
Hive内核调优(三)
1.6 参数调优案例
1.6.1 OBS 数据操作最佳实践
如何识别OBS流控 从yarn日志里面找到某一个map的syslog日志,打开查看ObsClient xx的时延,如果有多次大于100ms以上,即可能有流控异常。此时,需要拉通OBS同事查看后台监控流量,调整指标阈值。为了防止流控,一般前期需要根据实际业务数据量大小评估桶带宽和并发,按照OBS同事提供的经验值参考:1000核集群需要5GB(40Gb)带宽来评估。使用限制_对象存储服务 OBS_产品介绍_华为云 (huaweicloud.com) --OBS桶使用限制:
 如下日志触发流控:
如下日志触发流控:
OBS相关参数
参数名作用建议值fs.obs.readahead.range读数据时,发起预读建立range读的请求大小默认值:29版本前64KB,29版本开始1MB。此值设置大了,会提前碰到OBS BPS Qos。 Spark/Hive场景:每个map读数据很多时,建议设置为8/16MB;每个map读数据较少时,建议设置为1/2MB;HBase场景:设置为64KB;fs.obs.threads.max上传对象的线程数默认值:20 上传超过5GB大对象时,建议调整到50-100fs.obs.block.size计算split用到的block 大小,和map并发数相关默认值:128MB 注:使用distcp 带update参数时,需要注意保证源HDFS集群和该值一致fs.obs.list.parallel.factor fs.obs.list.threads.max fs.obs.list.threads.coreOBSFileSystem递归 List,并发参数默认值:30,60,30结合Hive参数操作OBS数据
参数名作用建议值mapreduce.input.fileinputformat.list-status.num-threadsgetSplits时,list的线程数默认15,建议改成50-100注:对继承FileInputFormat的 InputFormat有效hive.orc.compute.splits.num.threadsorc文件 input读的线程数和input内的目录数成正比,建议:50-100 默认值:1hive.exec.input.listing.max.threadsOrc list的线程数默认0,单线程运行,建议改成50-100tez.grouping.min-size tez.grouping.by-countTez时才有用。tez.grouping.min-size和tez.grouping.by-count配合使用,可控制map中的文件个数均衡建议tez.grouping.by-count=true tez.grouping.min-size=1KBhive.mv.files.threadHive mv(rename)的并发线程数。默认15,建议601.6.2 当输入数据量较大时减小 Map 处理的最大数据量
已知表midsrc有1.5亿条记录,如下:
分别设置map处理最大数据量为1024000000、512000000、256000000、128000000观察
以下语句的执行情况。
下面展示一些
内联代码片
。
CREATETABLE splittb1 ASSELECT base64 (unbase64 (base64 (binary(Row))))FROM midsrc;
统计信息如下:
Map处理的最大数据量Mapper数执行时长(秒)10240000005117.098512000000967.622560000001752.73912800000033 49.971
可以看到:随着map处理最大数据量变小,map数逐渐增大,整体效率提升。在最大数据量从256000000到128000000时,差别已经不大了。
1.6.3 当大量重复数据做去重时减少 Reduce 数量
已知文本表hugest有9.5亿条记录,如下: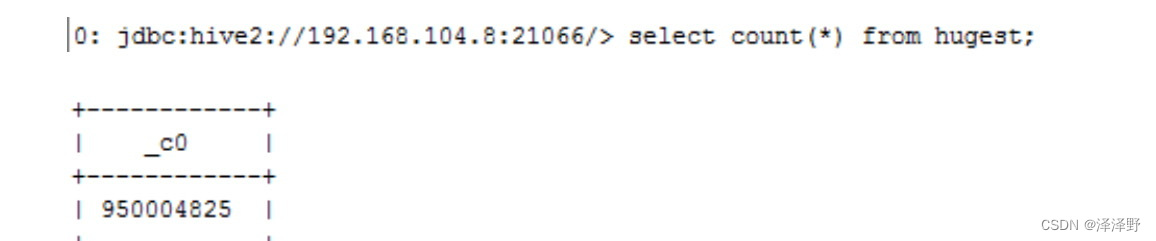
使用Hive默认参数执行以下语句查询不重复的记录。
O: jdbc:hive2://192.168.104.8:21066/>select distinct row from hugest;
共启动105个mapper,110个reducer,耗时137.394秒。
最终发现仅有三条不重复记录,由于map端已聚合,可推测reducer只要一个就够了,会大大减少reduce阶段耗时。
设置以下参数后再次执行语句。
