
前言:
首先,这篇博客写给自己看的,方便自己回顾一下,复习项目过程中的知识点,加深自己的记忆。
参考了这篇文章:从零开始实现C++ TinyWebServer 全过程记录_tinywebserver要做多久-CSDN博客
实现流程:
1.框架:
网络框架的设计离不开 I/O 线程模型,线程模型的优劣直接决定了系统的吞吐量、可扩展性、安全性等。目前主流的网络框架几乎都采用了 I/O 多路复用的方案。Reactor 模式作为其中的事件分发器,负责将读写事件分发给对应的读写事件处理者。
本次项目使用的就是单reactor多线程模式,在主线程中通过epoll来实现 I/O多路复用监听多个文件描述符上的事件,在线程池中通过添加任务从而达到让子线程来处理读写事件,
单reactor多线程模式的缺点:连接建立、IO事件读取以及事件分发完全有单线程处理;比如当某个连接通过系统调用正在读取数据,此时相对于其他事件来说,完全是阻塞状态,新连接无法处理、其他连接的IO查询/IO读写以及事件分发都无法完成。(但满足Tiny-webserver的性能需求还是绰绰有余的)
关于Reactor 网络模型的具体知识点可以看一下:
高性能网络编程之 Reactor 网络模型(彻底搞懂) - 掘金 (juejin.cn)https://juejin.cn/post/7092436770519777311
2.底层的轮子:
服务器使用的是非阻塞I/O模型,即每次
send()
不一定会发送完,没发完的数据要用一个容器进行接收,所以必须要实现应用层缓冲区。
自定义一个buffer类:依靠底层容器vector实现,依靠读写两个指针的移动来实现,buffer中数据的读写。结构: prependable 区域** | **可读区域 | 可写区域 。prependable 区域的作用是当可写区域不足时,提供多余的空间。区域范围是:readindex - 0. readable 区域的作用是存放可供读取数据,即写入到buffer中的数据,区域范围是:writeindex - readindex。 writeable 区域的作用是留出空间写入数据,数据写完之后就转化成readable 区域,区域范围是:vector.capacity() - writeindex 。
整个buffer类实现最重要的----readindex和writeindex。封装的主要功能有:1.返回读指针和写指针的位置。2.读取数据和写入数据。3.扩展可写区间的大小。
#ifndef __BUFFER_H_
#define __BUFFER_H_
#include <cstring> //perror
#include <iostream>
#include <unistd.h> // write
#include <sys/uio.h> //readv
#include <vector> //readv
#include <atomic>
#include <assert.h>
class Buffer
{
private:
std::vector<char>buffer;
std::atomic<size_t>read_index; //atomic是一种原子类型,可以保证在多线的情况下,
std::atomic<size_t>write_index;//安全高性能得执行程序,更新变量。
public:
Buffer(int bufsize=1024);
~Buffer()=default;
size_t Writablebytes ()const;//类内函数后面加const修饰,表示只读函数,不修改类内成员
size_t ReadableBytes ()const;//这三个函数分别返回剩余多少字节
size_t PrependableBytes ()const;
const char * Return_read_index_point()const;
const char * Return_write_index_point()const;// 返回读写指针所指向的buffer容器中的位置,读指针不能被修改,所以要加const进行修饰
char * Return_wirte_index_point(); //便于后续操作容器,定义两种同名不同类型的函数
void EnsureWriteable(size_t len); //确保还有写的字节
void HasWritten(size_t len); //写入数据,修改写指针的位置
void Retrieve(size_t len); //从读的buffer中索取数据,并修改读指针的位置
void Retrieve_To(const char *pos);
void Retrieve_All();
std::string Retrieve_All_toString();
void Append(const char* str,size_t len); //拼接函数,相当于写数据的一种操作方式
void Append(const std::string &str);
void Append(const void * data,size_t len);
void Append(const Buffer &buffer);
ssize_t ReadFd(int fd, int* Errno); //读文件描述符中的内容,放在buffer中可写的区域
ssize_t WriteFd(int fd, int* Errno); // 将buffer中可读的区域写入fd中
private:
char *Begin_buffer(); //返回buffer的头
const char* Begin_buffer()const;
void Expand_Space(size_t len); //当buffer的空间暂时不够时,利用栈上的空间储存,
//等待buffer,扩容过后在append到buffer缓存中。
};
#endif
3.连接池和线程池
线程池没什么好说的,业务就是处理读写事件。pool_相当于线程池中的管理者,每个子线程线程,通过它使用锁,条件变量,任务队列。创造子线程的是时候巧妙的利用lamada表达式,子线程要执行的work()函数,写在了thread函数里
线程池中的工作线程是一直等待的吗?
对,等待新任务来了之后,条件变量将其唤醒,防止他一直遍历循环,耗费计算机资源。
线程池中的工作线程是一直等待的吗?
对,等待新任务来了之后,条件变量将其唤醒,防止他一直遍历循环,耗费计算机资源。
如果同时1000个客户端进行访问请求,线程数不多,怎么能及时响应处理每一个呢?
该项目是基于IO复用的并发模式。但需要注意的是,不是一个客户连接就对应一个线程!如果真是如此,淘宝双11服务器早就崩了!因为那么多的用户,不可能一人一个线程。
当客户连接有事件需要处理的时,epoll会进行事件提醒,然后将其对应的任务加入请求队列,等待工作线程竞争执行。如果速度还是慢,那就只能够增大线程池容量,或者考虑集群分布式的做法。
如果一个客户请求需要占用线程很久的时间,会不会影响接下来的客户请求呢,有什么好的策略呢?
会影响,因为线程的数量是固定的,如果一个客户请求长时间占用线程资源,就会影响服务器对外部整体的响应速度。解决的策略可以是给每一个线程处理任务设定一个时间阈值,当某一个客户请求时间过长,则将其置于任务请求最后,或断开连接。
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include <queue>
#include <mutex>
#include <condition_variable>
#include <functional>
#include <thread>
#include <assert.h>
class ThreadPool
{
public:
ThreadPool()=default;
ThreadPool(ThreadPool&&)=default;
explicit ThreadPool(int ThreadSzie=8):pool_(std::make_shared<Pool>())
{
assert(ThreadSzie>0);
for (int i = 0; i < ThreadSzie; i++)
{
std::thread([this]() { //利用lamanda表达式,创建线程,并执行下面的函数
std::unique_lock<std::mutex> locker(pool_->m_mutex);
while(true) { //工作线程,一直循环工作
if(!pool_->task_Q.empty()) { //任务队列有任务的话取出任务然后执行
auto task= std::move(pool_->task_Q.front()); // 左值变右值,资产转移
pool_->task_Q.pop();
locker.unlock(); // 因为已经把任务取出来了,所以可以提前解锁了
task();
locker.lock(); // 马上又要取任务了,上锁
} else if(pool_->IsClosed) {
break;
} else {
pool_->cond_.wait(locker); // 等待,如果任务来了就notify的
}
}
}).detach();
}
}
~ThreadPool()
{
if(pool_)
{
std:: unique_lock<std::mutex> locker(pool_->m_mutex);
pool_->IsClosed=true;
}
pool_->cond_.notify_all(); //唤醒所有线程
}
template<typename T>
void AddTask(T&& task)
{
std:: unique_lock<std::mutex> locker(pool_->m_mutex);
pool_->task_Q.emplace(std::forward<T>(task)); //emplace()可以避免push()产生的额外的复制或移动操作
pool_->cond_.notify_one();
//std::forward是C++11中用于实现完美转发的函数模板,可以根据传入的参数决定将参数以左值引用还是右值引用的方式进行转发,
} //解决了传递参数时临时对象被强制转换为左值的问题。
private:
struct Pool
{
std::mutex m_mutex;
std::condition_variable cond_;
bool IsClosed;
std::queue<std::function<void()>> task_Q; //任务队列,队列中的每一个成员都是一个void()任务函数给线程来执行
};
std::shared_ptr<Pool> pool_; //线程中的一个共享指针,给每个线程池中的线程调用
};
mysql连接池:(饿汉模式实现)
2.1 RAII
什么是RAII?RAII是Resource Acquisition Is Initialization(wiki上面翻译成 “资源获取就是初始化”)的简称,是C++语言的一种管理资源、避免泄漏的惯用法。利用的就是C++构造的对象最终会被销毁的原则。RAII的做法是使用一个对象,在其构造时获取对应的资源,在对象生命期内控制对资源的访问,使之始终保持有效,最后在对象析构的时候,释放构造时获取的资源。
为什么要使用RAII?
