
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
无论是在计算机视觉、自然语言处理还是图像生成方面,深度神经网络目前表现出来的性能都是最先进的。然而,它们在计算能力、内存或能源消耗方面的成本可能令人望而却步,这使得大部份公司的因为有限的硬件资源而完全负担不起训练的费用。但是许多领域都受益于神经网络,因此需要找到一个在保持其性能的同时降低成本的办法。
这就是神经网络压缩的重点。该领域包含多个方法系列,例如量化 [11]、分解[13]、蒸馏 [32]。而本文的重点是剪枝。
神经网络剪枝是一种移除网络中性能良好但需要大量资源的多余部分的方法。尽管大型神经网络已经无数次证明了它们的学习能力,但事实证明,在训练过程结束后,并非它们的所有部分都仍然有用。这个想法是在不影响网络性能的情况下消除这些多余部分。
不幸的是,每年发表的数十篇(可能是数百篇的话)论文都揭示了这个被认为直截了当的想法所隐藏的复杂性。事实上,只要快速浏览一下文献,就会发现有无数方法可以在训练前、训练中或训练后识别这些无用的部分,或将其移除;最主要的是并不是所有类型的剪枝都能加速神经网络,这才是关键所在。
这篇文章的目标是为解决围绕神经网络剪枝各种问题。我们将依次回顾三个似乎是整个领域核心的问题:“我应该修剪什么样的部分?”,“如何判断哪些部分可以修剪?”和“如何在不损害网络的情况下进行修剪?”。综上所述,我们将详细介绍剪枝结构、剪枝标准和剪枝方法。
1 - 剪枝介绍
1.1 - 非结构化剪枝
在谈到神经网络的成本时,参数数量肯定是最广泛使用的指标之一,还有 FLOPS(每秒浮点运算)。当我们看到网络显示出天文数字的权重(GPT3的参数数量是1,750亿)确实令人生畏。实际上,修剪连接是文献中最广泛的范式之一,足以被视为处理剪枝时的默认框架。Han等人的开创性工作[26]提出了这种剪枝方法,并作为许多贡献的基础 [18, 21, 25]。
直接修剪参数有很多优点。首先,它很简单,因为在参数张量中用零替换它们的权重值就足以修剪连接。被广泛使用的深度学习框架,例如 Pytorch,允许轻松访问网络的所有参数,使其实现起来非常简单。尽管如此,修剪连接的最大优势是它们是网络中最小、最基本的元素,因此,它们的数量足以在不影响性能的情况下大量修剪它们。如此精细的粒度允许修剪非常细微的模式,例如,最多可修剪卷积核内的参数。由于修剪权重完全不受任何约束的限制,并且是修剪网络的最佳方式,因此这种范式称为非结构化剪枝。
然而,这种方法存在一个主要的、致命的缺点:大多数框架和硬件无法加速稀疏矩阵计算,这意味着无论你用多少个零填充参数张量,它都不会影响网络的实际成本。然而,影响它的是以一种直接改变网络架构的方式进行修剪,任何框架都可以处理。

非结构化(左)和结构化(右)剪枝的区别:结构化剪枝去除卷积滤波器和内核行,而不仅仅是剪枝连接。这导致中间表示中的特征图更少。
1.2 - 结构化剪枝
这就是为什么许多工作都专注于修剪更大的结构的原因,例如整个神经元 [36],或者在更现代的深度卷积网络中直接等效,卷积过滤器 [40, 41, 66]。由于大型网络往往包括许多卷积层,每个层数多达数百或数千个过滤器,因此过滤器修剪允许使用可利用但足够精细的粒度。移除这样的结构不仅会导致稀疏层可以直接实例化为更薄的层,而且这样做还会消除作为此类过滤器输出的特征图。
因此,由于参数较少这种网络不仅易于存储,而且它们需要更少的计算并生成更轻的中间表示,因此在运行时需要更少的内存。实际上,有时减少带宽比减少参数计数更有益。事实上,对于涉及大图像的任务,例如语义分割或对象检测,中间表示可能会消耗大量内存,远远超过网络本身。由于这些原因,过滤器修剪现在被视为结构化剪枝的默认类型。
然而,在应用这种修剪时,应注意以下几个方面。让我们考虑如何构建卷积层:对于输入通道中的 C 和输出通道中的 C,卷积层由 Cout 过滤器组成,每个过滤器都计算 Cin 核;每个过滤器输出一个特征图,在每个过滤器中,一个内核专用于每个输入通道。考虑到这种架构,在修剪整个过滤器时,人们可能会观察到修剪当前过滤器,然后它会影响当前输出的特征图,实际上也会导致在随后的层中修剪相应的过滤器。这意味着,在修剪过滤器时,实际上可能会修剪一开始被认为要删除的参数数量的两倍。
让我们也考虑一下,当整个层碰巧被修剪时(这往往是由于层崩溃 [62],但并不总是破坏网络,具体取决于架构),前一层的输出现在完全没有连接,因此也被删减:删减整个层实际上可能删减其所有先前的层,这些层的输出在其他地方没有以某种方式连接(由于残差连接[28]或整个并行路径[61])。因此在修剪过滤器时,应考虑计算实际修剪参数的确切数量。事实上,根据过滤器在体系结构中的分布情况,修剪相同数量的过滤器可能不会导致相同数量的实际修剪参数,从而使任何结果都无法与之进行比较。
在转移话题之前,让我们提一下,尽管数量很少,但有些工作专注于修剪卷积核(过滤器)、核内结构 [2,24, 46] 甚至特定的参数结构。但是,此类结构需要特殊的实现才能实现任何类型的加速(如非结构化剪枝)。然而,另一种可利用的结构是通过修剪每个内核中除一个参数之外的所有参数并将卷积转换为“位移层”(shift layers),然后可以将其总结为位移操作和 1×1 卷积的组合 [24]。

