
文章目录
训练一个神经网络的时候,中途出现
Killed,然后程序就被终止了。
- 因为以前遇到过这个问题,所以知道是因为内存不足所以系统将程序终止了。
- 不过这次想认真看一下系统日志,看一下内存等的消耗状况,然后再考虑解决方案。
1. 查看Killed对应的日志
1.1 触发Killed常见原因
当系统资源不足时,Linux 内核也可以决定终止一个或多个进程。 一个非常常见的例子是内存不足 (OOM) killer,会在系统的物理内存耗尽时触发。
- 当内存不足时,内核会将相关信息记录到内核日志缓冲区中,该缓冲区可通过
/dev/kmsg获得。 - 有几个工具/脚本/命令 可以更轻松地从该虚拟设备读取数据,其中最常见的是
dmesg和journalctl。
1.2 查看Killed日志
**使用
sudo dmesg | tail -7
命令**(任意目录下,不需要进入
log
目录,这应该是最简单的一种)
hs@hs:~$ sudodmesg|tail -7
[4772612.871775][1125836]1000112583625399116144000bash[4772612.871777][1126560]1000112656017874745324800 tmux: client
[4772612.871779][1138439]10001138439202948914124611284505600 python3
[4772612.871781][1141425]100011414251809384915200sleep[4772612.871783] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/user.slice/user-1000.slice/session-1549.scope,task=python3,pid=1138439,uid=1000[4772612.871840] Out of memory: Killed process 1138439(python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
[4772612.968800] oom_reaper: reaped process 1138439(python3), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
可以看到:
oom-kill之后,就是解释那个被killed的程序的pid和uidOut of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB,内存不够 - total_vm:总共使用的虚拟内存 Virtual memory use (in 4 kB pages) 8117956/1024(得到MB)/1024(得到GB)=7.741GB- rss:常驻内存使用Resident memory use (in 4 kB pages) 5649844/1024/1024=5.388GB
另外,网上还有几种方式,如下:
使用下面的这几行命令
journalctl --list-boots |
awk ‘{ print $1 }’ |
xargs -I{} journalctl --utc --no-pager -b {} -kqg ‘killed process’ -o verbose --output-fields=MESSAGE
就可以直接得到,最关键的信息
hs@hs:~$ journalctl --list-boots |\>awk'{ print $1 }'|\>xargs -I{} journalctl --utc --no-pager -b {} -kqg 'killed process' -o verbose --output-fields=MESSAGE
Mon 2022-02-14 08:48:43.684987 UTC [s=ed0a1ecfd36e41bda458e5e111c46e95;i=d4573;b=7bc379f894944dcd81ae32ff54afa009;m=456b0ad36d2;t=5d7f67bdee47b;x=5bfe01f8e2ca9b2c]MESSAGE=Out of memory: Killed process 1125888(python3) total-vm:8530488kB, anon-rss:5653404kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12552kB oom_score_adj:0
Mon 2022-02-14 09:29:43.854158 UTC [s=ed0a1ecfd36e41bda458e5e111c46e95;i=d4785;b=7bc379f894944dcd81ae32ff54afa009;m=45743506aa5;t=5d7f70e82184e;x=9b55cfb2e7c081e7]MESSAGE=Out of memory: Killed process 1138439(python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
网上更常见的似乎是:
journalctl -xb | egrep -i 'killed process’
hs@hs:~$ journalctl -xb |egrep -i 'killed process'
Feb 14 08:48:43 hs kernel: Out of memory: Killed process 1125888(python3) total-vm:8530488kB, anon-rss:5653404kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12552kB oom_score_adj:0
Feb 14 09:29:43 hs kernel: Out of memory: Killed process 1138439(python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
Feb 15 03:42:08 hs sudo[1151639]: hs :TTY=pts/0 ;PWD=/home/hs ;USER=root ;COMMAND=/usr/bin/egrep -i -r killed process /var/log
以及
sudodmesg|egrep -i -B100 'killed process'# 但是这个会输出非常多的信息。。。
其中
-B100
,表示 'killed process’之前的100行内容
其中有一部分信息也许有用,如下所示,类似一个表格
- 重点关注其中最后两列:
oom_score_adj和name - 可以看到,有些服务常驻内存,所以占了不少内存,考虑清理出去。
- 同时killed之后,似乎有些内存,不会从内存中自动释放。需要手动释放。
[4770152.819134] Tasks state (memory values in pages):
[4770152.819135][ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name
[4770152.819138][414]0414700684518901120 -1000 multipathd
[4770152.819142][704]07046033069810649600 accounts-daemon
[4770152.819144][708]070821366105734400cron[4770152.819775][734]0734737238709420800 python3
