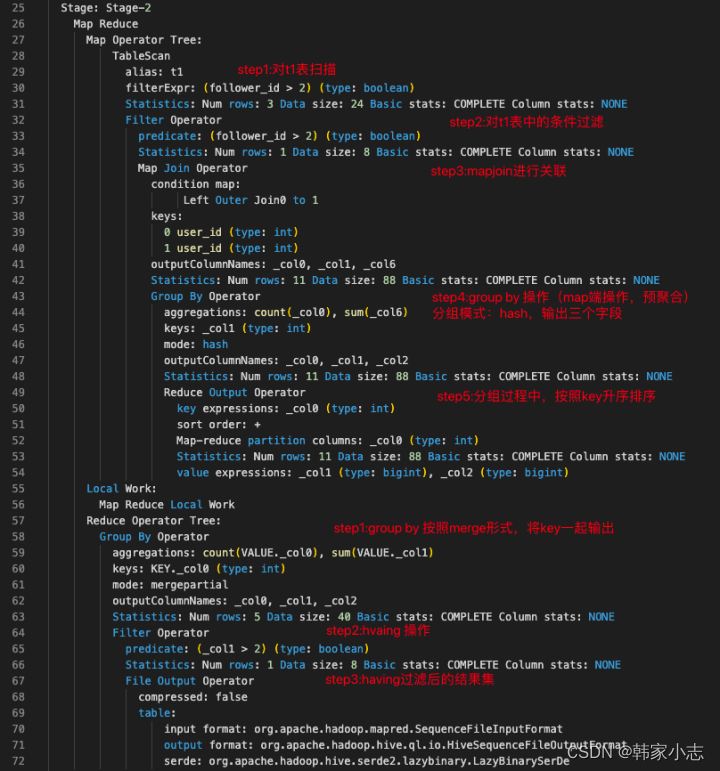
- part4:Stage-3
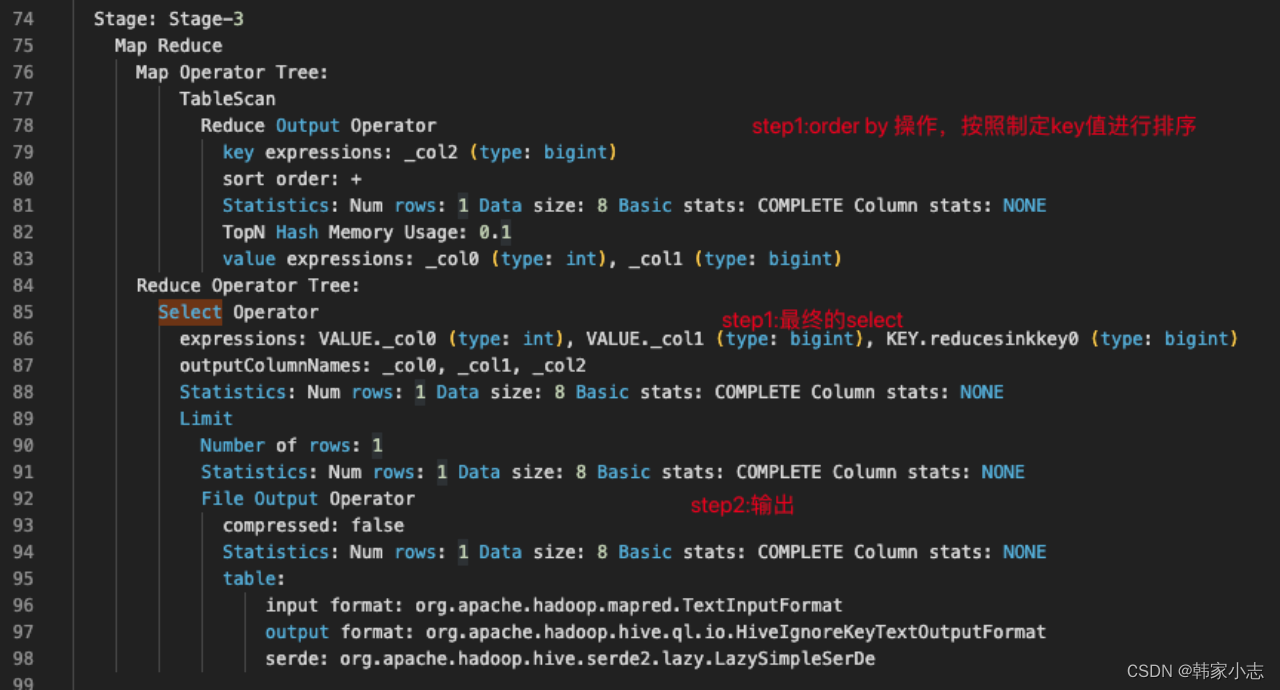
- part5:Stage-0
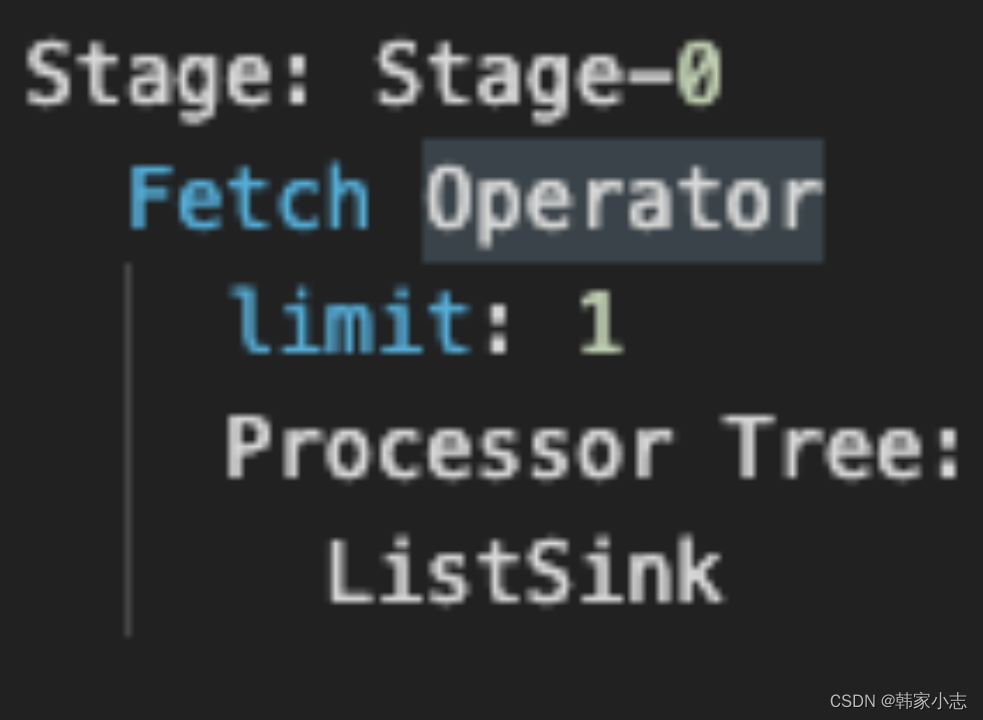
- 结论:from → where → on → join → select(select中的字段与group by只要不一致就会有) → group by → select(为having准备数据,因而having中可以使用select别名) → having → order by → select → limit
- 思考:where 和select 似乎很特殊?为什么? - 可以看到select是很特殊的,不能简单归到哪一步,其实由于谓词下推(将过滤尽可 能地下沉到数据源端),on 和where也会有点特殊