结构化剪枝的危险:改变层的输入和输出维度会导致一些差异。如果在左边,两个层输出相同数量的特征图,然后可以很好地相加,右边的剪枝产生不同维度的中间表示,如果不处理它们就无法相加。
2 - 剪枝标准
一旦决定了要修剪哪种结构,下一个可能会问的问题是:“现在,我如何确定要保留哪些结构以及要修剪哪些结构?”。为了回答这个问题,需要一个适当的修剪标准,这将对参数、过滤器或其他的相对重要性进行排名。
2.1- 权重大小标准
一个非常直观且非常有效的标准是修剪绝对值(或“幅度”)最小的权重。实际上,在权重衰减的约束下,那些对函数没有显着贡献的函数在训练期间会缩小幅度。因此,多余的权重被定义为是那些绝对值较小的权重[8]。尽管它很简单,但幅度标准仍然广泛用于最新的方法 [21, 26, 58],使其成为该领域的主要内容。
然而,虽然这个标准在非结构化剪枝的情况下实现起来似乎微不足道,但人们可能想知道如何使其适应结构化剪枝。一种直接的方法是根据过滤器的范数(例如 L 1 或 L 2)对过滤器进行排序 [40, 70]。如果这种方法非常简单,人们可能希望将多组参数封装在一个度量中:例如,一个卷积过滤器、它的偏差和它的批量归一化参数,或者甚至是并行层中的相应过滤器,其输出随后被融合。
一种方法是在不需要计算这些参数的组合范数的情况下,在要修剪的每组图层之后为每个特征图插入一个可学习的乘法参数。当这个参数减少到零时,有效地修剪了负责这个通道的整套参数,这个参数的大小说明了所有参数的重要性。因此,该方法包括修剪较小量级的参数 [36, 41]。
2.2 - 梯度幅度剪枝
权重的大小并不是唯一存在的流行标准(或标准系列)。实际上,一直持续到现在的另一个主要标准是梯度的大小。事实上,早在 80 年代,一些基础工作 [37, 53] 通过移除参数对损失的影响的泰勒分解进行了理论化,一些从反向传播梯度导出的度量可以提供一种很好的方法来确定 可以在不损坏网络的情况下修剪哪些参数。
该方法 [4, 50] 的最新的实现实际上是在小批量训练数据上累积梯度,并根据该梯度与每个参数的相应权重之间的乘积进行修剪。该标准也可以应用于上述参数方法[49]。
2.3 — 全局或局部剪枝
要考虑的最后一个方面是所选标准是否是全局应用于网络的所有参数或过滤器,或者是否为每一层独立计算。虽然多次证明全局修剪可以产生更好的结果,但它可能导致层崩溃 [62]。避免这个问题的一个简单方法是采用逐层局部剪枝,即在使用的方法不能防止层崩溃时,在每一层剪枝相同的速率。
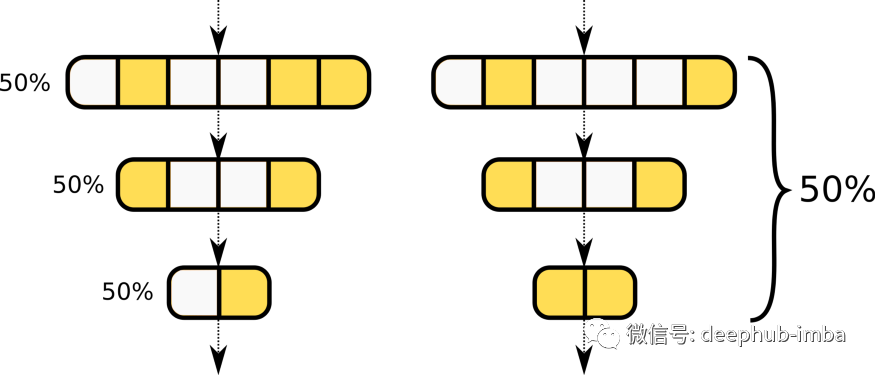
局部剪枝(左)和全局剪枝(右)的区别:局部剪枝对每一层应用相同的速率,而全局剪枝一次在整个网络上应用。
3 - 剪枝方法
现在我们已经获得了修剪结构和标准,剩下的唯一需要确认的是我们应该使用哪种方法来修剪网络。这实际上这是文献中最令人困惑的话题,因为每篇论文都会带来自己的怪癖和噱头,以至于人们可能会在有条不紊的相关内容和给定论文的特殊性之间迷失。
这就是为什么我们将按主题概述一些最流行的修剪神经网络的方法系列,以突出训练期间使用稀疏性的演变。
3.1 - 经典框架:训练、修剪和微调
要知道的第一个基本框架是训练、修剪和微调方法,它显然涉及 1) 训练网络 2) 通过将修剪结构和标准所针对的所有参数设置为 0 来修剪它(这些参数之后无法恢复)和 3)用最低的学习率训练网络几个额外的时期,让它有机会从修剪引起的性能损失中恢复过来。通常,最后两个步骤可以迭代,每次都会增加修剪率。
Han等人提出的方法 [26] 应用的就是这种方法,在修剪和微调之间进行 5 次迭代,以进行权重修剪。迭代已被证明可以提高性能,但代价是额外的计算和训练时间。这个简单的框架是许多方法 [26, 40, 41, 50, 66] 的基础,可以看作是其他所有作品的默认方法。
3.2 - 扩展经典框架
虽然没有偏离太多,但某些方法对 Han 等人的上述经典框架进行了重大修改[26],Gale 等人 [21] 通过在整个训练过程中逐渐移除越来越多的权重,进一步推动了迭代的原则,这使得可以从迭代的优势中受益并移除整个微调过程。He等人[29] 在每个 epoch 将可修剪的过滤器逐步减少到 0,同时不阻止它们学习和之后更新,以便让它们的权重在修剪后重新增长,同时在训练期间加强稀疏性。
最后,Renda 等人的方法 [58] 涉及在修剪网络后完全重新训练网络。与以最低学习率执行的微调不同,再训练遵循与训练相同的学习率计划,因此被称为:“Learning-Rate Rewinding”。与单纯的微调相比,这种再训练已显示出更好的性能,而且成本要高得多。
3.3 - 初始化时的修剪
为了加快训练速度,避免微调并防止在训练期间或之后对架构进行任何更改,多项工作都集中在训练前的剪枝上。在 SNIP [39] 之后,许多方法都研究了 Le Cun 等人的方法 [37] 或 Mozer 和 Smolensky [53] 在初始化时修剪 [12, 64],包括深入的理论研究 [27, 38, 62]。然而,Optimal Brain Damage [37] 依赖于多个近似值,包括“极值”近似值,即“假设训练收敛后将执行参数删除”[37];这个事实很少被提及,即使在基于它的方法中也是如此。一些工作对此类方法生成掩码的能力提出了保留意见,这些掩码的相关性优于每层相似分布的随机掩码[20]。