O: jdbc:hive2://192.168.104.8:21066/>setmapreduce.job.reduces=1;
No rows affected (0.006 seconds)0: jdbc:hive2://192.168.104.8:21066/>select distinct row from hugest;
共启动105个mapper,1个reducer,耗时98.524秒,效果明显。
1.6.4 当大量匹配记录做关联时增加 Reduce 数量
己知表dynhuge和Idynhugel有784万条记录,使用Hive默认参数执行以下语句关联两表并将数据导入表tmp。
CREATETABLE Imp ASSELECT a. seq
FROM dynhugel a
JOIN dynhuge b ON a.seq = b.seq;
共启动2个mapper,1个reducer,耗时10个小时左右。
观察发现由于两表关联字段seq存在很多相同值,关联产生巨大的数据,一个reducer处理起来非常慢,按照当前集群和租户的能力,最大可启动56个container,因此考虑设置reducer个数为50。
设置以下参数后再次执行语句。
SET mapred. reduce. tasks=50;CREATETABLE Imp ASSELECT a. seq
FROM dynhugel a
JOIN dynhuge b ON a.seq = b.seq;
共启动2个 mapper,50个reducer,耗时16分钟,效果明显。
1.6.5 当出现 Join 倾斜时打开 Join 倾斜优化开关
表skewtable有392329条记录,表unskewtable有129927条记录。
使用Hive默认参数执行以下语句:
CREATETABLE tmp1 ASSELECT a.rowFROM skewtable a
JOIN unskewtable b oN a.row= b.row;
启动一个MR,耗时215.742秒,同时主要耗费在reduce阶段。
经统计,发现表skewtable有记录A的数量131650,表unskewtable有记录A的数量449,可知两表关联将会出现一定的数据倾斜。
设置join倾斜优化开关,再次执行如下:
SET hive.optimize.skewjoin=TRUE;
CREATETABLE tmp2 ASSELECT a.rowFROM skewtable a
JOIN unskewtable b oN a.row= b.row;
启动了两个MR,总耗时157.494秒,单独启动一个MR处理了倾斜数据后,效率提升
了。
1.6.6 当Join 和 Group By 的字段一致时打开相关性优化开关
表log有305872条记录,表logcopy有295825条记录。
使用Hive默认参数执行以下语句:
CREATETABLE tmp1 ASSELECT x.record ASKEY,count (1) AS cnt
FROM logcopy x
JOIN log y oN(x.record = y.record)GROUPBY x.record;
启动了两个MR,总耗时64.59秒
由于join的字段和group by字段均key,可以利用相关性优化,减少MR个数从而提高运行速度。
设置以下参数后,再次执行:
SET hive.optimize. correlation=TRUE;CREATETABLE tmp1 ASSELECT x. record ASKEY,count(1) A5 cnt
FROM logcopy x
JOIN1og y ON (x.record = y.record)
GROUPBY X.record;
只启动一个MR,总耗时32.678秒。
1.6.7 当Join 字段和参与Join 的子查询的Group By 的字段一致时打开相关性优化开关
表log有305872条记录,表logcopy有295825条记录。
使用Hive默认参数执行以下语句:
CREATETABLE tmp1 ASSELECT a.keyAS keyl,
a. cnt As cntl,
b.keyAs keyz,
b. cnt As cnt2
FROM(SELECT x.record ASKEY,count(*)AS cnt
FROM10g x
GROUPBY x.record) a
JOIN(SELECT y. record ASKEY,count(*)AS cnt
FROM Togcopy y
GROUPBY y.record) b oN(a.KEY= b.KEY)
启动了三个MR,总耗时98.714秒。