上面说到RAII是用来管理资源、避免资源泄漏的方法。那么,用了这么久了,也写了这么多程序了,口头上经常会说资源,那么资源是如何定义的?在计算机系统中,资源是数量有限且对系统正常运行具有一定作用的元素。比如:网络套接字、互斥锁、文件句柄和内存等等,它们属于系统资源。由于系统的资源是有限的,就好比自然界的石油,铁矿一样,不是取之不尽,用之不竭的,所以,我们在编程使用系统资源时,都必须遵循一个步骤:
1 申请资源;
2 使用资源;
3 释放资源。
第一步和第三步缺一不可,因为资源必须要申请才能使用的,使用完成以后,必须要释放,如果不释放的话,就会造成资源泄漏。我们常用的智能指针如unique_ptr、锁lock_guard就是采用了RAII的机制。
在使用多线程时,经常会涉及到共享数据的问题,C++中通过实例化std::mutex创建互斥量,通过调用成员函数lock()进行上锁,unlock()进行解锁。不过这意味着必须记住在每个函数出口都要去调用unlock(),也包括异常的情况,这非常麻烦,而且不易管理。C++标准库为互斥量提供了一个RAII语法的模板类std::lock_guard,其会在构造函数的时候提供已锁的互斥量,并在析构的时候进行解锁,从而保证了一个已锁的互斥量总是会被正确的解锁。
这些都是C++11的新特性,所以采用Modern C++可以大大减少代码量,毕竟都21世纪了,现在的语言都有只能垃圾回收机制,C++作为一门古老的语言,要是再不与时俱进,真的就没人用了。
sqlconpool的实现思想和threadpool差不太多,都是创建多个mysql的句柄且放在一个队列当中给应用层循环使用,这就避免了你访问一次数据库,就要申和请初始化一个句柄,结束访问后,又要释放这个句柄,减少了时间和资源的开支。
SqlConRall的作用就是充当应用层访问mysql数据库的接口,构造时获取对应的mysql句柄,在对象生命期内控制对资源的访问,使之始终保持有效,最后在析构的时候,释放构造时获取的资源,即把句柄放回到sqlconpool的队列中
#ifndef SQLCONNPOOL_H
#define SQLCONNPOOL_H
#include <mysql/mysql.h>
#include <string>
#include <queue>
#include <mutex>
#include <semaphore.h>
#include <thread>
#include "../log/log.h"
class SqlConPool //mysql的连接池
{
public:
static SqlConPool *Instance(); //获得连接池的单个实例
MYSQL *GetConnect(); //返回连接队列中的一个句柄,
void FreeConnection(MYSQL* con); //因为只能实例化了一个连接池,所以句柄不能被释放,可放入连接队列中重复使用,free代表了空闲,而不是释放
int GetFreeConCount();
void Init(const char* host,int port, //初始化连接池中的连接队列
const char* user,const char* pwd,
const char*dbName,int Size);
void ClosePool(); //关闭连接池,释放连接队列
private:
SqlConPool()=default;
~SqlConPool(){ClosePool();};
int MAX_CON_; //
std::queue<MYSQL *> Con_Queue;
std::mutex m_mutex;
sem_t semId_;
};
/* 资源在对象构造初始化 资源在对象析构时释放*/
class SqlConRall //给外部使用的类接口
{
private:
MYSQL *sql_;
SqlConPool *conpool_;
public:
SqlConRall(MYSQL **sql,SqlConPool*conpool) //构造函数,获得连接池,和一个sql句柄,给外部访问mysql库
{
assert(conpool);
*sql=conpool->GetConnect(); //获得连接队列中的一个句柄
sql_=*sql;
conpool_=conpool; //获取指向连接池的一个指针,给下面的析构函数使用
}
~SqlConRall()
{
if(sql_) conpool_->FreeConnection(sql_);//将使用玩的句柄,放回连接队列中
}
};
#endif
4.http的解析和响应
总结一下,一个HTTP连接要实现的功能就是:
- 读取请求
- 解析请求
- 生成响应
- 发送响应
然后浏览器就可以进行解析渲染了。
httpcon就是专门处理BS之间HTTP连接过程的类,通过这个类我们读取请求报文到读缓冲区中,然后调用httprequest解析读缓冲区,在调用httpresponse生成响应报文中到读缓冲区中,最后把读缓冲区的响应报文发送给浏览器。
#ifndef HTTP_CONN_H
#define HTTP_CONN_H
#include <sys/types.h>
#include <sys/uio.h> // readv/writev
#include <arpa/inet.h> // sockaddr_in
#include <stdlib.h> // atoi()
#include <errno.h>
#include "../log/log.h"
#include "../buffer/buffer.h"
#include "httprequest.h"
#include "httpresponse.h"
/*
进行读写数据并调用httprequest 来解析数据以及httpresponse来生成响应
*/
class HttpConnect
{
public:
HttpConnect();
~HttpConnect();
void init(int sockfd,const sockaddr_in&addr); //初始化客户端的地址数据
ssize_t read(int* Errno); //从读缓冲区读数据
ssize_t write(int* Errno); //从写缓冲区写数据
void Close(); //关闭客户端的请求
int GetFd()const; //接口,返回客户端的sockfd
int GetPort()const; //接口,返回客户端的端口号
const char* GetIP()const; //接口,返回客户端的IP
sockaddr_in GetAddr()const; //接口,返回客户端的sockaddr
bool process(); //流程函数,包含reques解析请求,response响应报文
int The_WriteBytes() //获取响应报文的总大小
{
return iov_[0].iov_len+iov_[1].iov_len;
}
bool IsKeepAlive()const
{
return request_.IsKeepAlive();
}
static bool isET; //边沿触发模式的标志
static const char* srcDir; //服务器的文件目录
static std::atomic<int> userCount; //原子变量,多线程修改的时候不需要mutex
private:
int fd_; //客户端进行tcp通信的socket
struct sockaddr_in addr_;//客户端的IP地址结构
bool IsClose_; //连接状态标志
int iovCnt_; //iovec结构体中,不同缓冲区的数量
struct iovec iov_[2]; //拼接响应报文,因为当客户端请求的文件过大超过写缓冲区时,要用临时的缓冲区去存请求的文件
//struct iovec定义了一个向量元素。通常,这个结构用作一个多元素的数组。对于每一个传输的元素,指针成员iov_base指向一个缓冲区,
Buffer readbuff_; //读缓冲->浏览器发送来的请求报文
Buffer writebuff; //写缓冲->生成的响应报文放在这里
HttpRequest request_;
HttpResponse response_;
};
#endif
httprequest类专门用来解析请求报文中的数据读缓存区并把请求报文中的关键信息(请求访问文件的文件名等)写入读缓冲区中给生成响应报文的时候使用,以及通过sqlconrall连接数据库登录和注册账号。对于HTTP请求报文,采用分散读进行读取,使用有限状态机和正则表达式进行解析;
HTTP
为什么要用状态机?