4.7初步定位数据倾斜
- shuffle阶段堪称性能的杀手,为什么这么说,一方面shuffle阶段是最容易引起数据倾斜的;另一方面shuffle的过程中会产生大量的磁盘I/O、网络I/O 以及压缩、解压缩、序列化和反序列化等。这些操作都是严重影响性能的。
4.7.1.数据倾斜
- 并行处理的过程中,某些分区或节点处理的数据,显著高于其他分区或节点,导致这部分的数据处理任务比其他任务要大很多,从而成为这个阶段执行最慢的部分,进而成为整个作业执行的瓶颈,甚至直接导致作业失败。
- 数据倾斜是分布式系统不可避免的问题,任何分布式系统都有几率发生数据倾斜。
- 二八原理,百分之0.2的人干了百分之99.8的活~进度卡在了99.99%~~~
- 但有些小伙伴在平时工作中感知可能不是很明显,这是因为如果一个任务的数据量只有几百万,它即使发生了数据倾斜,所有数据都跑到一台机器去执行,对于几百万的数据量,一台机器执行起来还是毫无压力的,这时数据倾斜对我们感知不大,只有数据达到一个量级时,一台机器应付不了这么多的数据,这时如果发生数据倾斜,那么最后就很难算出结果。
4.7.2.发生阶段
- 2.1 map端:任务读取不可分割的大文件 - 数据文件在进入map阶段之前会进行切分,如果当对文件使用GZIP压缩等不支持文件分割操作的压缩方式时,MR任务读取压缩后的文件时,是对它切分不了的,该压缩文件只会被一个任务所读取,如果有一个超大的不可切分的压缩文件被一个map读取时,就会发生map阶段的数据倾斜。
- 2.2 reduce端:任务中需要处理大量相同的key的数据。 - map到reduce会经过shuffle阶段,在shuffle中默认会按照key进行hash,如果相同的key过多,那么hash的结果就是大量相同的key进入到同一个reduce中,导致数据倾斜。