另一个研究修剪和初始化之间关系的方法家族围绕着“彩票假设”[18]。这个假设指出“随机初始化的密集神经网络包含一个子网工作,它被初始化,这样当单独训练时它可以在训练最多相同迭代次数后与原始网络的测试精度相匹配”。在实践中,该文献研究了使用已经收敛的网络定义的剪枝掩码在刚初始化时可以应用于网络的效果如何。多项工作扩展、稳定或研究了这一假设 [14, 19, 45, 51, 69]。然而,多项工作再次倾向于质疑假设的有效性以及用于研究它的方法 [21, 42],有些甚至倾向于表明它的好处来自于使用确定性掩码而不是完全训练的原则,“Winning Ticket”[58]。

经典的“训练、剪枝和微调”框架 [26]、彩票实验 [18] 和Learning-Rate Rewinding [58] 之间的比较。
3.4 - 稀疏训练
上面提到的方法都与一个看似共享的潜在主题相关联:在稀疏约束下训练。这个原则是一系列方法的核心,称为稀疏训练,它包括在训练期间强制执行恒定的稀疏率,同时其分布变化并逐渐调整。由 Mocanu 等人提出 [47],它包括:1) 用随机掩码初始化网络,修剪一定比例的网络 2) 在一个轮次内训练这个修剪过的网络 3) 修剪一定数量的最低数量的权重 4) 重新增长相同的随机权重的数量。
这样,修剪掩码首先是随机的,逐渐调整以针对最小的导入权重,同时在整个训练过程中强制执行稀疏性。每一层 [47] 或全局 [52] 的稀疏级别可以相同。其他方法通过使用某个标准来重新增加权重而不是随机选择它们来扩展稀疏训练 [15, 17]。

稀疏训练在训练期间周期性地削减和增长不同的权重,这会导致调整后的掩码应仅针对相关参数。
3.5 - 掩码学习
与依赖任意标准来修剪或重新增加权重不同,多种方法专注于在训练期间学习修剪掩码。两种方法似乎在这个领域盛行:1)通过单独的网络或层进行掩码学习;2)通过辅助参数进行掩码学习。多种策略可以适用于第一类方法:训练单独的代理以尽可能多地修剪一层的过滤器,同时最大限度地提高准确性 [33]、插入基于注意力的层 [68] 或使用强化学习 [30] .第二种方法旨在将剪枝视为一个优化问题,它倾向于最小化网络的 L 0 范数及其监督损失。
由于 L0 是不可微的,因此各种方法主要涉及通过使用惩罚辅助参数来规避这个问题,这些辅助参数在前向传递期间与其相应的参数相乘 [59, 23]。许多方法 [44, 60, 67] 依赖于一种类似于“二元连接”[11] 的方法,即:对参数应用随机门,这些参数的值每个都从它们自己的参数 p 的伯努利分布中随机抽取“Straight Through Estimator”[3] 或其他方式 [44]。
3.6 - 基于惩罚的方法
许多方法不是手动修剪连接或惩罚辅助参数,而是对权重本身施加各种惩罚,使它们逐渐缩小到 0。这个概念实际上很古老 [57],因为权重衰减已经是一个必不可少的权重大小标准。除了使用单纯的权重衰减之外,甚至在那时也有多项工作专注于制定专门用于强制执行稀疏性的惩罚 [55, 65]。今天,除了权重衰减之外,各种方法应用不同的正则化来进一步增加稀疏性(通常使用 L 1 范数 [41])。
在最新的方法中,多种方法依赖于 LASSO[22, 31, 66] 来修剪权重或组。其他方法制定了针对弱连接的惩罚,以增加要保留的参数和要修剪的参数之间的差距,从而减少它们的删除影响 [7, 16]。一些方法表明,针对在整个训练过程中不断增长的惩罚的权重子集可以逐步修剪它们并可以进行无缝删除[6, 9, 63]。文献还计算了围绕“Variational Dropout”原理构建的一系列方法 [34],这是一种基于变分推理 [5] 的方法,应用于深度学习 [35]。作为一种剪枝方法 [48],它产生了多种将其原理应用于结构化剪枝 [43, 54] 的方法。
4 - 可用的框架
如果这些方法中的大多数必须从头开始实现(或者可以从每篇论文的提供源代码中重用),以下这些框架都可以应用基本方法或使上述实现更容易。
4.1 - Pytorch
Pytorch [56] 提供了一些基本的剪枝方法,例如全局剪枝或局部剪枝,无论是结构化的还是非结构化的。结构化修剪可以应用于权重张量的任何维度,它可以修剪过滤器、内核行甚至内核内部的一些行和列。那些内置的基本方法还允许随机修剪或根据各种规范进行修剪。
4.2 - Tensorflow
Tensorflow [1] 的 Keras [10] 库提供了一些基本工具来修剪最低量级的权重。例如在 Han 等人 [25] 的工作中,修剪的效率是根据所有插入的零引入的冗余程度来衡量的,可以更好地压缩模型(与量化结合得很好)。
4.3 - ShrinkBench
Blalock 等人 [4] 在他们的工作中提供了一个自定义库,以帮助社区规范剪枝算法的比较方式。ShrinkBench 基于 Pytorch,旨在使剪枝方法的实施更容易,同时规范训练和测试的条件。它提供了几种不同的基线,例如随机剪枝、全局或分层以及权重大小或梯度大小剪枝。
5 - 方法的简要回顾
在这篇文章中,引用了许多不同的论文。这是一个简单的表格,粗略总结了它们的作用以及它们的区别(提供的日期是首次发布的日期):
ArticleDateStructureCriterionMethodRemarkSourcesClassic methods