有限状态机,是一种抽象的理论模型,它能够把有限个变量描述的状态变化过程,以可构造可验证的方式呈现出来。比如,封闭的有向图。有限状态机可以通过if-else,switch-case和函数指针来实现,从软件工程的角度看,主要是为了封装逻辑。有限状态机一种逻辑单元内部的一种高效编程方法,在服务器编程中,服务器可以根据不同状态或者消息类型进行相应的处理逻辑,使得程序逻辑清晰易懂。
#ifndef HTTP_REQUEST_H
#define HTTP_REQUEST_H
#include <unordered_map>
#include <unordered_set>
#include <string>
#include <regex> // 正则表达式
#include <errno.h>
#include <mysql/mysql.h> //mysql
#include "../buffer/buffer.h"
#include "../log/log.h"
#include "../pool/sqlconpool.h"
/*
http协议的请求格式如下:
请求行 ([请求方法] [url] [版本] (空格分开))
请求头 (Name:[空格]内容(一行就是一个属性,这里的“行”是以换行符作为标准))
\n(换行符不可省略,也是区分请求头和正文的标识)
正文(也就是请求的数据)
*/
class HttpRequest
{
public:
enum PARSE_STATE //解析状态的枚举类型
{
REQUEST_LINE,
HEADERS,
BODY,
FINISH,
};
HttpRequest(){Init();}
~HttpRequest()=default;
void Init();
bool parse(Buffer &buff); //解析缓冲区中的数据
std::string path()const;
std::string &path();
/*函数名称前面加引用符号“&”的意思是返回引用类型可以返回类成员的引用,
但最好是const。这条原则可以参照Effective C++的Item 30。
主要原因是当对象的属性是与某种业务规则(business rule)相关联的时候,
其赋值常常与某些其它属性或者对象的状态有关,因此有必要将赋值操作封装在一个业务规则当中。*/
std::string method()const; //外部接口调用,返回method
std::string version()const; //外部接口调用,返回version
std::string Getpost(const std::string& key)const;
std::string Getpost(const char *key)const;
bool IsKeepAlive() const;
private:
bool ParseRequestLine_(const std::string &line); //处理请求行,也就是http请求的第一行
void ParseRequestHead_(const std::string &head); //处理请求头,也就是有关http请求的一些属性和相关信息
void ParseRequestBody_(const std::string &body); //处理正文内容,当通过post来发送http请求时,就需要处理正文的内容
void ParsePath_(); //处理请求行的URL,即要访问的服务器文件路径,也就是页面
void ParsePost_(); //如果请求方法是post,就需要多识别正文的这一步,所以单独处理post事件
void ParseFromUrl_(); //从URL中解析编码
static bool UserVerify(const std::string&name,const std::string&pwd,bool isLogin);//用户验证登录
PARSE_STATE state_; //保存解析的状态
std::string method_,path_,version_,body_; //string 存储method_,path_,version,body等信息
/* unordered_类型容器是无序的
1、优点:因为内部实现了哈希表,因此其查找速度非常的快。
2、缺点:哈希表的建立比较耗费时间
3、适用处:对于查找问题,unordered_map 会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map*/
std::unordered_map<std::string,std::string> header_; //用哈希表来存储请求头中的键值对,即请求头中的数据
std::unordered_map<std::string,std::string> post_; //存储请求体中的数据,即
static const std::unordered_set<std::string >DEFAULT_HTML; //存储界面路径
static const std::unordered_map<std::string ,int>DEFAULT_HTML_TAG; //存储登录和注册等相关信息
static int ConverHex(char ch); //16进制转换为10进制
};
#endif
在HttpResponse.cpp中,主要是考MakeResponse(Buffer& buff)这个函数实现的,分为三个步骤:1. 添加状态行;
添加头部;
添加响应报文,
其中,第三步涉及到内存映射,后面马上讲。
我们之前不是在HttpRequest.cpp中生成了请求报文吗,请求报文里面包括了我们要请求的页面(path),响应报文的过程就是根据请求报文写出响应头,将path上的文件放在响应体,然后通过httpconn类发送给客户端(浏览器)。
2.3 添加响应正文
- 首先需要打开这个文件
- 用
mmap这个函数映射到内存,可以提高文件的访问速度- 映射过后,就可以将该文件描述符关闭了
- 将该内存映射的指针在HTTPConnect的process()中赋值给了
iov[1],这样HttpConnect::write()就可以通过iov数组,将文件和响应报文中的状态行,消息报头集中写给浏览器了- mmap 私有文件映射的读时共享,写时复制(copy on write)以及修改不会回写到映射文件中等特点
关于mmap的使用特性和原理可以参靠考这篇文章:
操作系统虚拟内存管理(三):MMAP内存映射 - 知乎 (zhihu.com)
#ifndef HTTP_RESPONSE_H
#define HTTP_RESPONSE_H
#include <unordered_map>
#include <fcntl.h> // open
#include <unistd.h> // close
#include <sys/stat.h> // stat
#include <sys/mman.h> // mmap, munmap
#include "../buffer/buffer.h"
#include "../log/log.h"
/*
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
\r\n
<html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
1.状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。 第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为OK。
2.消息报头,用来说明客户端要使用的一些附加信息。 第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8。
3.空行,消息报头后面的空行是必须的。它的作用是通过一个空行,告诉服务器头部到此为止。
4.响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文。*/
//struct stat
//{
// dev_t st_dev; /* 文件所在设备的 ID */
// ino_t st_ino; /* 文件对应 inode 节点编号 */
// mode_t st_mode; /* 文件对应的模式 */
// nlink_t st_nlink; /* 文件的链接数 */
// uid_t st_uid; /* 文件所有者的用户 ID */
// gid_t st_gid; /* 文件所有者的组 ID */
// dev_t st_rdev; /* 设备号(指针对设备文件) */
// off_t st_size; /* 文件大小(以字节为单位) */
// blksize_t st_blksize; /* 文件内容存储的块大小 */
// blkcnt_t st_blocks; /* 文件内容所占块数 */
// struct timespec st_atim; /* 文件最后被访问的时间 */
// struct timespec st_mtim; /* 文件内容最后被修改的时间 */
// struct timespec st_ctim; /* 文件状态最后被改变的时间 */
// };
class HttpResponse
{
public:
HttpResponse();
~HttpResponse();
void INIT(const std::string &SrcDir,const std::string &path,bool isAlive=false,int code = -1);
void MakeResponse(Buffer &buff);//制作响应报文
void UnMapFile(); //解除内存映射的关系
char *File(); //返回指向内存映射区的首地址
size_t File_Len() const; //返回请求文件的大小
void ErroeContent(Buffer &buff,std::string msg);
int Code()const { return code_;}//返回状态码
private:
void AddStateLine(Buffer &buff);//给缓冲区添加状态行
void AddHeader(Buffer &buff); //给缓冲区添加消息报头
void AddContent(Buffer &buff); //给缓冲区添加响应正文
void ErrorHtml(); //获取状态码为40X的时候的响应内容
std::string GetFileType(); //返回文件的类型 e.g:text/html
int code_; //状态码
bool isKeepAlive_; //连接状态
std::string path_; //目录下的文件路径(包含文件名)
std::string SrcDir_; //存放html的目录,即resources目录
char * mFile_; //指向文件在内存映射下的首地址
struct stat mFileStat_; //所访问文件的stat结构体,结构体中包含了许多有关文件的信息
static const std::unordered_map<std::string,std::string> SUFFERFIX_TYPE;//后缀类型集
static const std::unordered_map<int,std::string> CODE_STATUE; //编码状态集
static const std::unordered_map<int,std::string> CODE_PATH; //编码路径集
};
#endif
5.定时器:时间堆
网络编程中除了处理IO事件之外,定时事件也同样不可或缺,如定期检测一个客户连接的活动状态、游戏中的技能冷却倒计时以及其他需要使用超时机制的功能。我们的服务器程序中往往需要处理众多的定时事件,因此有效的组织定时事件,使之能在预期时间内被触发且不影响服务器主要逻辑,对我们的服务器性能影响特别大。
我们的web服务器也需要这样一个时间堆,定时剔除掉长时间不动的空闲用户,避免他们占着茅坑不拉屎,耗费服务器资源。
一般的做法是将每个定时事件封装成定时器,并使用某种容器类数据结构将所有的定时器保存好,实现对定时事件的统一管理。常用方法有排序链表、红黑树、时间堆和时间轮。这里使用的是时间堆。
时间堆的底层实现是由小根堆实现的。小根堆可以保证堆顶元素为最小的。
为什么手动实现小根堆?
