
在这篇文章中,我将解释使用 SMOTE、SVM SMOTE、BorderlineSMOTE、K-Means SMOTE 和 SMOTE-NC 进行过采样/上采样。我将通过一个实际示例进行解释,在该示例中我们应用这些方法来解决不平衡的机器学习问题,以了解它们的影响。
更多关于【数据科学】【机器学习】等最新算法请关注官W(芯媒)https://mp.weixin.qq.com/s/rvLsUEP_1vge-HU9lzRoJw

介绍
在处理机器学习问题时,我检查的第一件事是目标类在我的数据中的分布。这个分布告诉我如何解决问题的某些方面。我经常在数据中看到某种不平衡,有时这种不平衡并不显着(为简单起见,假设二进制分类任务为 60:40),而有时却是(比如 98:2)。
现在,当这种不平衡变得微不足道时,我的生活就轻松多了;但是,我已经学会接受并非总是如此。对于那些使用过此类数据集(例如,流失建模、倾向建模等)的人,您会知道模型在正确识别少数类样本方面的性能有多差。这是了解如何处理此类问题以获得最佳结果的关键所在。
有几种方法可以解决这个问题,今天我们将讨论过采样(又名上采样)。简单地说,过采样正在增加少数类样本的数量。然而,这不仅仅是复制少数类的样本(有时可能很有效!),而是使用一些更复杂的方法。这些复杂的方法包括流行的 SMOTE 和从它派生的几个有用的变体(我觉得没有太多讨论)。
我将首先解释这些方法是如何工作的,然后我们将介绍一个小的实际示例,我们将在其中应用这些方法并查看它们的性能。让我们开始吧!
方法
SMOTE(合成少数过采样技术)
SMOTE [1] 遵循一个非常简单的方法:

SMOTE
- 从少数类中随机选择一个样本,我们称它为O(代表 Origin)
- 找到属于同一类的 O 的 K-Nearest Neighbors
- 使用直线将 O 连接到这些邻居中的每一个
- 随机选择 [0,1] 范围内的缩放因子“ z”
- 对于每个新连接,在距离 O 的 (z*100)% 线上放置一个新点。这些将是我们的合成样本。
- 重复此过程,直到获得所需数量的合成样本
虽然在复制原始样本上生成新的合成样本的想法是一个进步,但 SMOTE 有一个主要弱点。如果在第 1 步或第 2 步中选择的点位于以多数类样本为主的区域中,则合成点可能会在多数类区域内生成(这可能会使分类变得困难!)。要了解更多信息,Saptarsi Goswami 博士和Aleksey Bilogur为这一现象提供了信息丰富的可视化。
边界线SMOTE
BorderlineSMOTE [2] 的工作方式与传统的 SMOTE 类似,但有一些注意事项。为了克服 SMOTE 的缺点,它识别了两组点——Noise和Border。你问的这些特殊点是什么?如果一个点的所有最近邻居都属于不同的类别(即大多数),则该点称为“噪声” 。另一方面,“边界” 点是那些混合了多数和少数类点作为最近邻居的点。
采样完成后(SMOTE -> Step 1),仅使用边界点。之后,当找到最近的邻居时,只选择属于同一类的点的标准放宽到包括属于任何类的点。这有助于选择有误分类风险的点和更靠近边界的新点。其他一切都是一样的。
但这个解决方案不是灵丹妙药。限制仅从边界点采样和放宽邻域选择标准并不需要在所有情况下都有效。但是,这是另一天的话题。
K-Means SMOTE
这是一种相当新的方法 [3],旨在减少其他过采样方法产生的噪声合成点。它的工作方式相当简单:
- 对数据进行 K-Means 聚类。(什么是 K-Means 聚类?)