Han *et al.*2015weightsweights magnitudetrain, prune and fine-tuneprototypical pruning methodnoneGale *et al.*2019weightsweights magnitudegradual removal-noneRenda *et al.*2020weightsweights magnitudetrain, prune and re-train (“LR-Rewinding”)-yesLi *et al.*2016filtersL1 norm of weightstrain, prune and fine-tune-noneMolchanov *et al.*2016filtersgradient magnitudetrain, prune and fine-tune-noneLiu *et al.*2017filtersmagnitude of batchnorm parameterstrain, prune and fine-tunegates-based structured pruningnoneHe *et al.*2018filtersL2 norm of weightssoft pruningzeroes out filters without removal until the endyesMolchanov *et al.*2019filtersgradient magnitudetrain, prune and fine-tuneinserts gates to prune filtersnonePruning at initialization
Lee *et al.*2018weightsgradient magnitudeprune and train“SNIP”yesLee *et al.*2019weights“dynamical isometry”prune and traindataless methodyesWang *et al.*2020weightssecond-order derivativeprune and train“GraSP”: alike SNIP but with a criterion closer to that of Le Cun *et al.*yesTanaka *et al.*2020weights“synaptic flow”prune and train“SynFlow”: dataless methodyesFrankle *et al.*2018weightsweights magnitudetrain, rewind, prune and retrain“lottery ticket”noneSparse training
Mocanu *et al.*2018weightsweights magnitudesparse trainingrandom regrowth of pruned weightsyesMostafa and Wang2019weightsweights magnitudesparse trainingalike Mocanu et al. but global instead of layer-wisenoneDettmers and Zettlemoyer2019weightsweights magnitudesparse trainingregrowth and layer-wise pruning rate depending on momentumyesEvci *et al.*2019weightsweights magnitudesparse trainingregrowth on gradient magnitudeyesMask learning
Huang *et al.*2018filtersN/Atrain, prune and fine-tunetrains pruning agents that target filters to prunenoneHe *et al.*2018filtersN/Atrain, prune and fine-tuneuses reinforcement learning to target filters to pruneyesYamamoto and Maeno2018filtersN/Atrain, prune and fine-tune“PCAS”: uses attention modules to target filters to prunenoneGuo *et al.*2016weightsweight magnitudemask learningupdates a mask depending on two different thresholds on the magnitude of weightsyesSrinivas *et al.*2016weightsN/Amask learningalike Binary Connect applied to auxiliary parametersnoneLouizos *et al.*2017weightsN/Amask learningvariant of Binary Connect, applied to auxiliary parameters, that avoids resorting to the Straight Through EstimatoryesXiao *et al.*2019weightsN/Amask learningalike Binary Connect but alters the gradient propagated to the auxiliary parametersnoneSavarese *et al.*2019weightsN/Amask learningapproximates L0 with a heavyside function, which is itself approximated by a sigmoid of increasing temperature over auxiliary parametersyesPenalty-based methods
