
经过前期讨论,我们决定爬取以下几大公司官网发布的招聘岗位相关信息:
华为 美团 腾讯 字节跳动 联想 菜鸟 阿里巴巴淘天集团 小米
爬虫教程
创建爬虫项目
scrapy startproject 项目名

scrapy genspider example example.com

使用Pycharm打开项目
安装scrapy,selenium,driver
pip install scrapy
pip install selenium
修改settings
- 设置user-agent,取消注释DEFAULT_REQUEST_HEADERS

- ROBOTSTXT_OBEY 设置为False(不遵循)
- 取消注释ITEM_PIPELINES

修改Items
确定好要爬取的数据字段,编写在这里
比如要爬取网址、岗位名、工作地点、工作描述

编写spiders
- 可以先编写要爬取的到底是什么网页,比如,实际上我们的数据来自于京东的岗位详情页面,所以先编写爬取岗位详情页- 查看网页源代码确定爬取哪部分数据- 编写代码定位到要爬取的数据,可以使用浏览器自带的复制xpath
 - 创建selenium模拟浏览器(这里要先安装驱动,我安装的是Edge驱动)selenium环境搭建,浏览器驱动下载教程,超详细!_selenium下载-CSDN博客- 定位到包含数据的标签
- 创建selenium模拟浏览器(这里要先安装驱动,我安装的是Edge驱动)selenium环境搭建,浏览器驱动下载教程,超详细!_selenium下载-CSDN博客- 定位到包含数据的标签list_items = browser.find_elements(by=By.XPATH, value='//*[@id="app"]/div[2]/div') for list_item in list_items: item['job_url'] = response.meta['url'] item['job_name'] = list_item.find_element(by=By.XPATH,value='//*[@id="app"]/div/div[2]/div/div/div[1]').text item['job_description'] = list_item.find_element(by=By.XPATH,value='//*[@id="app"]/div/div[2]/div/div/ul/li[1]/div[2]/p').text ...... - 解决怎么才能爬取到岗位详情页的url(要爬取到详情页url,才能爬取详情页)- 一般是在包含多个岗位的页面中会有href属性,可取出href中的内容,比较简单-
 - 那就可以取出url
- 那就可以取出urlcurrent_job_links=browser.find_elements(by=By.XPATH,value='//li[@class="border-top"]//a[@target="_blank"]')for link in current_job_links: job_path = link.get_attribute("href") job_url = urljoin(self.base_url, job_path) job_links.append(job_url)- 但是现在更多网页是不存在href,而是使用javascript进行跳转,也就是点击卡片之后会新开一个选项卡,因此这里要使用selenium的选项卡管理来实现browser的url变化,从而获得新打开页面的url(如果不切换选项卡,即使模拟单击了卡片,也不能对打开的页面进行爬虫)card_elements=browser.find_elements(By.XPATH,'.//div[@class="position_list_item cursor_pointer"]')for card_element in card_elements: # 单击卡片元素 browser.execute_script("arguments[0].click();",card_element) # 等待新页面加载完成 wait.until(EC.number_of_windows_to_be(2)) # 切换到新的窗口 browser.switch_to.window(browser.window_handles[1]) # 获取新页面的URL current_url2 = browser.current_url current_url_list.append(current_url2) browser.close() - 最后实现翻页功能- 大部分网页都是通过url的变化实现翻页的:
 这种就比较简单,爬完一页换url就可以
这种就比较简单,爬完一页换url就可以if self.page < 100: self.page += 1 # 换url url = 'https://zhaopin.meituan.com/web/position?hiringType=2_6&pageNo=' +str(self.page) #再次调用爬虫 yield scrapy.Request(url=url, callback=self.parse, dont_filter=True) time.sleep(3) # 设置3秒间隔- 但是会有换页时url不变的情况,所以使用selenium模拟浏览器点击下一页按钮next_button = browser.find_element(by=By.XPATH,value='//[@id="target_list"]/div/div[2]/div[3]/button[2]')if not next_button.is_enabled(): breakbrowser.execute_script("arguments[0].click();", next_button)## 爬虫网页
使用上述教程,对相应公司招聘官网进行爬虫
华为
华为应届生实习生留学生_海外本地最新招聘信息-华为校园招聘 (huawei.com)
爬取华为公司,首先观察一个岗位的页面布局,写好爬取一个页面的代码:
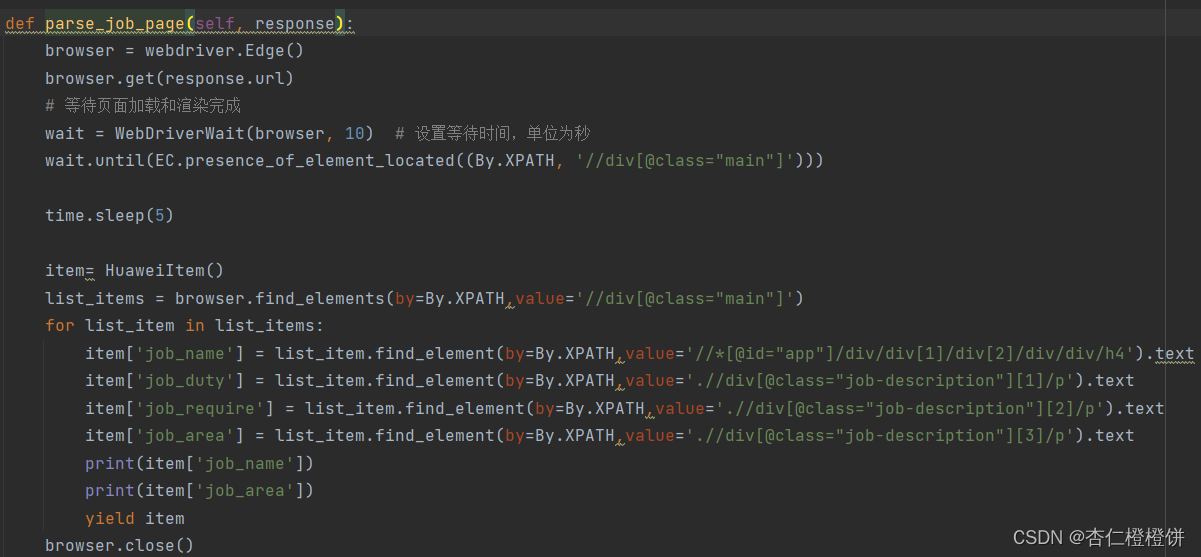
- 卡片中有跳转后的连接-
 -
- 
- 需要注意的是,页面需要加载和渲染,而scrapy只能爬取静态的网页源代码,不能执行js或处理动态内容,所以需要使用selenium
- 爬取之后,暂时只爬取了10个页面 因为下一页是通过javascript跳转的,有待研究- 使用execute_script("arguments[0].click();",button)实现点击下一页,从而翻页- 实现翻页后,首先爬取每页中的详情页面链接,最后再循环链接进行爬虫-

其他公司类似,遇到的相关问题都在爬虫教程中有所介绍。
数据量
对上述全部公司爬虫后,共获得1266条数据,数据格式如下:

本文转载自: https://blog.csdn.net/m0_63711281/article/details/139300818
版权归原作者 杏仁橙橙饼 所有, 如有侵权,请联系我们删除。
版权归原作者 杏仁橙橙饼 所有, 如有侵权,请联系我们删除。