[4770152.819777][735]07359505194915200 atd
[4770152.819790][1033]0103382072559013107200 python3
[4770152.819792][1577]015773046915614400 -1000 sshd
[4770152.819795][29492]100029492466311877372800 systemd
[4770152.819798][29493]10002949342531119610240000(sd-pam)[4770152.819800][135845]01358454574333853383558400 nebula-metad
[4770152.819802][135908]01359083336672493638502400 nebula-graphd
[4770152.819804][135927]0135927592451139719168755200 nebula-storaged
[4770152.819818][689086]068908629221271322867200 -900 snapd
[4770152.819821][694790]100069479017796416144000 dbus-daemon
[4770152.819823][699514]10006995144071295193147456000 node
[4770152.819825][699523]10006995234163987757163430400 node
[4770152.819827][699549]100069954948931711361249446400 node
[4770152.819830][699555]100069955548841610836253132800 node
[4770152.819832][699559]100069955948894510316246169600 node
[4770152.819835][1102457]01102457349110106553600 sshd
[4770152.819837][1102573]1000110257334914286553600 sshd
[4770152.819839][1102574]1000110257422155745734400bash[4770152.819841][1102636]100011026366541224096000sh[4770152.819843][1102643]10001102643403507180866373145600 node
[4770152.819845][1102681]100011026812339446666126566400 node
[4770152.819847][1102707]1000110270722141113611276889600 node
[4770152.819849][1102777]1000110277725359524915200bash[4770152.819851][1103566]100011035662077461375972089600 node
[4770152.819853][1110927]11311109272395391627318888422400 java
[4770152.819856][1121028]100011210281488563907652863027200 python3
[4770152.819858][1125835]1000112583519836594915200 tmux: server
[4770152.819860][1125836]1000112583625399446144000bash[4770152.819862][1125888]10001125888213262214133511285324800 python3
[4770152.819864][1126560]1000112656017875695324800 tmux: client
[4770152.819867][1137700]100011377001809384915200sleep
另外,还有
egrep -i ‘killed process’ /var/log/messages 或
egrep -i -r ‘killed process’ /var/log
hs@hs:~$ sudoegrep -i -r 'killed process' /var/log
Binary file /var/log/journal/482df032dea642279e0da48fa9dd4a1a/system.journal matches
/var/log/auth.log:Feb 15 03:42:08 hs sudo: hs :TTY=pts/0 ;PWD=/home/hs ;USER=root ;COMMAND=/usr/bin/egrep -i -r killed process /var/log
/var/log/syslog.1:Feb 14 08:48:43 hs kernel: [4770152.820348] Out of memory: Killed process 1125888(python3) total-vm:8530488kB, anon-rss:5653404kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12552kB oom_score_adj:0
/var/log/syslog.1:Feb 14 09:29:43 hs kernel: [4772612.871840] Out of memory: Killed process 1138439(python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
/var/log/kern.log.1:Feb 14 08:48:43 hs kernel: [4770152.820348] Out of memory: Killed process 1125888(python3) total-vm:8530488kB, anon-rss:5653404kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12552kB oom_score_adj:0
/var/log/kern.log.1:Feb 14 09:29:43 hs kernel: [4772612.871840] Out of memory: Killed process 1138439(python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
1.3 dmesg输出信息说明
参考:Out of Memory events and decoding their logging
参数解释pid进程IDuid用户IDtgid线程组IDtotal_vm总共使用的虚拟内存 Virtual memory use (in 4 kB pages)rss常驻内存使用Resident memory use (in 4 kB pages)nr_ptes页表实体Page table entriesswapents页表实体Page table entriesoom_score_adj通常为 0。较小的数字表示在调用 OOM 杀手时进程不太可能死亡。(oom会优先kill分数高的进程,分数高表示占用内存资源多)
参考:
- linux 程序被Killed,如何精准查看日志
- https://www.baeldung.com/linux/what-killed-a-process
- What killed my process and why?