Wen *et al.*2016filtersN/AGroup-LASSO regularization-yesHe *et al.*2017filtersN/AGroup-LASSO regularizationalso reconstructs the outputs of pruned layers by least squaresyesGao *et al.*2019filtersN/AGroup-LASSO regularizationprunes matching filters accross layers and penalizes variance of weightsnoneChang and Sha2018weightsweight magnitudeglobal penaltymodifies the weight decay to make it induce more sparsitynoneMolchanov *et al.*2017weightsN/A“Variational Dropout”application of variational inference on pruningnoneNeklyudov *et al.*2017filtersN/A“Variational Dropout”structured version of variational dropoutyesLouizos *et al.*2017filtersN/A“Variational Dropout”another structured version of variational dropoutnoneDing *et al.*2018filtersweight magnitudetargeted penaltypenalizes or stimulate filters depending on the distance of their L 2 norm to a given thresholdnoneChoi *et al.*2018weightsweight magnitudetargeted penaltyat each step penalizes weights of least magnitude by its L 2 norm, with an importance that is learned throughout trainingnoneCarreira-Perpiñán and Idelbayev2018weightsweight magnitudetargeted penaltydefines a mask depending on weights of least magnitudes and penalizes them toward zerononeTessier et al.2020anyany (weight magnitude)targeted penaltyat each step penalizes prunable weights or filters by its L2 norm, with an importance that grows exponentially throughout trainingyes
5 - 总结
在我们对文献的快速概览中,我们看到 1) 剪枝结构定义了从剪枝中期望获得的收益 2) 剪枝标准基于各种理论或实践 3) 剪枝方法倾向于在训练期间引入稀疏性兼顾性能和成本。我们还看到,尽管它的最开始的工作可以追溯到 80 年代后期,但神经网络剪枝是一个非常动态的领域,今天仍然经历着基本的发现和新的基本概念。
尽管该领域每天都有贡献,但似乎仍有很大的探索和创新空间。如果方法的每个子族都可以看作是回答问题的一个尝试(“如何重新生成剪枝后的权重?”、“如何通过优化学习剪枝掩码?”、“如何通过更柔和的平均值来进行权重去除?”…… ),根据文献的演变似乎指出了一个方向:整个训练的稀疏性。这个方向提出了许多问题,例如:“剪枝标准在尚未收敛的网络上是否有效?”或者“如何从一开始就从任何类型的稀疏性训练中区分选择要修剪的权重的好处?”
引用
[1] Martı́n Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
[2] Sajid Anwar, Kyuyeon Hwang, and Wonyong Sung. Structured pruning of deep convolutional neural networks. ACM Journal on Emerging Technologies in Computing Systems (JETC), 13(3):1–18, 2017.