由于子查询的group by字段和join字段一致,可以利用相关性优化,减少MR个数从而提高运行速度。
设置以下参数后,再次执行:
SET hive.optimize. correlation=TRUE;CREATETABLE Imp2 ASSELECT a.keyAs key1,
a. cnt A5 cntl,
b.keyAs keyz,
b. cnt AS cnt2
FROM(SELECT X. record ASKEY,count(*)AS cnt
FROM log x
GROUPBY x. record) a
JOIN(SELECT y.record ASKEY,count(*)AS cnt
FROM logcopy y
GROUPBY y.record) b ON (a.KEY= b.KEY)
``
只启动一个MR,耗时33.855秒,效果明显。
### 1.6.8 对 Count(Distinct)优化
ORC表orctbl有78914976条记录,表大小1.6G。
使用Hive默认参数执行以下语句:
```sqlSELECTcount(DISTINCT record)FROM orctbl;
由于是全聚合,只启动一个MR,总耗时295.997秒。

优化后可以将reduce数增大(测试集群可启动的container数次51),执行如下:
SET mapred.reduce.tasks=50;
SELECTcount(*)FROM(SELECTDISTINCT record
FROM orctbl) sub;
启动了两个MR,总耗时198.123秒。
1.6.9 使用 Mutiple Insert 优化
表src有500条记录。
分别执行插入操作,第一个插入操作如下:
INSERT OVERWRITE TABLE el
SELECTKEY, COUNT(x)
FROM src
WHEREKEY>450GROUPBYKEY;

第一个插入操作耗时30.536秒。
第二个插入操作如下:
INSERT OVERWRITE TABLE e2
SELECTKEY,COUNT(*)FROM src
WHEREKEY>500GROUPBYKEY;

第二个插入操作总耗时26.257秒。
两个SQL分别启动两个MR,共耗时56.793秒。
优化如下:
FROM src
INSERT OVERWRITE TABLE el
SELECTKEY,COUNT(*)WHEREKEY>450GROUPBYKEYINSERT OVERWRITE TABLE e2
SELECTKEY,COUNT(*)WHEREKEY>500GROUPBYKEY;

只启动一个MR,耗时27.187秒,效果提升明显。
1.6.10 当大量表参与 Join 时改用MR
如下场景,需要将用户信息表USER与INDICT_1、INDICT_2、INDICT_3、INDICT_4、INDICT_5等一定数量的指标表进行关联,目标是汇总用户的所有指标到一个新的用户指标表,一方面SQL比较冗长,另一方面由于多次join性能较低。同时后续还需要加入更多同类型的指标表参与连接,届时还需要修改SQL才能完成相应功能。
CREATETABLE USER_INDICT ASSELECTUSER.USERID,
INDICT_1.VALUE, INDICT_2.VALUE, INDICT_3.VALUE, INDICT_4.VALUE, INDICT_5.VALUEJOIN INDICT_1 ONUSER.USERID = INDICT_1. USERID
JOIN INDICT_2 ONUSER. USERID = INDICT_2. USERID
JOIN INDICT_3 ONUSER. USERID = INDICT_3. USERID
JOIN INDICT_4 ONUSER.USERID = INDICT_4. USERID
JOIN INDICT_5 ONUSER. USERID = INDICT_5. USERID ...WHEREUSER.LOC ='shenzhen';
了解业务需求后,考虑使用直接编写MR实现,MAP的输入为用户信息表USER及所有指标表的目录下的文件,MAP输出为用户ID、指标值,REDUCE输入为用户ID、指标值序列,REDUCE输出为用户ID和按顺序排列的指标值,落地成结果文件。MR程序能做到指标可配置(可配置文件目录名与指标名的映射),扩展性好(不断新增指标只需改配置文件,无须修改代码/SQL),效率更高(一个MR完成指标汇总的所有功能)。
1.6.11 调度器优化