2. 释放无用内存占用
2.1 查看系统内存情况
查看系统内存情况:cat /proc/meminfo
hs@hs:~$ cat /proc/meminfo
MemTotal: 14331380 kB
MemFree: 9515720 kB
MemAvailable: 9947704 kB
Buffers: 141952 kB
查看当前空闲内存:
free -m
(以MB显示内存情况),
free -g
(以GB显示内存情况)
hs@hs:~$ free -m
total used free shared buff/cache available
Mem: 1399540008308116869656
Swap: 000
hs@hs:~$ free -g
total used free shared buff/cache available
Mem: 1338019
Swap: 000
2.2 修改OOM触发条件来解决OOM Killer
参考:Linux OOM-killer(内存不足时kill高内存进程的策略)
OOM_killer是Linux自我保护的方式,当内存不足时不至于出现太严重问题,有点壮士断腕的意味
在kernel 2.6,内存不足将唤醒oom_killer,挑出
/proc/<pid>/oom_score
最大者并将之kill掉
- 为了保护重要进程不被oom-killer掉,可以:- `echo -17 > /proc//oom_adj,- 17表示禁用OOM
- 也可以对把整个系统的OOM给禁用掉:-
sysctl -w vm.panic_on_oom=1(默认为0,表示开启)-sysctl -p - 值得注意的是,有些时候