[3] Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432, 2013.
[4] Davis Blalock, Jose Javier Gonzalez Ortiz, Jonathan Frankle, and John Guttag. What is the state of neural network pruning? arXiv preprint arXiv:2003.03033, 2020.
[5] David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians. Journal of the American statistical Association, 112(518):859–877, 2017.
[6] Miguel A Carreira-Perpinán and Yerlan Idelbayev. “learning-compression” algorithms for neural net pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8532–8541, 2018.
[7] Jing Chang and Jin Sha. Prune deep neural networks with the modified L1/2 penalty. IEEE Access, 7:2273–2280, 2018.
[8] Yves Chauvin. A back-propagation algorithm with optimal use of hidden units. In NIPS, volume 1, pages 519–526, 1988.
[9] Yoojin Choi, Mostafa El-Khamy, and Jungwon Lee. Compression of deep convolutional neural networks under joint sparsity constraints. arXiv preprint arXiv:1805.08303, 2018.
[10] Francois Chollet et al. Keras, 2015.
[11] Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. Binaryconnect: Training deep neural networks with binary weights during propagations. In NIPS, 2015.
[12] Pau de Jorge, Amartya Sanyal, Harkirat S Behl, Philip HS Torr, Gregory Rogez, and Puneet K Dokania. Progressive skeletonization: Trimming more fat from a network at initialization. arXiv preprint arXiv:2006.09081, 2020.
[13] Emily Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. Exploiting linear structure within convolutional networks for efficient evaluation. In 28th Annual Conference on Neural Information Processing Systems 2014, NIPS 2014, pages 1269–1277. Neural information processing systems foundation, 2014.
[14] Shrey Desai, Hongyuan Zhan, and Ahmed Aly. Evaluating lottery tickets under distributional shifts. In Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019), pages 153–162, 2019.
[15] Tim Dettmers and Luke Zettlemoyer. Sparse networks from scratch: Faster training without losing performance. arXiv preprint arXiv:1907.04840, 2019.
[16] Xiaohan Ding, Guiguang Ding, Xiangxin Zhou, Yuchen Guo, Jungong Han, and Ji Liu. Global sparse momentum sgd for pruning very deep neural networks. arXiv preprint arXiv:1909.12778, 2019.
