
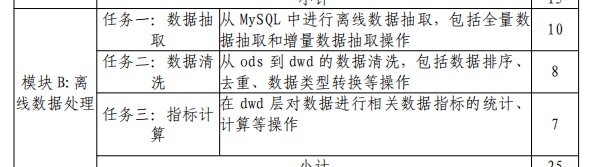
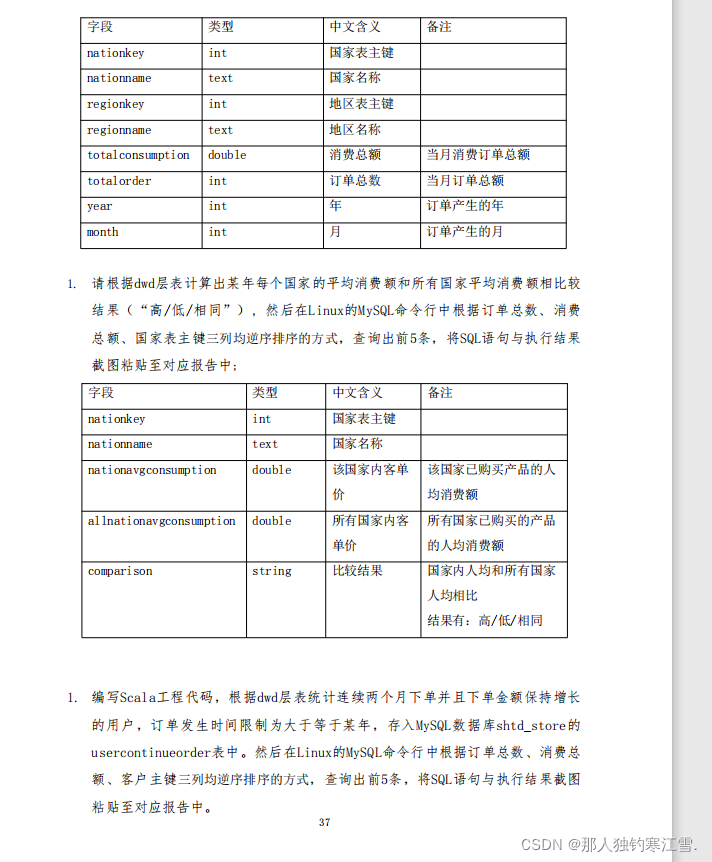
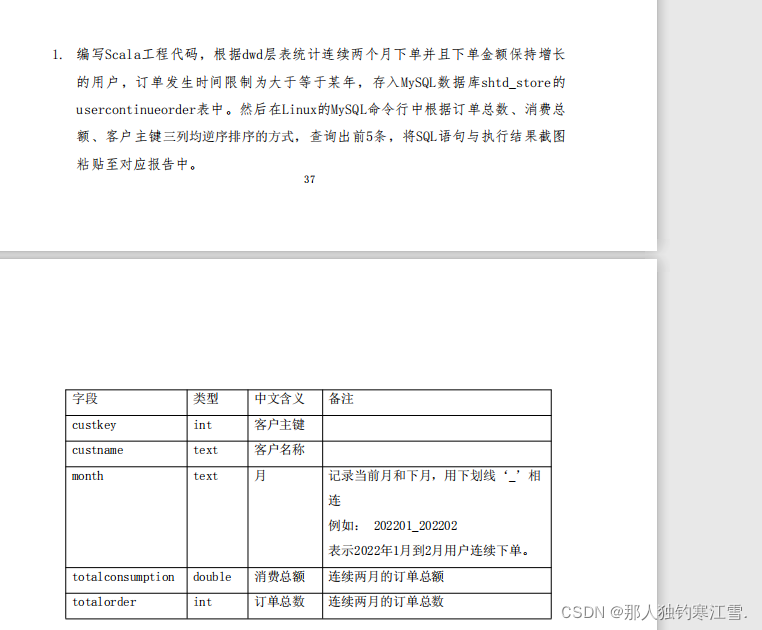
模块B离线数据抽取
任务简介
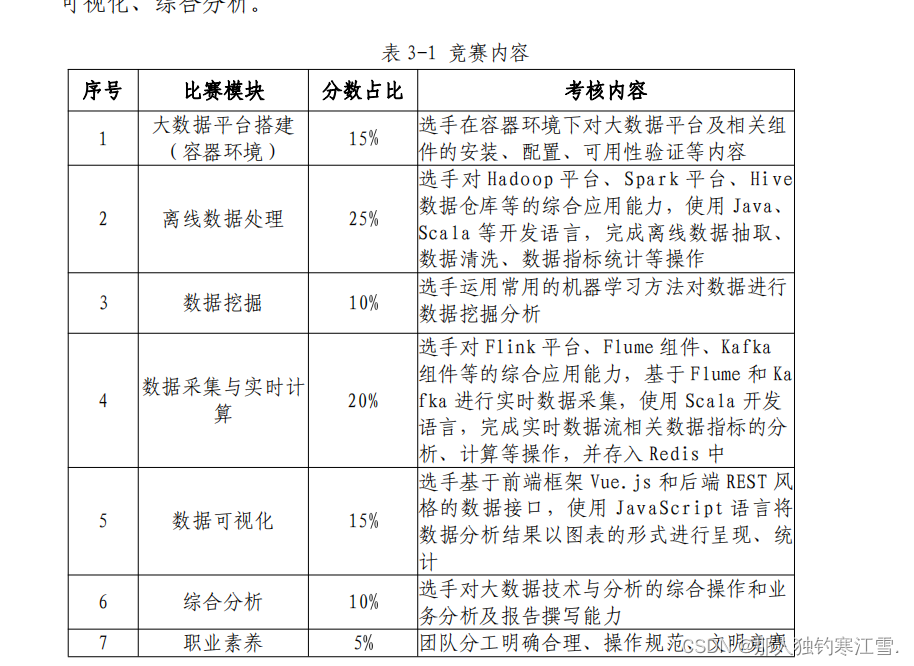





具体步骤简介

第一步:开启动态分区
val spark: SparkSession =newsql.SparkSession
.Builder().appName("data_Extraction").master("master//:7707").config("hive.exec.dynamic",value=true)//开启动态分区.config("hive.exec.dynamic.partitions","nonstrict")//关闭严格模式,否则必须要有个静态分区.config("hvie.exec.dynamic.partition",10000)//动态分区数量.enableHiveSupport().getOrCreate()
第二步:提取前一天时间
//提取前一天时间
def getYesterday():String={
val simpleDateFormat =newSimpleDateFormat("yyyyMMdd")//设置日期格式为年月日
val calendar=Calendar.getInstance()
