
稳定扩散模型因其从文本描述生成高质量、多样化图像的能力而获得了极大的关注。但是这些预训练模型在生成高度定制或个性化主题的图像时可能会有所不足。
这时就需要我们进行手动的微调。微调可以根据相对较小的图像集向模型教授新的、独特的主题。我们今天使用DreamBooth在不影响模型原始功能的情况下实现微调过程。
基础概念
1、生成模型和文本到图像的合成
生成模型是一类机器学习模型,旨在生成与给定数据集相似的新数据实例。他们捕捉潜在的数据分布,产生新的样本。
文本到图像模型是生成模型的一个子集,因为它们以极高的准确性和保真度将文本描述转换为相应的视觉表示而特别有趣。
Stable Diffusion是一种文本到图像的模型,它利用Transformer架构的一种变体来根据文本输入生成图像。
这些模型的生成过程可以描述如下:
给定一个文本描述T,模型的目标是生成一个图像I,使联合概率P(I,T)最大化。这通常是通过训练模型来最大化条件概率P(I∣T)来实现的,以确保生成的图像与文本描述一致。
2、生成模型的微调
微调是指在一个新的、通常更小的数据集上调整预训练的模型,以使模型适应特定的需求,而不会失去从原始数据集学习到的泛化性。这种方法在数据稀缺或需要定制的应用程序中至关重要。
在数学上,微调调整模型的参数θ以优化新数据集Dnew上的损失函数L,同时防止与原始参数θ origin的显著偏差。这可以被表述为一个正则化问题:
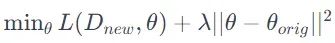
3、DreamBooth
DreamBooth提出了一种新的微调方法,允许生成具有特定主题或对象的图像,同时保持模型生成不同图像的能力。
传统的微调可能会导致过度拟合或灾难性遗忘(忘记原始数据分布),DreamBooth则能确保模型保留其一般功能。
该过程包括训练特定于主题的标记以及原始模型参数。这在概念上类似于向模型的词汇表中添加一个代表新主题的新“单词”。训练的目标可以描述为:
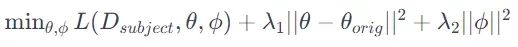
其中φ表示主题特定参数,1,2λ1,λ2为正则化参数。
更详细内容请看原论文 《DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation》
技术准备
使用DreamBooth微调像Stable Diffusion这样的生成模型需要大量的计算,并且需要大量的内存。为了确保训练过程的效率并避免潜在的瓶颈,强烈建议使用高性能GPU。
如果没有GPU,我们可以直接使用Google Colab,他就可以满足本文的需求。
然后需要安装以下库
Diffusers:扩散模型库,专门用于微调和利用预训练模型。
Accelerate:一个用于分布式训练和混合精度的库。
TensorBoard:用于可视化训练进度和指标。
transformer、FTFY和Gradio:用于模型组件、文本处理和创建用于模型交互的web ui。
Bitsandbytes:用于内存高效和快速训练,特别是用于优化特定GPU架构上的模型训练。
!pip install -U -qq git+https://github.com/huggingface/diffusers.git
!pip install -qq accelerate tensorboard transformers ftfy gradio
!pip install -qq "ipywidgets>=7,<8"
!pip install -qq bitsandbytes
!pip install huggingface_hub
为了更快、更节省内存的训练,特别是如果使用特定类型的gpu (T4、P100、V100、A100),还可以选择安装以下组件:
Xformers:提供高效transformers 组件的库。
Triton:用于gpu编程。
然后我们开始进行代码的编写,首先导入库:
importargparse
importitertools
importmath
importos
fromcontextlibimportnullcontext
importrandom
importnumpyasnp
importtorch
importtorch.nn.functionalasF
importtorch.utils.checkpoint
fromtorch.utils.dataimportDataset
importPIL
fromaccelerateimportAccelerator
fromaccelerate.loggingimportget_logger
fromaccelerate.utilsimportset_seed
fromdiffusersimportAutoencoderKL, DDPMScheduler, PNDMScheduler, StableDiffusionPipeline, UNet2DConditionModel
fromdiffusers.optimizationimportget_scheduler
fromdiffusers.pipelines.stable_diffusionimportStableDiffusionSafetyChecker
fromPILimportImage
fromtorchvisionimporttransforms
fromtqdm.autoimporttqdm
fromtransformersimportCLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
importbitsandbytesasbnb
defimage_grid(imgs, rows, cols):
assertlen(imgs) ==rows*cols
w, h=imgs[0].size
