
文章目录
⭐前言
大家好,我是yma16,本文分享关于python自动化获取个人博客质量分并可视化。
该系列文章:
python爬虫_基本数据类型
python爬虫_函数的使用
python爬虫_requests的使用
⭐selenium
Selenium 通过使用 WebDriver 支持市场上所有主流浏览器的自动化。 Webdriver 是一个 API 和协议,它定义了一个语言中立的接口,用于控制 web 浏览器的行为。 每个浏览器都有一个特定的 WebDriver 实现,称为驱动程序。 驱动程序是负责委派给浏览器的组件,并处理与 Selenium 和浏览器之间的通信。
python使用selenium调用WebDriver自动控制浏览器动作
💖 获取所有的文章url
思路分解
- 获取article标签
- 拿到a标签的属性链接
- 拿到a标签内容的标题
html的元素分析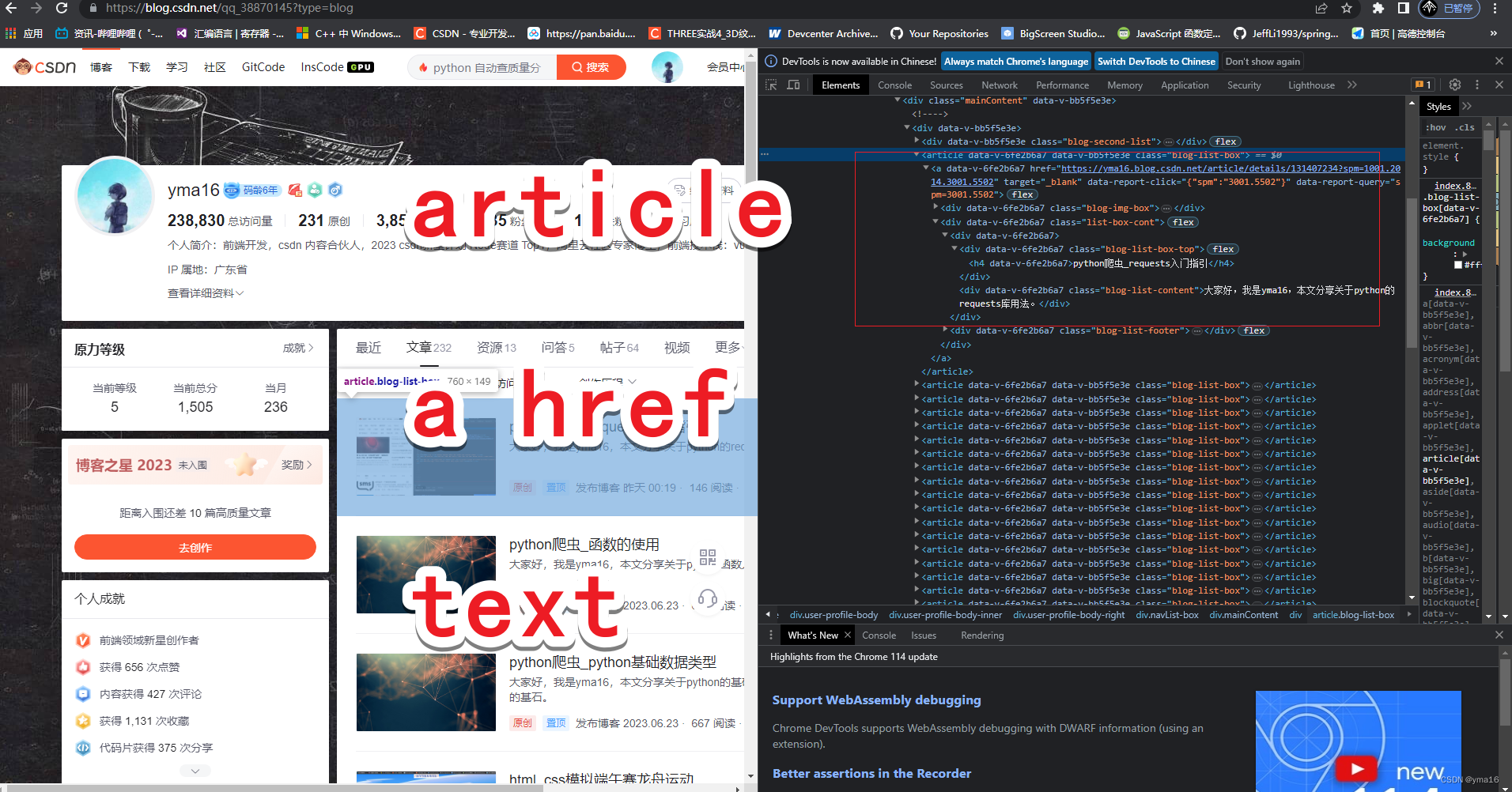
注意:需要完全滚动到底部加载所有的文章
代码块:
from selenium import webdriver
import time,re,json
dir_path='C:\\Users\MY\PycharmProjects\Spider_python\study2021\day07\dirver\msedgedriver.exe'
driver=webdriver.Edge(executable_path=dir_path)
url='https://blog.csdn.net/qq_38870145?type=blog'
driver.get(url)
now_url=driver.current_url
#定义一个初始值
temp_height=0
time.sleep(3)whileTrue:#循环将滚动条下拉
driver.execute_script("window.scrollBy(0,1000)")#sleep一下让滚动条反应一下
time.sleep(5)#获取当前滚动条距离顶部的距离
check_height = driver.execute_script("return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")#如果两者相等说明到底了if check_height==temp_height:break