calendar.add(Calendar.DATE,-1)//提取前一天的时间
simpleDateFormat.format(Calendar.getInstance)}
第三步:读取MYSQL数据
//读取MYSQL数据
def extract(tableName:String):DataFrame={
val prop=newProperties()
prop.put("user","root")//输入用户名 登陆密码 以及链接驱动
prop.put("password","123456")
prop.put("dirver","com.mysql.jdbc.Diver")
val df=spark
.read
.jdbc(MYSQL_URL,tableName.toUpperCase,prop)
df
第四步:全量写入数据
//全量写入
defoverWiteTable(tableName:String): Unit ={
val df=extract(tableName)
val yesterday=getYesterday()
df.withColumn("etldate",lit(yesterday)).write
.format("hive").mode(SaveMode.Overwrite).insertInto(tableName)
第五步:Main
//主方法
def main(args:Array[String]):Unit={sql("use ods")//进入overWiteTable("customer")
第六步:打包集群
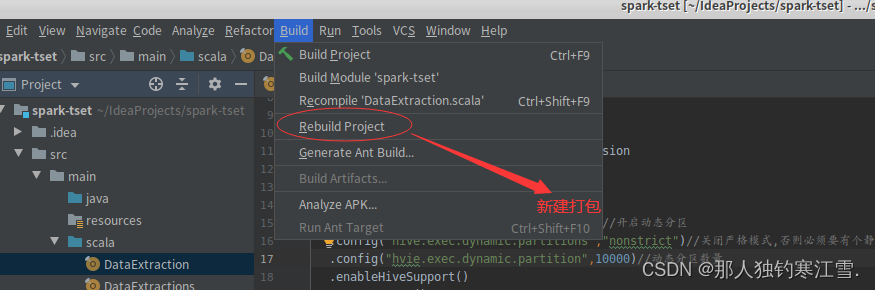
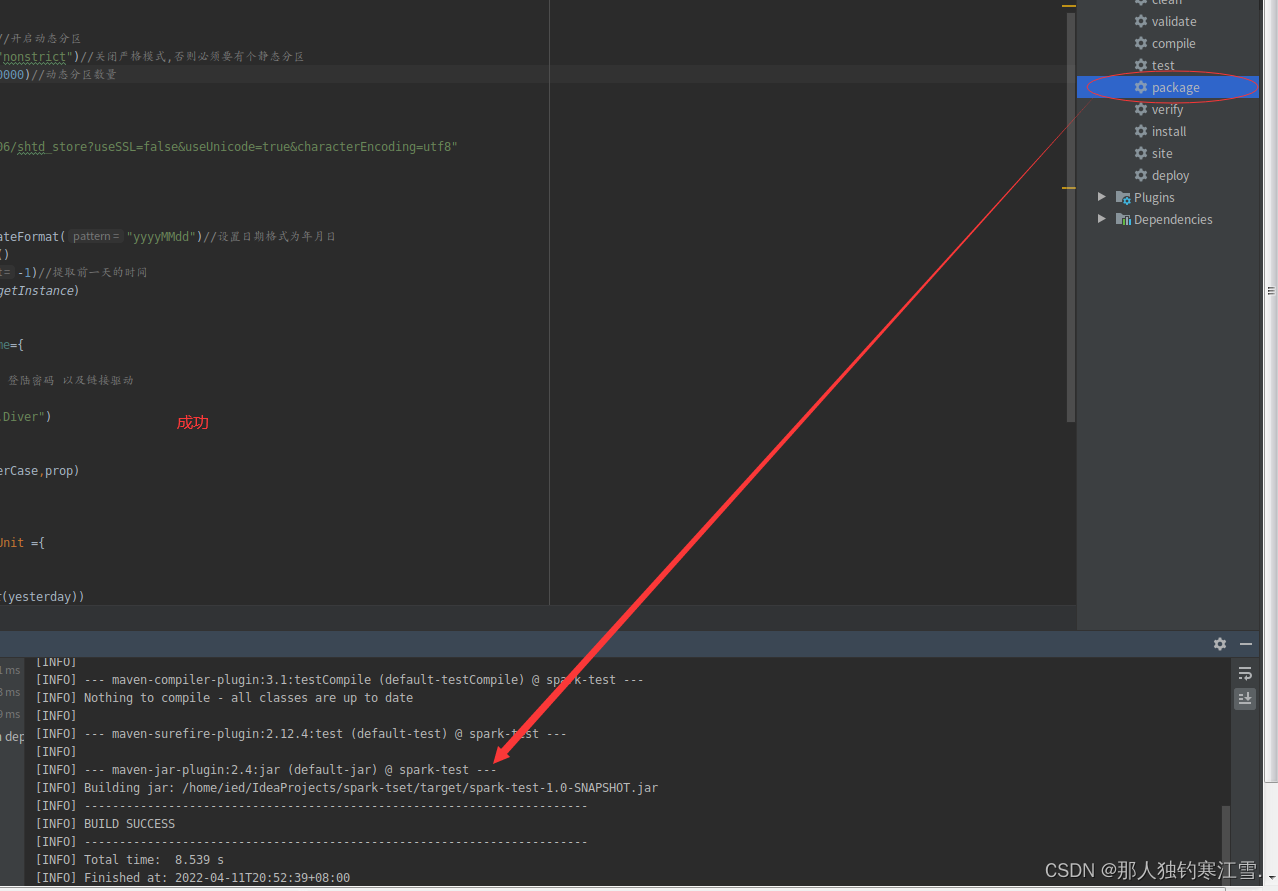
第七步:找到jar包
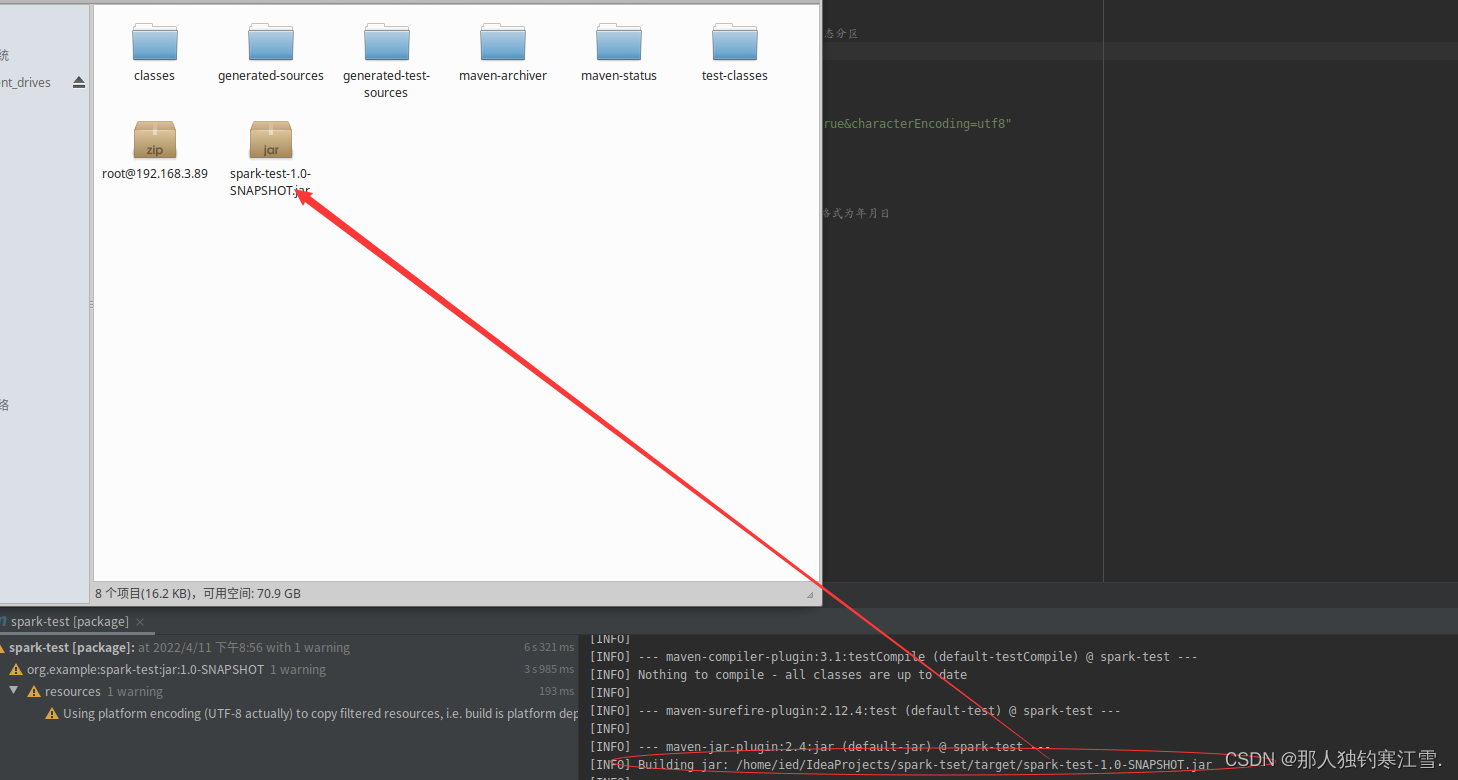
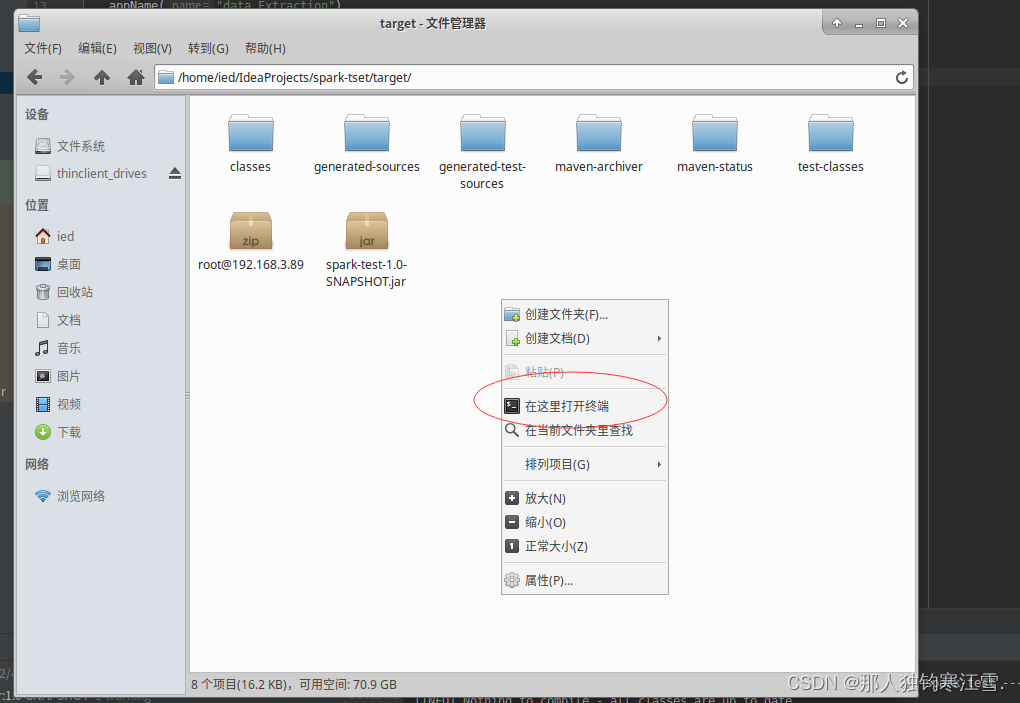
第八步:把jar包打包到集群目录下


第九步:进入Master目录下运行
可能会遇见的错误:没有那个文件目录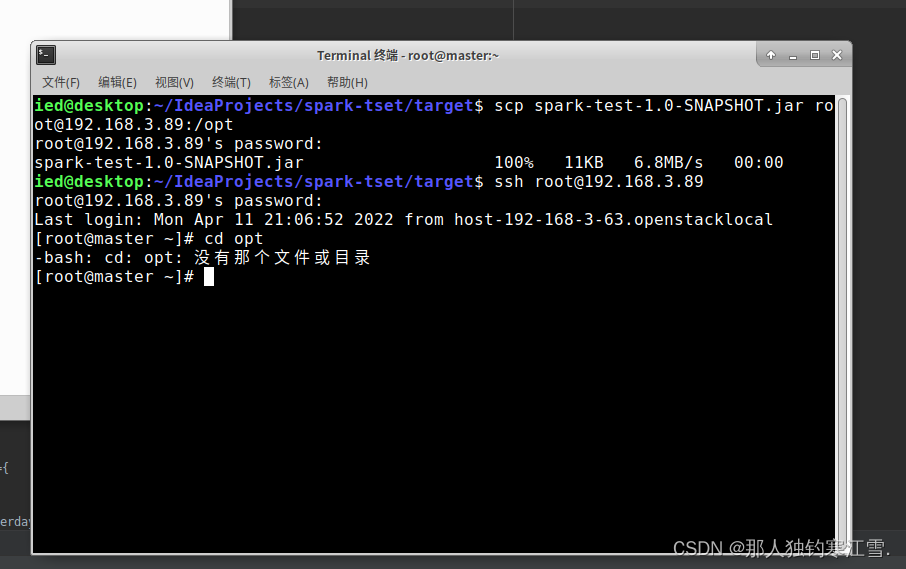

第十步: 输入代码及——运行结果
整体代码
import java.text.SimpleDateFormat
import java.util.Calendar
import java.util.Properties
import org.apache.spark.sql.functions._
import org.apache.spark.sql
import org.apache.spark.sql.{DataFrame,SaveMode,SparkSession}object DataExtraction {
val spark: SparkSession =newsql.SparkSession