grid=Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h=grid.size
fori, imginenumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
returngrid
数据集的准备
这个过程包括选择有代表性的图像,对它们进行预处理,并将它们组织成一个结构化的格式以供训练。在本文中,我们将使用以下4个训练图像作为示例。

1、下载和可视化训练图像
下面的download_image函数用于从指定的url列表中检索图像,然后下载这些图像并将其转换为RGB格式以保持一致性。
我们将使用他来下载上面的4个图片
urls= [
"https://huggingface.co/datasets/Entreprenerdly/finetunestablediffusion/resolve/main/2.jpeg",
"https://huggingface.co/datasets/Entreprenerdly/finetunestablediffusion/resolve/main/3.jpeg",
"https://huggingface.co/datasets/Entreprenerdly/finetunestablediffusion/resolve/main/5.jpeg",
"https://huggingface.co/datasets/Entreprenerdly/finetunestablediffusion/resolve/main/6.jpeg",
## Add additional images here
]
importrequests
importglob
fromioimportBytesIO
defdownload_image(url):
try:
response=requests.get(url)
except:
returnNone
returnImage.open(BytesIO(response.content)).convert("RGB")
images=list(filter(None,[download_image(url) forurlinurls]))
save_path="./my_concept"
ifnotos.path.exists(save_path):
os.mkdir(save_path)
[image.save(f"{save_path}/{i}.jpeg") fori, imageinenumerate(images)]
image_grid(images, 1, len(images))

2、创建图像文字对
为了使用DreamBooth对生成模型进行微调,需要配置特定的设置以有效地定义新概念。instance_prompt非常重要,因为它包含一个描述性标识符,模型使用它来识别和生成新概念——在本例中是cat_toy。
prior_preservation标志指示模型在训练期间是否应该保留更广泛的类属性。这有助于提高质量和泛化,但可能会延长训练时间。
instance_prompt="<cat-toy> toy" # Descriptive prompt with unique identifier
prior_preservation=False # Flag for enabling class characteristics preservation
prior_preservation_class_prompt="a photo of a cat clay toy" # Prompt for the class of the concept
# Parameters for class image generation and loss weighting
num_class_images=12
sample_batch_size=2
prior_loss_weight=0.5
prior_preservation_class_folder="./class_images"
# Directories for storing class images
class_data_root=prior_preservation_class_folder
class_prompt=prior_preservation_class_prompt
3、自定义DataSet类
DreamBoothDataset类扩展了PyTorch的Dataset,用于管理用于训练模型的图像数据。它负责从指定的目录加载图像,应用所需的转换,并使用提供的标记器对提示进行编码。
另一个类PromptDataset被设置为处理类图像提示的生成。这个简单的数据集结构存储了提示和要生成的样本数量。
这些类有助于为DreamBooth微调过程构建训练数据,确保模型以预期的格式接收数据并进行必要的扩展。
# Initialization of DreamBoothDataset with directory paths and settings
classDreamBoothDataset(Dataset):
...
def__init__(self, instance_data_root, instance_prompt, tokenizer, class_data_root=None, class_prompt=None, size=512, center_crop=False):
...
self.image_transforms=transforms.Compose([...])
def__getitem__(self, index):
...
returnexample
# Class for prompt dataset
classPromptDataset(Dataset):
...