- 选择少数类样本比例较高(>50% 或用户定义)的集群。
- 将常规 SMOTE 应用于这些选定的集群。每个集群将被分配新的合成点。这些生成点的数量将取决于集群中少数类的稀疏性;越稀疏,新点越多。
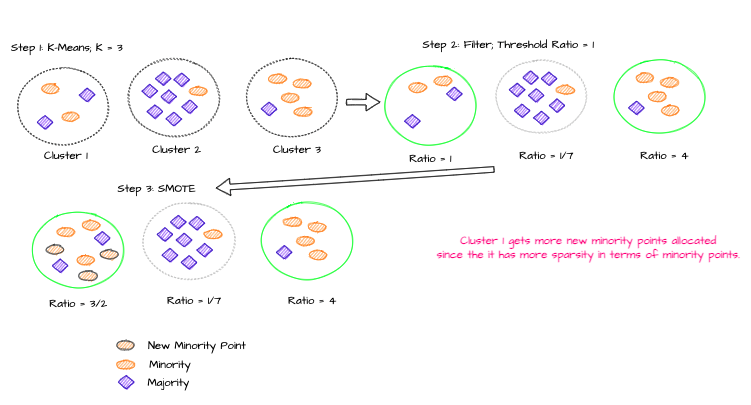
K-Means SMOTE
从本质上讲,这种方法有助于创建少数类的集群(受其他类影响不大)。这最终可以使 ML 模型受益。然而,它继承了 K-Means 算法的弱点——例如找到正确的K等等。
我想现在是对采样模因大笑的好时机(在阅读了上述方法后应该是有意义的)。

使用 imgflip 生成的图像
支持向量机
SVM SMOTE [4] 侧重于沿决策边界增加少数点。这背后的论点是,围绕该边界的实例对于估计最佳决策边界至关重要(这与我们之前看到的 K-Means 方法形成对比,但与 Borderline 变体一致)。
所以这就是这个方法的工作原理:
- 根据您的数据训练 SVM。这将为您提供支持向量(我们专注于少数类支持向量)。(什么是 SVM?)
- 然后我们使用这些支持向量来生成新样本。对于每个支持向量,我们找到它的 K-Nearest Neighbors,并使用插值或外推法沿着连接支持向量和最近邻居的线创建样本。
- 如果少于一半的最近邻居属于多数类,那么我们进行外推。这有助于将少数族裔地区扩大到多数族裔地区。如果没有,我们进行插值。这里的想法是,由于大多数邻居属于多数类别,因此我们将整合少数类别的当前区域。
如果您发现难以掌握第 3 点,请尝试在脑海中想象它或将其画在一张纸上,这样您就可以看到它的样子。这应该使事情更加明显。查看本文末尾列出的研究论文 [4] 并验证您的理解。
注意:当找到最近的邻居时,我们考虑所有的类,但是当将少数支持向量加入这些邻居时,我们只考虑少数的。
当类之间的重叠程度较低时,此方法效果很好。
SMOTE-NC
如果您想知道上述方法如何处理分类变量(无需进行某种形式的编码),那么您就在正确的轨道上。上述所有方法仅适用于数值数据。虽然这个世界上有许多问题没有得到解决,但处理分类数据并不是其中之一。
SMOTE-NC (N 代表标称,C 代表连续) [1] 当我们有数字©和分类 (N) 数据的混合时可以使用。要了解此方法的工作原理,我将回答两个问题。暂停片刻,想一想他们可以成为什么样的人。
问题 1:鉴于我们有分类变量,我们如何计算最近邻时的距离?
答案 1:我们计算一个常数M(将其视为惩罚项),它是少数样本的数值特征的标准差的中位数。请参见下图:
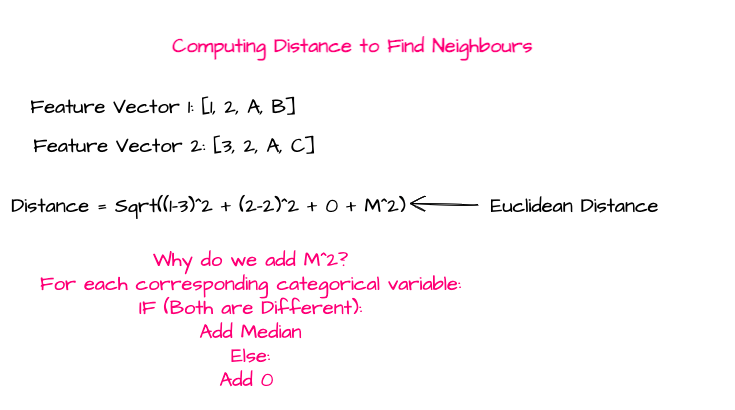
SMOTE-NC:计算距离
问题 2:我们如何为新的合成点分配类别?
