
一、行业主流性能工具
Apache AB
Apache JMeter
LoadRunner
Ngrinder
PTS
Apache AB:
1.apache ab测试的并发数与其所运行的服务器的CPU颗粒数有很大关系,CPU颗粒数越大,测试结果所支持的并发数就越大
2.只支持http协议,不支持其他协议
3.不支持上下文等复杂场景(比如创建订单再支付订单等)
4.适合单接口性能的测试
LoadRunner:
1.LoadRunner是一种具备高规模适应性的、自动负载测试工具,它能测试系统行为,优化系统性能
2.主要由3个组件组成:Generator(虚拟用户生成器)来录制或编辑虚拟用户脚本、Controller(控制器) 设置场景如需要多少用户数,执行时间等、Analysis (分析器)有助于您查看、分析和比较性能结果。
3.不开源、付费,随着QPS需求增大使用随之减少
Grinder:
1.用于在多台机器上运行jython(在jvm上运行的python)编写测试脚本的应用程序。
2.Grinder主要有controller、agent、monitor三部分,controller提供web界面、协调测试过程、显示结果、创建和调试python脚本,agent实际发起压力的工具,使用monitor监听性能指标反馈给controller。
3.所有方式都要用脚本实现
4.面对大量并发请求时,性能不太好(低于jmeter),需要修改源码
PTS:
1.可以不需要实际服务器,在云平台进行压测
2.按需发起压测任务,可提供百万并发、千万TPS流量发起能力,100%兼容JMeter。
3.免去搭建和运维成本,更紧密结合监控类产品提供一站式监控、定位等
4.需要付费使用
Jmeter:
1.主要分成2个模块:前置处理器和取样器等模拟负载请求过程和实现、断言和监听器鞥验证请求的有效性和结果报告
2.开源的java程序,适合二次开发
3.支持多协议
4.提供插件较多
结论:
1、单接口使用ab。
2、有核心场景使用jmeter:
压力需求:jmeter分布式可以支持大量qps
周期性:场景文件,数据驱动,结果落库
问题支持:jmeter广泛使用,开发社区
其他:开源免费、应用简单上手快