.Builder().appName("data_Extraction").master("spark://192.168.3.89:7077").config("hive.exec.dynamic",value =true)//开启动态分区.config("hive.exec.dynamic.partition.mode","nonstrict")//关闭严格模式,否则必须要有个静态分区.config("hive.exec.max.dynamic.partitions",10000)//动态分区数量.enableHiveSupport().getOrCreate()
val MYSQL_URL="jdbc:mysql://master:3306/shtd_store?useSSL=false&useUnicode=true&characterEncoding=utf8"
import spark.sql
//提取前一天时间
def getYesterday():String={
val simpleDateFormat =newSimpleDateFormat("yyyyMMdd")//设置日期格式为年月日
val calendar=Calendar.getInstance()
calendar.add(Calendar.DATE,-1)//提取前一天的时间
simpleDateFormat.format(calendar.getTime)}//读取MYSQL数据
def extract(tableName:String):DataFrame={
val prop=newProperties()
prop.put("user","root")//输入用户名 登陆密码 以及链接驱动
prop.put("password","123456")
prop.put("driver","com.mysql.jdbc.Driver")
val df=spark
.read
.jdbc(MYSQL_URL,tableName.toUpperCase,prop)
df
}//全量写入
def overWiteTable(tableName:String):Unit={
val df=extract(tableName)
val yesterday=getYesterday()
df.withColumn("etldate",lit(yesterday)).write
.format("hive").mode(SaveMode.Overwrite)//覆盖,适合全量更新,增量更新为.append.insertInto(tableName)}//本地运行出错为没有链接到hive//主方法
def main(args:Array[String]):Unit={sql("use ods").show//进入overWiteTable("customer")}}
本文转载自: https://blog.csdn.net/m0_62491934/article/details/124105599
版权归原作者 那人独钓寒江雪. 所有, 如有侵权,请联系我们删除。
版权归原作者 那人独钓寒江雪. 所有, 如有侵权,请联系我们删除。