[17] Utku Evci, Trevor Gale, Jacob Menick, Pablo Samuel Castro, and Erich Elsen. Rigging the lottery: Making all tickets winners. In International Conference on Machine Learning, pages 2943–2952. PMLR, 2020.
[18] Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635, 2018.
[19] Jonathan Frankle, Gintare Karolina Dziugaite, Daniel M Roy, and Michael Carbin. Stabilizing the lottery ticket hypothesis. arXiv preprint arXiv:1903.01611, 2019.
[20] Jonathan Frankle, Gintare Karolina Dziugaite, Daniel M Roy, and Michael Carbin. Pruning neural networks at initialization: Why are we missing the mark? arXiv preprint arXiv:2009.08576, 2020.
[21] Trevor Gale, Erich Elsen, and Sara Hooker. The state of sparsity in deep neural networks. arXiv preprint arXiv:1902.09574, 2019.
[22] Susan Gao, Xin Liu, Lung-Sheng Chien, William Zhang, and Jose M Alvarez. Vacl: Variance-aware cross-layer regularization for pruning deep residual networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 0–0, 2019.
[23] Yiwen Guo, Anbang Yao, and Yurong Chen. Dynamic network surgery for efficient dnns. In NIPS, 2016.
[24] Ghouthi Boukli Hacene, Carlos Lassance, Vincent Gripon, Matthieu Courbariaux, and Yoshua Bengio. Attention based pruning for shift networks. In 2020 25th International Conference on Pattern Recognition (ICPR), pages 4054–4061. IEEE, 2021.
[25] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
[26] Song Han, Jeff Pool, John Tran, and William J Dally. Learning both weights and connections for efficient neural network. In NIPS, 2015.
[27] Soufiane Hayou, Jean-Francois Ton, Arnaud Doucet, and Yee Whye Teh. Robust pruning at initialization.
[28] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[29] Yang He, Guoliang Kang, Xuanyi Dong, Yanwei Fu, and Yi Yang. Soft filter pruning for accelerating deep convolutional neural networks. arXiv preprint arXiv:1808.06866, 2018.
[30] Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, and Song Han. Amc: Automl for model compression and acceleration on mobile devices. In Proceedings of the European Conference on Computer Vision (ECCV), pages 784–800, 2018.
[31] Yihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 1389–1397, 2017.
[32] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. stat, 1050:9, 2015.
[33] Qiangui Huang, Kevin Zhou, Suya You, and Ulrich Neumann. Learning to prune filters in convolutional neural networks. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 709–718. IEEE, 2018.
[34] Diederik P Kingma, Tim Salimans, and Max Welling. Variational dropout and the local reparameterization trick. stat, 1050:8, 2015.
[35] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. stat, 1050:1, 2014.
[36] John K Kruschke and Javier R Movellan. Benefits of gain: Speeded learning and minimal hidden layers in back-propagation networks. IEEE Transactions on systems, Man, and Cybernetics, 21(1):273–280, 1991.
[37] Yann LeCun, John S Denker, and Sara A Solla. Optimal brain damage. In Advances in neural information processing systems, pages 598–605, 1990.
[38] Namhoon Lee, Thalaiyasingam Ajanthan, Stephen Gould, and Philip HS Torr. A signal propagation perspective for pruning neural networks at initialization. In International Conference on Learning Representations, 2019.
[39] Namhoon Lee, Thalaiyasingam Ajanthan, and Philip HS Torr. Snip: Single-shot network pruning based on connection sensitivity. International Conference on Learning Representations, ICLR, 2019.
[40] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710, 2016.
[41] Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, pages 2736–2744, 2017.
[42] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. In International Conference on Learning Representations, 2018.
[43] C Louizos, K Ullrich, and M Welling. Bayesian compression for deep learning. In 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA., 2017.
[44] Christos Louizos, Max Welling, and Diederik P Kingma. Learning sparse neural networks through l 0 regularization. arXiv preprint arXiv:1712.01312, 2017.
[45] Eran Malach, Gilad Yehudai, Shai Shalev-Schwartz, and Ohad Shamir. Proving the lottery ticket hypothesis: Pruning is all you need. In International Conference on Machine Learning, pages 6682–6691. PMLR, 2020.