答案 2:为了获得新合成样本的数字特征,我们使用传统的 SMOTE。然而,为了获得分类特征,我们分配出现在大多数 K-Nearest Neighbors(都属于少数类)中的值。
所以现在我们知道如何找到最近的邻居(SMOTE 的第 2 步)并分配类别。剩下的基本上就是 SMOTE 算法了。
注意:如果您的数据只有分类特征,那么您可以使用SMOTE-N。但是,这种情况应该很少见。
实际例子
实现这些方法相对简单(尽管您需要查看研究论文中的一些更详细的细节——列在本文末尾)。有一个名为Imbalanced Learn的优秀包已经实现了所有这些方法,并且非常易于使用。但是,如果你有时间,为什么不做你的实现,看看它与包的比较。
所以,来举个例子。我们将使用电信客户流失数据集,因为它本质上是不平衡的。这是一个二元分类问题,客户要么离开(即流失),要么留下。
我们将比较以下策略的分类器性能:
- 没有过采样
- 随机过采样
- SMOTE
- 边界线SMOTE
- 支持向量机
- K-Means SMOTE
由于这是一个不平衡的问题,分类器准确度不是比较的最佳指标。相反,我将重点关注少数群体(流失)的召回。召回让我们了解分类器在正确识别流失客户方面的能力。我们也可以专注于精度和 F1,但这取决于业务需求和重点是什么(最大限度地减少误报或误报或两者兼而有之)。阅读这篇文章以了解有关这些指标的更多信息,并获得关于何时选择什么的基本直觉。
整个笔记本可以在这里找到。我只会在下面展示与过采样相关的代码。
#Imports
from imblearn.over_sampling import RandomOverSampler
from imblearn.over_sampling import SMOTE from
imblearn.over_sampling import BorderlineSMOTE
from imblearn.over_sampling import SVMSMOTE
from imblearn.over_sampling import KMeansSMOTE#Random Oversampling
random_os = RandomOverSampler(random_state = 42)
X_random, y_random = random_os.fit_resample(X_train, y_train)#SMOTE
smote_os = SMOTE(random_state = 42)
X_smote, y_smote = smote_os.fit_resample(X_train, y_train)#BorderlineSMOTE
smote_border = BorderlineSMOTE(random_state = 42, kind = 'borderline-2')
X_smoteborder, y_smoteborder = smote_border.fit_resample(X_train, y_train)#SVM
SMOTE smote_svm = SVMSMOTE(random_state = 42)
X_smotesvm, y_smotesvm = smote_svm.fit_resample(X_train, y_train)#K-Means
SMOTE smote_kmeans = KMeansSMOTE(random_state = 42)