优于篇幅太长,我们就不贴完整代码了,请在最后的完整代码中查看
模型加载与配置
我们将使用stable-diffusion-2
pretrained_model_name_or_path = "stabilityai/stable-diffusion-2"
然后就是与DreamBooth微调相关的配置参数包括加载模型体系结构的各种组件:文本编码器、变分自动编码器(VAE)和U-Net。
每个组件都是从预训练的模型中加载的,以确保兼容性并保留学习到的特征。
# Load models and create wrapper for stable diffusion
text_encoder=CLIPTextModel.from_pretrained(
pretrained_model_name_or_path, subfolder="text_encoder"
)
vae=AutoencoderKL.from_pretrained(
pretrained_model_name_or_path, subfolder="vae"
)
unet=UNet2DConditionModel.from_pretrained(
pretrained_model_name_or_path, subfolder="unet"
)
tokenizer=CLIPTokenizer.from_pretrained(
pretrained_model_name_or_path,
subfolder="tokenizer",
)
这里的CLIPTextModel负责将文本描述编码为嵌入;AutoencoderKL处理图像的潜在空间表示;UNet2DConditionModel是模型的主要生成网络;tokenizer则是处理词元令牌的标记器。
微调
1、设置训练参数
训练参数封装在argparse模块的Namespace类中。这些参数包括预训练模型的路径、图像的分辨率、是否训练文本编码器、学习率以及与启用之前保存相关的细节。
fromargparseimportNamespace
args=Namespace(
pretrained_model_name_or_path=pretrained_model_name_or_path,
resolution=vae.sample_size,
center_crop=True,
train_text_encoder=False,
instance_data_dir=save_path,
instance_prompt=instance_prompt,
learning_rate=5e-06,
max_train_steps=300,
save_steps=50,
train_batch_size=2, # set to 1 if using prior preservation
gradient_accumulation_steps=2,
max_grad_norm=1.0,
mixed_precision="fp16", # set to "fp16" for mixed-precision training.
gradient_checkpointing=True, # set this to True to lower the memory usage.
use_8bit_adam=True, # use 8bit optimizer from bitsandbytes
seed=3434554,
with_prior_preservation=prior_preservation,
prior_loss_weight=prior_loss_weight,
sample_batch_size=2,
class_data_dir=prior_preservation_class_folder,
class_prompt=prior_preservation_class_prompt,
num_class_images=num_class_images,
lr_scheduler="constant",
lr_warmup_steps=100,
output_dir="dreambooth-concept",
)
2、定义训练函数
训练函数负责微调过程。它初始化Accelerator以处理分布式训练,为调试复现设置随机种子,配置优化器(使用8位精度以提高内存效率)。
该函数还准备数据集和数据加载器,设置学习率调度器,并定义训练循环,其中包括损失计算和模型更新。
下面是训练函数设置的代码片段:
fromaccelerate.utilsimportset_seed
deftraining_function(text_encoder, vae, unet):
logger=get_logger(__name__)
set_seed(args.seed)
...
ifargs.use_8bit_adam:
optimizer_class=bnb.optim.AdamW8bit
else:
optimizer_class=torch.optim.AdamW
...
3、训练
实际的训练是使用accelerate库中的notebook_launcher启动的,它接受训练函数和先前定义的参数。
importaccelerate
accelerate.notebook_launcher(training_function, args=(text_encoder, vae, unet))
forparaminitertools.chain(unet.parameters(), text_encoder.parameters()):
ifparam.gradisnotNone:
delparam.grad # free some memory
torch.cuda.empty_cache()
推理
使用StableDiffusionPipeline设置推理管道:
fromdiffusersimportStableDiffusionPipeline, DPMSolverMultistepScheduler
try:
pipe
exceptNameError:
pipe=StableDiffusionPipeline.from_pretrained(
args.output_dir,
scheduler=DPMSolverMultistepScheduler.from_pretrained(args.output_dir, subfolder="scheduler"),
torch_dtype=torch.float16,
).to("cuda")
在Gradio和/或Google Colab上运行Pipeline
importgradioasgr
definference(prompt, num_samples):
images=pipe(prompt, num_images_per_prompt=num_samples, num_inference_steps=25).images
returnimages
withgr.Blocks() asdemo:
prompt=gr.Textbox(label="prompt")
samples=gr.Slider(label="Samples", value=1)
run=gr.Button(value="Run")
gallery=gr.Gallery(show_label=False)
run.click(inference, inputs=[prompt, samples], outputs=gallery)
demo.launch()
如果是Colab,则使用下面代码
prompt = "a <cat-toy> in mad max fury road"
num_samples = 2
all_images = []
images = pipe(prompt, num_images_per_prompt=num_samples, num_inference_steps=25, guidance_scale=9).images
all_images.extend(images)
grid = image_grid(all_images, num_rows, num_samples)

总结
dreambooth通过向模型注入自定义的主题来fine-tune diffusion model,它简化了我们微调自定义模型的成本,而Google Colab的免费GPU可以让我们进行更多的测试,以下是本文的完整代码,可以直接在线测试:
https://colab.research.google.com/drive/1muBY-yFCu_jAxnxeNW0RGwwNQhWQsE24
作者:Cris Velasquez