free -m时还有剩余内存,但还是会触发OOM-killer,可能是因为进程占用了特殊内存地址- 平常应该留意下新进来的进程内存使用量,免得系统重要的业务进程被无辜牵连- 可用top M查看最消耗内存的进程,但也不是进程一超过就会触发oom_killer - 参数
/proc/sys/vm/overcommit_memory可以控制进程对内存过量使用的应对策略- 当overcommit_memory=0,允许进程轻微过量使用内存,但对大量过载请求则不允许(默认)- 当overcommit_memory=1,永远允许进程overcommit- 当overcommit_memory=2,永远禁止overcommit
2.3 释放无用内存
2.3.1 top命令
查看某个用户的内存使用情况
查看当前内存使用情况,使用
top
命令,如果要查看某个用户的内存使用情况,可以
top -u username
,例如:
top -u hs # 查看某个用户的内存使用情况
可以使用
q
退出top界面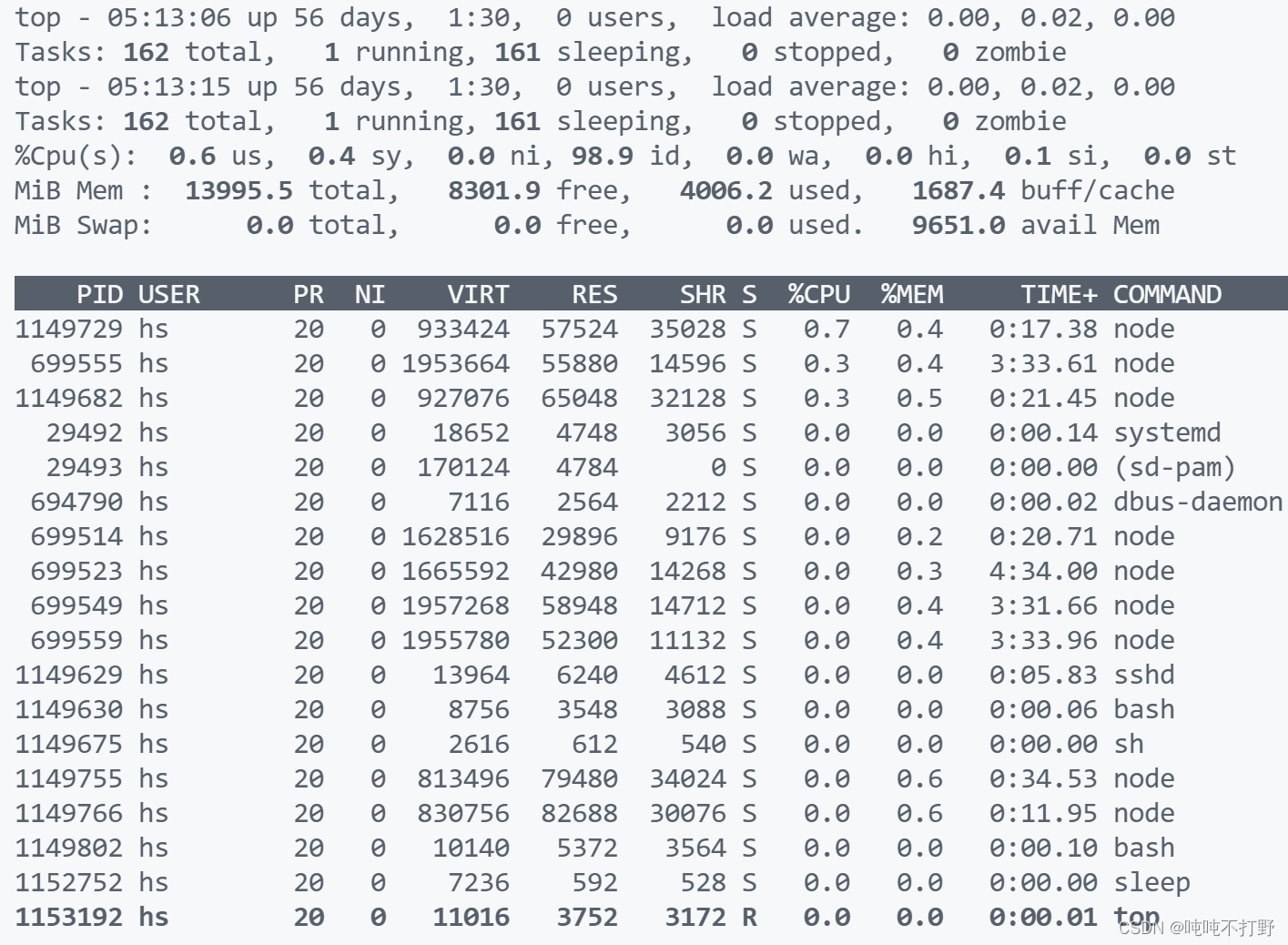
查看详细的command内容
如果想查看详细的command,可以使用
-c
参数
top -u hs -c
然后就会显示每个command的详细内容,例如: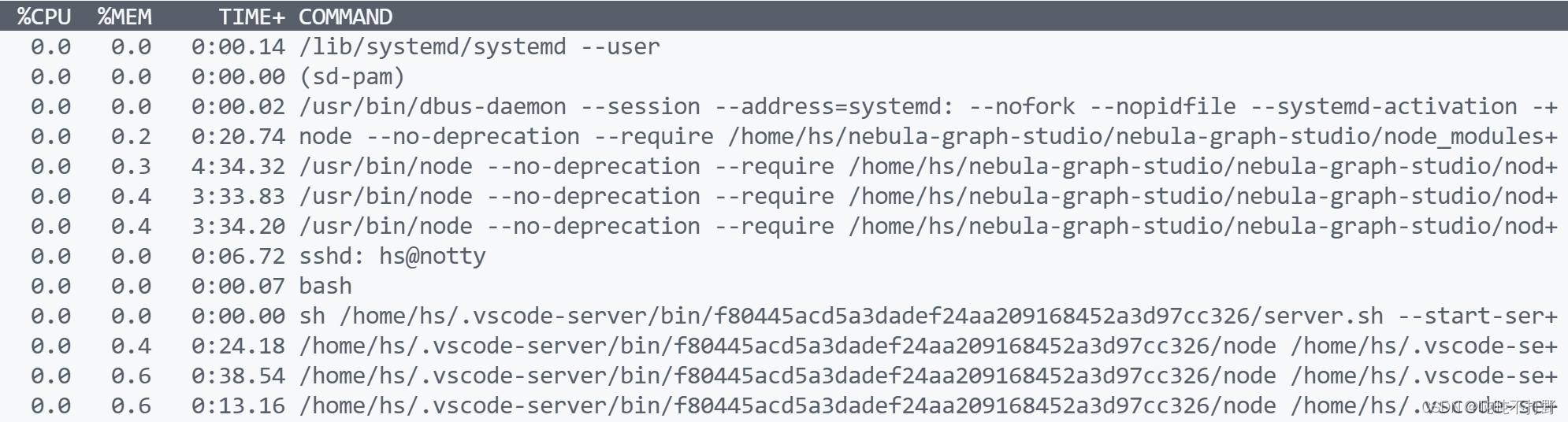
查看特定PID或进程的资源消耗情况
进一步,如果希望查看这个用户下某个特定 command的占用情况,可以使用
grep
命令来进一步处理
top
命令的输出,参考:How to view a specific process in top
top -p `pgrep -d "," node`# 正解
top -p pid1,pid2: 展示多个进程信息,PID之间用逗号隔开pgrep -d "," java: 打印出所有含有java词的PID的信息- 如果看到类似