4.7.3.不同的处理方式
- 3.1空值引发的数据倾斜(直接过滤 or 赋随机数调整hash结果让其进入不同reduce)
- 3.2不同数据类型引发的数据倾斜(转换为string)
- 3.3不可拆分大文件引发的数据倾斜(数据压缩的时候可以采用bzip2和Zip等支持文件分割的压缩算法。)
- 3.4数据膨胀引发的数据倾斜(针对grouping sets/rollups/cubes这类多维聚合的操作,拆分sql,但如果多了可以参数hive.new.job.grouping.set.cardinality 配置的方式自动控制作业的拆解,该参数默认值是30。)
- 3.5确实无法减少数据量引发的数据倾斜 (调内存~)
4.7.4.实战
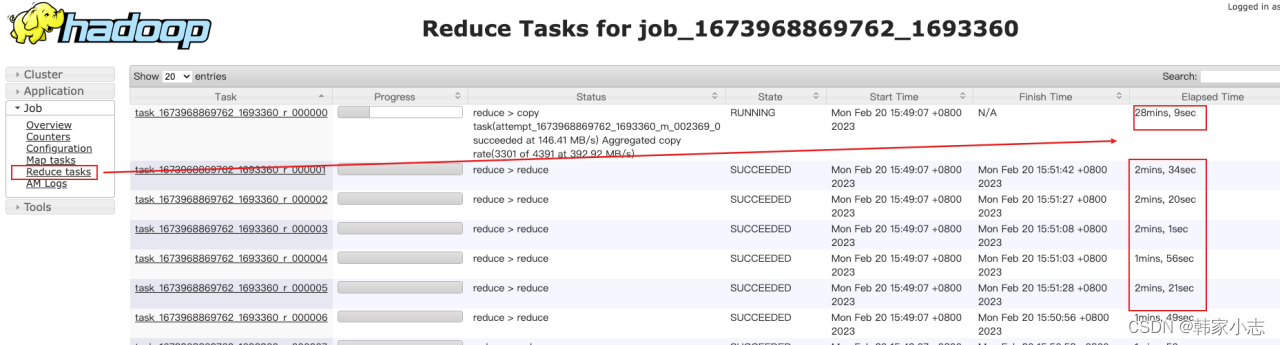
- step1:从右图的日志我们可以 通过时间判断似乎发生了数据倾斜(这里为了复现,没有让执行很长时间,实际执行了2h)


