
Pandas 库是用于数据分析的流行 Python 包。Pandas 中处理数据集时,结构将是二维的,由行和列组成,也称为dataframe。然而,数据分析的一个重要部分是对这些数据进行分组、汇总、聚合和计算统计的过程。
Pandas 数据透视表提供了一个强大的工具来使用 python 执行这些分析技术。
如果你是excel用户,那么可能已经熟悉数据透视表的概念。Pandas 数据透视表的工作方式与 Excel 等电子表格工具中的数据透视表非常相似。数据透视表函数接受一个df,一些参数详细说明了您希望数据采用的形状,并且输出是以数据透视表的形式汇总数据。
在下面的文章中,我将通过代码示例简要介绍 Pandas 数据透视表工具。
数据
在本教程中,我将使用一个名为“autos”的数据集。该数据集包含有关汽车的一系列特征,例如品牌、价格、马力和每公里油耗等。
数据可以从 openml 下载。或者可以使用 scikit-learn API 将代码直接导入到代码中,如下所示。
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_openml
X,y = fetch_openml("autos", version=1, as_frame=True, return_X_y=True)
data = X
data['target'] = y
透视表剖析
Pandas 数据透视表具有三个主要元素。索引指定行级分组,列指定列级分组和值,这些值是您要汇总的数值。
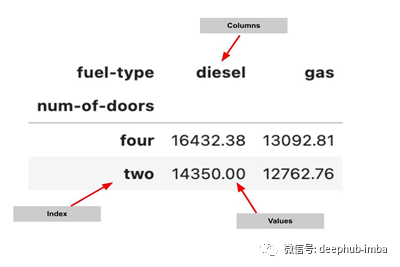
用于创建上述数据透视表的代码如下所示。在 pivot_table 函数中,我们指定要汇总的df,然后是值、索引和列的列名。此外,我们指定了我们想要使用的计算类型,我们以计算平均值为例。
pivot = np.round(pd.pivot_table(data, values='price',
index='num-of-doors',
columns='fuel-type',
aggfunc=np.mean),2)
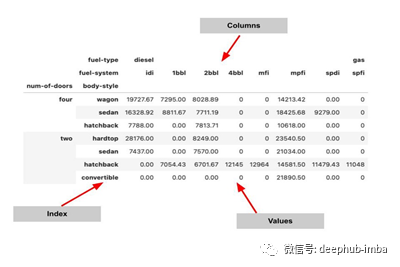
数据透视表可以是多级的。我们可以使用多个索引和列级分组来创建更强大的数据集摘要。
pivot = np.round(pd.pivot_table(data, values='price',
index=['num-of-doors', 'body-style'],
columns=['fuel-type', 'fuel-system'],
aggfunc=np.mean,
fill_value=0),2)
可视化
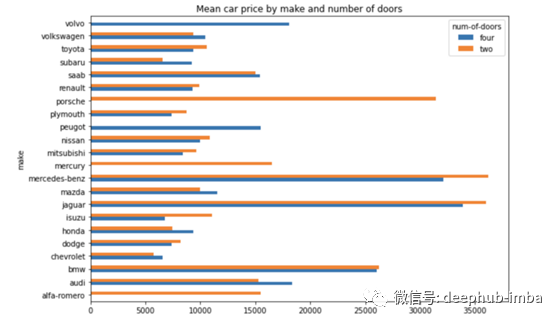
Pandas 数据透视表可与 Pandas 绘图功能结合使用,以创建有用的数据可视化。
只需将 .plot() 添加到数据透视表代码的末尾即可创建数据图。例如,下面的代码创建了一个条形图,显示了按品牌和门数划分的平均汽车价格。
np.round(pd.pivot_table(data, values='price',
index=['make'],
columns=['num-of-doors'],
aggfunc=np.mean,
fill_value=0),2).plot.barh(figsize=(10,7),
title='Mean car price by make and number of doors')
计算和统计
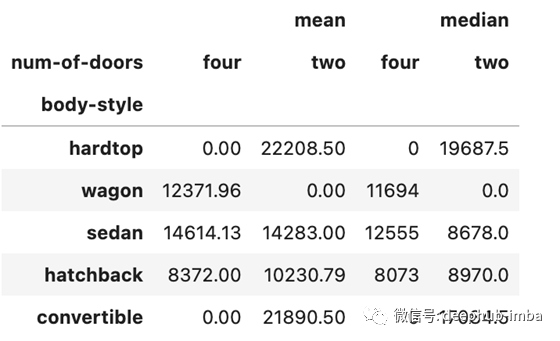
数据透视表函数中的 aggfunc 参数可以进行一项或多项标准计算。