top: -p argument missing这样的提示,说明当前没有在运行的java程序,所以pgrep没有输出
输出以下内容: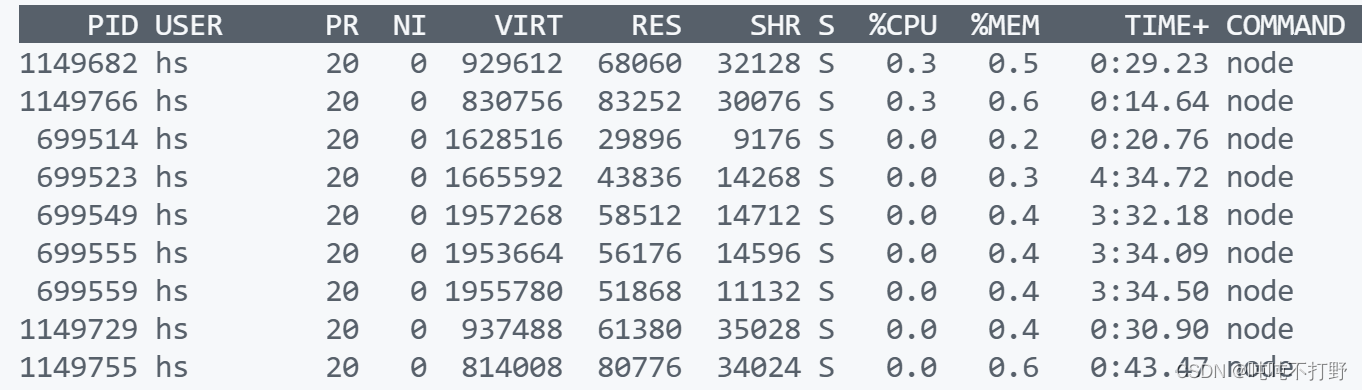
为什么%MEM大于100%
参考:Sum of memory of few processes in top is greater than 100%
- 大致意思就是这里的%MEM会包含一些共享内存,这个东西不准,不要以top命令中的%MEM命令为准来判断程序的内存占用。
- 可以考虑使用其他命令查看内存情况
参考:Linux查看CPU和内存使用情况
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下表:
参数解释s改变画面更新频率l关闭或开启第一部分第一行 top 信息的表示t关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示m关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示N以 PID 的大小的顺序排列表示进程列表(第三部分后述)P以 CPU 占用率大小的顺序排列进程列表 (第三部分后述)M以内存占用率大小的顺序排列进程列表 (第三部分后述)h显示帮助n设置在进程列表所显示进程的数量q退出 tops改变画面更新周期
2.3.2 其他查看内存的命令
TBD
参考:
- How to Check Memory Usage Per Process on Linux
- How can I measure the actual memory usage of an application or process?
2.3.3 kill占用内存的无关进程