二、行业流行性能监控工具
1.linux自带命令vmstat,top等
2.机器监控工具Nmon
3.物理机监控Collectd+influxdb+grafana
4.Prometheus+Grafana(node_exporter,mysqld_exporter)
top:分整体性能情况和每个pid的占用情况两大部分;可以实时查看数据,但是结果不能落地
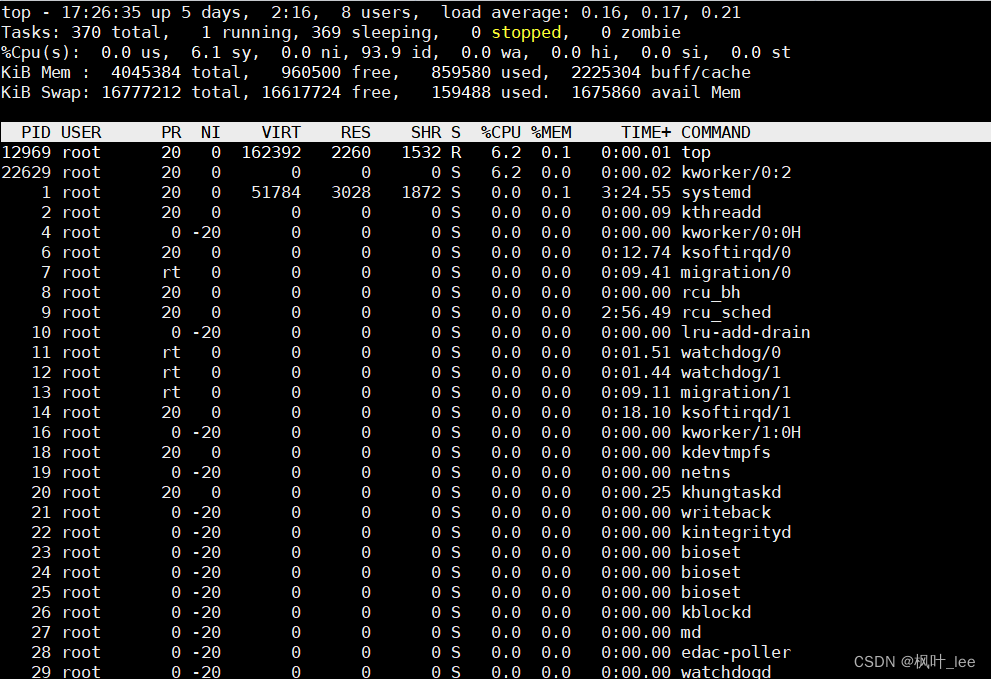
vmstat:可对操作系统的虚拟内存、进程、CPU活动进行监控;可以实时查看数据,但是结果不能落地
nmon:
1.它能在系统运行过程中实时地捕捉系统资源的使用情况,记录的信息比较全面
2.它可将服务器系统资源耗用情况收集起来并输出一个特定的文件,并可利用 excel 分析工具(nmon analyser)进行数据的统计分析
3.结合grafana之类的仪表图,可以更直观的实时展示所监控的数据
4.占用资源较少,可无人值守监控

collectd是一个守护进程,由c语言实现(占用资源较少),用来收集系统信息。守护进程本身只有查询和提交的功能,不能进行收集和存储,需要额外安装插件。colletcd支持多种插件,主要分为read类型和wirte类型插件。read类型插件就是用于读取监控指标,write类型的插件将值写入文件、数据库、缓存等。
influxdb:按照时间顺序记录系统、设备状态变化的数据被称为时序数据(Time Series Data),如CPU、内存利用率等。
Grafana:将插入InfluxDB以可视化数据的Web应用程序。
Prometheus:是一个开源监控解决方案,用于收集和聚合指标作为时间序列数据。
1.多维度数据模型
2.灵活的查询语言
3.通过基于http的pull方式采集实时数据
4.在不依赖外部存储的情况下,支持服务器节点的本地存储,通过Prometheus自带的时序数据库,可以完成每秒千万级的数据存储
5.支持多样化图片和界面展示,比如grafana等。
6.比较适合容器化平台
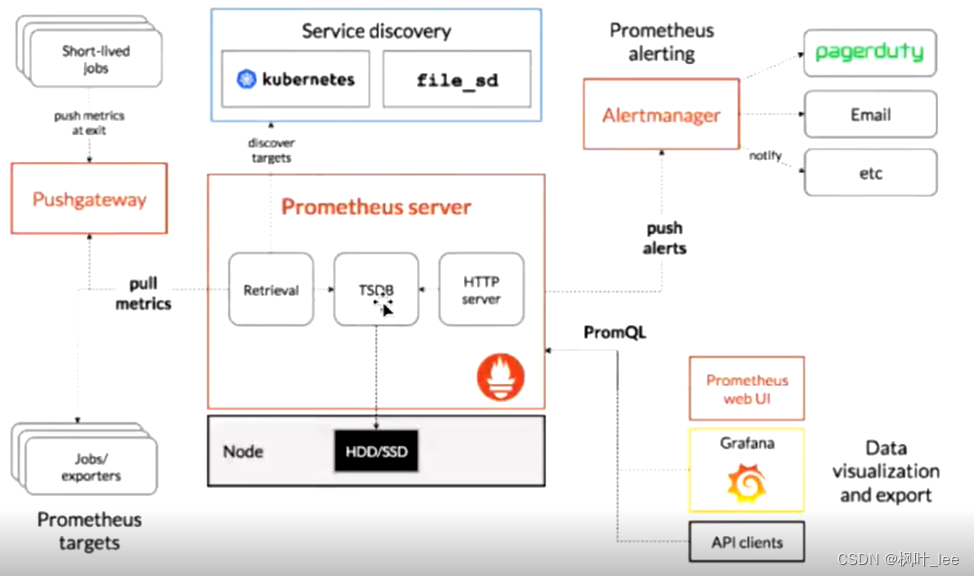
targets可以是docker机器、数据库、redis机器等,exporters实时收据数据推送到Prometheus server