学以致用,为了更好的熟悉堆这一数据结构。常用的定时器结构和它们的差异?
除了小根堆实现之外,还有使用时间轮和基于升序链表实现的定时器结构。基于升序链表实现的定时器结构按照超时时间作为升序做排序,每个结点都链接到下一个结点,由于链表的有序性以及不支持随机访问的特性,每次插入定时器都需要遍历寻找合适的位置,而且每次定时器调整超时时间时也需要往后遍历寻找合适的位置进行挪动,遍历操作效率较低。
小根堆实现的定时器结构,每次取堆头都是最短超时时间,能够利用IO复用的超时选项,每次的计时间隔动态调整为最短超时时间,确保每次调用IO复用系统调用返回时都至少有一个定时事件的超时发生或者监听事件的到达,有效地减少了多余的计时中断(利用信号中断进行计时)。最主要是确保每次定时器插入、更新、删除都能实现稳定的logn时间复杂度。
#ifndef HEAP_TIMER_H
#define HEAP_TIMER_H
#include <queue>
#include <unordered_map>
#include <time.h>
#include <algorithm>
#include <arpa/inet.h>
#include <functional>
#include <assert.h>
#include <chrono>
#include "../log/log.h"
typedef std::function<void()> TimeoutCallBack;
typedef std::chrono::high_resolution_clock Clock;
typedef std::chrono::milliseconds MS;
typedef Clock::time_point TimeStamp;
struct TimerNode {
int id;
TimeStamp expires; // 超时时间点
TimeoutCallBack cb; // 回调function<void()>
bool operator<(const TimerNode& t) { // 重载比较运算符
return expires < t.expires;
}
bool operator>(const TimerNode& t) { // 重载比较运算符
return expires > t.expires;
}
};
class HeapTimer {
public:
HeapTimer() { heap_.reserve(64); } // 保留(扩充)容量
~HeapTimer() { clear(); }
void adjust(int id, int newExpires);
void add(int id, int timeOut, const TimeoutCallBack& cb);
void doWork(int id);
void clear();
void tick();
void pop();
int GetNextTick();
private:
void del_(size_t i);
void siftup_(size_t i);
bool siftdown_(size_t i, size_t n);
void SwapNode_(size_t i, size_t j);
std::vector<TimerNode> heap_;
// key:id value:vector的下标
std::unordered_map<int, size_t> ref_; // id对应的在heap_中的下标,方便用heap_的时候查找
};
#endif //HEAP_TIMER_H
6.封装epoll和webserver
epoller类就是简单封装了一下epoll的各个接口(增删改查),在webserver类中调用
关于epoll具体接口的使用的文章:Linux下的I/O复用技术 — epoll如何使用(epoll_create、epoll_ctl、epoll_wait) 以及 LT/ET 使用过程解析_安卓选择linux epoll唤醒线程 而不用wait/notify的原因是什么-CSDN博客
#ifndef EPOLLER_H
#define EPOLLER_H
#include <sys/epoll.h> //epoll_ctl()
#include <unistd.h> // close()
#include <assert.h> // close()
#include <vector>
#include <errno.h>
class Epoller
{
public:
explicit Epoller(int maxEvent = 1024);
~Epoller();
bool AddFd(int fd,uint32_t events); //增
bool ModFd(int fd,uint32_t events); //改
bool DelFd(int fd); //删
int Wait(int outMStime=-1); //监听epoll上注册的事件,返回事件触发的个数
int GetEventFd(size_t index)const; //返回事件的fd
uint32_t GetEvents(size_t index)const; 获取事件属性
private:
int Epollfd_ ; //操作epoll的实例的fd
std::vector<struct epoll_event> event_; //存放epoll_event的容器
};
#endif
WebServer类详解
1.WebServer的初始化
创建线程池和数据库的连接池,初始化socket(绑定服务器ip地址和端口),初始化epoller和epoller中使用的事件模式,日志系统以及服务器的工作文件目录。
2.监听I/O事件
接下来启动WebServer,首先需要设定epoll_wait()等待的时间(连接的超时时间),这里我们选择调用定时器的GetNextTick()函数,这个函数的作用是返回最小堆堆顶的连接设定的过期时间与现在时间的差值。这个时间的选择可以保证服务器等待事件的时间不至于太短也不至于太长。接着调用epoll_wait()函数,返回需要已经就绪事件的数目。这里的就绪事件分为两类:收到新的http请求和其他的读写事件。 这里设置两个变量fd和events分别用来存储就绪事件的文件描述符和事件类型。
1.收到新的HTTP请求的情况
在fd==listenFd_的时候,也就是收到新的HTTP请求的时候,调用函数DealListen_();处理监听,接受客户端连接;2.已经建立连接的HTTP发来IO请求的情况
在events& EPOLLIN 或events & EPOLLOUT为真时,需要进行读写的处理。分别调用 DealRead_(&users_[fd])和DealWrite_(&users_[fd]) 函数。这里需要说明:DealListen_()函数并没有调用线程池中的线程,而DealRead_(&users_[fd])和DealWrite_(&users_[fd]) 则都交由线程池中的线程进行处理了。这就是Reactor,读写事件交给了工作线程处理。
3 I/O处理的具体流程
有新的连接产生,调用DealListen来处理,
有读事件产生,调用DealRead()来处理,在函数里给线程池添加OnRead_()任务函数
有写事件产生,调用DealWrite()来处理,在函数里给线程池添加OnWrite_()任务函数
函数来取出线程池中的线程继续进行读写,而主进程这时可以继续监听新来的就绪事件了。
注意此处用std:;bind将参数绑定,他可以将可调用对象将参数绑定为一个仿函数,绑定后的结果可以使用std::function保存,而且bind绑定类成员函数时,第一个参数表示对象的成员函数的指针(所以上面的函数用的是&WebServer::OnRead_),第二个参数表示对象的地址。

按业务逻辑顺序
**1.**OnRead_()函数首先把数据从缓冲区中读出来(调用HttpConn的read,read调用ReadFd读取到读缓冲区BUFFER),然后交由逻辑函数OnProcess()处理。这里多说一句,httpconnect::process()函数在解析请求报文后随即就生成了响应报文等待OnWrite_()函数发送,这一点我们前面谈到过的。
**2.**OnProcess()就是进行业务逻辑处理(解析请求报文、生成响应报文)的函数了。
这里必须说清楚OnRead_()和OnWrite_()函数进行读写的方法,那就是:分散读和集中写
**3.**OnWrite_()函数首先把之前根据请求报文生成的响应报文从缓冲区交给fd,传输完成后修改该fd的events.
分散读(scatter read)和集中写(gatherwrite)具体来说是来自读操作的输入数据被分散到多个应用缓冲区中,而来自应用缓冲区的输出数据则被集中提供给单个写操作。 这样做的好处是:它们只需一次系统调用就可以实现在文件和进程的多个缓冲区之间传送数据,免除了多次系统调用或复制数据的开销。
这里我要提一嘴我之前犯的思想错误,一定要记住:“如果没有数据到来,epoll是不会被触发的”。当浏览器向服务器发出request的时候,epoll会接收到EPOLL_IN读事件,此时调用OnRead去解析,将fd(浏览器)的request内容放到读缓冲区,并且把响应报文写到写缓冲区,这个时候调用OnProcess()是为了把该事件变为EPOLL_OUT,让epoll下一次检测到写事件,把写缓冲区的内容写到fd。当EPOLL_OUT写完后,整个流程就结束了,此时需要再次把他置回原来的EPOLL_IN去检测新的读事件到来。
#ifndef WEBSERVER_H
#define WEBSERVER_H
#include <unordered_map>
#include <fcntl.h> // fcntl()
#include <unistd.h> // close()
#include <assert.h>
#include <errno.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include "epoller.h"
#include "../timer/heaptimer.h"
#include "../log/log.h"
#include "../pool/sqlconpool.h"
#include "../pool/threadpool.h"
#include "../http/httpconn.h"
class WebServer
{
public:
WebServer(
int port, int trigMode, int timeoutMS,
int sqlPort, const char* sqlUser, const char* sqlPwd,
const char* dbName, int connPoolNum, int threadNum,
bool openLog, int logLevel, int logQueSize);
~WebServer();
void start();
private:
bool InitSocket(); //初始服务器的socket
void InitEventMode(int triMode); //初始化事件模式
void AddClient(int fd,sockaddr_in c_addr); //把客户端的socket加入timer和epoller中
void DealListen(); //处理服务器的监听事件(即有客户端连接)
void DealWrite(HttpConnect*http_client); //处理写事件
void DealRead(HttpConnect*http_client); //处理读事件
void SendError(int fd,const char*info); //将客户端于服务器连接时的错误发送给客户端
void ExtentTime(HttpConnect*http_client); //更新客户端对应的定时器的超时时间
void CloseConn(HttpConnect*http_client); //关闭客户端的连接
void OnRead(HttpConnect*http_client); //OnRead_()函数首先把数据从缓冲区中读出来(调用HttpConn的read,read调用ReadFd读取到读缓冲区BUFFER),
void Onwrite(HttpConnect*http_client); //OnWrite_()函数首先把之前根据请求报文生成的响应报文从缓冲区交给fd,传输完成后修改该fd的events.