以下代码计算body-style和num-of-doors的平均价格和中位数价格。
np.round(pd.pivot_table(data, values='price',
index=['body-style'],
columns=['num-of-doors'],
aggfunc=[np.mean, np.median],
fill_value=0),2)
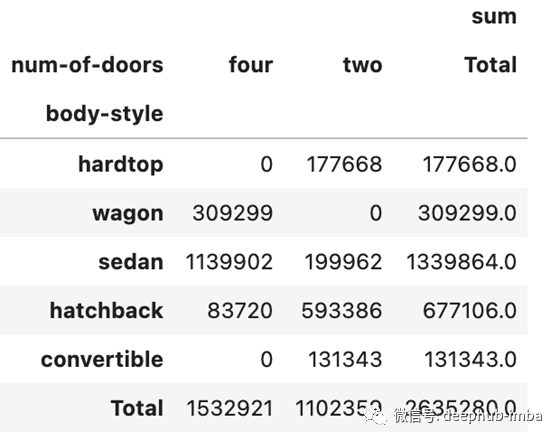
要将总计添加到列和行,可以简单地添加参数 margins=True 实现并且您可以使用 margins_name 为总计指定一个名称。
np.round(pd.pivot_table(data, values='price',
index=['body-style'],
columns=['num-of-doors'],
aggfunc=[np.sum],
fill_value=0,
margins=True, margins_name='Total'),2)
样式
在汇总数据时,样式很重要。我们希望确保数据透视表提供的模式和见解易于阅读和理解。在本文前面部分使用的数据透视表中,应用了很少的样式,因此,这些表不容易理解或没有视觉上的重点。
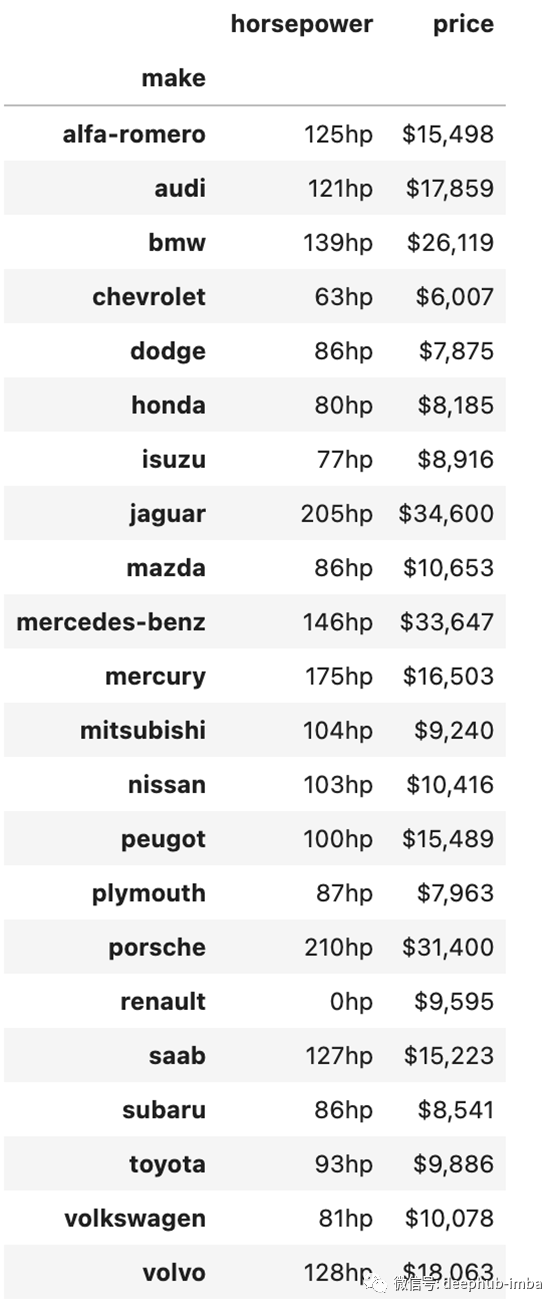
我们可以使用另一种 Pandas 方法,称为样式方法,使表格看起来更漂亮,更容易从中得出见解。下面的代码为此数据透视表中使用的每个值添加了适当的格式和度量单位。现在更容易区分这两列并理解数据告诉您的内容。
pivot = np.round(pd.pivot_table(data, values=['price', 'horsepower'],
index=['make'],
aggfunc=np.mean,
fill_value=0),2)
pivot.style.format({'price':'${0:,.0f}',
'horsepower':'{0:,.0f}hp'})
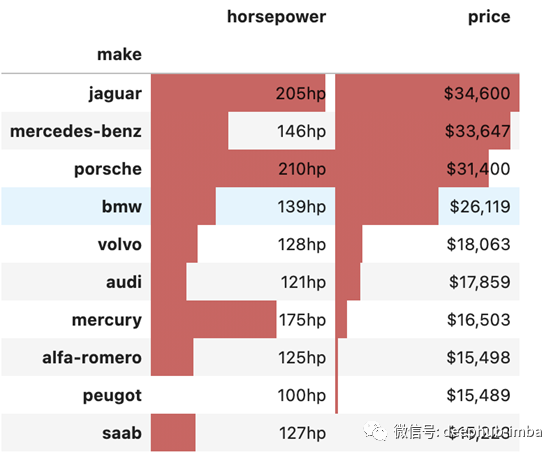
我们可以使用styler组合不同的格式,并使用 Pandas 内置样式以一种好的方式汇总数据。在下面显示的代码和数据透视表中,我们按价格从高到低对汽车制造商进行了排序,为数字添加了适当的格式,并添加了一个覆盖两列值的条形图。这使得很容易得出结论,例如哪种品牌的汽车最贵,以及马力与每种品牌的价格之间的关系。
pivot = np.round(pd.pivot_table(data, values=['price', 'horsepower'],
index=['make'],
aggfunc=np.mean,
fill_value=0),2)
pivot = pivot.reindex(pivot['price'].sort_values(ascending=False).index).nlargest(10, 'price')
pivot.style.format({'price':'${0:,.0f}',
'horsepower':'{0:,.0f}hp'}).bar(color='#d65f5f')
总结
数据透视表自 90 年代初开始使用,微软于 1994 年为著名的 Excel 版本“数据透视表”申请了专利。它们今天仍在广泛使用,因为它们是分析数据的强大工具。Pandas 数据透视表将这个工具从电子表格中带到了 python 用户的手中。
本指南简要介绍了 Pandas 中数据透视表工具的使用。它旨在为初学者提供一个快速教程来启动和运行,但我建议深入研究 Pandas 文档,其中提供了有关此功能的更深入指南。
作者:Rebecca Vickery