temp_height=check_height
jsonData={'articleInfo':[# {src,title,name,aId}]}defnext_list():
article=driver.find_elements_by_xpath('//article[@class="blog-list-box"]')for item in article:
link=item.find_element_by_tag_name('a').get_attribute('href')
text=item.text
title=text.split('\n')[0]print('link', link)print('title',title)
compile1 = re.compile(r'https://(.*?).blog.csdn.net/article/details/(.*?)$', re.S)# 匹配 name和用户id
result = re.findall(compile1, link)print('result',result)
uid=''
aid=''for uid, aid in result:
uid=uid
aid=aid
jsonData['articleInfo'].append({'title':title,'src':link,'article':aid,'username':uid
})
next_list()
driver.close()withopen("./articleContent.json",'w')as write_f:
write_f.write(json.dumps(jsonData, indent=4, ensure_ascii=False))
写入json成功!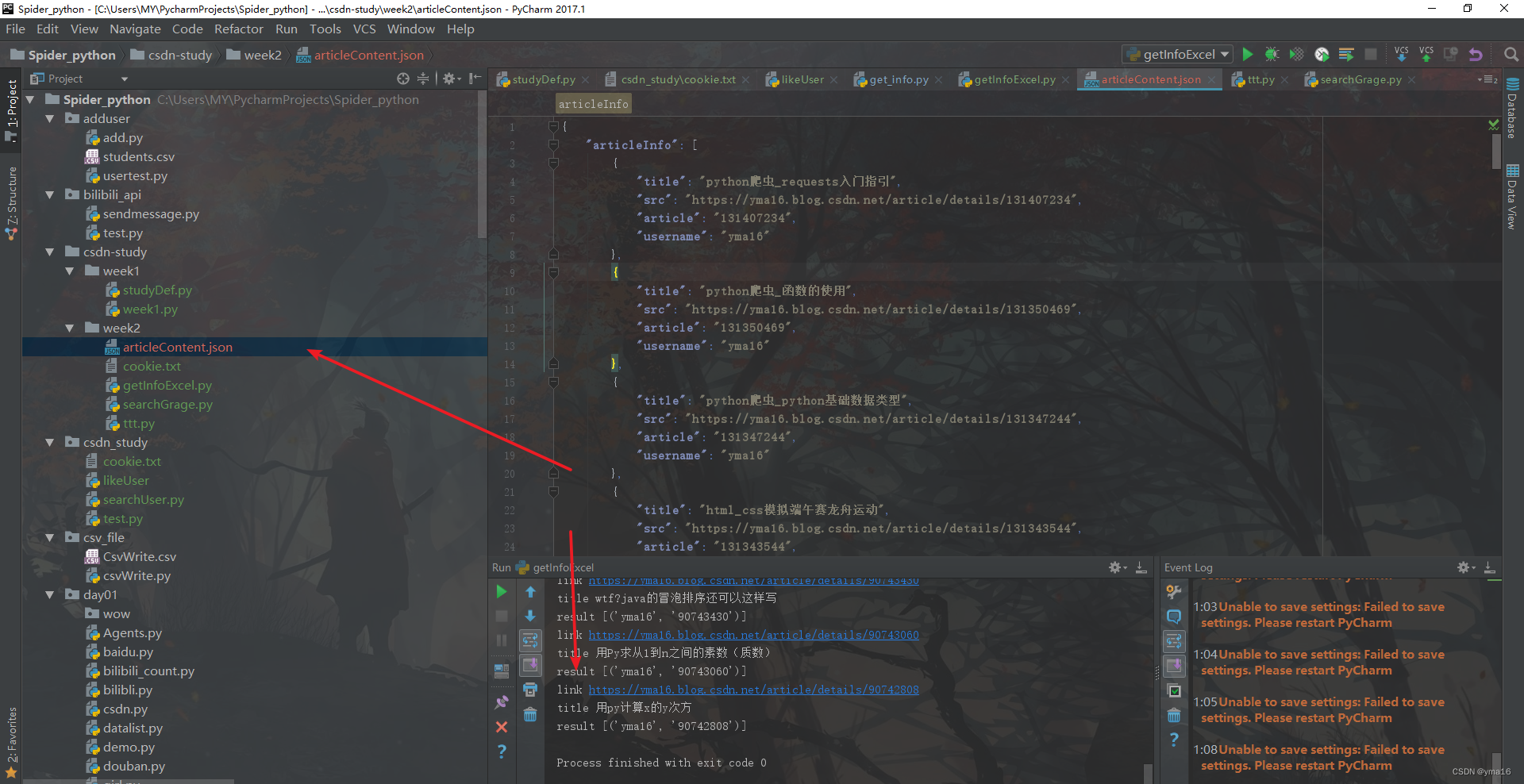
💖 根据url查询分数
思路分解:
- 自动填充url
- 获取分数
- 记录分数

注意:获取分数显示的渲染需要延迟一段时间
单个url读取代码块:
from selenium import webdriver
import time,re,json
dir_path='C:\\Users\MY\PycharmProjects\Spider_python\study2021\day07\dirver\msedgedriver.exe'