void OnProcess(HttpConnect*http_client); //进行业务逻辑处理(解析请求报文、生成响应报文)的函数
static int SetNonblock(int fd); //设置fd为非阻塞类型
static const int MAX_FD=65536; //客户端的最大连接数
int port_; //服务器绑定的端口号
int MS_OutTime_; //连接超时的时间
bool IsClose_; //webserver打开状态的标志
int listen_fd_; //监听fd(服务器自身的fd)
char *SrcDir_; //服务器运行目录的绝对路径
uint32_t listenEvent_; //连接事件的事件类型(accept)
uint32_t ConnEvent_; //客户端的事件类型 (客户端和服务器的读写操作)
std::unique_ptr<HeapTimer> timer_; //定时器
std::unique_ptr<ThreadPool> threadpool_; //线程池
std::unique_ptr<Epoller> epoller_; //epoll池
std::unordered_map<int,HttpConnect> users_;//用户队列<客户端的socket,对应的httpconnect>
};
#endif
#include"webserver.h"
WebServer::WebServer(
int port, int trigMode, int timeoutMS,
int sqlPort, const char* sqlUser, const char* sqlPwd,
const char* dbName, int connPoolNum, int threadNum,
bool openLog, int logLevel, int logQueSize):
port_(port), MS_OutTime_(timeoutMS), IsClose_(false),
timer_(new HeapTimer()), threadpool_(new ThreadPool(threadNum)), epoller_(new Epoller())
{
std::cout<<"it ok1"<<endl;
SrcDir_=getcwd(nullptr,256); //getcwd成功返回指向当前目录的指针,和buf 的值一样,错误返回NULL
assert(SrcDir_);
strcat(SrcDir_,"/resources");//把/resources/添加到SrcDir_结尾处,即使SrcDir_指向存放html,mp3等资源的文件夹
HttpConnect::userCount=0;
HttpConnect::srcDir=SrcDir_;
std::cout<<"it ok2"<<endl;
SqlConPool::Instance()->Init("localhost",sqlPort,sqlUser,sqlPwd,dbName,connPoolNum); //初始化MySQL的连接池
InitEventMode(trigMode); //初始化事件的读写类型
if(!InitSocket()) IsClose_=true;//初始化服务器的socket
//是否打开日志
std::cout<<"it ok3"<<endl;
if(openLog)
{
Log::Instance()->init(logLevel,"./log",".log",logQueSize);//日志的初始化,初始化日志存放的路径和后缀
if(IsClose_)
{
LOG_ERROR("=========Server init error!=========");
}
else{
LOG_INFO("=========Server init=========");
LOG_INFO("Liseten Mode :%s, Openconn Mode: %s",(listenEvent_&EPOLLET ? "ET":"LT"),
(ConnEvent_&EPOLLET ? "ET":"LT"));
LOG_INFO("LogSystem Level: %d",logLevel);
LOG_INFO("SrcDir: %s",HttpConnect::srcDir);
LOG_INFO("SqlConnPool nums: %d,ThreadPool nums: %d",connPoolNum,threadNum);
}
}
}
WebServer::~WebServer()
{
IsClose_=true;
close(listen_fd_);
free(SrcDir_);
SqlConPool::Instance()->ClosePool();
}
//初始化事件模式
void WebServer::InitEventMode(int triMode)
{
listenEvent_=EPOLLRDHUP; //检测socket关闭。EPOLLRDHUP->套接字对端关闭。
/*epoll的EPOLLONESHOT事件可以使得操作系统最多触发其上注册的一个可读、可写、异常的事件,且只触发一次,除非我们使用epoll_ctl函数重置该文件描述符上注册的EPOLLONESHOT事件。
这样,当一个线程在处理一个clientfd时,其他线程没有机会操作该clientfd。另一方面,注册了EPOLLONESHOT事件的clientfd一旦被处理完毕,
我们应该立即重置这个clientfd的EPOLLONESHOT事件,确保下一次可读事件能顺利触发。*/
ConnEvent_=EPOLLONESHOT|EPOLLRDHUP;//只能由一个线程处理客户端的读或写事件
switch (triMode)
{
case 0:
break;
case 1:
ConnEvent_ |=EPOLLET;
break;
case 2:
listenEvent_ |=EPOLLET;
break;
case 3:
listenEvent_ |=EPOLLET;
ConnEvent_ |=EPOLLET;
break;
default:
listenEvent_ |=EPOLLET;
ConnEvent_ |=EPOLLET;
break;
}
HttpConnect::isET=(ConnEvent_&EPOLLET);//设置httpcon中的et标志
}
bool WebServer::InitSocket()
{
int ret; //接收返回值
struct sockaddr_in s_addr;
s_addr.sin_family=AF_INET;
s_addr.sin_port=htons(port_);
s_addr.sin_addr.s_addr=htonl(INADDR_ANY);
listen_fd_=socket(AF_INET,SOCK_STREAM,0);
if(listen_fd_<0)
{
LOG_ERROR("Create socket error");
return false;
}
//opt: 对于setsockopt(),指针,指向存放选项待设置的新值的缓冲区。获得或者是设置套接字选项.根据选项名称的数据类型进行转换。
int opt=1;
ret=setsockopt(listen_fd_,SOL_SOCKET,SO_REUSEADDR,(const void*)&opt,sizeof(int));//设置端口复用
if(ret==-1)
{
LOG_ERROR("set socket setsockopt error!");
close(listen_fd_);
return false;
}
//绑定ip结构
ret=bind(listen_fd_,(struct sockaddr*)&s_addr,sizeof(s_addr));
if(ret<0)
{
LOG_ERROR("Server Bind Error!");
close(listen_fd_);
return false;
}
ret=listen(listen_fd_,8);
if(ret<0)
{
LOG_ERROR("Server Listen Error!");
close(listen_fd_);
return false;
}
ret=epoller_->AddFd(listen_fd_,listenEvent_|EPOLLIN);//将服务器的套接字挂在树上
if(ret==0)
{
LOG_ERROR("Epoller Add_Server_fd Error!");
close(listen_fd_);
return false;
}
SetNonblock(listen_fd_); //设置监听fd为非阻塞
LOG_INFO("Server port:%d",port_);
return true;
}
int WebServer::SetNonblock(int fd)
{
assert(fd>0);
return fcntl(fd,F_SETFL,fcntl(fd,F_GETFD,0)|O_NONBLOCK);//F_GETFL 取得文件描述符状态,或上O_NONBLOCK
}
/*这就是Reactor模式,读写事件交给了工作线程处理。*/
void WebServer::start()
{
//epoll->wait中timeout = -1:表示调用将一直阻塞,直到有文件描述符进入ready状态或者捕获到信号才返回
int MStime=-1;
if(!IsClose_)
LOG_INFO("=========Server Start!=========");
while (!IsClose_)
{
if(MS_OutTime_>0) MStime=timer_->GetNextTick();//获取下一次超时等待事件,(至少这个事件才会有用户过期,每次关闭超时连接则需要有新的请求进来
}
int evtcount=epoller_->Wait(MStime);
for(int i=0;i<evtcount;i++)
{
int fd=epoller_->GetEventFd(i); //返回事件队列中i对应的socket
uint32_t events=epoller_->GetEvents(i); //返回事件队列中i对应的事件event
if(fd==listen_fd_) DealListen();
else if(events&(EPOLLRDHUP| EPOLLHUP| EPOLLERR))//客户端的套接字关闭,挂断,或者有错误发生
{
assert(users_.count(fd)>0);
CloseConn(&users_[fd]);
}else if(events& EPOLLIN) //读事件发生
{
assert(users_.count(fd)>0);
DealRead(&users_[fd]);
}else if(events& EPOLLOUT) //写事件发生
{
assert(users_.count(fd)>0);
DealWrite(&users_[fd]);
}else{
LOG_ERROR("UnExpected Error!");
}
}
}
// 处理监听套接字,主要逻辑是accept新的套接字,并加入timer和epoller中
void WebServer::DealListen()
{
struct sockaddr_in addr;
socklen_t len=sizeof(addr);
do
{
int cfd=accept(listen_fd_,(struct sockaddr*)&addr,&len);
if(cfd<0) return;
else if(HttpConnect::userCount>MAX_FD) //如果客户端的连接数量,超过了服务器最大连接数量,报错
{
SendError(cfd,"Server busy!");
LOG_WARN("Client Connect Full!");
return;
}
AddClient(cfd,addr);
} while (listenEvent_&EPOLLET);
}
//将accept新的套接字加入timer和epoller中
/*bind绑定类成员函数时,第一个参数表示对象的成员函数的指针,第二个参数表示对象的地址,