[46] Huizi Mao, Song Han, Jeff Pool, Wenshuo Li, Xingyu Liu, Yu Wang, and William J Dally. Exploring the regularity of sparse structure in convolutional neural networks. arXiv preprint arXiv:1705.08922, 2017.
[47] Decebal Constantin Mocanu, Elena Mocanu, Peter Stone, Phuong H Nguyen, Madeleine Gibescu, and Antonio Liotta. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science. Nature communications, 9(1):1–12, 2018.
[48] Dmitry Molchanov, Arsenii Ashukha, and Dmitry Vetrov. Variational dropout sparsifies deep neural networks. In International Conference on Machine Learning, pages 2498–2507. PMLR, 2017.
[49] Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, and Jan Kautz. Importance estimation for neural network pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11264–11272, 2019.
[50] Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila, and Jan Kautz. Pruning convolutional neural networks for resource efficient inference. arXiv preprint arXiv:1611.06440, 2016.
[51] Ari S Morcos, Haonan Yu, Michela Paganini, and Yuandong Tian. One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers. stat, 1050:6, 2019.
[52] Hesham Mostafa and Xin Wang. Parameter efficient training of deep convolutional neural networks by dynamic sparse reparameterization. In International Conference on Machine Learning, pages 4646–4655. PMLR, 2019.
[53] Michael C Mozer and Paul Smolensky. Skeletonization: A technique for trimming the fat from a network via relevance assessment. In Advances in neural information processing systems, pages 107–115, 1989.
[54] Kirill Neklyudov, Dmitry Molchanov, Arsenii Ashukha, and Dmitry Vetrov. Structured bayesian pruning via log-normal multiplicative noise. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pages 6778–6787, 2017.
[55] Steven J Nowlan and Geoffrey E Hinton. Simplifying neural networks by soft weight-sharing. Neural Computation, 4(4):473–493, 1992.
[56] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
[57] Russell Reed. Pruning algorithms-a survey. IEEE transactions on Neural Networks, 4(5):740–747, 1993.
[58] Alex Renda, Jonathan Frankle, and Michael Carbin. Comparing rewinding and fine-tuning in neural network pruning. arXiv preprint arXiv:2003.02389, 2020.
[59] Pedro Savarese, Hugo Silva, and Michael Maire. Winning the lottery with continuous sparsification. Advances in Neural Information Processing Systems, 33, 2020.
[60] Suraj Srinivas, Akshayvarun Subramanya, and R Venkatesh Babu. Training sparse neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 138–145, 2017.
[61] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015.
[62] Hidenori Tanaka, Daniel Kunin, Daniel L Yamins, and Surya Ganguli. Pruning neural networks without any data by iteratively conserving synaptic flow. Advances in Neural Information Processing Systems, 33, 2020.
[63] Hugo Tessier, Vincent Gripon, Mathieu Léonardon, Matthieu Arzel, Thomas Hannagan, and David Bertrand. Rethinking weight decay for efficient neural network pruning. 2021.
[64] Chaoqi Wang, Guodong Zhang, and Roger Grosse. Picking winning tickets before training by preserving gradient flow. In International Conference on Learning Representations, 2019.
[65] Andreas S Weigend, David E Rumelhart, and Bernardo A Huberman. Generalization by weight-elimination with application to forecasting. In Advances in neural information processing systems, pages 875–882, 1991.
[66] Wei Wen, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Learning structured sparsity in deep neural networks. In NIPS, 2016.
[67] Xia Xiao, Zigeng Wang, and Sanguthevar Rajasekaran. Autoprune: Automatic network pruning by regularizing auxiliary parameters. Advances in neural information processing systems, 32, 2019.
[68] Kohei Yamamoto and Kurato Maeno. Pcas: Pruning channels with attention statistics for deep network compression. arXiv preprint arXiv:1806.05382, 2018.
[69] Hattie Zhou, Janice Lan, Rosanne Liu, and Jason Yosinski. Deconstructing lottery tickets: Zeros, signs, and the supermask. arXiv preprint arXiv:1905.01067, 2019.
[70] Zhuangwei Zhuang, Mingkui Tan, Bohan Zhuang, Jing Liu, Yong Guo, Qingyao Wu, Junzhou Huang, and Jin-Hui Zhu. Discrimination-aware channel pruning for deep neural networks. In NeurIPS, 2018.
本文作者:Hugo Tessier
喜欢就关注一下吧:
点个 在看 你最好看!********** **********