- step2:从yarn上我们看到存在某个 reduce task的时间比其他task 时间长的多, 且该task数据处理量也要大得多,到这里我们基本可以确认的确发生了数据倾斜了 - (1)如果每个 reduce 执行时间差不多,都特别长,不一定是数据倾斜导致的,可能是 reduce 设置过少导致的。- (2)有时候,某个 task 执行的节点可能有问题,导致任务跑的特别慢。这个时候,mapreduce 的推测执行,会重启一个任务。如果新的任务在很短时间内能完成,通常则是由于 task 执行节点问题导致的个别 task 慢。但是如果推测执行后的 task 执行任务也特别慢,那更说明该 task 可能会有倾斜问题。
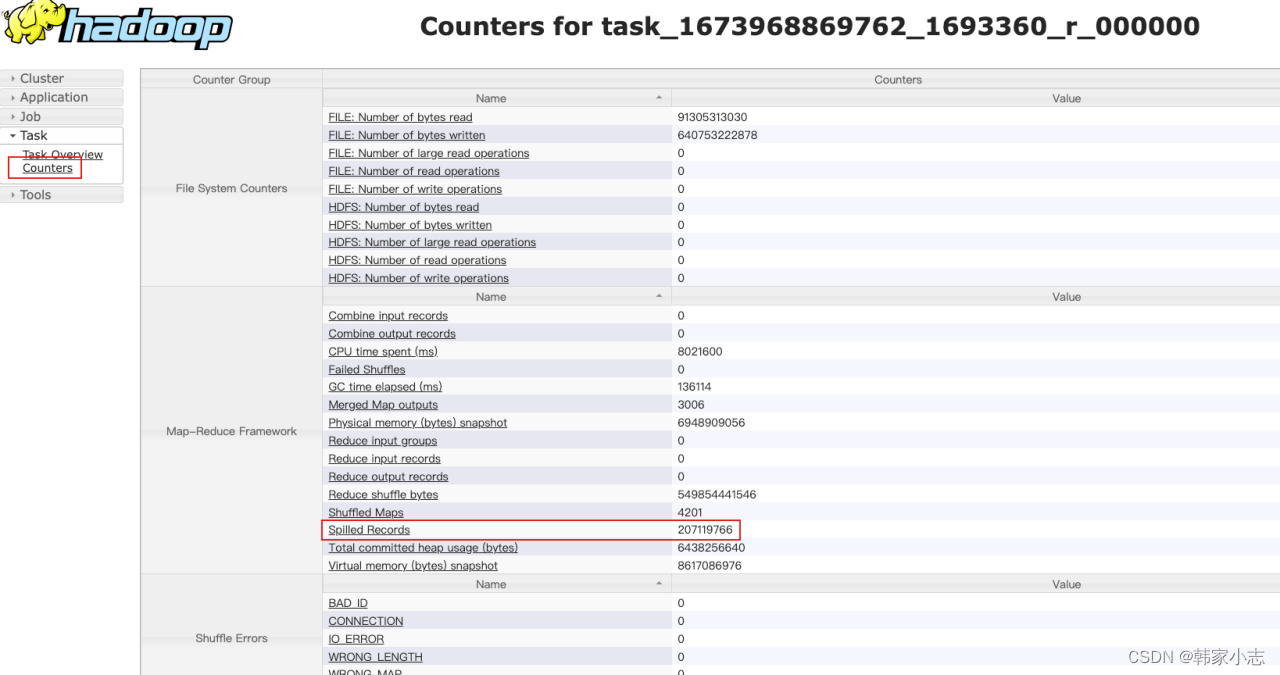
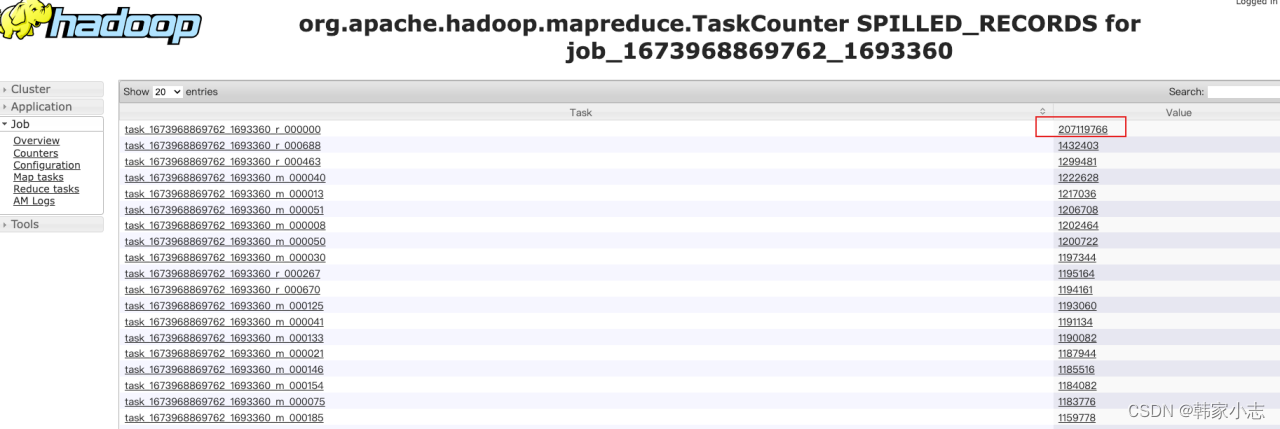