Prometheus server通过http server对外提供服务和接口,Prometheus webui进行查询或者通过api查询(用grafana等报表展示)
Alertmanager可以配置查询语句进行报警,发送email等
三、性能方案设计
1.需求分析和测试设计
根据具体的性能测试需求,确定测试类型以及压测的模块(web/mysql/redis)
前期与相关人员沟通,初步确定压测方案等(确定大致流量设计并发数)
完成设计后,将内容发送给项目相关人员,确认是否满足需求
2.环境设计和搭建
根据需求采用线下还是线上压测
3.测试数据准备和构造
接口请求数据:自己构造
数据表的数据填充
多接口,结合业务场景设计请求比例
4.性能指标预期
每秒请求数
请求相应时间
错误率
机器性能:cpu、内存有误抖动
压测过程接口功能是否正常
5.发压工具准备
jmeter安装,准备机器数量
脚本编写,http请求等
启压命令
6.结果分析和测试报告
根据测试过程中记录的各种参数,结合压测工具产生的日志,对测试结果进行分析,并产生测试报告
测试完成后,确定是否满足要求
编写测试报告发送邮件
四、全链路性能测试介绍
因为测试环境硬件资源以及压测数据与线上差别太大并且服务间依赖关系错综复杂,测试环境很难模拟且不够稳定,压测出来的数据指标参考价值不大,难以用测试环境得出的结果推导生产真实容量。 所以需要基于实际的生产业务场景、生产环境,模拟海量的用户请求和数据对整个业务链进行压力测试。
生产环境进行单台机器压力测试的方式主要分为 4 种:
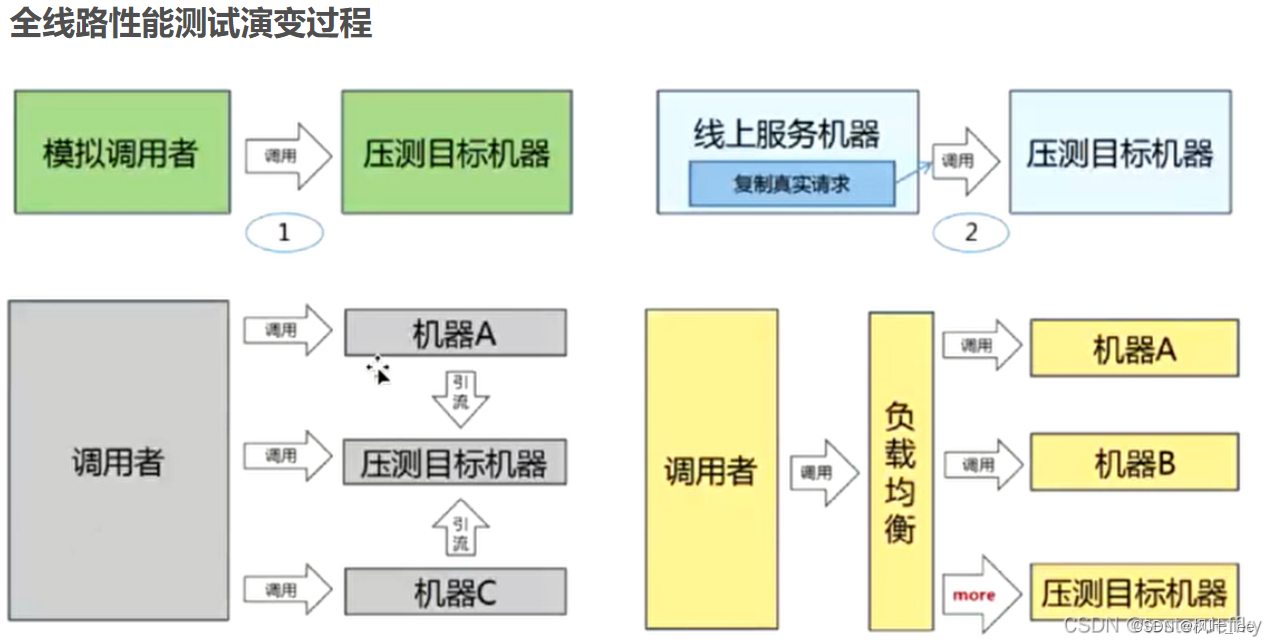
模拟请求:通过对生产环境的一台机器发起模拟请求调用来达到压力测试的目的
复制请求:通过将一台机器的请求复制多份发送到指定的压测机器
请求转发:将分布式环境中多台机器的请求转发到一台机器上
调整负载均衡:修改负载均衡设备的权重,让压测的机器分配更多的请求
当前全链路压测方式

压测线上,对服务影响,写数据影响,统计影响,对第三方依赖造成压力,恢复困难
版权归原作者 枫叶_lee 所有, 如有侵权,请联系我们删除。