driver=webdriver.Edge(executable_path=dir_path)
url='https://www.csdn.net/qc'
driver.get(url)
now_url=driver.current_url
defautoWriteUrl(url):
driver.find_element_by_xpath('//input[@type="text" and @popperclass="csdn-input-autocomplete"]') \
.send_keys(url)# 输入内容
searchBtn()
getGrade()defsearchBtn():
driver.find_element_by_xpath('//div[@class="trends-input-box-btn"]') \
.click()# 点击defgetGrade():
time.sleep(2)
grade=driver.find_element_by_xpath('//p[@class="img"]')
gradeNum=grade.text
des=driver.find_element_by_xpath('//p[@class="desc text"]')
desContent=des.text
print(gradeNum)print(desContent)
time.sleep(1)
autoWriteUrl('https://yma16.blog.csdn.net/article/details/131407234')
运行结果: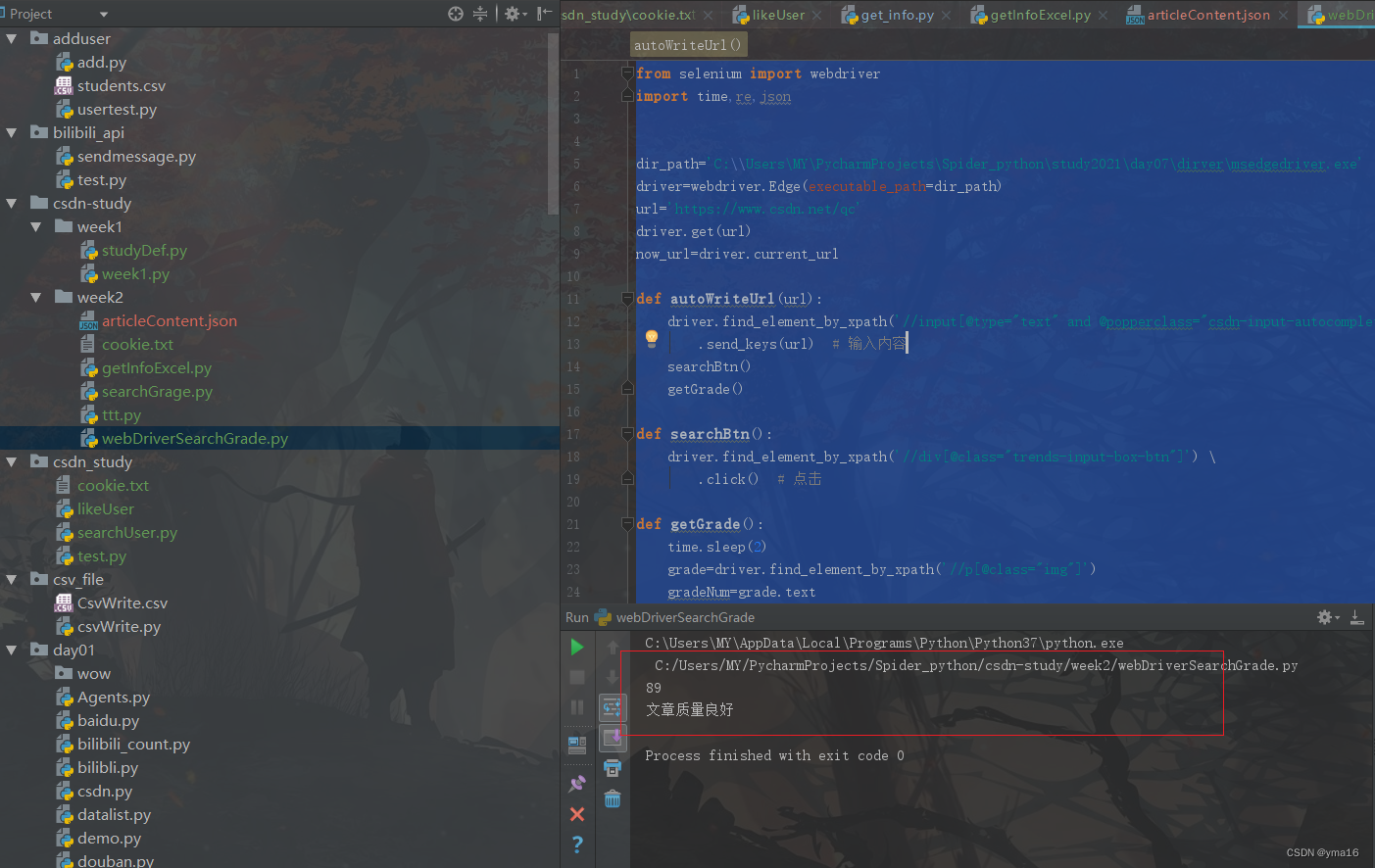
批量读取:
from selenium import webdriver
import time,json
dir_path='C:\\Users\MY\PycharmProjects\Spider_python\study2021\day07\dirver\msedgedriver.exe'
driver=webdriver.Edge(executable_path=dir_path)
url='https://www.csdn.net/qc'
driver.get(url)
now_url=driver.current_url
defautoWriteUrl(url):print(url)