这是因为对象的成员函数需要有this指针。并且编译器不会将对象的成员函数隐式转换成函数指针,需要通过&手动转换;*/
void WebServer::AddClient(int fd,sockaddr_in c_addr)
{
users_[fd].init(fd,c_addr);
if(MS_OutTime_>0) timer_->add(fd,MS_OutTime_,std::bind(&WebServer::CloseConn,this,&users_[fd]));//添加定时器,定时器的id就为socket
epoller_->AddFd(fd,EPOLLIN | ConnEvent_); //添加事件
SetNonblock(fd);
LOG_INFO("Client[%d] in!", users_[fd].GetFd())
}
//关闭客户端的连接
void WebServer::CloseConn(HttpConnect*http_client)
{
assert(http_client);
LOG_INFO("Client[%d] quit!", http_client->GetFd());
epoller_->DelFd(http_client->GetFd()); //从树上摘下客户端的socket;
http_client->Close(); //关闭该客户端对应的httpconn
}
//处理读事件
void WebServer::DealRead(HttpConnect*http_client)
{
assert(http_client);
ExtentTime(http_client);//当客户端有事件发生且未超时,则应该更新客户端对应的定时器的超时剩余时间
threadpool_->AddTask(std::bind(&WebServer::OnRead,this,http_client));//将读任务添加到任务对列中,由子线程来处理
}
//把数据从缓冲区中读出来
void WebServer::OnRead(HttpConnect*http_client)
{
assert(http_client);
int ret=-1;
int readerrno =0;
ret =http_client->read(&readerrno);//调用HTTPConnect类中的read函数,把请求报文读到读缓冲中
if(ret<=0 && readerrno != EAGAIN) //当读入的字节数小于等于0,并且不是读到文件的末尾,说明出错了
{
CloseConn(http_client);
return;
}
OnProcess(http_client); //进行业务逻辑处理(解析请求报文、生成响应报文),等待写事件的触发,通过OnWrite发送给客户端
}
void WebServer::ExtentTime(HttpConnect*http_client)
{
assert(http_client);
if(MS_OutTime_>0) timer_->adjust(http_client->GetFd(),MS_OutTime_);
}
//处理读数据的函数
void WebServer::OnProcess(HttpConnect*http_client)
{
//首先调用HTTPConnect的业务处理函数(解析读缓冲区中的请求报文,写缓冲去中生成响应报文)
if(http_client->process())//响应报文生成成功后,返回true,注册写事件
epoller_->ModFd(http_client->GetFd(),ConnEvent_|EPOLLOUT);
else //http_client->process(),说明响应报文生成失败,重新注册读事件
epoller_->ModFd(http_client->GetFd(),ConnEvent_|EPOLLIN);
}
void WebServer::DealWrite(HttpConnect*http_client)
{
assert(http_client);
ExtentTime(http_client);//当客户端有事件发生且未超时,则应该更新客户端对应的定时器的超时剩余时间
threadpool_->AddTask(std::bind(&WebServer::Onwrite,this,http_client));
}
void WebServer::Onwrite(HttpConnect*http_client)
{
assert(http_client);
int ret=-1;
int writeErrno=0;
ret=http_client->write(&writeErrno); //调用http_client->write给客户端发送响应报文
if(http_client->The_WriteBytes()==0) //响应报文传输完成
{
if(http_client->IsKeepAlive()) //客户端还是保持连接的话,就继续监听客户端的读事件
{
epoller_->ModFd(http_client->GetFd(),ConnEvent_|EPOLLIN);
return;
}
}else if(ret<0)
{
if(writeErrno==EAGAIN) //调用函数的时候tcp发送缓冲被占满,重新注册写事件,等待tcp发送缓冲缓冲有空了继续传输
{
epoller_->ModFd(http_client->GetFd(),ConnEvent_|EPOLLOUT);
return;
}
}
CloseConn(http_client);
}
void WebServer::SendError(int fd,const char*info)
{
assert(fd>0);
int ret=send(fd,info,strlen(info),0); //直接把客户端和服务器连接时出现的错误发送给客户端
if(ret<0)
{
LOG_WARN("send error to client[%d] error!", fd);
}
close(fd);
}
7.时间堆
网络编程中除了处理IO事件之外,定时事件也同样不可或缺,如定期检测一个客户连接的活动状态、游戏中的技能冷却倒计时以及其他需要使用超时机制的功能。我们的服务器程序中往往需要处理众多的定时事件,因此有效的组织定时事件,使之能在预期时间内被触发且不影响服务器主要逻辑,对我们的服务器性能影响特别大。
我们的web服务器也需要这样一个时间堆,定时剔除掉长时间不动的空闲用户,避免他们占着茅坑不拉屎,耗费服务器资源。
一般的做法是将每个定时事件封装成定时器,并使用某种容器类数据结构将所有的定时器保存好,实现对定时事件的统一管理。常用方法有排序链表、红黑树、时间堆和时间轮。这里使用的是时间堆。
时间堆的底层实现是由小根堆实现的。小根堆可以保证堆顶元素为最小的。
关于小根堆的知识:
小根堆,本质是一棵完全二叉树,它的每一个父节点都小于等于左右子节点,所以当我们一直维护着小根堆的堆序性的时候,堆的头结点(也就是下标为0的结点,堆排序中需要用数组来存储堆的每个结点的下表)一定是整个堆中最小的,也是距离超时时间最近的httpconnect。
维护堆序性一共有两种方法:1.上滤 2.下滤。(这两种方法的操作对象都是结点)
插入和删除:
1.删除:将待删除的结点和堆中的最后一个结点(记为结点a)交换,然后通过上滤或者下滤结点a,维护堆序行
2.插入:将待插入的结点连接在堆的末尾,然后上滤这个结点,从而维护堆序性
具体的有关堆排序的知识点可以看下面两个视频
https://www.bilibili.com/video/BV1fp4y1D7cj/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1AF411G7cA/?spm_id_from=333.337.search-card.all.click
#ifndef HEAP_TIMER_H
#define HEAP_TIMER_H
#include <queue>
#include <unordered_map>
#include <time.h>
#include <algorithm>
#include <arpa/inet.h>
#include <functional>
#include <assert.h>
#include <chrono>
#include "../log/log.h"
typedef std::function<void()> TimeoutCallBack;
typedef std::chrono::high_resolution_clock Clock;
typedef std::chrono::milliseconds MS;
typedef Clock::time_point TimeStamp;
struct TimerNode {
int id; //堆的每个节点都拥有一个id,用于区别不同的HttpConnect
TimeStamp expires; // 超时时间点
TimeoutCallBack cb; // 回调function<void()>
bool operator<(const TimerNode& t) { // 重载比较运算符
return expires < t.expires;
}
bool operator>(const TimerNode& t) { // 重载比较运算符
return expires > t.expires;
}
};
class HeapTimer {
public:
HeapTimer() { heap_.reserve(64); } // 保留(扩充)容量
~HeapTimer() { clear(); }
void adjust(int id, int newExpires);
void add(int id, int timeOut, const TimeoutCallBack& cb);
void doWork(int id);
void clear();
void tick();
void pop();
int GetNextTick();
private:
void del_(size_t i);
void siftup_(size_t i);
bool siftdown_(size_t i, size_t n);
void SwapNode_(size_t i, size_t j);
std::vector<TimerNode> heap_;
// key:id value:vector的下标
std::unordered_map<int, size_t> ref_; // id对应的在heap_中的下标,方便用heap_的时候查找
};
#endif //HEAP_TIMER_H
8.日志系统
就像在写代码中通过printf来输出实现“你想知道某个变量的值是否达到了预期一样”,通过日志系统,程序原就可以了解到服务器在运行过程中的出现的一些具体请况,方便程序员快速的定位和修改问题。
一个合格的Web服务器当然少不了日志系统了。正如标题所言,日志系统在整个项目中能够帮助调试、错误定位、数据分析。我们想设计一个日志模块,他能顺利写日志但是又不要占用主线程时间去写,所以我们设计异步写日志的模块。
日志系统的实现需要考虑什么?
线程安全性还有效率问题。首先是线程安全方面,日志系统需要记录多个连接运行的情况,也就是说日志系统被多个线程拥有,这个时候需要考虑线程安全的问题,通过内部关键操作(涉及临界区资源的部分)进行加锁,实现每个线程对日志对象的访问不会产生冲突,避免日志写入的混乱。
另一个方面的话是效率问题,为了实现线程安全人为地加锁,而日志系统又需要进行IO操作,这样会导致线程持锁阻塞其他线程对锁地争用,同时大量地IO读写也会使当前调用日志对象的线程被阻塞在IO操作上,颠倒了事件处理优先级的顺序。效率这一块可以通过采用异步线程加双缓冲区写入的方式优化,调用日志对象的线程只需要完成两次内存拷贝,通过空间换时间的手法【双缓冲区是为了缓解内存读写速度和磁盘读写速度的差异导致部分数据丢失】,将磁盘IO操作交给单独的线程去处理,这样调用日志对象的线程能够保证尽可能地持锁时间短而且不会阻塞在IO操作上。
** 1. 知识点**
1.1 单例模式