X_smotekmeans, y_smotekmeans = smote_kmeans.fit_resample(X_train, y_train)
读者练习:
我所做的过采样使流失和非流失之间的比率为 1。但是我们可以根据需要使用采样器的超参数(请参阅这些文档**)来改变它以及许多其他事情。您可以使用这些超参数,看看它们如何改变结果样本。
完成后,我得到以下结果:
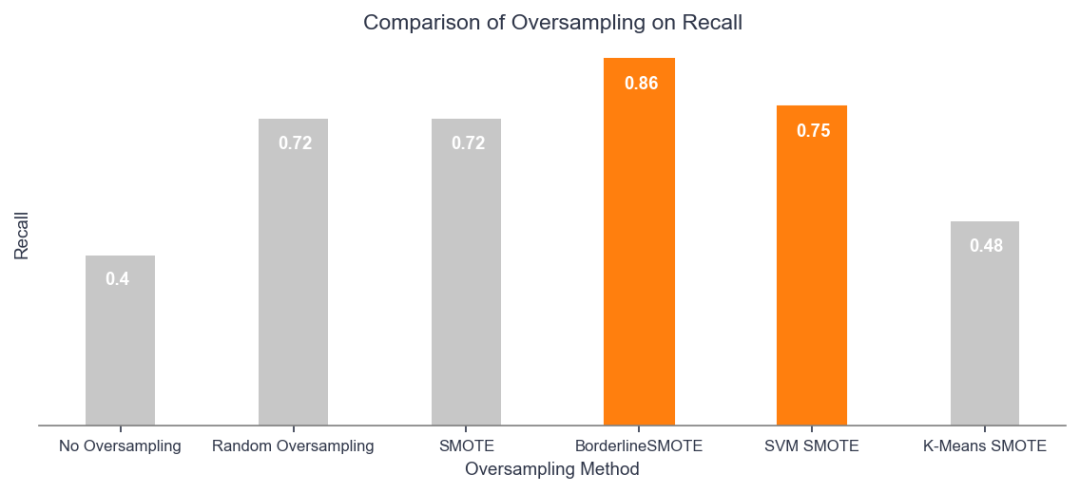
过采样对召回的比较
结论:
1. 对于这个问题,某种形式的过采样总比没有过采样要好。
2. BorderlineSMOTE 在 SMOTE、SVM SMOTE 和 Random Oversampling 相对相同的情况下,大大优于其他方法。正如我之前所说,随机过采样有时会产生有利的结果。
3. K-Means SMOTE 给出了所有过采样方法中最差的结果。但是,您不应放弃此方法以供将来使用。根据问题类型和数据分布,任何方法都可以胜过其他方法。也许,在这种情况下,我们选择的数据不适合 K-Means。
注意:在笔记本中,我绘制了每种比较方法的结果数据分布。看一看,并尝试形成一种视觉直觉来解释为什么我们会得到这些结果(尤其是对于 BorderlineSMOTE 和 K-Means SMOTE)。
我希望这篇文章能帮助您了解一些基本和高级的过采样方法,以及如何使用它们更好地处理不平衡数据。需要注意的是,有很多方法可以处理不平衡的数据,例如欠采样 (也称为下采样)和 类权重。良好的 ML 实践,如 EDA、特征选择和工程、模型调整等,在解决这些问题方面也有很长的路要走。
正如我之前所说,这个不平衡问题没有灵丹妙药。如果您了解可以解决问题的各种方法,您将能够就您可以做什么、应该做什么做出更明智的决定,并节省时间来获得性能更好的模型。
这就是所有人,让我们以一个很好的采样模因(和教训)结束这篇文章。

使用 imgflip 生成的图像
致谢
本文是代表 Intellify Australia 撰写的——我在该公司担任数据科学家。
在 Intellify,我们使用数据、分析和机器学习来帮助
解决客户最具挑战性的业务问题。请访问我们的网站以了解更多信息。
**更多关于【数据科学】【机器学习】等最新算法请关注官W(芯媒)
https://mp.weixin.qq.com/s/rvLsUEP_1vge-HU9lzRoJw**
参考
[1] NV Chawla、KW Bowyer、LOHall、WP Kegelmeyer,“SMOTE:合成少数过采样技术”,人工智能研究杂志,321-357,2002。
[2] H. Han, W. Wen-Yuan, M. Bing-Huan,“Borderline-SMOTE:一种新的不平衡数据集学习中的过采样方法”,智能计算进展,878-887,2005。
[3] Felix Last、Georgios Douzas、Fernando Bacao,“基于 K-Means 和 SMOTE 的不平衡学习的过采样”
[4] HM Nguyen、EW Cooper、K. Kamei,“用于不平衡数据分类的边界过采样”,国际知识工程和软数据范式杂志,3(1),第 4-21 页,2009 年。
版权归原作者 challeypeng 所有, 如有侵权,请联系我们删除。