调度器从Superior修改次CapacityScheduler,并且root.default队列的调度策略修改力
fair,fair调度策略能够更好的分配资源,节点间的负载也更加均衡。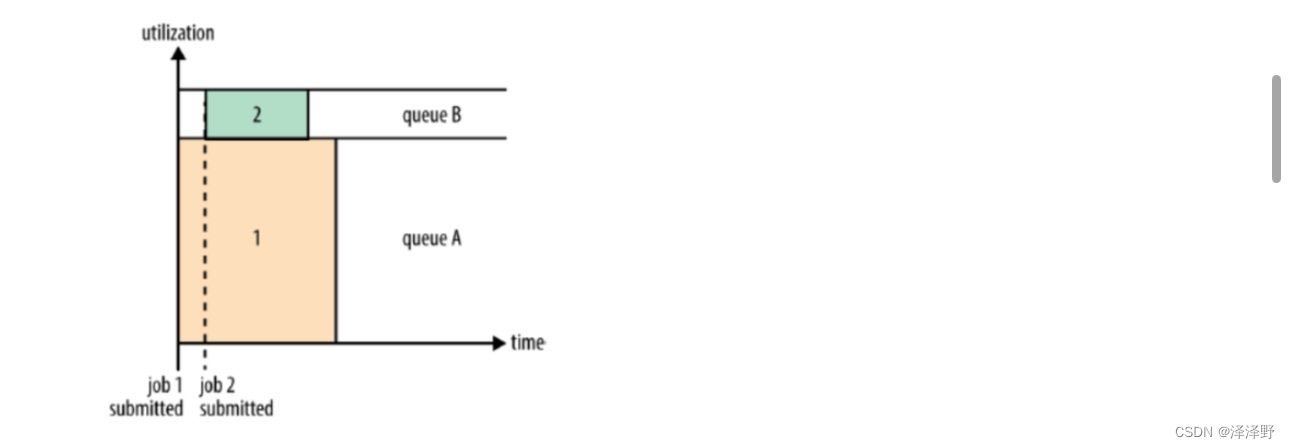
业务场景:执行时间长的作业较多,避免大作业,影响小作业调度。调度优化为公平调度。
1.6.12 Tez 笛卡尔积优化
A表
JOIN
B表
ON
c.play _start time< d.timeendAND c.play_ endtime>- d.timestart-笛卡尔积问题
由于两表join出现笛卡尔积问题,需要增加tez对笛卡尔积的优化set hive.tez.cartesian-product.enabled-true;
该优化利用TEZ的笛卡尔积边,使得可以有多个Reducer处理笛卡尔积的数据,而不是只有1个Reducer处理。
适用业务场景:在进行Joi是没有指定相对精确的条件,出现两表Join时,Join结果为两个表的笛卡尔积。针对笛卡尔积,本质上提升reduce数量、并发以及CPU利用率。
建议:设计Join的SQL时,避免条件不精确。
1.6.13 Hive 读 Hbase 表优化
sethbase.mapreduce.tableinput.mappers.per.region=50;
sethbase.mapreduce.tif.input.autobalance=true;
sethbase.mapreduce.tif.ave.regionsize=536870912;
HiveHIBaseTablelnputFormat
在计算split时,默认一个region作为一个split,当hbase的region不均衡或者region太大时,Map处理时间太久,无法利用资源加速计算过程。
hbase.mapreduce.tableinput.mappers.per.region
参数控制每个region生成的split数量,
hbase.mapreduce.tif.input.autobalance
开关打开后会子自动调整split的大小,使其接近
hbase.mapreduce.tif.ave.regionsize
设定的值,该值默认8GB,因此需要调小至512MB
适用业务场景:Hive作业部分依赖HBase的数据作为输入,Hive根据HBase中region数目做map划分,当HBase中有region数据不均衡存在数据倾斜时,会导致Hive map不均衡(数据量大于数据量小同时存在)。
优化原则:根据region数据量大小均衡分配生成map,增加map并发,处理数据更均衡。
1.6.14 MapJoin 算法优化
set hive.mapjoin.hybridgrace.hashtable-false;
使用hybridgrace mapjoin算法时,小表的数据有一部分在内存中,容易导致内存溢出。该参数关闭后会使用grace mapjoin算法,会对小表的数据进行partition,溢出到磁盘上。
适用业务场景:存在大小表join场景,且小表比较大,加载到内存容易内存溢出,加重gc。
优化原则:小表partition后部分加载到内存,降低内存高负荷,保持整个业务流运行。
1.6.15 数据倾斜优化
例如tmp_1表的message_channelid字段存在倾斜,大部分的值为NULL,只有一个Reducer
处理倾斜数据。
select message_channel id,count(*)fromtemp.tmp_1
groupby message channel id;

设置参数
hive.stats.fetch.column.stats-tue,
对表的大小估计更加准确,执行计划中使用MapJoin,没有shuffle过程,不会出现数据倾斜。或者增加
hive.auto.convert.join.noconditionaltask.size
值也可以使得该SQL执行Mapjoin。
hive.optimize.dynamic.partition.hashjoin=true;---hashjoin优化
hive.optimize.skewjoin=true;
适用业务场景:存在过程表数据倾斜,message_chanel id 的NULL取值远大于其他取值,并且只有1个reduce处理。
优化原则:ReduceJoin->MapJoin,避免将倾斜字段取值shuffle到同一个reduce上。利用统计信息和小表阈值,将计算过程优化为mapjoin。
版权归原作者 泽泽野 所有, 如有侵权,请联系我们删除。