
该脚本是kafka提供用来重新分配分区的脚本工具;
1.1 生成推荐配置脚本
**关键参数
--generate
**
在进行分区副本重分配之前,最好是用下面方式获取一个合理的分配文件;
编写
move-json-file.json
文件; 这个文件就是告知想对哪些Topic进行重新分配的计算
{
“topics”: [
{“topic”: “test_create_topic1”}
],
“version”: 1
}
然后执行下面的脚本,
--broker-list "0,1,2,3"
这个参数是你想要分配的Brokers;
sh bin/kafka-reassign-partitions.sh --zookeeper xxx:2181 --topics-to-move-json-file config/move-json-file.json --broker-list "0,1,2,3" --generate
执行完毕之后会打印
Current partition replica assignment//当前副本分配方式
{“version”:1,“partitions”:[{“topic”:“test_create_topic1”,“partition”:2,“replicas”:[1],“log_dirs”:[“any”]},{“topic”:“test_create_topic1”,“partition”:1,“replicas”:[3],“log_dirs”:[“any”]},{“topic”:“test_create_topic1”,“partition”:0,“replicas”:[2],“log_dirs”:[“any”]}]}
Proposed partition reassignment configuration//期望的重新分配方式
{“version”:1,“partitions”:[{“topic”:“test_create_topic1”,“partition”:2,“replicas”:[2],“log_dirs”:[“any”]},{“topic”:“test_create_topic1”,“partition”:1,“replicas”:[1],“log_dirs”:[“any”]},{“topic”:“test_create_topic1”,“partition”:0,“replicas”:[0],“log_dirs”:[“any”]}]}
需求注意的是,此时分区移动尚未开始,它只是告诉你当前的分配和建议。保存当前分配,以防你想要回滚它
1.2. 执行Json文件
**关键参数
--execute
**
将上面得到期望的重新分配方式文件保存在一个json文件里面
reassignment-json-file.json
{“version”:1,“partitions”:[{“topic”:“test_create_topic1”,“partition”:2,“replicas”:[2],“log_dirs”:[“any”]},{“topic”:“test_create_topic1”,“partition”:1,“replicas”:[1],“log_dirs”:[“any”]},{“topic”:“test_create_topic1”,“partition”:0,“replicas”:[0],“log_dirs”:[“any”]}]}
然后执行
sh bin/kafka-reassign-partitions.sh --zookeeper xxxxx:2181 --reassignment-json-file config/reassignment-json-file.json --execute
迁移过程注意流量陡增对集群的影响
Kafka提供一个broker之间复制传输的流量限制,限制了副本从机器到另一台机器的带宽上限,当重新平衡集群,引导新broker,添加或移除broker时候,这是很有用的。因为它限制了这些密集型的数据操作从而保障了对用户的影响、
例如我们上面的迁移操作加一个限流选项
-- throttle 50000000
sh bin/kafka-reassign-partitions.sh --zookeeper xxxxx:2181 --reassignment-json-file config/reassignment-json-file.json --execute – throttle 50000000
在后面加上一个
—throttle 50000000
参数, 那么执行移动分区的时候,会被限制流量在
50000000 B/s
加上参数后你可以看到
The throttle limit was set to 50000000 B/s
Successfully started reassignment of partitions.
需要注意的是,如果你迁移的时候包含 副本跨路径迁移(同一个Broker多个路径)那么这个限流措施不会生效,你需要再加上|
--replica-alter-log-dirs-throttle
这个限流参数,它限制的是同一个Broker不同路径直接迁移的限流;
如果你想在重新平衡期间修改限制,增加吞吐量,以便完成的更快。你可以重新运行execute命令,用相同的reassignment-json-file
1.3. 验证
**关键参数
--verify
**
该选项用于检查分区重新分配的状态,同时
—throttle
流量限制也会被移除掉; 否则可能会导致定期复制操作的流量也受到限制。
sh bin/kafka-reassign-partitions.sh --zookeeper xxxx:2181 --reassignment-json-file config/reassignment-json-file.json --verify