- step3:explain一下,找到对应的stage
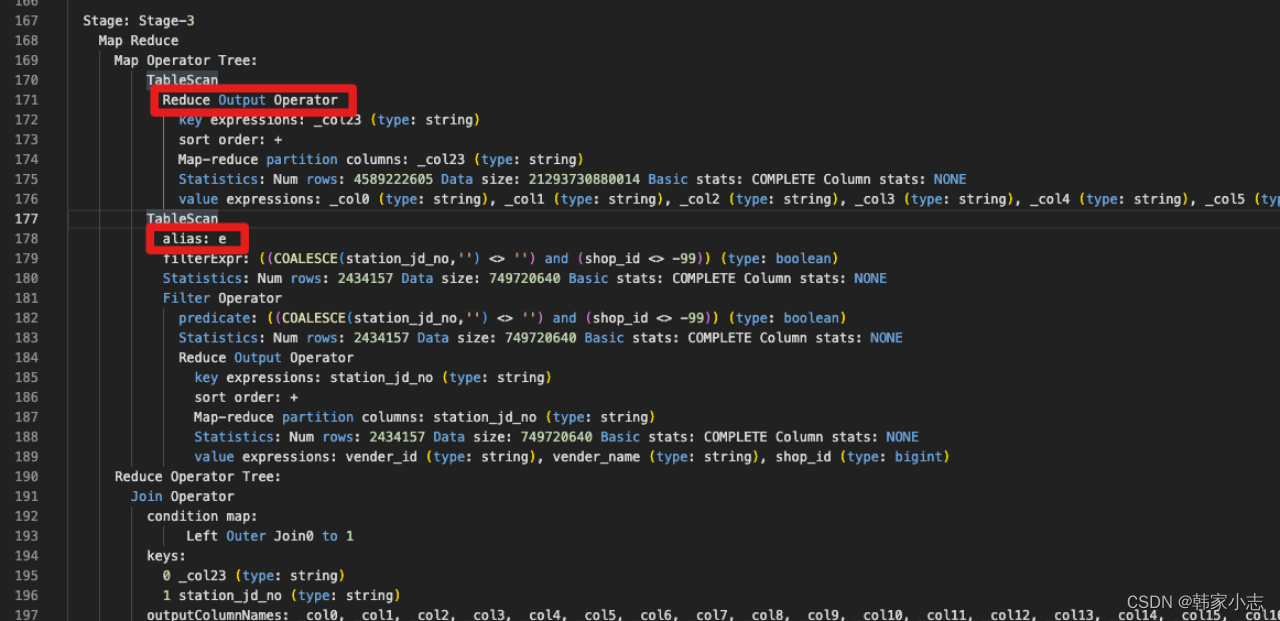
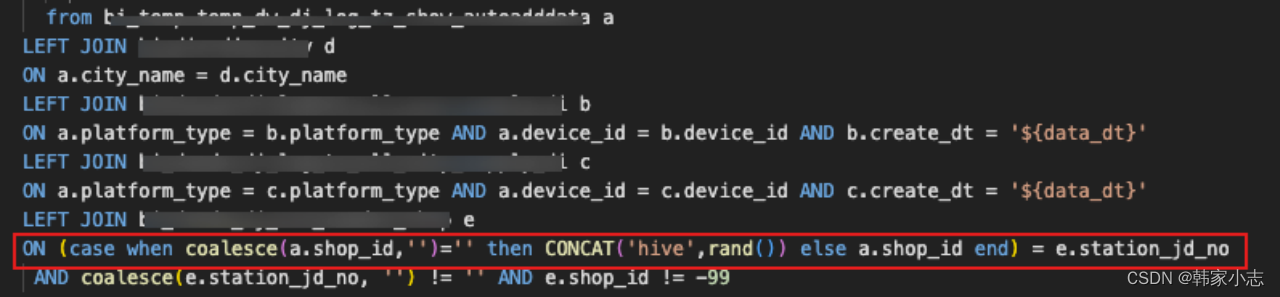
- step4:通过stage描述,找到对应的sql片段
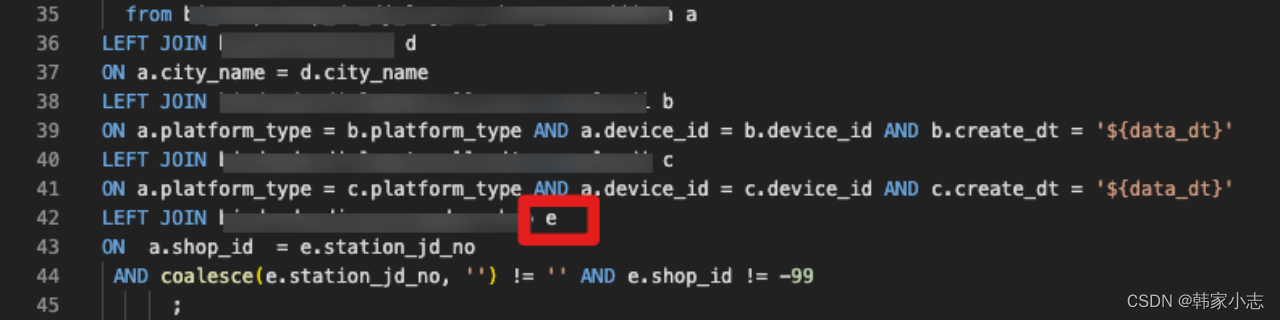
- step5:对a表的数据进行探查,看看是否有可以过滤的大key

- step6:处理该大key,结合sql判断,可以将其加随机数进行随机分布,再执行发现很快就执行完成了

本文转载自: https://blog.csdn.net/qq_46893497/article/details/128778138
版权归原作者 韩家小志 所有, 如有侵权,请联系我们删除。
版权归原作者 韩家小志 所有, 如有侵权,请联系我们删除。