单例模式是最常用的设计模式之一,目的是保证一个类只有一个实例,并提供一个他的全局访问点,该实例被所有程序模块共享。此时需要把该类的构造和析构函数放入private中。单例模式有两种实现方法,一种是懒汉模式,另一种是饿汉模式。
懒汉模式: 顾名思义,非常的懒,只有当调用getInstance的时候,才会去初始化这个单例。其中在C++11后,不需要加锁,直接使用函数内局部静态对象即可。
饿汉模式: 即迫不及待,在程序运行时立即初始化。饿汉模式不需要加锁,就可以实现线程安全,原因在于,在程序运行时就定义了对象,并对其初始化。之后,不管哪个线程调用成员函数getinstance(),都只不过是返回一个对象的指针而已。所以是线程安全的,不需要在获取实例的成员函数中加锁。
1.2 异步日志
同步日志:日志写入函数与工作线程串行执行,由于涉及到I/O操作,当单条日志比较大的时候,同步模式会阻塞整个处理流程,服务器所能处理的并发能力将有所下降,尤其是在峰值的时候,写日志可能成为系统的瓶颈。异步日志:将所写的日志内容先存入阻塞队列中,写线程从阻塞队列中取出内容,写入日志。
考虑到文件IO操作是非常慢的,所以采用异步日志就是先将内容存放在内存里,然后日志线程有空的时候再写到文件里。
日志队列是什么呢?他的需求就是时不时会有一段日志放到队列里面,时不时又会被取出来一段,这不就是经典的生产者消费者模型吗?所以还需要加锁、条件变量等来帮助这个队列实现。
1.3 可变参数模板
因为在服务器运行的情况很多很杂乱,所以日志的输出参数也一定是复杂的,多变的,这样子才方便程序员通过日志获得服务器运行的具体情况。这种状态下可变参数模板的使用,就可以很大程度上的解决这个问题。
2. 日志的运行流程
1、使用单例模式(局部静态变量方法)获取实例Log::getInstance()。2、通过实例调用Log::getInstance()->init()函数完成初始化,若设置阻塞队列大小大于0则选择异步日志,等于0则选择同步日志,更新isAysnc变量。
3、通过实例调用write_log()函数写日志,首先根据当前时刻创建日志(前缀为时间,后缀为".log",并更新日期today和当前行数lineCount。
4、在write_log()函数内部,通过isAsync变量判断写日志的方法:如果是异步,工作线程将要写的内容放进阻塞队列中,由写线程在阻塞队列中取出数据,然后写入日志;如果是同步,直接写入日志文件中。
- blockqueue
阻塞队列采用deque实现。
若MaxCapacity为0,则为同步日志,不需要阻塞队列。内部有生产者消费者模型,搭配锁、条件变量使用。
其中,消费者防止任务队列为空,生产者防止任务队列满。
- 日志的分级与分文件
分级情况:Debug,调试代码时的输出,在系统实际运行时,一般不使用。
Warn,这种警告与调试时终端的warning类似,同样是调试代码时使用。
Info,报告系统当前的状态,当前执行的流程或接收的信息等。
Erro,输出系统的错误信息
分文件情况:按天分,日志写入前会判断当前today是否为创建日志的时间,若为创建日志时间,则写入日志,否则按当前时间创建新的log文件,更新创建时间和行数。
按行分,日志写入前会判断行数是否超过最大行限制,若超过,则在当前日志的末尾加lineCount / MAX_LOG_LINES为后缀创建新的log文件。
#ifndef LOG_H
#define LOG_H
#include <mutex>
#include <string>
#include <thread>
#include <sys/time.h>
#include <string.h>
#include <stdarg.h> // vastart va_end
#include <assert.h>
#include <sys/stat.h> // mkdir
#include "../buffer/buffer.h"
#include"blockqueue.h"
class Log
{
public:
void init(int level,const char* path="./log",const char *suffix=".log",int QueueCapacity=1024);
//初始化日志的实例,日志类型,日志保存路径,日志后缀,阻塞队列的最大容量
static Log *Instance();
static void FlushLogThread(); //异步写日志的public方法,在函数中调用private的asyncWrite方法
void write(int level,const char*format,...); //格式化输出的日志内容,如果使用省略号,传递可变数量的参数时使用va_arg、va_start、va_end 和 va_list等宏,定义在<cstdarg>中(c中定义在<stdarg.h>)。
void flush(); //唤醒阻塞队列消费者,开始写日志
int GetLevel();
void SetLevel(int level);
bool IsOpen(){return isOpen_;}
private:
Log(const Log& t)=default;
Log& operator=(const Log& t)=default;
Log();
~Log();
void AppendLogLevelTitle_(int level);
void AsyncWrite_(); //异步写日志的方法
private:
static const int LOG_PATH_LEN =256; //日志文件最长文件路径
static const int LOG_NAME_LEN =256; //日志文件最长文件名
static const int MAX_LINES =50000; //日志文件所记录的最大条数
const char *path_;
const char *suffix_;
int MAX_LINES_; //当前文件中的最大日志条数
int Line_Counts; //日志行数记录
int today; //按照 天 来区分日志文件
bool isOpen_;
Buffer buff_; //输出的内容,先存放在缓存区里
int level_; //日志等级
bool isAsync_; //是否开启异步日志
FILE * fd_; //指向日志的文件描述符 //使用unique_ptr,是因为log只能有一个实例,且它的成员变量有且只能有一个,不能够拷贝给别人
std::unique_ptr<BlockQueue<std::string>> deque_; //阻塞队列
std::unique_ptr<std::thread> writeThread_; //异步写线程的指针
std::mutex m_mutex; //同步写日志的锁
};
#define LOG_BASE(level, format, ...)\
do {\
Log *log=Log::Instance();\
if(log->IsOpen()&&log->GetLevel()<=level){\
log->write(level,format,##__VA_ARGS__);\
log->flush();\
}\
}while (0);
#define LOG_DEBUG(format, ...) do {LOG_BASE(0, format, ##__VA_ARGS__)} while(0);
#define LOG_INFO(format, ...) do {LOG_BASE(1, format, ##__VA_ARGS__)} while(0);
#define LOG_WARN(format, ...) do {LOG_BASE(2, format, ##__VA_ARGS__)} while(0);
#define LOG_ERROR(format, ...) do {LOG_BASE(3, format, ##__VA_ARGS__)} while(0);
#endif
# ifndef BLOCKQUEUE_H
# define BLOCKQUEUE_H
#include <deque>
#include <condition_variable>
#include <mutex>
#include <sys/time.h>
using namespace std;
//可变参数的类模板
template<typename T>
class BlockQueue
{
public:
explicit BlockQueue(size_t maxsize=1024);//explicit
~BlockQueue();
bool empty(); //判断队列是否空
bool full(); //判断队列是否满
void push_back(const T &item); //给任务队列添加任务
void push_front(const T &item);
bool pop(T&item); //获取任务队列中的任务
bool pop(T&item,int timeout);
void clear(); //清空任务队列
T front(); //返回任务队列的头任务,但不修改任务队列
T back(); //返回任务队列的尾任务,但不修改任务队列
size_t capacity(); //容器的最大容量
size_t size(); //容器的元素个数
void Flush(); //唤醒消费者
void Close(); //容器的关闭
private:
deque<T>deq_; //底层数据结构容器
mutex m_mutex; //修改任务队列的锁
bool isClose;
size_t capacity_;
condition_variable not_Empty; //消费者的条件变量
condition_variable not_Full; //生产者的条件变量
};
//可变参数的函数模板
template<typename T>
BlockQueue<T>::BlockQueue(size_t maxsize):capacity_(maxsize)
{
assert(maxsize>0);
isClose=false;
}
template<typename T>
BlockQueue<T>::~BlockQueue()
{
Close();
}
template<typename T>
void BlockQueue<T>::Close()
{
clear();
isClose=true;
not_Empty.notify_all(); //相当于c中的条件变量signalbroadcast
not_Full.notify_all();
}
template<typename T>
void BlockQueue<T>::clear()
{
m_mutex.lock(); //也可以使用lock_guard和unique_lock这两种不同的类型上锁,lock_guard不需要自己手动解锁,而unique_lock可以选择是否自己手动解锁
deq_.clear();
m_mutex.unlock();
}
template<typename T>
bool BlockQueue<T>::full()
{
lock_guard<mutex> locker(m_mutex);
return deq_.size()>=capacity_;
}
template<typename T>
bool BlockQueue<T>::empty()
{
lock_guard<mutex> locker(m_mutex);
return deq_.empty();
}
template<typename T>
void BlockQueue<T>::push_back(const T &item)
{
unique_lock<mutex> locker(m_mutex);
while (deq_.size()>=capacity_)
{
not_Full.wait(locker);//先判断条件是否满足,不满足的话先释放锁然后阻塞线程,满足的话再重新获得锁
}
deq_.push_back(item);
not_Empty.notify_one();
}
template<typename T>
void BlockQueue<T>::push_front(const T &item)
{