注意: 当你输入的BrokerId不存在时,该副本的操作会失败,但是不会影响其他的;例如
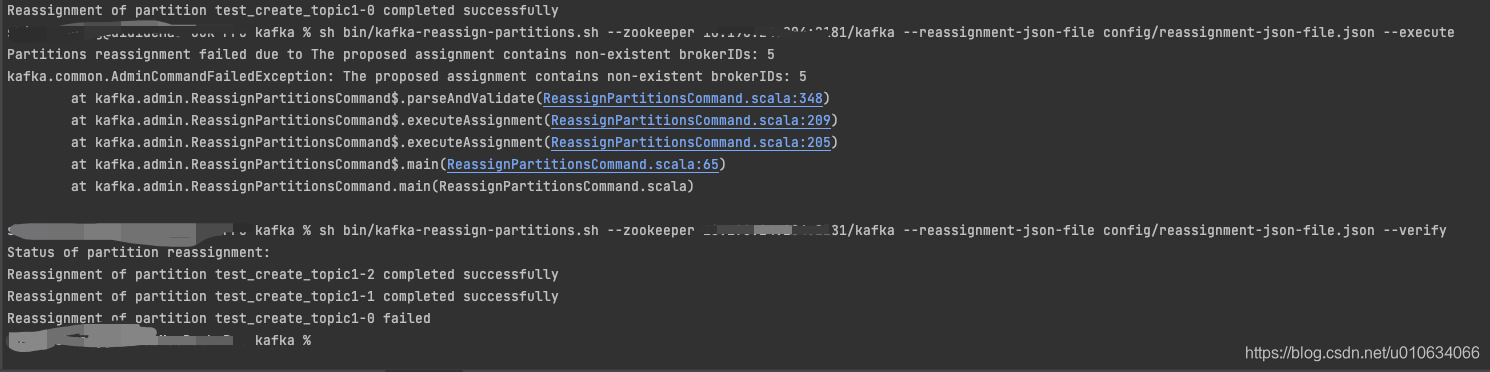
- 副本扩缩
kafka并没有提供一个专门的脚本来支持副本的扩缩, 不像
kafka-topic.sh脚本一样,是可以扩分区的; 想要对副本进行扩缩,只能是曲线救国了; 利用
kafka-reassign-partitions.sh来重新分配副本
2.1 副本扩容
假设我们当前的情况是 3分区1副本,为了提供可用性,我想把副本数升到2;
2.1.1 计算副本分配方式
我们用步骤1.1的
--generate
获取一下当前的分配情况,得到如下json
{
“version”: 1,
“partitions”: [{
“topic”: “test_create_topic1”,
“partition”: 2,
“replicas”: [2],
“log_dirs”: [“any”]
}, {
“topic”: “test_create_topic1”,
“partition”: 1,
“replicas”: [1],
“log_dirs”: [“any”]
}, {
“topic”: “test_create_topic1”,
“partition”: 0,
“replicas”: [0],
“log_dirs”: [“any”]
}]
}
我们想把所有分区的副本都变成2,那我们只需修改
"replicas": []
里面的值了,这里面是Broker列表,排在第一个的是Leader; 所以我们根据自己想要的分配规则修改一下json文件就变成如下
{
“version”: 1,
“partitions”: [{
“topic”: “test_create_topic1”,
“partition”: 2,
“replicas”: [2,0],
“log_dirs”: [“any”,“any”]
}, {
“topic”: “test_create_topic1”,
“partition”: 1,
“replicas”: [1,2],
“log_dirs”: [“any”,“any”]
}, {
“topic”: “test_create_topic1”,
“partition”: 0,
“replicas”: [0,1],
“log_dirs”: [“any”,“any”]
}]
}
注意
log_dirs
里面的数量要和
replicas
数量匹配;或者直接把
log_dirs
选项删除掉; 这个
log_dirs
是副本跨路径迁移时候的绝对路径
2.1.2 执行–execute