经过上面
top
命令的查看,其实发现,我系统很干净,只有
nebula-graph-studio
的4个进程以及使用vscode访问占用了一些资源。
因此,首先不再使用vscode访问服务器,改成xshell。
参考:too much memory for remote-ssh vscode
- vscode的远程连接确实比较费资源
- 一开始关闭VScode,很快打开xshell连上服务器之后,还是可以在xshell的界面里看到vscode的一些服务,但是过一会就会消失
然后**关闭
nebula-graph-studio
服务**。
关闭掉无关进程之后,可以看到,
top
命令中基本没东西了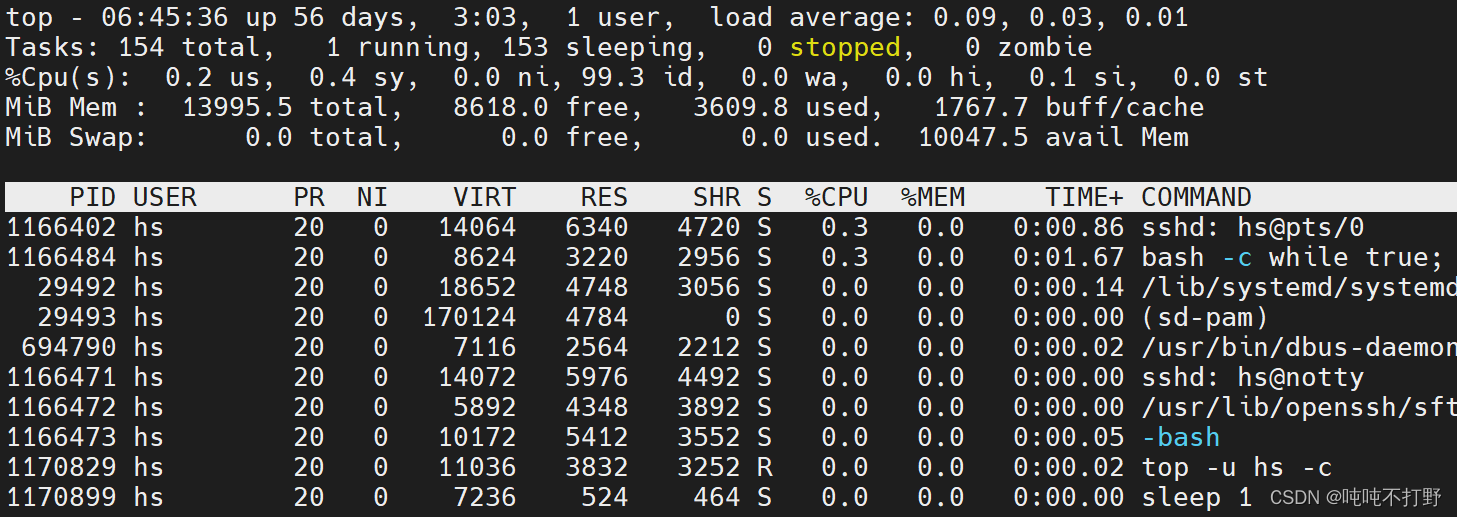
再去查看
free -g

似乎没什么用,哎。算了,那只能修改模型的batch_size了,或者把模型参数降低。
2.4 vscode remote connection问题
这里只记录一些我观察到的情况。
- 关闭vscode(直接关闭程序,不手动切断远程连接),使用
mobaxtem查看系统内存使用情况,为3.83GB。(此时,vscode的连接进程还没有消失) - 再打开vscode,内存使用增加到
3.94GB - 在vscode的远程命令行界面输入
exit并关闭vscode,内存使用量变为3.84GB - 关闭之后,大概需要等待5分钟,下面的三个进程才会消失,内存使用量变为
3.77GB
- 同时,相比于
mobaxterm中的openssh等进程,vscode的内存占用确实大很多,但是如果机器比较跟的上时代的话,其实不是很大的问题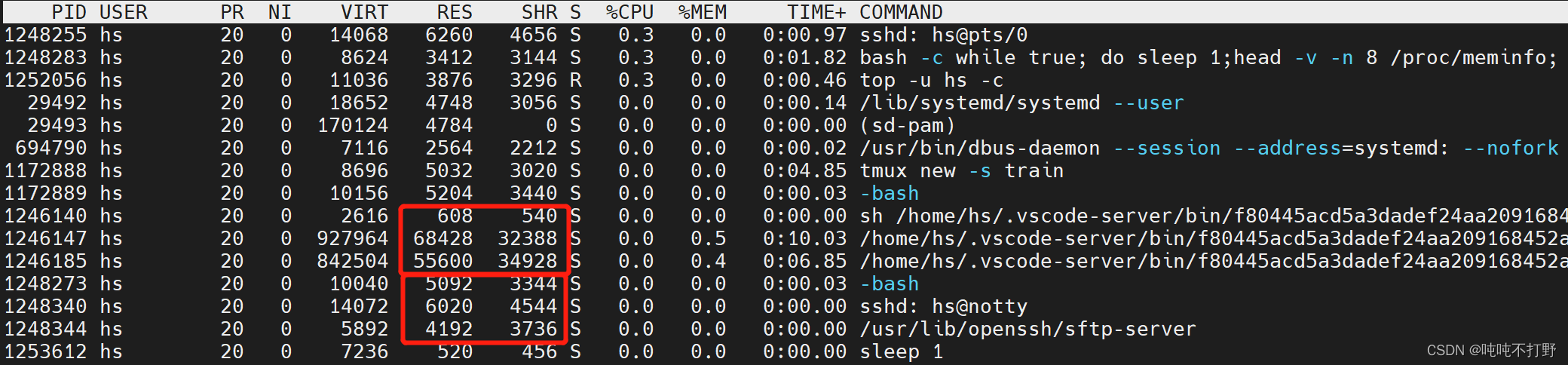
版权归原作者 吨吨不打野 所有, 如有侵权,请联系我们删除。