unique_lock<mutex> locker(m_mutex);
while (deq_.size()>=capacity_)
{
not_Full.wait(locker);//先判断条件是否满足,不满足的话先释放锁然后阻塞线程,满足的话再重新获得锁
}
deq_.push_front(item);
not_Empty.notify_one();
}
template<typename T>
bool BlockQueue<T>::pop(T &item)
{
unique_lock<mutex> locker(m_mutex);
while (deq_.empty())
{
not_Empty.wait(locker);
if(isClose) return false;
}
item=deq_.front();
deq_.pop_front();
not_Full.notify_one();
return true;
}
template<typename T>
bool BlockQueue<T>::pop(T &item,int timeout)
{
unique_lock<mutex> locker(m_mutex);
while (deq_.empty())
{
if(not_Empty.wait_for(locker,std::chrono::seconds(timeout))
==std::cv_status::timeout)return false;
if(isClose) return false;
}
item=deq_.front();
deq_.pop_front();
not_Full.notify_one();
return true;
}
template<typename T>
T BlockQueue<T>::front()
{
lock_guard<mutex> locker(m_mutex);
return deq_.front();
}
template<typename T>
T BlockQueue<T>::back()
{
lock_guard<mutex> locker(m_mutex);
return deq_.back();
}
template<typename T>
size_t BlockQueue<T>::capacity()
{
lock_guard<mutex> locker(m_mutex);
return capacity_;
}
template<typename T>
size_t BlockQueue<T>::size()
{
lock_guard<mutex> locker(m_mutex);
return deq_.size();
}
template<typename T>
void BlockQueue<T>::Flush()
{
not_Empty.notify_one();
}
#endif
** 以上就是整个webserver的实现流程框架,这里总结一下,**
该项目总体框架采用的是单Reactor多线程模型,在主线程里面通过I/O多路复用监听多个文件描述符上的事件。主线程负责连接的建立和断开、把读写和逻辑处理函数加入线程池的任务队列,由线程池的子线程完成相应的读写操作,实现任务的高并发处理。在最底层实现了自动增长的Buffer缓冲区。在应用层方面实现心跳机制,通过定时器清楚掉不活跃的连接以减少高并发场景下不必要的系统资源的占用(文件描述符的占用、维护TCP连接所需要的资源等)。对于HTTP请求报文,采用分散读进行读取,使用有限状态机和正则表达式进行解析;并通过集中写和内存映射的方式对响应报文进行传输。应用层还实现了数据库功能,采用RAII机制实现连接池,可以实现基本的注册和登录功能。最后还加入了日志模块帮助工程项目开发和实现服务器的日常运行情况的记录。
解决方案
通过局部、自底向下的设计思想。以下是别人的,我觉得这个说的很好,下次也这样做项目了。
1.通过采用从局部到整体的设计思想。先使用单一线程完成串行的HTTP连接建立、HTTP消息处理和HTTP应答发送,然后围绕高并发这个核心扩展多个模块。
2.首先就是日志模块和缓冲区模块的一个设计,这里优先实现是为了下面各个模块的调试方便,记录各个模块运行的状况和打印输出模块运作情况来排除明显的BUG。
3.然后是引入I/O多路复用实现单线程下也能在一次系统调用中同时监听多个文件描述符,再进一步搭配线程池实现多客户多任务并行处理,这是高并发的核心部分。
4.在这个基础上做一点优化,在应用层实现了心跳机制,通过定时器实现非活跃连接的一个检测和中断,减少系统资源(内存)不必要的浪费。最后将所有模块整合起来,实现一个单Reactor多线程的网络设计模式,将多个模块串联起来实现完整高并发的服务器程序。
5.线程安全这块是通过不断将锁的粒度降低,平衡性能和安全。一开始采用粒度较粗的锁实现互斥(通常是整个操作),然后慢慢分析将一些不共享的代码移出临界区,慢慢调整慢慢优化。
6.最后加入数据库部分,因为这一部分比较独立,采用RAII机制创建连接池,拿出连接来使用。在HTTP中加入数据库信息验证的功能。
2.C++11新特性
整个项目中采用了较多的c++11以来的新特性,所以为了之后使用c++的时候Modern风格能够更明显一点,也是方便我复习和记忆这些新特性的功能和使用方法,所以就原地总结一下。
1.可变参数模板
c++11增加的变参数模板,今天总算整明白了 - 知乎 (zhihu.com)
【C++泛型编程】 C++ 模板 编程 可变参数模板 与 折叠表达式_哔哩哔哩_bilibili
原文中的使用的va_list完全就可以替换成可变参数的函数模板,再用snprintf替换vsnprintf,从而达到想要的输出日志的效果,例如:
c++之可变参数格式化字符串(c++11可变模板参数) - mohist - 博客园 (cnblogs.com)
2.explicit关键字
作用是防止类的有参构造函数中出现隐式调用
C++11 explicit关键字的作用_explicitc++11-CSDN博客
3.类中成员函数后面加 const表示函数不可以修改class的成员
4.atomic原子类型,保证了变量在同一时刻只能有一个线程对其进行操作
5.assert断言 assert的作用是先计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行。
6.struct_iovec,定义了一个向量元素,结构体中有两个变量,第一个变量是指向缓冲区的指针,第二个变量是缓冲区中存放bytes的大小,用于分散读(readv)和集中写(writev)
https://blog.csdn.net/baidu_15952103/article/details/109888362
iovec结构体定义及使用-CSDN博客
7.lock_guard/unique_lock 是一种关于mutex rall类型的变量,lock_guard/unique_lock上锁后,都会在锁的生命周期结束后自动解锁,unique_lock可以在所得生命结束前由程序员手动解锁,而lock_guard不行。
C++11多线程编程(三)——lock_guard和unique_lock - 知乎 (zhihu.com)
8.**智能指针 **
unique_ptr: unique_ptr 不共享它的指针。它无法复制到其他 unique_ptr,无法通过值传递到函数,也无法用于需要副本的任何标准模板库 (STL) 算法。只能移动unique_ptr。这意味着,内存资源所有权将转移到另一 unique_ptr,并且原始 unique_ptr 不再拥有此资源。
shared_ptr:
shared_ptr 是一种智能指针(smart pointer),作用有如同指针,但会记录有多少个shared_ptrs共同指向一个对象。这便是所谓的引用计数(reference counting)。一旦最后一个这样的指针被销毁,也就是一旦某个对象的引用计数变为0,这个对象会被自动删除。
C++11智能指针|巨巨巨详细 - 知乎 (zhihu.com)其他的智能指针可以参考这篇文章
9.lambda表达式,因为lambada表达式知识点还是挺多的,所以直接可以参考这篇文章
C++ Lambda表达式的完整介绍 - 知乎 (zhihu.com)
10.move 移动构造函数让一个对象它原本控制的内存的空间转移给构造出来的对象,这样就相当于把它移动过去了,而原本的那个对象的内存将会被置为空。
C++11——移动构造函数及std::move() 的使用_c++11移动构造函数的功能和用法-CSDN博客
11.f**orward 完美转发 **当我们将一个右值引用传入函数时,他在实参中有了命名,所以继续往下传或者调用其他函数时,根据C++ 标准的定义,这个参数变成了一个左值。那么他永远不会调用接下来函数的右值版本,这可能在一些情况下造成拷贝。为了解决这个问题 C++ 11引入了完美转发,根据右值判断的推倒,调用forward 传出的值,若原来是一个右值,那么他转出来就是一个右值,否则为一个左值。(这个完美转发是配合着move的移动构造函数配合使用,可以减少与线程池任务队列中的取/加任务的开销)
想要透彻理解C++11新特性:右值引用可以看这篇文章透彻理解C++11新特性:右值引用、std::move、std::forward-阿里云开发者社区 (aliyun.com)
12.四种强制类型转换
static_cast :static_cast用于将一种数据类型强制转换为另一种数据类型。
const_cast :const_cast用于强制去掉不能被修改的常数特性,但需要特别注意的是const_cast不是用于去除变量的常量性,而是去除指向常数对象的指针或引用的常量性,其去除常量性的对象必须为指针或引用。
reinterpret_cast : 在C++语言中,reinterpret_cast主要有三种强制转换用途:改变指针或引用的类型、将指针或引用转换为一个足够长度的整形、将整型转换为指针或引用类型**。
**
dynamic_cast
** 是C++中的一种类型转换运算符,主要用于在类继承层次结构中执行安全的向上或向下类型转换,并进行运行时类型检查,dynamic_cast只能用于具有虚函数的类(主要是父类向子类转换的时候要确保转换安全而使用)
【c++11特性】——static_cast,dynamic_cast,const_cast,reinterpret_cast解析_c++11 static_cast-CSDN博客
13.**回调函数和bind **
std::function<void(int)> Fun 声明指针函数,模板类。
std::bind()是C++11中的一个函数模板,用于将函数和其参数绑定到一个可调用对象上。它可以用于创建一个函数对象,这个函数对象可以调用原来的函数并传递预先绑定的参数。(项目中使用bind是在类内调用的所以要添加this指针)
bind绑定类成员函数时,第一个参数表示对象的成员函数的指针,第二个参数表示对象的地址,这是因为对象的成员函数需要有this指针。并且编译器不会将对象的成员函数隐式转换成函数指针,需要通过&手动转换
14.处理时间和日期的chorno库
chrono库中最主要三种类:
时间间隔duration
、
时钟clocks
、
时间点time point
**时间间隔**:
template<class Rep, class Period = std::ratio<1>>这是duration的模板,Rep就表示时间间隔数字的类型,比如double,int这种,如果为double,时间间隔的数字可以设置为0.01s,或者0.01ms。ratio则表示时间间隔的单位,例如秒,毫秒,分钟等。为了方便使用,库里直接定义了大部分常用的时间单位,所以ratio可以直接使用下面定义的模板
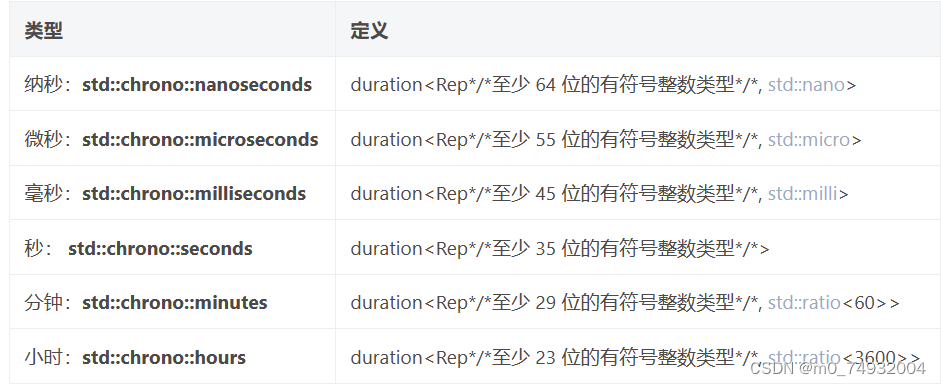
时钟:

**
时间点:
**
顾名思义表示的就是到达具体某个点的时间,比如当前时间就是一个时间点,就我写这篇文章的时候的上一个小时也是个时间。时间点经常搭配时钟来一起使用,所以可以看一下有关于时钟的使用,都会包含对于时间点的使用。
处理日期和时间的chrono库 | 爱编程的大丙 (subingwen.cn)
利用到的新特性就这些,如果后面再遇到新的c++11新特性,应该还会再记录一下
版权归原作者 氢氦锂皮彭 所有, 如有侵权,请联系我们删除。