driver.find_element_by_xpath('//input[@type="text" and @popperclass="csdn-input-autocomplete"]') \
.send_keys(url)# 输入内容
searchBtn()return getGrade()defsearchBtn():
driver.find_element_by_xpath('//div[@class="trends-input-box-btn"]') \
.click()# 点击defgetGrade():
time.sleep(1)
grade=driver.find_element_by_xpath('//p[@class="img"]')
gradeNum=grade.text
des=driver.find_element_by_xpath('//p[@class="desc text"]')
desContent=des.text
print(gradeNum)print(desContent)return[gradeNum,desContent]# autoWriteUrl('https://yma16.blog.csdn.net/article/details/131407234')# 质量分数据
gradeJsonData={}defmapJson(jsonVal):for key in jsonVal.keys():
gradeJsonData[key]=[]for childItem in jsonVal[key]:print(childItem)
grade =0
des =''
temp={}for childItemKey in childItem:
temp[childItemKey]=childItem[childItemKey]if(childItemKey=='src'):
grade=autoWriteUrl(childItem[childItemKey])[0]
des=autoWriteUrl(childItem[childItemKey])[1]
temp['grade']=grade
temp['des']=des
gradeJsonData[key].append(temp)if __name__=='__main__':withopen('articleContent.json','r')as f:
jsonData = json.load(f)
mapJson(jsonData)withopen("./articleGrade.json",'w', encoding='utf-8')as write_f:
write_f.write(json.dumps(gradeJsonData, indent=4, ensure_ascii=False))
driver.close()
运行结果如下: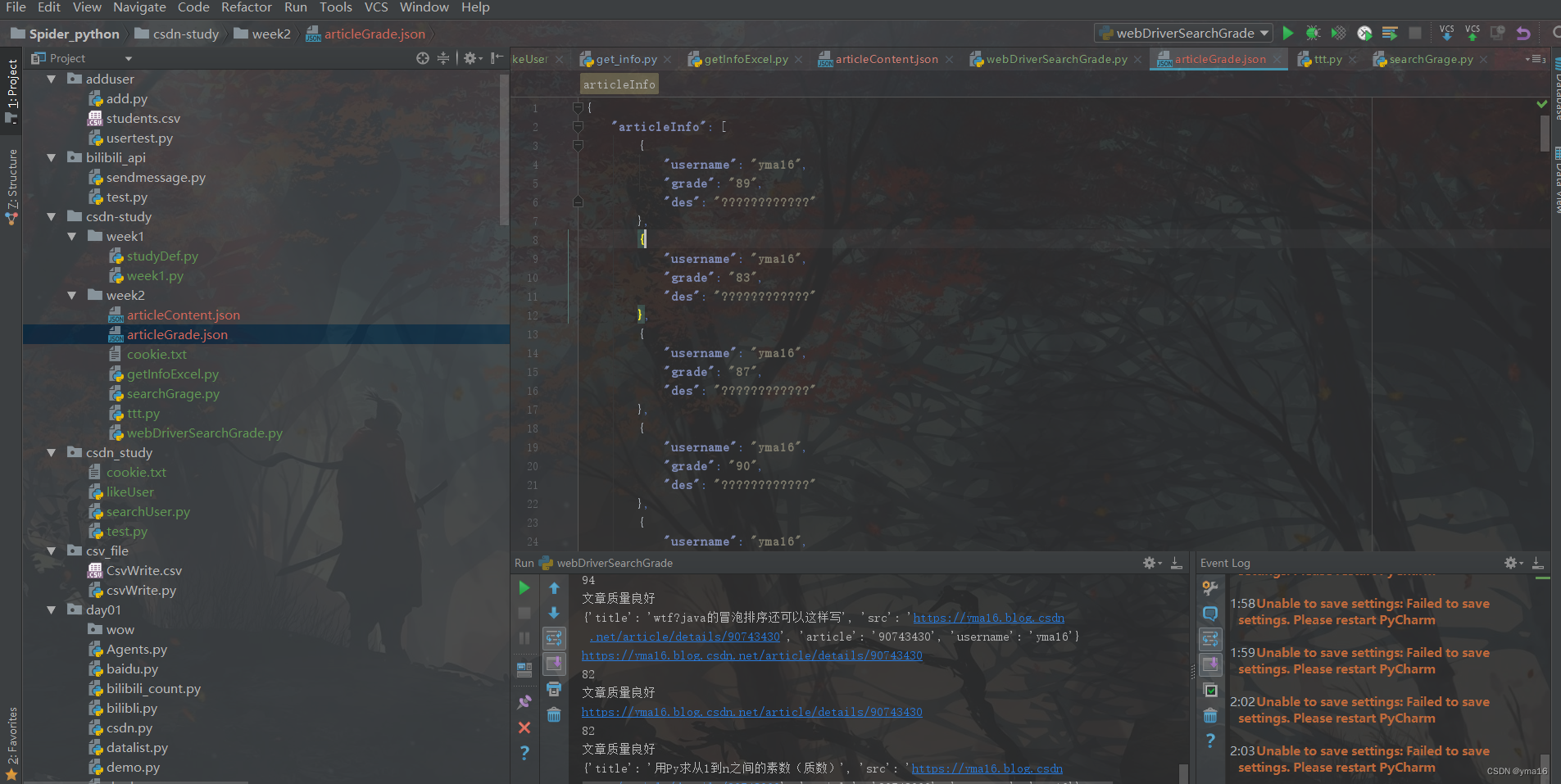
💖 inscode结合echarts展示
echarts读取json显示柱状图
<!DOCTYPEhtml><html><head><metacharset="utf-8"><title>echarts 滚动事件</title><!-- vue2 生产环境版本,优化了尺寸和速度 --><scriptsrc="https://cdn.jsdelivr.net/npm/vue@2"></script><scriptsrc="./echarts.js"></script><scripttype="text/javascript"src="./csdnGrade.js"></script></head><style>#app{position: absolute;height: 100vh;width: 100vw;}</style><body><divid="app"><div>
csdn 质量分柱状图
<divid="first"style="width: 900px;height:1200px;"></div></div></div><scripttype="text/javascript">
csdnJson.articleInfo.sort((a,b)=>parseInt(a.grade)-parseInt(b.grade))const instanceVue ={el:'#app',name:'ecahrts',data(){return{firstChart:null,secondChart:null,thirdChart:null,maxNum:1000,};},mounted(){this.initFirstData()},methods:{initFirstData(){// 基于准备好的dom,初始化echarts实例var myChart = echarts.init(document.getElementById('first'));// 指定图表的配置项和数据let base =+newDate(1968,9,3);let oneDay =24*3600*500;let date =[];let data =[Math.random()*300];for(let i =1; i <this.maxNum; i++){var now =newDate((base += oneDay));
date.push([now.getFullYear(), now.getMonth()+1, now.getDate()].join('/'));
data.push(Math.round((Math.random()-0.5)*20+ data[i -1]));}const option ={tooltip:{trigger:'axis',axisPointer:{type:'shadow'}},legend:{},xAxis:{type:'category',data: csdnJson.articleInfo.map(item=> item.username)},yAxis:{type:'value'},series:[{data: csdnJson.articleInfo.map(item=> item.grade),type:'bar',showBackground:true,backgroundStyle:{color:'rgba(180, 180, 180, 0.2)'}}]};// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);// 监听this.firstChart = myChart;},}}// 实例化newVue(instanceVue);</script></body></html>
运行结果:
inscode:
结束
本文分享python的自动化获取质量分到此结束!
👍 点赞,是我创作的动力!
⭐️ 收藏,是我努力的方向!
✏️ 评论,是我进步的财富!
💖 感谢你的阅读!
本文转载自: https://blog.csdn.net/qq_38870145/article/details/131427987
版权归原作者 yma16 所有, 如有侵权,请联系我们删除。
版权归原作者 yma16 所有, 如有侵权,请联系我们删除。