如果你想在重新平衡期间修改限制,增加吞吐量,以便完成的更快。你可以重新运行execute命令,用相同的reassignment-json-file:
2.1.2 验证–verify

完事之后,副本数量就增加了;
2.2 副本缩容
副本缩容跟扩容是一个意思; 当副本分配少于之前的数量时候,多出来的副本会被删除;
比如刚刚我新增了一个副本,想重新恢复到一个副本
执行下面的json文件
{
“version”: 1,
“partitions”: [{
“topic”: “test_create_topic1”,
“partition”: 2,
“replicas”: [2],
“log_dirs”: [“any”]
}, {
“topic”: “test_create_topic1”,
“partition”: 1,
“replicas”: [1],
“log_dirs”: [“any”]
}, {
“topic”: “test_create_topic1”,
“partition”: 0,
“replicas”: [0],
“log_dirs”: [“any”]
}]
}
执行之后可以看到其他的副本就被标记为删除了; 一会就会被清理掉
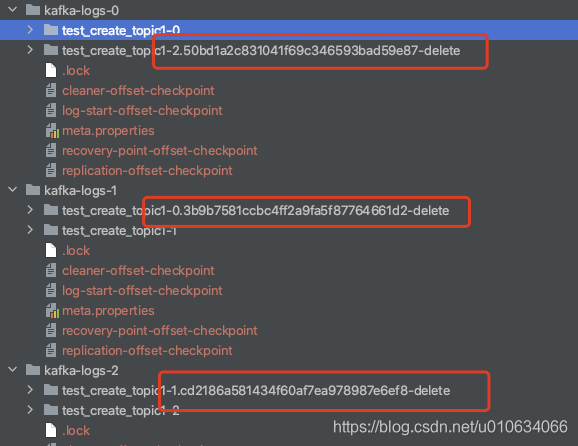
用这样一种方式我们虽然是实现了副本的扩缩容, 但是副本的分配需要我们自己来把控好, 要做到负载均衡等等; 那肯定是没有kafka自动帮我们分配比较合理一点; 那么我们有什么好的方法来帮我们给出一个合理分配的Json文件吗?PS:
我们之前已经分析过【kafka源码】创建Topic的时候是如何分区和副本的分配规则 那么我们把这样一个分配过程也用同样的规则来分配不就Ok了吗?
--generate
本质上也是调用了这个方法,
AdminUtils.assignReplicasToBrokers(brokerMetadatas, assignment.size, replicas.size)
写在最后
作为一名即将求职的程序员,面对一个可能跟近些年非常不同的 2019 年,你的就业机会和风口会出现在哪里?在这种新环境下,工作应该选择大厂还是小公司?已有几年工作经验的老兵,又应该如何保持和提升自身竞争力,转被动为主动?
就目前大环境来看,跳槽成功的难度比往年高很多。一个明显的感受:今年的面试,无论一面还是二面,都很考验Java程序员的技术功底。
最近我整理了一份复习用的面试题及面试高频的考点题及技术点梳理成一份“Java经典面试问题(含答案解析).pdf和一份网上搜集的“Java程序员面试笔试真题库.pdf”(实际上比预期多花了不少精力),包含分布式架构、高可扩展、高性能、高并发、Jvm性能调优、Spring,MyBatis,Nginx源码分析,Redis,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!
Java经典面试问题(含答案解析)

阿里巴巴技术笔试心得

“Java程序员面试笔试真题库.pdf”(实际上比预期多花了不少精力),包含分布式架构、高可扩展、高性能、高并发、Jvm性能调优、Spring,MyBatis,Nginx源码分析,Redis,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!
[外链图片转存中…(img-PTP3Jxyu-1721834761831)]
Java经典面试问题(含答案解析)
[外链图片转存中…(img-fvOMLpc0-1721834761831)]
阿里巴巴技术笔试心得
[外链图片转存中…(img-2soC7kvs-1721834761831)]
版权归原作者 2401_85358655 所有, 如有侵权,请联系我们删除。